hadoop知识整理(5)之kafka
一、简介
来自官网介绍:
翻译:kafka,是一个分布式的流处理平台。LinkedIn公司开发。scala语言编写。
1、支持流处理的发布订阅模式,类似一个消息队列系统;
2、多备份存储,副本冗余机制,具备高容错性;
3、可以处理流。
二、使用
1、需要zk支持;
2、集群模式启动很简单,类似zk,只要在server.properties中指定broker.id即可;kafka定义每一个节点都为一个broker
3、启动后jps中存在Kafka进程;
4、启动命令中需指定配置文件:sh /kfaka安装目录/bin/kafka-server-start.sh /kafka安装目录/conf/指定的.properties
5、创建topic:sh kafka-topics.sh --create --zookeeper hadoop01,hadoop02,hadoop03:2181 --replication-factor 3 --partitions 3 --topic gjm1,其中,指定了zookeeper集群,制定了副本数量为3,副本数量不要大于节点,我这里有3个节点的kafka,分区数量也为3;
6、查看所有的topic:sh kafka-topics.sh --list --zookeeper hadoop01:2181
7、启动命令行的producer:sh kafka-console-producer.sh --broker-list hadoop01:9092 --topic gjm1
8、启动命令行的consumer:sh kafka-console-consumer.sh --zookeeper hadoop02:2181 --topic gjm1 --from-beginning,注意此中指定的是zk的访问地址,且将一开始的消息通通消费
9、jms之创建topic
@Test
public void create_topic(){
ZkUtils zkUtils = ZkUtils.apply("192.168.0.199:2181,192.168.0.200:2181,192.168.0.201:2181", 30000, 30000, JaasUtils.isZkSecurityEnabled());
// 创建一个单分区单副本名为t1的topic
AdminUtils.createTopic(zkUtils, "gjm2", 1, 1, new Properties(), RackAwareMode.Enforced$.MODULE$);
zkUtils.close();
}
10、jms之发送消息
@Test
public void producer() throws InterruptedException, ExecutionException{
Properties props=new Properties();
props.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.0.201:9092"); Producer<Integer, String> kafkaProducer = new KafkaProducer<Integer, String>(props);
for(int i=0;i<100;i++){
ProducerRecord<Integer, String> message = new ProducerRecord<Integer, String>("gjm2",""+i);
kafkaProducer.send(message);
}
//while(true);
}
11、jms之接收消息
@Test
public void consumer(){
Properties props = new Properties();
//--设置kafka的服务列表
props.put("bootstrap.servers", "192.168.0.201:9092");
//--指定当前的消费者属于哪个消费者组 g1是自己定的
props.put("group.id", "g1");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//--指定消费者消费的主题,可以指定多个
consumer.subscribe(Arrays.asList("gjm2"));
try {
while (true) {
//--消费者从分区队列中消费数据,用到poll阻塞方法,如果没有数据可以消费,则一直阻塞
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records)
System.out.println("g1组c1消费者,分区编号:"+record.partition()+"offset:"+record.offset() + ":" + record.value());
}
} catch (Exception e) {
} finally {
consumer.close();
}
}
12、jms之删除topic
@Test
public void delete_topic(){
ZkUtils zkUtils = ZkUtils.apply("192.168.0.199:2181,192.168.0.200:2181,192.168.0.201:2181", 30000, 30000, JaasUtils.isZkSecurityEnabled());
// 删除topic 't1'
AdminUtils.deleteTopic(zkUtils, "gjm2");
zkUtils.close();
}
三、主要原理
1、主要角色
1)producer:消息生产者
2)broker:服务器节点
3)topic:消息队列
4)partition:分区,物理概念,每个topic有若干个partition
5)consumer:消息消费者
6)consumer group:每个消费着属于一个group,每条消息只能被组里的一个consumer消费,但可以被多个consumer消费,组间数据共享,组内数据竞争
7)replication:partition副本,保证高可用
8)leader:replication中的角色,producer和consumer只跟leader交互
9)follower:同replication中的角色,从leader中复制数据
10)controller:kafka集群中的一个服务器,用来leader election以及failover
11)zk集群:存储kafka集群中的meta信息
2、partition的意义
1)一个topic可以存在多个partition;
2)增加partition可以使得kafka的吞吐率性能提升很大;
3)每个partition在物理上对应一个文件夹,文件夹下存储partition的所有的消息log和索引文件;
4)每条消息会append到对应的partition中,顺序写磁盘,效率很高。
3、producer写入消息流程
1)producer先从zk服务器的get /brokers/topics/gjm3/partitions/2/state找到partition的leader
2)producer将消息发送给leader
3)leader将消息写入本地log
4)follower从leader中poll消息,写入本地log,然后返回给leader的ack信息
5)leader收到ISR中的replication的ack后,增加HW,并向producer返回ack
ISR简述:假如,1、2、3有3个broker,1、3存日志数据成功,2存日志超时或者返回失败ack,那么1、3形成ISR,未来选举leader时会优先从ISR选出
6)producer写入数据完成。
4、consumer消费消息流程
(1)offset英文释义为抵消,在kafka种释义为偏移;
(2)kafka中,每个topic都可以有多个partition,每个partition对应了broker上的一个文件夹,其中有数据文件和索引文件等;
(3)当consumer大于partition数量时,有consumer处于不消费状态;
当consumer小于partition数量时,多个partition被consumer共享消费;
当consumer=partition时,达到最佳消费状态,并发正好合适;
(4)可以通过kafka自带的kafka-consumer-groups.sh工具查看每一个consumer消费情况:文档:
Checking consumer position
Sometimes it's useful to see the position of your consumers. We have a tool that will show the position of all consumers in a consumer group as well as how far behind the end of the log they are. To run this tool on a consumer group named my-group consuming a topic named my-topic would look like this:
1
2
3
4
5
6
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
my-topic 0 2 4 2 consumer-1-029af89c-873c-4751-a720-cefd41a669d6 /127.0.0.1 consumer-1
my-topic 1 2 3 1 consumer-1-029af89c-873c-4751-a720-cefd41a669d6 /127.0.0.1 consumer-1
my-topic 2 2 3 1 consumer-2-42c1abd4-e3b2-425d-a8bb-e1ea49b29bb2 /127.0.0.1 consumer-2
Managing Consumer Groups
With the ConsumerGroupCommand tool, we can list, describe, or delete the consumer groups. The consumer group can be deleted manually, or automatically when the last committed offset for that group expires. Manual deletion works only if the group does not have any active members. For example, to list all consumer groups across all topics:
1
2
3
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list test-consumer-group
To view offsets, as mentioned earlier, we "describe" the consumer group like this:
1
2
3
4
5
6
7
8
9
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
topic3 0 241019 395308 154289 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic2 1 520678 803288 282610 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic3 1 241018 398817 157799 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic1 0 854144 855809 1665 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1
topic2 0 460537 803290 342753 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1
topic3 2 243655 398812 155157 consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4
There are a number of additional "describe" options that can be used to provide more detailed information about a consumer group:
--members: This option provides the list of all active members in the consumer group.
1
2
3
4
5
6
7
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --members CONSUMER-ID HOST CLIENT-ID #PARTITIONS
consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1 2
consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4 1
consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 3
consumer3-ecea43e4-1f01-479f-8349-f9130b75d8ee /127.0.0.1 consumer3 0
--members --verbose: On top of the information reported by the "--members" options above, this option also provides the partitions assigned to each member.
1
2
3
4
5
6
7
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --members --verbose CONSUMER-ID HOST CLIENT-ID #PARTITIONS ASSIGNMENT
consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1 2 topic1(0), topic2(0)
consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4 1 topic3(2)
consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2 3 topic2(1), topic3(0,1)
consumer3-ecea43e4-1f01-479f-8349-f9130b75d8ee /127.0.0.1 consumer3 0 -
--offsets: This is the default describe option and provides the same output as the "--describe" option.
--state: This option provides useful group-level information.
1
2
3
4
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group --state COORDINATOR (ID) ASSIGNMENT-STRATEGY STATE #MEMBERS
localhost:9092 (0) range Stable 4
To manually delete one or multiple consumer groups, the "--delete" option can be used:
1
2
3
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --delete --group my-group --group my-other-group Deletion of requested consumer groups ('my-group', 'my-other-group') was successful.
To reset offsets of a consumer group, "--reset-offsets" option can be used. This option supports one consumer group at the time. It requires defining following scopes: --all-topics or --topic. One scope must be selected, unless you use '--from-file' scenario. Also, first make sure that the consumer instances are inactive. See KIP-122 for more details. It has 3 execution options: (default) to display which offsets to reset.
--execute : to execute --reset-offsets process.
--export : to export the results to a CSV format.
--reset-offsets also has following scenarios to choose from (atleast one scenario must be selected): --to-datetime <String: datetime> : Reset offsets to offsets from datetime. Format: 'YYYY-MM-DDTHH:mm:SS.sss'
--to-earliest : Reset offsets to earliest offset.
--to-latest : Reset offsets to latest offset.
--shift-by <Long: number-of-offsets> : Reset offsets shifting current offset by 'n', where 'n' can be positive or negative.
--from-file : Reset offsets to values defined in CSV file.
--to-current : Resets offsets to current offset.
--by-duration <String: duration> : Reset offsets to offset by duration from current timestamp. Format: 'PnDTnHnMnS'
--to-offset : Reset offsets to a specific offset.
Please note, that out of range offsets will be adjusted to available offset end. For example, if offset end is at 10 and offset shift request is of 15, then, offset at 10 will actually be selected.
For example, to reset offsets of a consumer group to the latest offset: 1
2
3
4
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --reset-offsets --group consumergroup1 --topic topic1 --to-latest TOPIC PARTITION NEW-OFFSET
topic1 0 0
If you are using the old high-level consumer and storing the group metadata in ZooKeeper (i.e. offsets.storage=zookeeper), pass --zookeeper instead of bootstrap-server: 1
> bin/kafka-consumer-groups.sh --zookeeper localhost:2181 --list
(5)关于consumer的rebanlence,前提是consumer在不停向broker发送心跳消息(轮询或者提交偏移量时),否则被认为异常
组成员变更,增加或者减少consumer
组订阅topic数量发生变更,增加了订阅的topic
组订阅topic的分区数发生了变更
kafka提供了3种再平衡策略
range,范围策略,每个分区按照顺序排列,将分区画成固定大小并依次分配给消费着
round-robin策略,把所有的topic的分区顺序分开,轮询地分配个消费着
sticky策略,极大限度地维持之前地分配方案
rebalance流程:
找到coordinator,收集所有的consumer,选举leader并指定分配方案,组内所有consumer向coordinator发送joinGroup请求,cd选举一个作为leader通常第一个,,leader为整个group成员制定方案;
将方案返回给所有的consumer,重新分配成功。
(6)当consumer消费完消息进行提交时,会提交offset,并且在offset上+1操作,offset保存了消费者读取到了paritition哪条消息,当下一次读取该parttition从哪条消息开始读。

5、kafka的HA
1)每一个partition可能都有多个replication;
2)在只有一个replication的情况下,一旦broker宕机,其上所有的partition都将无法被消费,不可用;
3)引入replication后,一个partition可能存在多个replication,这些replication中会存在一个leader,producer和consumer只与leader进行交互,其他replication作为follower从leader中复制数据;
4)ISR列表中保存了跟上leader操作的有哪些follower,当leader挂了之后,会从这些follower中选取新的leader,kafka并不需要过半性存活;
5)只要有一个replication存活,那么kafka可以在此情况之下保证消息不丢失;
6)但是当所有的replication都挂了之后,kafka提供了2种方案:
(1)等待ISR种的任意一个replication活过来,选它当leader,可保证数据不丢失,但是时间相对较长;
(2)选择第一个活过来的replication当leader,不一定是ISR成员,所以无法保证消息不丢失。
6、kafka零拷贝技术
1)设备可以通过直接内存访问DMA,方式访问kernal space;
2)没有零拷贝时的操作:当consumer从kafka消费数据时,kernal把数据从disj读取出来,然后把它传给user级别的application,然后application再次把同样的数据再传回属于kernal的socket,返回给所谓的consumer,这种情况之下,applcation(kafka)只是充当了一个中间介质,用来把disk file的data传输给socket;

3)所以,在操作系统内部这种操作太多,达到了4次之多,完全浪费时间;
4)其实,从kernal传给application,然后application再把data发送给kernal完全没有必要存在,application应该发送一个指令,使得kernal直接把data发送给网卡前的kernal的缓冲区;
5)所以,上一点说的就是zero copy技术,避免了在用户空间和内存空间的拷贝,提高了系统性能;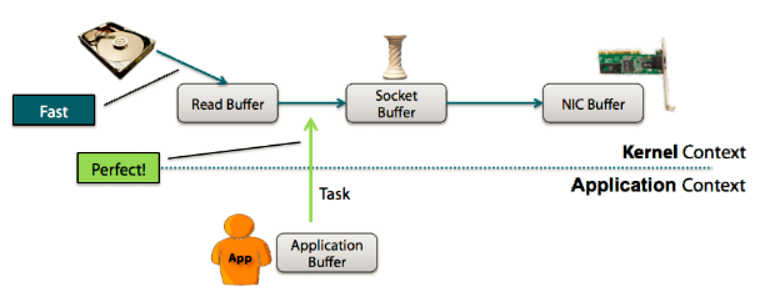
6)linux中的sendfile()以及java nio的FileChannel.transferTo()方法都实现了零拷贝功能,netty也封装了nio所以实现了零拷贝;
7、kafka索引机制
1)kafka既然可存储消息,那就必须解决查询效率问题,解决查询效率的通常办法就是建议索引;
2)log文件每1G生成一个新的,默认情况下,log文件的命名以文件中的第一条消息命名,每生成一个log文件,就会对应生成一个index文件;
3)首先文件名,可以通过2分法定位出在哪个文件中;
4)定位出文件之后,kafka为每个log文件建立了索引文件,index文件名字与log文件名字一致,只是后缀不同;
5)索引文件中记录了offset偏移量与position绝对文件中的位置对应关系;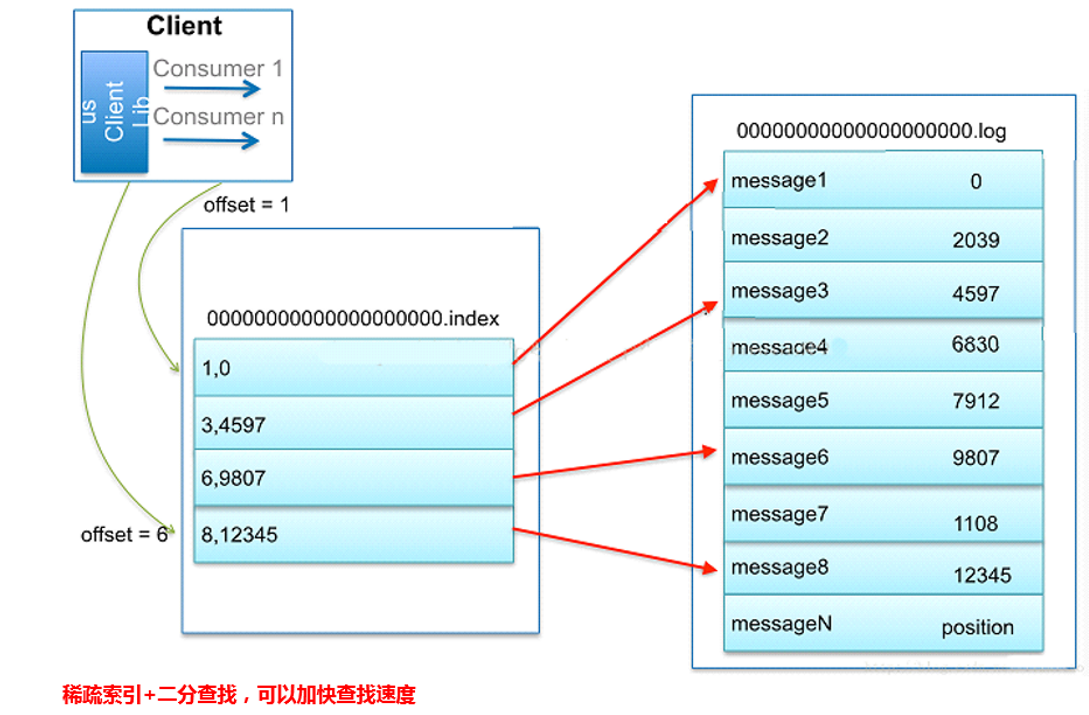
6)index中不会为每条消息建立索引,采用了稀疏索引的方式,通过二分查找的方式,快速地找到message位置;
7)这样index文件不会太大,就可以直接放在内存中,但在最末端查询的时候,也需要扫描一小段位置,但是范围极小;
8、kafka消息系统的语义
当producer生产消息到kafka或者consumer从kafka中消费消息时,会出现各种意外情况,比如网络突然出现波动,broker突然挂机,导致生产消息和消费消息失败,那么如何处理这样的失败情况,产生了不同的语义:
1)至少一次语义:at least once semantics
(1)当生产者收到了broker的ack,证明生产者的消息已经写入topic了;
(2)但是当生产者生产消息超时得不到broker的ack,或者收到了异常,producer会认为kafka写入topic消息失败;
(3)这时候,有可能kafka确实写入topic失败,但也有可能写成功,只是受到网络影响,ack未返回,那么producer的这个认为,会再次发送消息;
(4)所以这种情况下,consumer可能会收到重复消息;
2)至多一次语义:at most more semantics
(1)假如producer发一次消息给kafka,不管ack或者是否topic写入disk成功;
(2)那么只发送一次,就是至多一次,这样的情况是有可能发生consumer丢失消息的情况;
3)精确一次语义:exactly one semantics
(1)精确一次是在至少一次的情况下,虽然producer发送了多条重复消息,那么不管consumer在任何情况之下,都应该只消费1条精确的消息;
(2)精确一次是非常满意的保障,但实现也往往最复杂;
(3)比如,consumer成功消费一条消息后,又把消费的offset重置到之前的某个消息位置,显然会收到之前offset到现在offset的所有消息,所以需要客户端来配合;
实现:
(1)幂等性思想,执行多次任然是一次的结果;
(2)思路是producer给kafka发送消息时,给每一个消息增加一个序列号,此序列号全局递增,broker收到消息时,判断此id和已存储的最近消息的序列号比较,假如序列号相减=1那么存储下此条消息,如果序列号=0则放弃此条消息,>1则还有消息尚未到达,进行等待,如果<1那么同样说明已经处理过;
(3)在消费者端,设置processing.guarantee=exact_once保证消息只被消费一次;
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.150.137:9092,192.168.150.138:9092");
props.put("group.id", "g1");
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
props.put("enable.auto.commit", "false");
props.put("processing.guarantee","exact_once");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("enbook", "t2"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Long.MAX_VALUE);
for (ConsumerRecord<String, String> record : records) //--Process…… //--处理完成后,用户自己手动提交offset
consumer.commitAsync();
}
} catch (Exception e) {
} finally {
consumer.close();
}
hadoop知识整理(5)之kafka的更多相关文章
- 转:hadoop知识整理
文章来自于:http://tianhailong.com/hadoop%E7%9F%A5%E8%AF%86%E6%95%B4%E7%90%86.html 按照what.how.why整理了下文章,帮助 ...
- hadoop知识整理(4)之zookeeper
一.介绍 一个分布式协调服务框架: 一个精简的文件系统,每个节点大小最好不大于1MB: 众多hadoop组件依赖于此,比如hdfs,kafka,hbase,storm等: 旨在,分布式应用中,提供一个 ...
- hadoop知识整理(2)之MapReduce
之前写的关于MR的文章的前半部分已丢. 所以下面重点从3个部分来谈MR: 1)Job任务执行过程,以及主要进程-ResourceManager和NodeManager作用: 2)shuffle过程: ...
- hadoop知识整理(3)之MapReduce之代码编写
前面2篇文章知道了HDFS的存储原理,知道了上传和下载文件的过程,同样也知晓了MR任务的执行过程,以及部分代码也已经看到,那么下一步就是程序员最关注的关于MR的业务代码(这里不说太简单的): 一.关于 ...
- hadoop知识整理(1)之HDFS
一.HDFS是一个分布式文件系统 体系架构: hdfs主要包含了3部分,namenode.datanode和secondaryNameNode namenode主要作用和运行方式: 1)管理hdfs的 ...
- kafka知识整理
title: kafka知识整理 date: 2019-06-18 10:59:46 categories: MQ tags: kafka --- 转载自:https://www.cnblogs.co ...
- js事件(Event)知识整理
事件(Event)知识整理,本文由网上资料整理而来,需要的朋友可以参考下 鼠标事件 鼠标移动到目标元素上的那一刻,首先触发mouseover 之后如果光标继续在元素上移动,则不断触发mousemo ...
- Kali Linux渗透基础知识整理(四):维持访问
Kali Linux渗透基础知识整理系列文章回顾 维持访问 在获得了目标系统的访问权之后,攻击者需要进一步维持这一访问权限.使用木马程序.后门程序和rootkit来达到这一目的.维持访问是一种艺术形式 ...
- Kali Linux渗透基础知识整理(二)漏洞扫描
Kali Linux渗透基础知识整理系列文章回顾 漏洞扫描 网络流量 Nmap Hping3 Nessus whatweb DirBuster joomscan WPScan 网络流量 网络流量就是网 ...
随机推荐
- Java基础之抽象类和接口
今天来说说抽象类和接口的实现以及它们的区别.我们知道抽象类和接口都是对具体事物的抽象,接口在实现上比抽象类更加抽象,抽象类中可以有普通方法和变量,而接口中只有抽象方法和不可变常量.但是从另一个角度看, ...
- hadoop(hbase)副本数修改
一.需求场景 随着业务数据的快速增长,物理磁盘剩余空间告警,需要将数据备份从3份修改为1份,从而快速腾出可用磁盘容量. 二.解决方案 1. 修改hdfs的副本数 Hbase 的数据是存储在 hdfs ...
- Netty框架问题记录1--多线程下批量发送消息导致消息被覆盖
业务背景 项目是基于Netty实现的实时课堂项目,课堂中老师需要对试卷进行讲解,则老师向服务器发送一个打开试卷信息的请求,服务器获取试卷信息,将试卷信息发送给所有的客户端(学生和老师). 发送给学生的 ...
- charles 抓包iOS模拟器 HTTPS请求
参考: https://www.jianshu.com/p/3bfae9ede35e https://www.jianshu.com/p/171046d9f4f9 https://www.jiansh ...
- MySQL(9)— 规范数据库设计
九.规范数据库设计 9-1.为什么要设计? 当数据库比较复杂时,我们就需要设计了! 糟糕的数据库设计: 数据冗余,浪费大量存储空间 使用物理外键,大量的增删改操作麻烦,异常 查询效率低下 良好的数据库 ...
- Jmeter基础-HTTP请求
启动Jmeter 打开jmeter/bin文件/jmeter.bat(Windows执行文件)文件,就可以启动jmeter了 1.创建测试计划 启动后默认有一个TestPlan(测试计划),可修改其名 ...
- MySQL知识-MySQL同版本多实例的配置
MySQL多实例的配置 1. 创建需要目录 [root@db01 ~]# rm -rf /data/330{7..9}/data/*[root@db01 ~]# rm -rf /binlog/330{ ...
- Java基础语法--java中字符串比较中的坑点
Java 中两个字符串比较大小,可以有两种方式判定,要根据需求选择 == 判定,比较的是两个字符串的内存地址,地址相同则判定为true:反之则反 equals() 判定,比较的是两个字符串的内容,内容 ...
- vue中使用vue-qrcode生成二维码
要使用二维码,引入一个包就可以了,使用非常简单,话不多说,看代码吧 //1,引入, import VueQrcode from '@xkeshi/vue-qrcode'; Vue.component( ...
- 将`VuePress`建立的博客部署到GitHub或Gitee上
将VuePress建立的博客部署到GitHub或Gitee上 在上一篇中,我们详细介绍了如何利用VuePress搭建起个人博客系统,但这只是在本地debug启动的,接下来,我们把它部署到Github网 ...