Kaggle 题目 nu-cs6220-assignment-1
Kaggle题目 nu-cs6220-assignment-1
题目地址如下:
https://www.kaggle.com/c/nu-cs6220-assignment-1/overview
这是个二分类任务,需要预测一个人的收入,分为两类:收入大于50K,或是小于50K。
1. 查看数据结构
下载数据后,先大致了解数据:
raw_data = load_data('nu-cs/training.txt')
raw_data.head()

可以看到没有header,根据题目对数据的说明,给它们分配header:
header = ['age', 'workclass', 'fnlwgt', 'education', 'education-num',
'marital-status', 'occupation', 'relationship', 'race', 'sex',
'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'salary'] raw_data.columns = header
raw_data.head()

在这个问题中,label为’salary’,这里它是一个离散变量,可以看到其中一个值是 ‘ <=50K’。进一步查看一下这个label包含的离散值:
raw_data['salary'].value_counts()

可以看到仅包含两类,且无缺失值或异常值。
继续查看数据集描述:
raw_data.info()

一共15个特征,6个为连续型,9个为离散型。数据条目为32560,每个特征均包含32560,但这个并不能说明数据集中没有缺失值,根据题目描述,缺失值已由 ? 代替。
2. 数值型特征
对于数值型特征,看一下统计数据:
raw_data.describe()
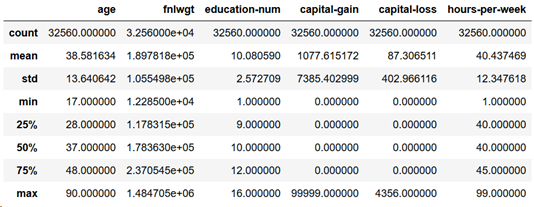
以及直方图:

结合这两组信息,我们可以看到有几点需要注意的地方:
- Capital-gain与capital-loss 大部分的值都是0,但是最大值却非常大,导致方差较大。
- 有些直方图是长尾分布,可以尝试将它们的分布转为钟型分布
- 部分特征需要进行分箱处理
下面先依次处理连续型变量。
2.1. Age特征
首先对于age特征,对它进行分箱并查看它们的相关性:
raw_data['age_band'] = pd.cut(raw_data['age'], 5)
raw_data[['age_band', 'salary']].groupby(['age_band'], as_index=False).mean().sort_values(by='age_band', ascending=True)

然后根据此分段,使用有序值替换 age 的值:
raw_data.loc[raw_data['age'] <= 31.6, 'age'] = 0
raw_data.loc[(raw_data['age'] <= 46.2) & (raw_data['age'] > 31.6), 'age'] = 1
raw_data.loc[(raw_data['age'] <= 60.8) & (raw_data['age'] > 46.2), 'age'] = 2
raw_data.loc[(raw_data['age'] <= 75.4) & (raw_data['age'] > 60.8), 'age'] = 3
raw_data.loc[(raw_data['age'] <= 90.0) & (raw_data['age'] > 75.4), 'age'] = 4
检查结果:
raw_data['age'].value_counts()
1 12210
0 11460
2 6558
3 2091
4 241 Name: age, dtype: int64
最后丢弃age_band 特征:
raw_data = raw_data.drop(['age_band'], axis=1)
raw_data.head()

2.2. fnlwgt特征
这个特征的问题在于:数值范围和方差都非常的大。
首先看它的直方图:
raw_data['fnlwgt'].hist(bins=100)
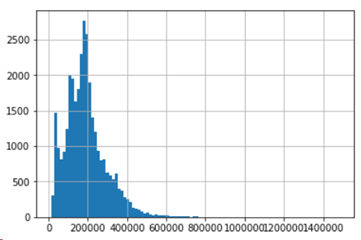
可以看到取值范围非常广,且类长尾分布。我们对它取对数,然后再观察它的直方图:
import numpy as np
raw_data['log_fnlwgt'] = raw_data['fnlwgt'].apply(np.log)
raw_data[['log_fnlwgt','fnlwgt']].hist(bins=100)
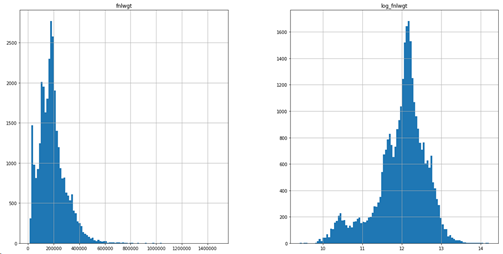
可以看到取对数后更接近钟型分布。最后,丢弃 log_fnlwgt,并直接在fnlwgt 上做变换:
raw_data.drop(['log_fnlwgt'], axis=1)
raw_data['fnlwgt'] = raw_data['fnlwgt'].apply(np.log)
2.3. Education-num
对于 education-num,它的取值虽然是数值型,但训练集中为有限集:
raw_data['education-num'].value_counts()
9 10501
10 7291
13 5354
14 1723
11 1382
7 1175
12 1067
6 933
4 646
15 576
5 514
8 433
16 413
3 333
2 168
1 51
Name: education-num, dtype: int64
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
同样对它使用区间量化,同 age 特征。过程在此不赘述,处理后的结果:
raw_data['education-num'].value_counts()
2 18225
3 7803
4 2712
1 2622
0 1198
Name: education-num, dtype: int64
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
2.4. capital-gain 与 capital-loss
raw_data[['capital-gain', 'capital-loss']].hist()
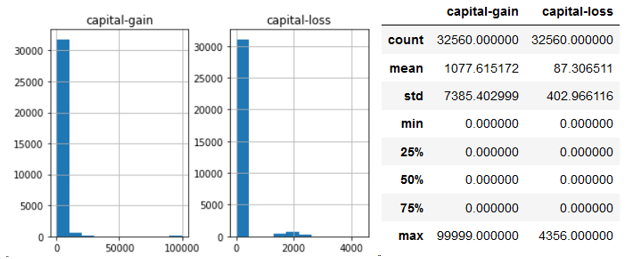
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
这两个特征的特点是:大部分值都为0,少部分值特别大。对这两个特征,采用二值化处理:
raw_data[['capital-gain', 'capital-loss']] = (raw_data[['capital-gain', 'capital-loss']] > 0) * 1
处理后结果为:
raw_data['capital-gain'].value_counts()
0 29849
1 2711
Name: capital-gain, dtype: int64 raw_data['capital-loss'].value_counts()
0 31041
1 1519
Name: capital-loss, dtype: int64
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
2.5. hours-per-week
此特征的图像类似为钟型分布,可以直接做标准化处理,或是做分桶处理均可,在此做了分桶处理,过程不追溯。
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
3. 离散特征
对于离散型特征,我们会用One-Hot 编码处理。首先我们清理缺失值:
workclass中存在 1836 条缺失值:
raw_data['workclass'].value_counts()
Private 22696
Self-emp-not-inc 2541
Local-gov 2093
? 1836
State-gov 1297
Self-emp-inc 1116
Federal-gov 960
Without-pay 14
Never-worked 7
Name: workclass, dtype: int64
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
occupation 中存在 1843 条缺失值:
raw_data['occupation'].value_counts()
Prof-specialty 4140
Craft-repair 4099
Exec-managerial 4066
Adm-clerical 3769
Sales 3650
Other-service 3295
Machine-op-inspct 2002
? 1843
Transport-moving 1597
Handlers-cleaners 1370
Farming-fishing 994
Tech-support 928
Protective-serv 649
Priv-house-serv 149
Armed-Forces 9
Name: occupation, dtype: int64
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
native-country 中存在583 条缺失值:
raw_data['native-country'].value_counts()
United-States 29169
Mexico 643
? 583
Philippines 198
…
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
对于这些缺失值,我们简单地使用众数来填充这个缺失值:
freq_workclass = raw_data.workclass.mode()[0]
raw_data.loc[(raw_data['workclass'] == ' ?'), 'workclass'] = freq_workclass freq_occupation = raw_data.occupation.mode()[0]
raw_data.loc[(raw_data['occupation'] == ' ?'), 'occupation'] = freq_workclass freq_nativecountry = raw_data['native-country'].mode()[0]
raw_data.loc[(raw_data['native-country'] == ' ?'), 'native-country'] = freq_nativecountry
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
补全缺失值后,我们可以对它们应用one-hot 编码。不过对于native-country 特征,里面包含的离散值类别过多,若是使用 one-hot 编码,则势必会造成特征维度大大增加。这里我们用更少的特征去对它们进行替换:
raw_data.loc[raw_data['native-country'] == ' Scotland', 'native-country'] = 'UK'
raw_data.loc[raw_data['native-country'] == ' United-States', 'native-country'] = 'US'
raw_data.loc[raw_data['native-country'] == ' Mexico', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Jamaica', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Philippines', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Germany', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' Canada', 'native-country'] = 'North-America'
raw_data.loc[raw_data['native-country'] == ' Puerto-Rico', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' El-Salvador', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' India', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Cuba', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' England', 'native-country'] = 'UK'
raw_data.loc[raw_data['native-country'] == ' Italy', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' Dominican-Republic', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Vietnam', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Guatemala', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Poland', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' Columbia', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Haiti', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Portugal', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' Greece', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' France', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' Ireland', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' Holand-Netherlands', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' China', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Japan', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Taiwan', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Hong', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Nicaragua', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Peru', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Ecuador', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Cambodia', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Thailand', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Laos', 'native-country'] = 'Asia'
raw_data.loc[raw_data['native-country'] == ' Trinadad&Tobago', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Yugoslavia', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' Honduras', 'native-country'] = 'South-America'
raw_data.loc[raw_data['native-country'] == ' Hungary', 'native-country'] = 'Euro'
raw_data.loc[raw_data['native-country'] == ' Iran', 'native-country'] = 'Middle-East'
raw_data.loc[raw_data['native-country'] == ' South', 'native-country'] = 'South-America' raw_data['native-country'].value_counts()
US 29752
South-America 1481
Asia 628
Euro 419
North-America 121
UK 102
Middle-East 43
Outlying-US(Guam-USVI-etc) 14
Name: native-country, dtype: int64
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
另一个可以进一步处理的特征是workclass,可以看到 workclass里的类别为:
Raw_data['workclass'].value_counts()
Private 24532
Self-emp-not-inc 2541
Local-gov 2093
State-gov 1297
Self-emp-inc 1116
Federal-gov 960
Without-pay 14
Never-worked 7
Name: workclass, dtype: int64
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
其中 Without-pay 与 Nerver-worked 数量都比较少,也意思接近,我们将它作为一个类别处理:
def change_workclass(df):
df.loc[df['workclass'] == ' Without-pay', 'workclass'] = 'No-pay'
df.loc[df['workclass'] == ' Never-worked', 'workclass'] = 'No-pay'
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
4. 数据中心化、标准化以及One-Hot编码
在连续性变量与离散型变量均处理完毕后,将特征数据与label数据分离:
def get_data_label(df, label):
dataset = df.drop(label, axis=1)
labels = df[label].copy()
return dataset, labels dataset, labels = get_data_label(raw_data, 'salary')
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
然后分别对数值型做中心化与标准化,离散值做one-hot编码:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer num_pipeline = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('std_scaler', StandardScaler()),
]) full_pipeline = ColumnTransformer([
('num', num_pipeline, num_attributes),
('cat', OneHotEncoder(), cat_attributes),
]) nu_cs_prepared = full_pipeline.fit_transform(dataset)
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
模型训练
首先我们用sk-learn提供的几个模型训练:
from sklearn.model_selection import cross_val_score
cross_val_score(tree_clf, nu_cs_prepared, labels, cv=10, scoring='accuracy')
array([0.77955173, 0.78194103, 0.78961916, 0.77610565, 0.79299754,
0.7779484 , 0.78808354, 0.79207617, 0.79391892, 0.77695853]) from sklearn.svm import LinearSVC
svm_clf = LinearSVC(C=3, loss="hinge")
cross_val_score(svm_clf, nu_cs_prepared, labels, cv=10, scoring='accuracy')
array([0.83911575, 0.83814496, 0.84520885, 0.82800983, 0.84029484,
0.84459459, 0.83630221, 0.84735872, 0.84490172, 0.83870968]) # logistic regression
logreg = LogisticRegression()
cross_val_score(logreg, nu_cs_prepared, labels, cv=10, scoring='accuracy')
array([0.84280012, 0.84029484, 0.84981572, 0.83169533, 0.84398034,
0.84797297, 0.84029484, 0.8470516 , 0.85104423, 0.84423963]) from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1)
cross_val_score(rnd_clf, nu_cs_prepared, labels, cv=10, scoring='accuracy')
array([0.82222905, 0.82493857, 0.83015971, 0.82340295, 0.82831695,
0.82985258, 0.82186732, 0.83476658, 0.8252457 , 0.82519201])
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
可以看到表现最好的是SVM和LR。下面选择SVM,进行超参数搜索:
from sklearn.model_selection import GridSearchCV param_grid = [
{'C':[1, 3, 10, 30], 'loss':['hinge'], 'dual':[True]}
] svm_clf = LinearSVC()
grid_search = GridSearchCV(svm_clf, param_grid, cv=5,
scoring='accuracy',
return_train_score=True) grid_search.fit(nu_cs_prepared, labels) grid_search.best_estimator_
LinearSVC(C=30, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='hinge', max_iter=1000, multi_class='ovr',
penalty='l2', random_state=None, tol=0.0001, verbose=0)
grid_search.best_score_
0.832063882063882
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
可以看到最好的模型C=30(所以还可以往上调整C进一步搜索),此时的准确率为83%,但仍比不上 LR 的准确率。
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
再试试对随机森林的超参数搜索:
from sklearn.model_selection import GridSearchCV param_grid = [
{'n_estimators':[3, 10, 30], 'max_features':[2, 4, 6, 8]},
{'bootstrap':[False], 'n_estimators':[3, 10], 'max_features':[2, 3, 4]},
] forest_clf = RandomForestClassifier()
grid_search = GridSearchCV(forest_clf, param_grid, cv=5,
scoring='accuracy',
return_train_score=True) grid_search.fit(nu_cs_prepared, labels)
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
表现最好的参数为:
grid_search.best_params_
{'max_features': 8, 'n_estimators': 30}
最高分为:
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
0.8196253071253071
Normal
0
false
false
false
EN-US
ZH-CN
X-NONE
/* Style Definitions */
table.MsoNormalTable
{mso-style-name:"Table Normal";
mso-tstyle-rowband-size:0;
mso-tstyle-colband-size:0;
mso-style-noshow:yes;
mso-style-priority:99;
mso-style-parent:"";
mso-padding-alt:0in 5.4pt 0in 5.4pt;
mso-para-margin-top:0in;
mso-para-margin-right:0in;
mso-para-margin-bottom:8.0pt;
mso-para-margin-left:0in;
line-height:107%;
mso-pagination:widow-orphan;
font-size:11.0pt;
font-family:"Calibri",sans-serif;
mso-ascii-font-family:Calibri;
mso-ascii-theme-font:minor-latin;
mso-hansi-font-family:Calibri;
mso-hansi-theme-font:minor-latin;
mso-bidi-font-family:"Times New Roman";
mso-bidi-theme-font:minor-bidi;}
效果仍逊色于LR 的平均0.84 左右,下一章再试试 sagemaker 对模型进行训练。
Kaggle 题目 nu-cs6220-assignment-1的更多相关文章
- Kaggle比赛:从何着手?
介绍 参加Kaggle比赛,我必须有哪些技能呢? 你有没有面对过这样的问题?最少在我大二的时候,我有过.过去我仅仅想象Kaggle比赛的困难度,我就感觉害怕.这种恐惧跟我怕水的感觉相似.怕水,让我无法 ...
- HDU - 5289 Assignment (RMQ+二分)(单调队列)
题目链接: Assignment 题意: 给出一个数列,问其中存在多少连续子序列,使得子序列的最大值-最小值<k. 题解: RMQ先处理出每个区间的最大值和最小值(复杂度为:n×logn),相 ...
- Algorithms : Programming Assignment 3: Pattern Recognition
Programming Assignment 3: Pattern Recognition 1.题目重述 原题目:Programming Assignment 3: Pattern Recogniti ...
- HDOJ 题目5289 Assignment(RMQ,技巧)
Assignment Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Total ...
- 试试看 ? 离奇古怪的javascript题目
来源地址: http://dmitrysoshnikov.com/ecmascript/the-quiz/#q1 另一篇帖子 看看国外的javascript题目,你能全部做对吗? http://www ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- 准备熟悉Kaggle -菜鸟进阶
原文链接http://www.bubuko.com/infodetail-525389.html 1.Kaggle简介 Kaggle是一个数据分析的竞赛平台,网址:https://www.kaggle ...
- NYOJ题目77开灯问题
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAsUAAAHXCAIAAADbX7BCAAAgAElEQVR4nO3dvVLrSMAm4L0Jci6E2B
- HITOJ 2662 Pieces Assignment(状压DP)
Pieces Assignment My Tags (Edit) Source : zhouguyue Time limit : 1 sec Memory limit : 64 M S ...
随机推荐
- 路由配置(route IP
转载于:http://blog.csdn.net/chenlycly/article/details/52141854 使用下面的 route 命令可以查看 Linux 内核路由表. # route ...
- tmux的基本用法
tmux的基本用法: tmux #启动 C-b d #挂起,效果如同screen中的C-a d tmux attach #恢复会话,效果如同screen中的screen -r 更多功能(需要在tmux ...
- WEB 安全 - xss 初探
零.参考资料 网络攻击-XSS攻击详解: 前端安全之XSS攻击: 一.概念 跨站脚本攻击Cross-site scripting (XSS)是一种安全漏洞,攻击者可以利用这种漏洞在网站上注入恶意的客户 ...
- 读书笔记之 数字图像处理的MATLAB实现(第2版)
- TNS-04612: "orcl--117-118" 的 RHS 为空
安装数据库时,TNS-04612: "orcl--117-118" 的 RHS 为空 解决办法: 把 D:\app\xxx\product\11.2.0\dbhome_1\NETW ...
- python基础 生成器 迭代器
列表生成式: a=[1,2,3] print a b=[i*2 for i in range(10)] #i循环10次,每一个i的值乘2就是列表中的值.列表生成式 print b >>[1 ...
- js中判断为false的情况
document.write((new Boolean())+"<br />"); document.write((new Boolean(" ...
- SpringMVC之springmvc原始api,请求中文乱码问题
先搞一波效果图 1.Controller package com.tz.controller; import javax.servlet.http.HttpServlet; import javax ...
- Flask向模板中JS传值简便方式
后台传值: return render_template('statistics/numberofuserlogin/login_number.html', result_json = json.du ...
- React中key的讲解
通过阅读React的文档我们知道React这个框架的核心思想是,将页面分割成一个个组件,一个组件还可能嵌套更小的组件,每个组件有自己的数据(属性/状态);当某个组件的数据发生变化时,更新该组件部分的视 ...