大二暑假第六周总结--开始学习Hadoop基础(五)
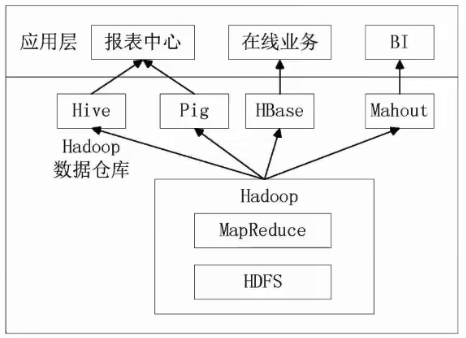
简单学习数据仓库HIVE
- HIVE是一个构建于Hadoop顶端的数据仓库工具
- 支持大规模数据存储,分析,具有良好的可扩展性
- 某种程度上可以看做是用户编程接口,本身不存储和处理数据
- 依赖分布式系统HDFS存储数据
- 定义了简单的类似SQL的查询语言——HIVEQL
- 用户可以通过编写的HIVEQL语句运行在MapReduce任务
- 可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上
- 是一个可以提供有效,合理,直观组织和使用数据的分析工具
特点:1.采用批处理方式处理海量数据:HIVE需要把HIVEQL语句转化成MapReduce任务进行运行,数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速相应给出结果,而且数据本身也不会频繁变化,2.本身提供一系列对数据进行提取,转换,加载(ETL)的工具,可以存储,查询和分析在Hadoop中大规模数据,这些工具能够很好地满足数据仓库各种应用场景
与传统数据库的对比

HIVE在企业大数据分析平台中的应用(一种)
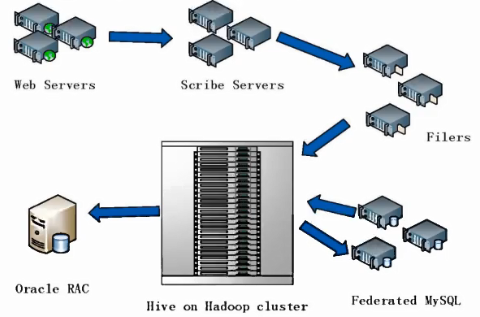
HIVE在Facebook公司中的应用:
- 基于Oracle的数据茶农库系统已经无法满足急诊的业务需求
- Facebook公司开发了数据库仓库工具HIVE,并在企业内部进行大量部署
HIVE系统架构:
- 用户接口模块包括CLI,HWI,JDBC,ODBC,Thrift Server
- 驱动模块(Driver)包括编译器,优化器,执行器等,负责把HiveQL语句转化成一系列MapReduce作业
- 元数据存储模块(Metastore)是一个独立的关系型数据库(自带derby数据库或者MySQL数据库)
SQL语句转化成MapReduce作业的基本原理
1.join的实现原理

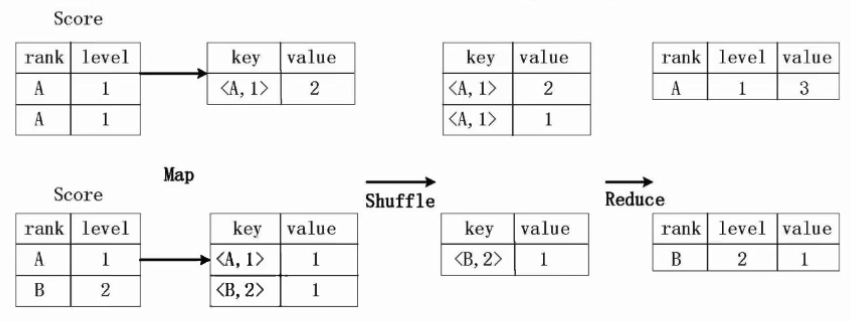
2.group by的实现原理
存在一个分组(Group By)操作,其功能是把Score的不同片段按照rank和level的组合值进行合并,计算不同的rank和level的组合值进行合并,计算不同的rank和level的组合值分别有几条记录:select rank,level,count(*)as value form score group by rank,level
HIVE中SQL查询转化成MapReduce作业的过程
- 当用户向hive输入一段命令或查询时,hive需要与Hadoop交互工作来完成该操作:
- 驱动模块接收该命令或查询编译器
- 对该命令或查询进行解析编译
- 由优化器对该命令或查询进行优化计算
- 该命令或查询通过执行器进行执行
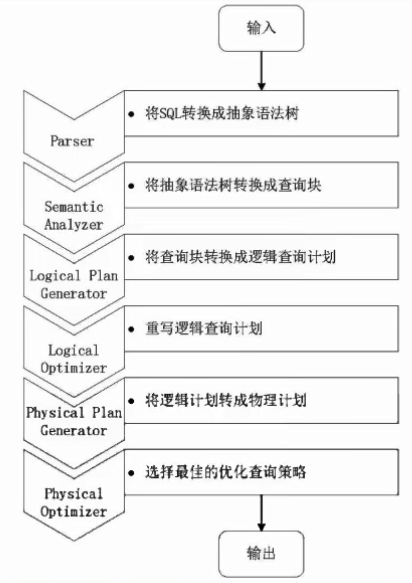
第1步:由Hive驱动模块中的编译器对用户输入的SQL语言进行词法和语法解析,将SQL语句转化为抽象语法树的形式
第2步:抽象语法树的结构仍很复杂,不方便直接翻译为MapReduce算法程序,因此,把抽象语法书转化为查询块
第3步:把查询块转换成逻辑查询计划,里面包含了许多逻辑操作符
第4步:重写逻辑查询计划,进行优化,合并多余操作,减少MapReduce任务数量
第5步:将逻辑操作符转换成需要执行的具体MapReduce任务
第6步:对生成的MapReduce任务进行优化,生成最终的MapReduce任务执行计划
第7步:由Hive驱动模块中的执行器,对最终的MapReduce任务进行执行输出
几点说明:
- 当启动MapReduce程序时,Hive本 身是不会生成MapReduce算法程序的需要通过一一个表示“Job执行计划”的XML文件驱动执行内置的、原生的Mapper和Reducer模块
- Hive通过和JobTracker通信来初始化MapReduce任务,不必直接部署在JobTracker所在的管理节点上执行
- 通常在大型集群上,会有专门的网关机来部署Hive工具。网关机的作用主要是远程操作和管理节点上的JobTracker通信来执行任务
- 数据文件通常存储在HDFS上,HDFS由名称节点管理
Hive HA基本原理
- 由多个Hive实例进行管理的,这些Hive实例奖杯纳入到一个资源池中,并由HAOrooxy提供一个统一的对外接口
- 对于程序开发人员来说,可以把它认为是一个超强“Hive”
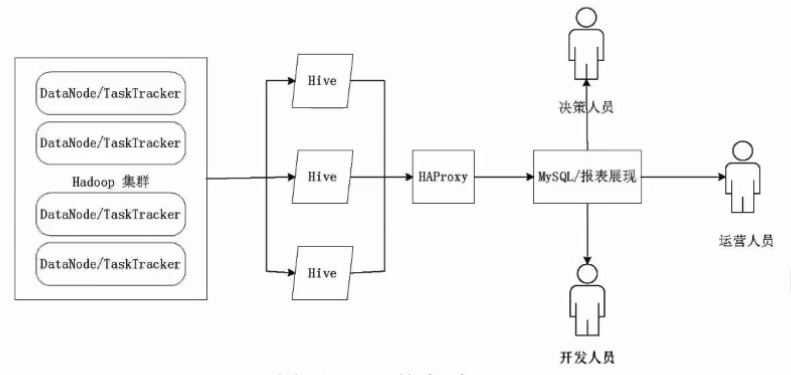
Impala
- Impala是由Cloudera公司开发的新型查询系统,它提供SQL予以,能查询储存在Hadoop的HDFS和HBase上的PB级大数据,在性能上比Hive高出3~30倍
- Impala的运行需要依赖于Hive的元数据
- Impala是参照Dremel系统进行设计的
- Impala采用了与商用并行关系数据库类似的分布式查询引擎,可以直接与HDFS和HBase进行交互查询
- Impala和Hive采用相同的SQL语法、ODBC驱动程序和用户接口
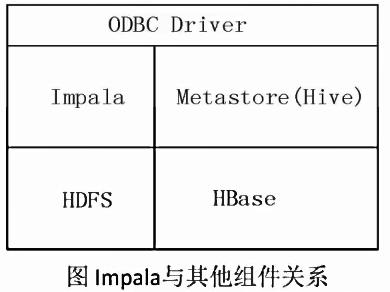
lmpala和Hive、HDFS、 HBase等工具是统一部署 在一-个Hadoop平台.上的Impala主要由Impalad, State Store和CLI三部分组成
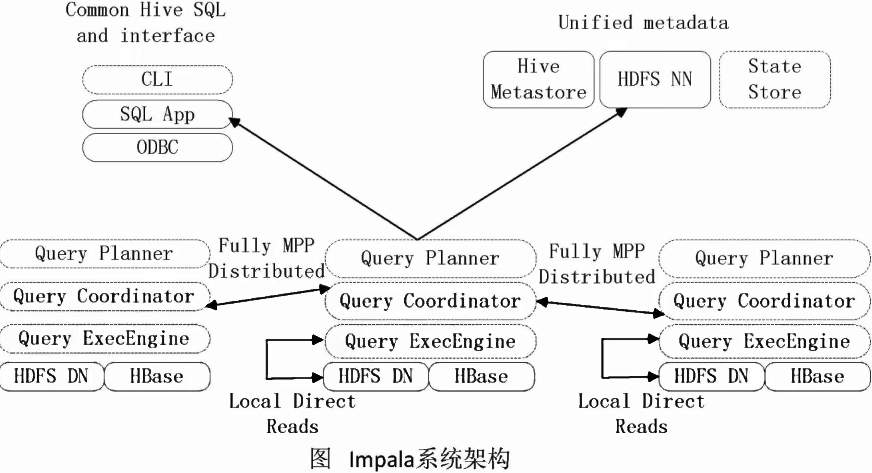
Impala主要是由Impalad,State Store和CLI三部分组成
- Impalad
- 负责协调客户端提交的查询的执行
- 包含Query Planner、 Query Coordinator和Query Exec Engine三个模块
- 与HDFS的数据节点(HDFS DN)运行在同一节点上
- 给其他Impalad分配任务以及收集其他Impalad的执行结果进行汇总
- Impalad也会执行其他Impalad给其分配的任务,主要就是对本地HDFS和HBase里的部分数据进行操作
2.State Store
- 会创建一个statestored进程
- 负责收集分布在集群中各个Impalad进程的资源信息,用于查询调度
3.CLI
- 给用户提供查询使用的命令行工具
- 还提供了Hue,JDBC以及ODBC的使用接口

Impala执行查询的具体过程:
- 第0步,当用户提交查询前,Impala先创建一个负责协调客户端提交的查询的Impalad进程,该进程会向Impala State Store提交注册订阅信息,State Store会创建一个statestored进程,statestored进 程通过创建多个线程来处理Impalad的注册订阅信息。
- 第1步,用户通过CLI客户端提交一个查询到impalad进程,Impalad 的Query Planner对SQL 语句进行解析,生成解析树;然后,Planner把这个查询的解析树变成若干P1 anFragment,发送到Query Coordinator
- 第2步,Coordinator 通过从MySQL元数据库中获取元数据,从HDFS的名称节点中获取数据地址,以得到存储这个查询相关数据的所有数据节点。
- 第3步,Coordinator初始化相应impalad上的任务执行,即把查询任务分配给所有存储这个查询相关数据的数据节点。
- 第4步,Query Executor 通过流式交换中间输出,并由Query Coord inator汇聚来自各个impalad的结果。
- 第5步,Coordinator把汇总后的结果返回给CLI客户端。
Hive和Impala不同点总结:
Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询
Hive依 赖于MapReduce计算框架,lmpala把执行计划表现为一棵完整的执行计划树,直接分发执行计划到各个Impalad执行查询
Hive在执行过程中, 如果内存放不下所有数据,则会使用外存,;以保证查询能顺序执行完成,而Impala在遇到内存放不下数据时,不会利用外存,所以Impala目 前处理查询时会受到一.定的限制
Hive和Impala相同点总结:
Hive与Impala使用相同的存储数据池,都支持把数据存储于HDFS和HBase中
Hive 与Impala使用相同的元数据3.Hive与Impala中对SQL的解释处理比较相似,都是通过词法分析生成执行计划
总结:
- lmpala的目的不在于替换现有的MapReduce工具
把Hive与Impala配合使用效果最佳
- 可以先使用Hive进行数据转换处理,之后再使用lmpala在Hive处理后的结果数据集_上进行快速的数据分析
大二暑假第六周总结--开始学习Hadoop基础(五)的更多相关文章
- 大二暑假第七周总结--开始学习Hadoop基础(六)
复习关于Hadoop的操作语句以及重点 Shell版 跳转目录到Hadoop: cd /usr/local/hadoop 启动Hadoop: ./sbin/start-dfs.sh 注意:Hadoop ...
- 大二暑假第三周总结--开始学习Hadoop基础(二)
简单学习NoSQL数据库理论知识 NoSQL数据库具有以下几个特点: 1.灵活的可扩展性(支持在多个节点上进行水平扩张) 2.灵活的数据模型(与关系数据库中严格的关系模型相反,显得较为松散) 3.与与 ...
- 大二暑假第二周总结--开始学习Hadoop基础(一)
一.简单视频学习Hadoop的处理架构 二.简单视频学习分布式文件系统HDFS并进行简单的实践操作 简单操作教程:http://dblab.xmu.edu.cn/blog/290-2/ 注意:在建立H ...
- 大二暑假第五周总结--开始学习Hadoop基础(四)
简单学习MapReduce并进行WordCount实践 分布式并行编程: MapReduce设计的一个理念就是“计算向数据靠拢”,将复杂的,运行于大规模集群上的并行计算过程高度地抽象到两个函数:Map ...
- 20145330第六周《Java学习笔记》
20145330第六周<Java学习笔记> . 这周算是很忙碌的一周.因为第六周陆续很多实验都开始进行,开始要准备和预习的科目日渐增多,对Java分配的时间不知不觉就减少了,然而第十和十一 ...
- 第六周—Alpha阶段项目复审(五饭来了吗)
第六周--Alpha阶段项目复审(五饭来了吗) 以下部分排名只是个人观点: 小组 优点 缺点,bug报告 名次 中午吃啥队 较完整的团体结构,可提供给商家和用户 感觉界面再优化一下就很棒了 1 天冷记 ...
- 20175215 2018-2019-2 第六周java课程学习总结
第七章 内部类与异常类 1.内部类 Java支持在一个类中定义另一个类,这样的类称作内部类,而包含内部类的类成为内部类的外嵌类 内部类和外嵌类之间重要关系如下 内部类的外嵌类的成员变量在内部类中仍然有 ...
- Pytorch_第六篇_深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数
深度学习 (DeepLearning) 基础 [2]---神经网络常用的损失函数 Introduce 在上一篇"深度学习 (DeepLearning) 基础 [1]---监督学习和无监督学习 ...
- 大二暑假第一周总结--初次安装配置Hadoop
本次配置主要使用的教程:http://dblab.xmu.edu.cn/blog/install-hadoop-in-centos/ 以下是自己在配置中的遇到的一些问题和解决方法,或者提示 一.使用虚 ...
随机推荐
- 「SDOI2015」寻宝游戏
传送门 Luogu 解题思路 发现一个性质: 对于所有的宝藏点 \({a_1,a_2...a_k}\) ,按照dfs序递增排列,答案就是: \(dis(a_1, a_2) + dis(a_2, a_3 ...
- JSP上传图片程序
1.下载相应的组件的最新版本 Commons FileUpload 可以在http://jakarta.apache.org/commons/fileupload/下载 附加的Commons IO ...
- ReadyBoost 的应用教程
一.什么是ReadyBoost 根据百度百科介绍,ReadyBoost是存在于Windows Vista中的一项新技术,在继Vista的下一代操作系统Windows 7中,同样包 含着这项技术,它利用 ...
- JAVA虚拟机:Java技术体系讲解(一)
按照Java系统的功能划分为: 一.Java语言,即使用Java编程语言进行软件开发. 二.开发过程中使用的工具和API(API(Application Programming Interface,应 ...
- Vue 实现分页效果
分页,是在业务中经常要用到,为了节省用户流量和提升用户体验 讲一下思路: 首先是定义页号currentPage 和 页大小pagesize,用一个数组保存总数据: 用一个计算属性page_arrs,作 ...
- 设备树DTS 学习:3-常用的DTS 函数
Linux内核中目前DTS相关的函数都是以of_前缀开头的,它们的实现位于内核源码的drivers/of下面 void __iomem*of_iomap(struct device_node *nod ...
- 初学微信小程序——配置问题(1)
一.注册: 微信小程序账号注册:登录https://mp.weixin.qq.com 点击“立即注册”->”小程序” 注册完成后,下载微信小程序开发者工具: 依次点击:“首页”->“文档 ...
- hostPath Volume【转】
hostPath Volume 的作用是将 Docker Host 文件系统中已经存在的目录 mount 给 Pod 的容器.大部分应用都不会使用 hostPath Volume,因为这实际上增加了 ...
- [U53204] 树上背包的优化
题目链接 本文旨在介绍树上背包的优化. 可见例题,例题中N,M∈[1,100000]N,M \in [1,100000]N,M∈[1,100000]的数据量让O(nm2)O(nm^2)O(nm2)的朴 ...
- Java开发程序员必须要学会的linux命令总结
查找文件 find / -name filename.txt 根据名称查找/目录下的filename.txt文件. find . -name "*.xml" 递归查找所有的xml文 ...