入门大数据---ClouderaManager和CDH是什么?
1.CDH概述
CDH(Cloudra's Distribution Apache Of Hadoop)是Apache Hadoop和相关项目的最完整,经过测试和最流行的发行版。CDH提供Hadoop的核心要素–可扩展的存储和分布式计算–以及基于Web的用户界面和重要的企业功能。CDH是Apache许可的开源软件,并且是唯一提供统一批处理,交互式SQL和交互式搜索以及基于角色的访问控制的Hadoop解决方案。 一句话概括CDH就是集成多种技术的一个框架。
CDH提供
- 灵活性-存储任何类型的数据并使用各种不同的计算框架进行处理,包括批处理,交互式SQL,自由文本搜索,机器学习和统计计算。
- 集成-在可与广泛的硬件和软件解决方案一起使用的完整Hadoop平台上快速启动并运行。
- 安全性-处理和控制敏感数据。
- 可扩展性-启用广泛的应用程序并进行扩展,并扩展它们以满足您的要求。
- 高可用性-自信地执行关键任务业务任务。
- 兼容性-利用您现有的IT基础架构和投资。
Hadoop生态构成
- HDFS:分布式文件系统
- ZKFC:为实现NameNode高可用,在NameNode和Zookeeper之间传递信息,选举主节点工具。
- NameNode:存储文件元数据
- DateNode:存储具体数据
- JournalNode:同步主NameNode节点数据到从节点NameNode
- MapReduce:开源的分布式批处理计算框架
- Spark:分布式基于内存的批处理框架
- Zookeeper:分布式协调管理
- Yarn:调度资源管理器
- HBase:基于HDFS的NoSql列式数据库
- Hive:将SQL转换为MapReduce进行计算
- Hue:是CDH的一个UI框架
- Impala:是Cloudra公司开发的一个查询系统,类似于Hive,可以通过SQL执行任务,但是它不基于MapReduce算法,而是直接执行分布式计算,这样就提高了效率。
- oozie:是一个工作流调度引擎,负责将多个任务组合在一起按序执行。
- kudu:Apache Kudu是转为hadoop平台开发的列式存储管理器。和impala结合使用,可以进行增删改查。
- Sqoop:将hadoop和关系型数据库互相转移的工具。
- Flume:采集日志
- 还有一些其它的
CDH结构图
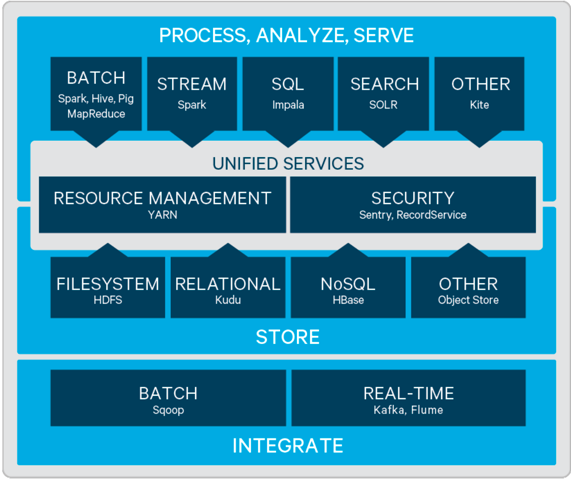
2.Cloudra Manager概述
Cloudra Manager简称CM,它是一个web操作平台,可以借助安装CDH然后安装多种Hadoop框架。
CloudraManager技术构成
Clients:客户端,通过web页面和ClouderaManager和服务器进行交互。
API:通过API和ClouderaManagement和服务器进行交互
Cloudera Repository:存储分发安装包
Management Server:进行监控和预警
Database:存储预警信息和配置信息。
Agent:分布在多台服务器,负责配置,启动和停止进程。监控主机。
结构图如下:
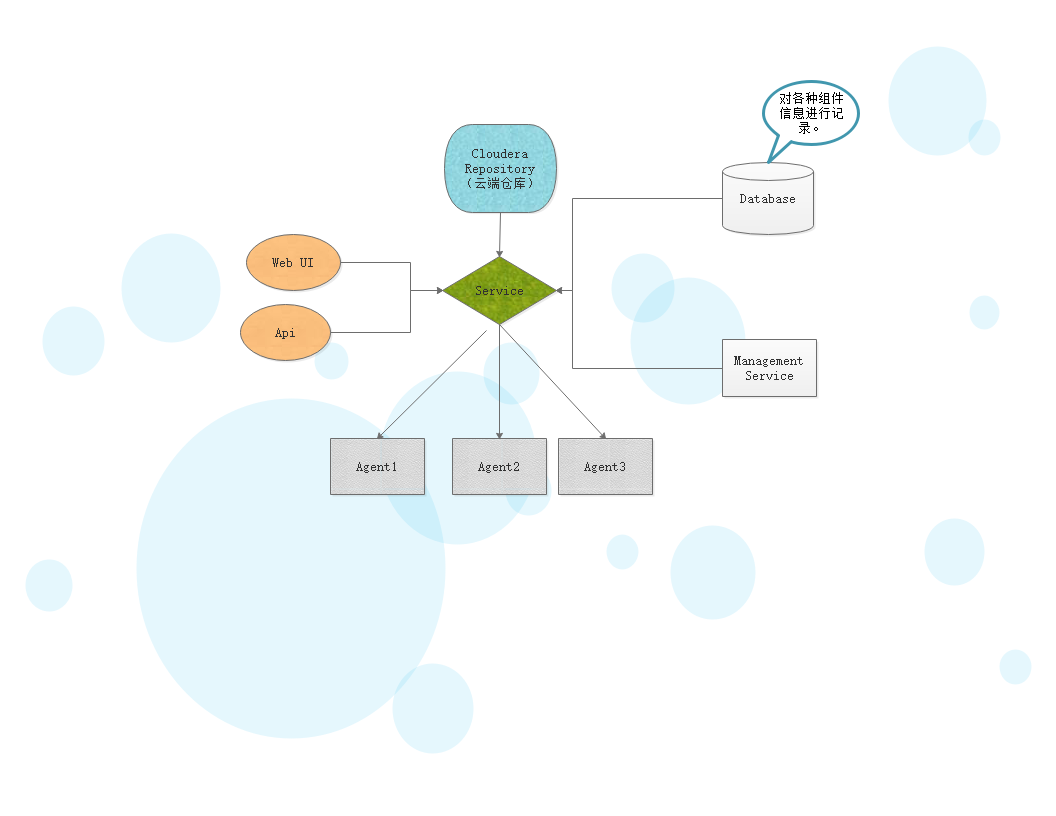
入门大数据---ClouderaManager和CDH是什么?的更多相关文章
- 入门大数据---安装ClouderaManager,CDH和Impala,Hue,oozie等服务
1.要求和支持的版本 (PS:我使用的环境,都用加粗标识了.) 1.1 支持的操作系统版本 操作系统 版本 RHEL/CentOS/OL with RHCK kernel 7.6, 7.5, 7.4, ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 入门大数据---Spark_Streaming整合Flume
一.简介 Apache Flume 是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中.Spark Straming 提供了以下两种方式用于 ...
- 入门大数据---SparkSQL外部数据源
一.简介 1.1 多数据源支持 Spark 支持以下六个核心数据源,同时 Spark 社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景. CSV JSON Parquet ORC JD ...
- 入门大数据---MapReduce-API操作
一.环境 Hadoop部署环境: Centos3.10.0-327.el7.x86_64 Hadoop2.6.5 Java1.8.0_221 代码运行环境: Windows 10 Hadoop 2.6 ...
- 入门大数据---Flume整合Kafka
一.背景 先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将 Flume 聚合 ...
- 入门大数据---Kylin是什么?
一.Kylin是什么? Apache Kylin是一个开源的.分布式的分析型数据仓库,提供Hadoop/Spark 上的SQL查询接口及多维度分析(OLAP)能力以支持超大规模的数据,最初由eBay开 ...
- 大数据学习系列之Hadoop、Spark学习线路(想入门大数据的童鞋,强烈推荐!)
申明:本文出自:http://www.cnblogs.com/zlslch/p/5448857.html(该博客干货较多) 1 Java基础: 视频方面: 推荐<毕向东JAVA ...
随机推荐
- itext7史上最全实战总结
1. itext7史上最全实战总结 1.1. 前言 最近有个需求需要我用Java手动写一份PDF报告,经过考察几种pdf开源代码,最终选取了itext7,此版本为7.1.11,由于发现网上关于该工具的 ...
- jchdl - GSL实例:FullAdder(使用HalfAdder实现)
https://mp.weixin.qq.com/s/5mcYAllizuxyr3QSNrotrw 全加器是能够计算低位进位的二进制加法电路.与半加器相比,全加器不只考虑本位计算结果是否有进位,也考虑 ...
- Java 异常(一) 异常概述及其架构
Java 异常(一) 异常概述及其架构 一.异常概述 (一).概述 Java异常是Java提供的一种识别及响应错误的一致性机制.异常指的是程序在执行过程中,出现的非正常的情况,最终会导致JVM的非正常 ...
- Java实现 LeetCode 24 两两交换链表中的节点
24. 两两交换链表中的节点 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表. 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换. 示例: 给定 1->2->3-&g ...
- java实现洛谷P3376【模板】网络最大流
题目描述 如题,给出一个网络图,以及其源点和汇点,求出其网络最大流. 输入格式 第一行包含四个正整数N.M.S.T,分别表示点的个数.有向边的个数.源点序号.汇点序号. 接下来M行每行包含三个正整数u ...
- Java实现第八届蓝桥杯迷宫
迷宫 题目描述 X星球的一处迷宫游乐场建在某个小山坡上. 它是由10x10相互连通的小房间组成的. 房间的地板上写着一个很大的字母. 我们假设玩家是面朝上坡的方向站立,则: L表示走到左边的房间, R ...
- java实现第四届蓝桥杯买不到的数目
买不到的数目 题目描述 小明开了一家糖果店.他别出心裁:把水果糖包成4颗一包和7颗一包的两种.糖果不能拆包卖. 小朋友来买糖的时候,他就用这两种包装来组合.当然有些糖果数目是无法组合出来的,比如要买 ...
- 2018年全国多校算法寒假训练营练习比赛(第二场)H-了断局
题目描述 既然是了断局了,大家就随便玩玩数字呗.已知一个数列前十项分别是{0, 1, 1, 2, 4, 7, 13, 24, 44, 81},小G不满足呀:我要更多的数!!!不给就不让你们玩了.小G会 ...
- 容器技术之Dockerfile(三)
前面我们聊到了dockerfile的 FROM.COPY .ADD.LABAL.MAINTAINER.ENV.ARG.WORKDIR.VOLUME.EXPOSE.RUN.CMD.ENTRYPOINT指 ...
- iOS-pthread && NSThread && iOS9网络适配
几个概念: 进程:"正在运行"应用程序(app)就是一个进程,它至少包含一个线程: 进程的作用:为应用程序开辟内存空间: 线程:CPU调度的最小单元: ...