备战秋招——C++知识点
1.字符串的末尾'\0'也算一个字符,一个字节。
2.使用库函数strcpy(a,b)进行拷贝b->a操作,strcpy会从源地址一直往后拷贝,直到遇到'\0'为止。所以拷贝的长度是不定的。如果一直没有遇到'\0'导致越界访问非法内存,程序就崩了。
3.strlen的结果未统计’\0’所占用的1个字节。
4.写出完整的strcpy函数
char * strcpy( char *strDest, const char *strSrc )
{
assert( (strDest != NULL) && (strSrc != NULL) );
char *address = strDest;
while( (*strDest++ = * strSrc++) != ‘\’ );
return address;
}
5.malloc和free要对应使用,防止内存泄漏
6.printf(str) 改为 printf("%s",str),否则可使用格式化 字符串攻击。printf会把str当成一个格式化字符串(formatstring),printf在其中寻找特殊的格式字符比如"%d"。如果碰到格式字符,一个变量的参数值就从堆栈中取出。很明显,攻击者至少可以通过打印出堆栈中的这些值来偷看程序的内存。
7.malloc之后应该对内存分配是否成功进行判断。free(p)之后应该把p=NULL,否则p会变成野指针。
8.浮点型变量并不精确,所以不可将float变量用“==”或“!=”与数字比较,应该设法转化成“>=”或“<=”形式。
9.数组名的本质如下:
(1)数组名指代一种数据结构,这种数据结构就是数组;
char str[];
cout << sizeof(str) << endl;
输出结果为10,str指代数据结构char[10]。
(2)数组名可以转换为指向其指代实体的指针,而且是一个指针常量,不能作自增、自减等操作,不能被修改;
char str[10];
str++; //编译出错,提示str不是左值
10.static关键字至少有下列n个作用:
(1)函数体内static变量的作用范围为该函数体,不同于auto变量,该变量的内存只被分配一次,因此这个静态变量的值在下次调用该函数时仍维持上次的值;
(2)在模块内的static全局变量可以被模块内所用函数访问,但不能被模块外其它函数访问;
(3)在模块内的static函数只可被这一模块内的其它函数调用,这个函数的使用范围被限制在声明它的模块内;
(4)在类中的static成员变量属于整个类所拥有,对类的所有对象只有一份拷贝;
(5)在类中的static成员函数属于整个类所拥有,这个函数不接收this指针,因而只能访问类的static成员变量。
11.const关键字至少有下列n个作用:
(1)欲阻止一个变量被改变,可以使用const关键字。在定义该const变量时,通常需要对它进行初始化,因为以后就没有机会再去改变它了; const int* p ;p指向的变量的值不能变。int* const p; p指向的东西不能变
(2)对指针来说,可以指定指针本身为const,也可以指定指针所指的数据为const,或二者同时指定为const;
(3)在一个函数声明中,const可以修饰形参,表明它是一个输入参数,在函数内部不能改变其值;
(4)对于类的成员函数,若指定其为const类型,则表明其是一个常函数,不能修改类的 成员变量;
(5)对于类的成员函数,有时候必须指定其返回值为const类型,以使得其返回值不为“左值”。例如:
const classA operator*(const classA& a1,const classA& a2);
operator*的返回结果必须是一个const对象。如果不是,这样的变态代码也不会编译出错:
classA a, b, c;
(a * b) = c; // 对a*b的结果赋值
操作(a * b) = c显然不符合编程者的初衷,也没有任何意义。
C++是面向对象的语言,而C是面向过程的结构化编程语言
语法上:
C++具有重载、继承和多态三种特性
C++相比C,增加多许多类型安全的功能,比如强制类型转换、
C++支持范式编程,比如模板类、函数模板等
C/C++ 中指针和引用的区别?
2.使用sizeof看一个指针的大小是4,而引用则是被引用对象的大小;
3.指针可以被初始化为NULL,而引用必须被初始化且必须是一个已有对象 的引用;
4.作为参数传递时,指针需要被解引用才可以对对象进行操作,而直接对引 用的修改都会改变引用所指向的对象;
5.可以有const指针,但是没有const引用;
6.指针在使用中可以指向其它对象,但是引用只能是一个对象的引用,不能 被改变;
7.指针可以有多级指针(**p),而引用至于一级;
8.指针和引用使用++运算符的意义不一样;
9.如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄露。
请你说一下你理解的c++中的smart pointer四个智能指针: shared_ptr,unique_ptr,weak_ptr,auto_ptr
1. auto_ptr(c++98的方案,cpp11已经抛弃)
采用所有权模式。
auto_ptr< string> p1 (new string ("I reigned lonely as a cloud.”));
auto_ptr<string> p2;
p2 = p1; //auto_ptr不会报错.
此时不会报错,p2剥夺了p1的所有权,但是当程序运行时访问p1将会报错。所以auto_ptr的缺点是:存在潜在的内存崩溃问题!
2. unique_ptr(替换auto_ptr)
unique_ptr实现独占式拥有或严格拥有概念,保证同一时间内只有一个智能指针可以指向该对象。它对于避免资源泄露(例如“以new创建对象后因为发生异常而忘记调用delete”)特别有用。
采用所有权模式,还是上面那个例子
unique_ptr<string> p3 (new string ("auto")); //#4
unique_ptr<string> p4; //#5
p4 = p3;//此时会报错!!
如果确实想执行类似的操作,要安全的重用这种指针,可给它赋新值。C++有一个标准库函数std::move(),让你能够将一个unique_ptr赋给另一个。例如:
unique_ptr<string> ps1, ps2;
ps1 = demo("hello");
ps2 = move(ps1);
ps1 = demo("alexia");
cout << *ps2 << *ps1 << endl;
3. shared_ptr
shared_ptr实现共享式拥有概念。多个智能指针可以指向相同对象,该对象和其相关资源会在“最后一个引用被销毁”时候释放。从名字share就可以看出了资源可以被多个指针共享,它使用计数机制来表明资源被几个指针共享。可以通过成员函数use_count()来查看资源的所有者个数。除了可以通过new来构造,还可以通过传入auto_ptr, unique_ptr,weak_ptr来构造。当我们调用release()时,当前指针会释放资源所有权,计数减一。当计数等于0时,资源会被释放。
shared_ptr 是为了解决 auto_ptr 在对象所有权上的局限性(auto_ptr 是独占的), 在使用引用计数的机制上提供了可以共享所有权的智能指针。
成员函数:
use_count 返回引用计数的个数
unique 返回是否是独占所有权( use_count 为 1)
swap 交换两个 shared_ptr 对象(即交换所拥有的对象)
reset 放弃内部对象的所有权或拥有对象的变更, 会引起原有对象的引用计数的减少
get 返回内部对象(指针), 由于已经重载了()方法, 因此和直接使用对象是一样的.如 shared_ptr<int> sp(new int(1)); sp 与 sp.get()是等价的
4. weak_ptr
weak_ptr 是一种不控制对象生命周期的智能指针, 它指向一个 shared_ptr 管理的对象. 进行该对象的内存管理的是那个强引用的 shared_ptr. weak_ptr只是提供了对管理对象的一个访问手段。weak_ptr 设计的目的是为配合 shared_ptr 而引入的一种智能指针来协助 shared_ptr 工作, 它只可以从一个 shared_ptr 或另一个 weak_ptr 对象构造, 它的构造和析构不会引起引用记数的增加或减少。weak_ptr是用来解决shared_ptr相互引用时的死锁问题,如果说两个shared_ptr相互引用,那么这两个指针的引用计数永远不可能下降为0,资源永远不会释放。它是对对象的一种弱引用,不会增加对象的引用计数,和shared_ptr之间可以相互转化,shared_ptr可以直接赋值给它,它可以通过调用lock函数来获得shared_ptr。
注意的是我们不能通过weak_ptr直接访问对象的方法,比如B对象中有一个方法print(),我们不能这样访问,pa->pb_->print(); 英文pb_是一个weak_ptr,应该先把它转化为shared_ptr,如:shared_ptr p = pa->pb_.lock(); p->print();
请回答一下数组和指针的区别
|
指针 |
数组 |
|
保存数据的地址 |
保存数据 |
|
间接访问数据,首先获得指针的内容,然后将其作为地址,从该地址中提取数据 |
直接访问数据, |
|
通常用于动态的数据结构 |
通常用于固定数目且数据类型相同的元素 |
|
通过Malloc分配内存,free释放内存 |
隐式的分配和删除 |
|
通常指向匿名数据,操作匿名函数 |
自身即为数据名 |
C++虚函数和虚函数表原理
虚表是属于类的,而不是属于某个具体的对象,一个类只需要一个虚表即可。同一个类的所有对象都使用同一个虚表。
为了指定对象的虚表,对象内部包含一个虚表的指针,来指向自己所使用的虚表。为了让每个包含虚表的类的对象都拥有一个虚表指针,编译器在类中添加了一个指针,*__vptr,用来指向虚表。这样,当类的对象在创建时便拥有了这个指针,且这个指针的值会自动被设置为指向类的虚表。
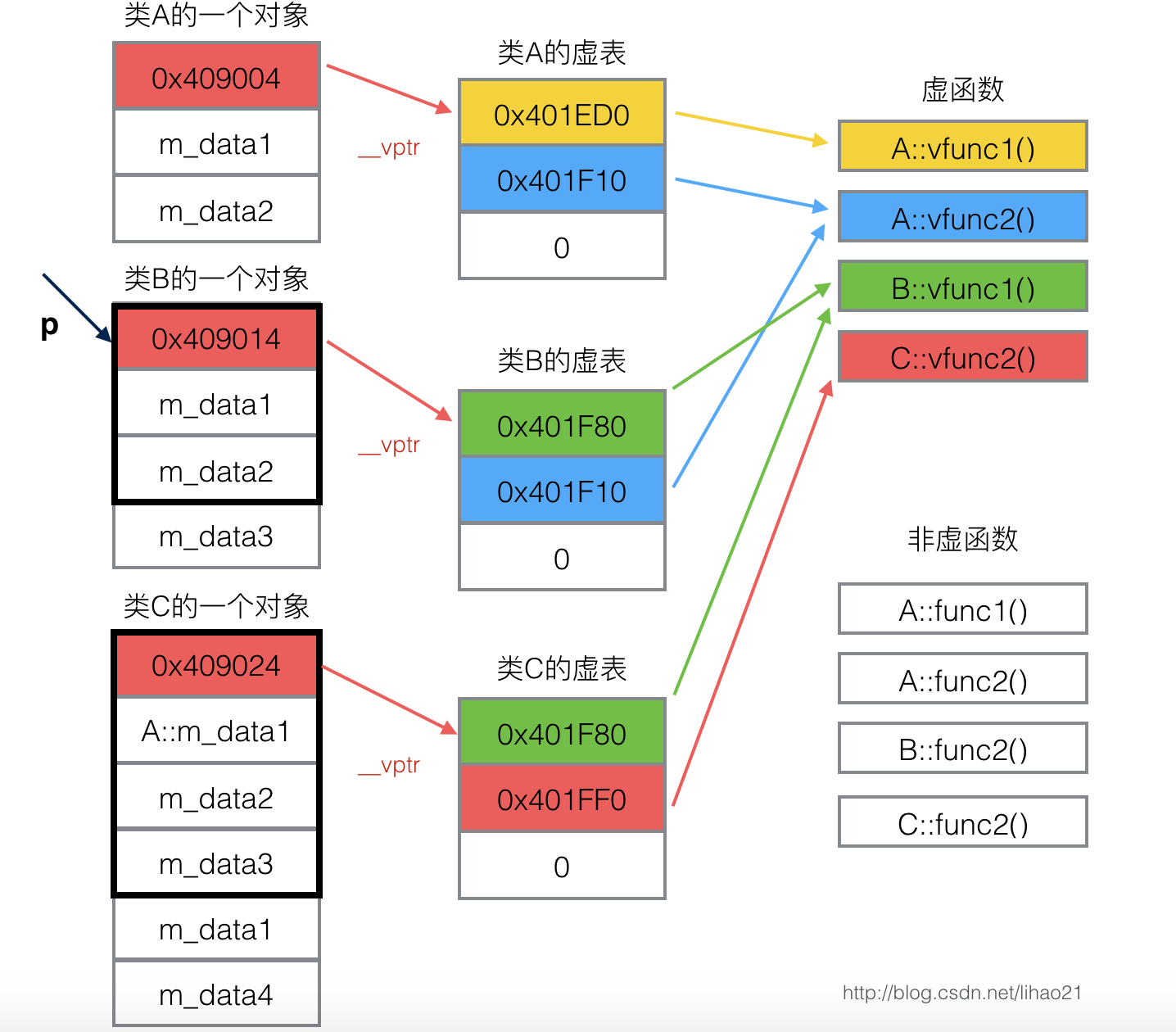
多继承情况下,派生类中有多个虚函数表,虚函数的排列方式和继承的顺序一致。派生类重写函数将会覆盖所有虚函数表的同名内容,派生类自定义新的虚函数将会在第一个类的虚函数表的后面进行扩充。
为什么析构函数必须是虚函数?为什么C++默认的析构函数不是虚函数
类析构顺序:1)派生类本身的析构函数;2)对象成员析构函数;3)基类析构函数。
C++默认的析构函数不是虚函数是因为虚函数需要额外的虚函数表和虚表指针,占用额外的内存。而对于不会被继承的类来说,其析构函数如果是虚函数,就会浪费内存。因此C++默认的析构函数不是虚函数,而是只有当需要当作父类时,设置为虚函数。
请你来说一下函数指针
函数指针是指向函数的指针变量。
函数指针本身首先是一个指针变量,该指针变量指向一个具体的函数。这正如用指针变量可指向整型变量、字符型、数组一样,这里是指向函数。
C在编译时,每一个函数都有一个入口地址,该入口地址就是函数指针所指向的地址。有了指向函数的指针变量后,可用该指针变量调用函数,就如同用指针变量可引用其他类型变量一样,在这些概念上是大体一致的。
2、用途:
调用函数和做函数的参数,比如回调函数。
3、示例:
char * fun(char * p) {…} // 函数fun
char * (*pf)(char * p); // 函数指针pf
pf = fun; // 函数指针pf指向函数fun
pf(p); // 通过函数指针pf调用函数fun
请你来说一下fork函数
#include <sys/types.h> #include <unistd.h> pid_t fork(void);
成功调用fork( )会创建一个新的进程,它几乎与调用fork( )的进程一模一样,这两个进程都会继续运行。在子进程中,成功的fork( )调用会返回0。在父进程中fork( )返回子进程的pid。如果出现错误,fork( )返回一个负值。
map和set有什么区别,分别又是怎么实现的?
请你来介绍一下STL的allocaotr
new运算分两个阶段:(1)调用::operator new配置内存;(2)调用对象构造函数构造对象内容
delete运算分两个阶段:(1)调用对象希构函数;(2)掉员工::operator delete释放内存
为了精密分工,STL allocator将两个阶段操作区分开来:内存配置有alloc::allocate()负责,内存释放由alloc::deallocate()负责;对象构造由::construct()负责,对象析构由::destroy()负责。
同时为了提升内存管理的效率,减少申请小内存造成的内存碎片问题,SGI STL采用了两级配置器,当分配的空间大小超过128B时,会使用第一级空间配置器;当分配的空间大小小于128B时,将使用第二级空间配置器。第一级空间配置器直接使用malloc()、realloc()、free()函数进行内存空间的分配和释放,而第二级空间配置器采用了内存池技术,通过空闲链表来管理内存。
C++中类成员的访问权限
C++中struct和class的区别
另外,class还可以定义模板类形参,比如template <class T, int i>。
C++中继承权限的区别
公有继承时基类中各成员属性保持不变,基类中private成员被隐藏。派生类的成员只能访问基类中的public/protected成员,而不能访问private成员;派生类的对象只能访问基类中的public成员。
私有继承时基类中各成员属性均变为private,并且基类中private成员被隐藏。派生类的成员也只能访问基类中的public/protected成员,而不能访问private成员;派生类的对象不能访问基类中的任何的成员。
保护继承时基类中各成员属性均变为protected,并且基类中private成员被隐藏。派生类的成员只能访问基类中的public/protected成员,而不能访问private成员;派生类的对象不能访问基类中的任何的成员。
//公有继承 对象访问 成员访问
public --> public Y Y
protected --> protected N Y
private --> private N N //保护继承 对象访问 成员访问
public --> protected N Y
protected --> protected N Y
private --> protected N N //私有继承 对象访问 成员访问
public --> private N Y
protected --> private N Y
private --> private N N
C++源文件从文本到可执行文件经历的过程?
预处理阶段:对源代码文件中文件包含关系(头文件)、预编译语句(宏定义)进行分析和替换,生成预编译文件。
编译阶段:将经过预处理后的预编译文件转换成特定汇编代码,生成汇编文件
汇编阶段:将编译阶段生成的汇编文件转化成机器码,生成可重定位目标文件
链接阶段:将多个目标文件及所需要的库连接成最终的可执行目标文件
include头文件的顺序以及双引号””和尖括号<>的区别?
Include头文件的顺序:对于include的头文件来说,如果在文件a.h中声明一个在文件b.h中定义的变量,而不引用b.h。那么要在a.c文件中引用b.h文件,并且要先引用b.h,后引用a.h,否则汇报变量类型未声明错误。
双引号和尖括号的区别:编译器预处理阶段查找头文件的路径不一样。
对于使用双引号包含的头文件,查找头文件路径的顺序为:
当前头文件目录
编译器设置的头文件路径(编译器可使用-I显式指定搜索路径)
系统变量CPLUS_INCLUDE_PATH/C_INCLUDE_PATH指定的头文件路径
对于使用尖括号包含的头文件,查找头文件的路径顺序为:
编译器设置的头文件路径(编译器可使用-I显式指定搜索路径)
系统变量CPLUS_INCLUDE_PATH/C_INCLUDE_PATH指定的头文件路径
malloc的原理,另外brk系统调用和mmap系统调用的作用分别是什么?
Malloc函数用于动态分配内存。为了减少内存碎片和系统调用的开销,malloc其采用内存池的方式,先申请大块内存作为堆区,然后将堆区分为多个内存块,以块作为内存管理的基本单位。当用户申请内存时,直接从堆区分配一块合适的空闲块。Malloc采用隐式链表结构将堆区分成连续的、大小不一的块,包含已分配块和未分配块;同时malloc采用显示链表结构来管理所有的空闲块,即使用一个双向链表将空闲块连接起来,每一个空闲块记录了一个连续的、未分配的地址。
当进行内存分配时,Malloc会通过隐式链表遍历所有的空闲块,选择满足要求的块进行分配;当进行内存合并时,malloc采用边界标记法,根据每个块的前后块是否已经分配来决定是否进行块合并。
Malloc在申请内存时,一般会通过brk或者mmap系统调用进行申请。其中当申请内存小于128K时,会使用系统函数brk在堆区中分配;而当申请内存大于128K时,会使用系统函数mmap在映射区分配。
C++的内存管理是怎样的?
在C++中,虚拟内存分为代码段、数据段、BSS段、堆区、文件映射区以及栈区六部分。
代码段:包括只读存储区和文本区,其中只读存储区存储字符串常量,文本区存储程序的机器代码。
数据段:存储程序中已初始化的全局变量和静态变量
bss 段:存储未初始化的全局变量和静态变量(局部+全局),以及所有被初始化为0的全局变量和静态变量。
堆区:调用new/malloc函数时在堆区动态分配内存,同时需要调用delete/free来手动释放申请的内存。
映射区:存储动态链接库以及调用mmap函数进行的文件映射
栈:使用栈空间存储函数的返回地址、参数、局部变量、返回值
C++/C的内存分配
什么时候会发生段错误
使用野指针
试图修改字符串常量的内容
什么是memory leak,也就是内存泄漏
内存泄漏的分类:
1. 堆内存泄漏 (Heap leak)。对内存指的是程序运行中根据需要分配通过malloc,realloc new等从堆中分配的一块内存,再是完成后必须通过调用对应的 free或者delete 删掉。如果程序的设计的错误导致这部分内存没有被释放,那么此后这块内存将不会被使用,就会产生Heap Leak.
2. 系统资源泄露(Resource Leak)。主要指程序使用系统分配的资源比如 Bitmap,handle ,SOCKET等没有使用相应的函数释放掉,导致系统资源的浪费,严重可导致系统效能降低,系统运行不稳定。
3. 没有将基类的析构函数定义为虚函数。当基类指针指向子类对象时,如果基类的析构函数不是virtual,那么子类的析构函数将不会被调用,子类的资源没有正确是释放,因此造成内存泄露。
new和malloc的区别
2、new返回的是指定对象的指针,而malloc返回的是void*,因此malloc的返回值一般都需要进行类型转化。
3、new不仅分配一段内存,而且会调用构造函数,malloc不会。
4、new分配的内存要用delete销毁,malloc要用free来销毁;delete销毁的时候会调用对象的析构函数,而free则不会。
5、new是一个操作符可以重载,malloc是一个库函数。
6、malloc分配的内存不够的时候,可以用realloc扩容。扩容的原理?new没用这样操作。
7、new如果分配失败了会抛出bad_malloc的异常,而malloc失败了会返回NULL。
8、申请数组时: new[]一次分配所有内存,多次调用构造函数,搭配使用delete[],delete[]多次调用析构函数,销毁数组中的每个对象。而malloc则只能sizeof(int) * n。
共享内存相关api
1)新建共享内存shmget
int shmget(key_t key,size_t size,int shmflg);
key:共享内存键值,可以理解为共享内存的唯一性标记。
size:共享内存大小
shmflag:创建进程和其他进程的读写权限标识。
返回值:相应的共享内存标识符,失败返回-1
2)连接共享内存到当前进程的地址空间shmat
void *shmat(int shm_id,const void *shm_addr,int shmflg);
shm_id:共享内存标识符
shm_addr:指定共享内存连接到当前进程的地址,通常为0,表示由系统来选择。
shmflg:标志位
返回值:指向共享内存第一个字节的指针,失败返回-1
3)当前进程分离共享内存shmdt
int shmdt(const void *shmaddr);
4)控制共享内存shmctl
和信号量的semctl函数类似,控制共享内存
int shmctl(int shm_id,int command,struct shmid_ds *buf);
shm_id:共享内存标识符
command: 有三个值
IPC_STAT:获取共享内存的状态,把共享内存的shmid_ds结构复制到buf中。
IPC_SET:设置共享内存的状态,把buf复制到共享内存的shmid_ds结构。
IPC_RMID:删除共享内存
buf:共享内存管理结构体。
请自己设计一下如何采用单线程的方式处理高并发
C++重载,重写与虚函数:
红黑树和AVL树的定义,特点,以及二者区别
平衡二叉树又称为AVL树,是一种特殊的二叉排序树。其左右子树都是平衡二叉树,且左右子树高度之差的绝对值不超过1。一句话表述为:以树中所有结点为根的树的左右子树高度之差的绝对值不超过1。将二叉树上结点的左子树深度减去右子树深度的值称为平衡因子BF,那么平衡二叉树上的所有结点的平衡因子只可能是-1、0和1。只要二叉树上有一个结点的平衡因子的绝对值大于1,则该二叉树就是不平衡的。
红黑树:
红黑树是一种二叉查找树,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(非红即黑)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,红黑树确保没有一条路径会比其它路径长出两倍,因此,红黑树是一种弱平衡二叉树,相对于要求严格的AVL树来说,它的旋转次数少,所以对于搜索,插入,删除操作较多的情况下,通常使用红黑树。
性质:
1. 每个节点非红即黑
2. 根节点是黑的;
3. 每个叶节点(叶节点即树尾端NULL指针或NULL节点)都是黑的;
4. 如果一个节点是红色的,则它的子节点必须是黑色的。
5. 对于任意节点而言,其到叶子点树NULL指针的每条路径都包含相同数目的黑节点;
区别:
AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance,导致效率下降;红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
红黑树较AVL树的优点:
AVL 树是高度平衡的,频繁的插入和删除,会引起频繁的rebalance,导致效率下降;红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
所以红黑树在查找,插入删除的性能都是O(logn),且性能稳定,所以STL里面很多结构包括map底层实现都是使用的红黑树。
map和unordered_map的底层实现
需要无序容器,快速查找删除,不担心略高的内存时用unordered_map;有序容器稳定查找删除效率,内存很在意时候用map。
对于map,其底层是基于红黑树实现的,优点如下:
1)有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
2)map的查找、删除、增加等一系列操作时间复杂度稳定,都为logn
缺点如下:
1)查找、删除、增加等操作平均时间复杂度较慢,与n相关
对于unordered_map来说,其底层是一个哈希表,优点如下:
查找、删除、添加的速度快,时间复杂度为常数级O(c)
缺点如下:
因为unordered_map内部基于哈希表,以(key,value)对的形式存储,因此空间占用率高
Unordered_map的查找、删除、添加的时间复杂度不稳定,平均为O(c),取决于哈希函数。极端情况下可能为O(n)
栈和堆的区别,以及为什么栈要快
堆是由低地址向高地址扩展;栈是由高地址向低地址扩展
堆中的内存需要手动申请和手动释放;栈中内存是由OS自动申请和自动释放,存放着参数、局部变量等内存
堆中频繁调用malloc和free,会产生内存碎片,降低程序效率;而栈由于其先进后出的特性,不会产生内存碎片
堆的分配效率较低,而栈的分配效率较高
栈的效率高的原因:
栈是操作系统提供的数据结构,计算机底层对栈提供了一系列支持:分配专门的寄存器存储栈的地址,压栈和入栈有专门的指令执行;而堆是由C/C++函数库提供的,机制复杂,需要一些列分配内存、合并内存和释放内存的算法,因此效率较低。
堆和栈的区别
栈由系统自动分配和管理,堆由程序员手动分配和管理。
2)效率:
栈由系统分配,速度快,不会有内存碎片。
堆由程序员分配,速度较慢,可能由于操作不当产生内存碎片。
3)扩展方向
栈从高地址向低地址进行扩展,堆由低地址向高地址进行扩展。
4)程序局部变量是使用的栈空间,new/malloc动态申请的内存是堆空间,函数调用时会进行形参和返回值的压栈出栈,也是用的栈空间。
Array&List, 数组和链表的区别
数组的优点:
1. 随机访问性强
2. 查找速度快
数组的缺点:
1. 插入和删除效率低
2. 可能浪费内存
3. 内存空间要求高,必须有足够的连续内存空间。
4. 数组大小固定,不能动态拓展
链表的优点:
1. 插入删除速度快
2. 内存利用率高,不会浪费内存
3. 大小没有固定,拓展很灵活。
链表的缺点:
不能随机查找,必须从第一个开始遍历,查找效率低
快排代码
第K大
各种排序
解决hash冲突的方法
开放定址法: 当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。
再哈希法:当发生哈希冲突时使用另一个哈希函数计算地址值,直到冲突不再发生。这种方法不易产生聚集,但是增加计算时间,同时需要准备许多哈希函数。
链地址法:将所有哈希值相同的Key通过链表存储。key按顺序插入到链表中
建立公共溢出区:采用一个溢出表存储产生冲突的关键字。如果公共溢出区还产生冲突,再采用处理冲突方法处理。
最长公共子串 and 最长公共连续子序列
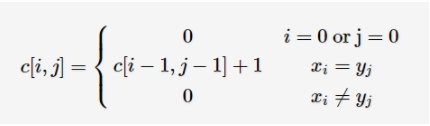
最长公共子串长度就为max{c[i][j]}了

最长回文子串
反转链表
设计模式
git中Merge和rebase区别
实现一个LRU cache
动态链接 静态链接
备战秋招——C++知识点的更多相关文章
- 备战秋招之十大排序——O(n)级排序算法
时间复杂度O(n)级排序算法 九.计数排序 前文说到,19591959 年 77 月,希尔排序通过交换非相邻元素,打破了 O(n^2)的魔咒,使得排序算法的时间复杂度降到了 O(nlog n) 级,此 ...
- 备战秋招之十大排序——O(nlogn)级排序算法
时间复杂度O(nlogn)级排序算法 五.希尔排序 首批将时间复杂度降到 O(n^2) 以下的算法之一.虽然原始的希尔排序最坏时间复杂度仍然是O(n^2),但经过优化的希尔排序可以达到 O(n^{1. ...
- 备战秋招之十大排序——O(n^2)级排序算法
一.冒泡排序 冒泡排序是入门级的算法,但也有一些有趣的玩法.通常来说,冒泡排序有三种写法: 一边比较一边向后两两交换,将最大值 / 最小值冒泡到最后一位: 经过优化的写法:使用一个变量记录当前轮次的比 ...
- Java秋招面经大合集
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 我的秋招经验分享(已拿BAT头条网易滴滴)
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- 【Java】几道常见的秋招面试题
前言 只有光头才能变强 Redis目前还在看,今天来分享一下我在秋招看过(遇到)的一些面试题(相对比较常见的) 0.final关键字 简要说一下final关键字,final可以用来修饰什么? 这题我是 ...
- 【Java】广州三本秋招经历
前言 只有光头才能变强 离上次发文章已经快两个月时间了,最近一直忙着秋招的事.今天是2018年10月22日,对于互联网行业来说,秋招就基本结束了.我这边的流程也走完了(不再笔试/面试了),所以来写写我 ...
- 2019秋招Java面经(未完待续)
2019秋招Java面经(凭记忆回忆, 可能不准) 随着我们从大三升到大四...秋招也开始了. 秋招进行的还比较顺利, 刚开始没几天, 我的秋招就结束了. 到现在我玩了差不多十多天了, 总想着总结一下 ...
- Leetcode - 剑指offer 面试题29:数组中出现次数超过一半的数字及其变形(腾讯2015秋招 编程题4)
剑指offer 面试题29:数组中出现次数超过一半的数字 提交网址: http://www.nowcoder.com/practice/e8a1b01a2df14cb2b228b30ee6a92163 ...
随机推荐
- 18.swoole学习笔记--案例
<?php //创建webSocket服务器 $ws=); //open $ws->on('open',function($ws,$request){ echo "新用户 $re ...
- 107-PHP类成员属性赋值
<?php class mao{ //定义猫类 public $age; //定义多个成员属性 protected $weight; private $color; } $mao1=new ma ...
- spring 动态bean注册
1. import org.springframework.beans.MutablePropertyValues; import org.springframework.beans.factory. ...
- js原型链理解(3)--构造借用继承
构造借用(constructor strealing) 1.为什么已经存在原型链继承还要去使用构造借用 首先看一下这个例子 function Super(){ this.sets = [0,1,2]; ...
- 面向对象第一个特征-封装(Encapsulation)
面向对象第一个特征-封装(Encapsulation) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.封装概述(Encapsulation) 1>.什么是封装 是指隐藏对 ...
- 1 - apicloud - str 字符串拼接技术
<body> <label>Hello APP</label> <div id='sys-info'></div></body> ...
- SpringCloud学习之Sleuth服务链路跟踪(十二)
一.为什么需要Spring Cloud Sleuth 微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元.由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很 ...
- Java生鲜电商平台-如何使用微服务来架构生鲜电商B2B2C平台?
Java生鲜电商平台-如何使用微服务来架构生鲜电商B2B2C平台? 说明:随着互联网的日益普及,人们通过手机下单买菜的人越来越多,生鲜这个行业有两个显著的特点,一个是刚需.(你每天都要吃饭,都要吃菜) ...
- 六、CI框架之分配变量
一.在controllers里面添加 $this->load->vars('m_Str1','我是一个字符串变量'); 二.在View中添加相应代码 界面显示效果如下: 不忘初心,如果您认 ...
- quartz详解3:quartz数据库集群-锁机制
http://blog.itpub.NET/11627468/viewspace-1764753/ 一.quartz数据库锁 其中,QRTZ_LOCKS就是Quartz集群实现同步机制的行锁表,其表结 ...