高性能MySQL笔记 第5章 创建高性能的索引
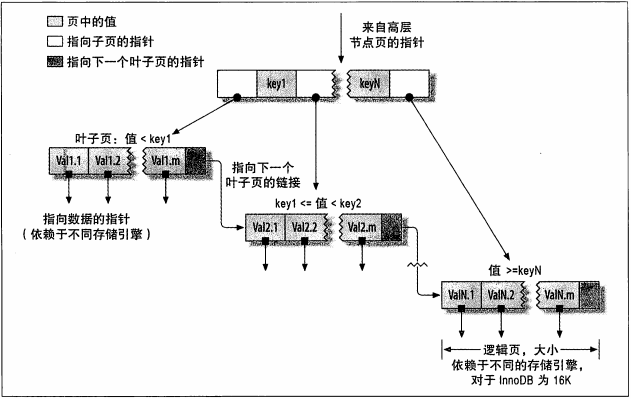
.png) 索引(index),在MySQL中也被叫做键(key),是存储引擎用于快速找到记录的一种数据结构。索引优化是对查询性能优化最有效的手段。
索引(index),在MySQL中也被叫做键(key),是存储引擎用于快速找到记录的一种数据结构。索引优化是对查询性能优化最有效的手段。- 全值匹配:是指和索引中的所有列进行匹配。
- 匹配最左前缀:即只使用索引的第一列。
- 匹配列前缀:即只使用索引第一列的开头部分。
- 匹配范围值:只使用了索引的第一列。
- 精确匹配某个列并范围匹配另外一列:即索引第一列全匹配,第二列范围匹配。
- 只访问索引的查询:又被称为“覆盖索引”,B-tree通常支持“只访问索引的查询”,即查询只需要访问索引,而无须访问数据行。如用户名与密码的匹配,手机号与验证码的匹配。
- 如果不是按照索引的最左列开始查找,则无法使用索引。
- 不能跳过索引中的列。
- 如果查询中有某个列的范围查询,则其右边所有列都无法使用索引。
- 索引大大减少了服务器需要扫描的数据量;
- 索引可以帮助服务器避免排序和临时表;
- 索引可以将随机I/O变为顺序I/O;
- 索引相关记录放在一起则获得一星;
- 索引中的数据顺序和查找中的排序顺序一致则获得二星;
- 索引中的列包含了查询中需要的全部列则获取三星;
- 当出现服务器对多个索引做相交操作时(通常有多个and条件),通常意味着需要一个包含所有香港列的多列索引,而不是多个独立的单列索引。
- 当服务器需要对多个索引做联合操作时(通常有多个or条件),通常需要消耗大量CPU和内存资源在算法的缓存、排序和合并操作上。特别是当其中有些索引的选择性不高,需要合并扫描返回的大量数据的时候。
- 更重要的是,优化器不会把这些计算到“查询成本”(cost)中,优化器只关心随机页面读取。这会使得查询的成本被“低估”,还可能会影响查询的并发性,但如果是单独运行这样的查询则往往会忽略对并发性的影响。
.png)
- 可以把相关数据保存在一起。
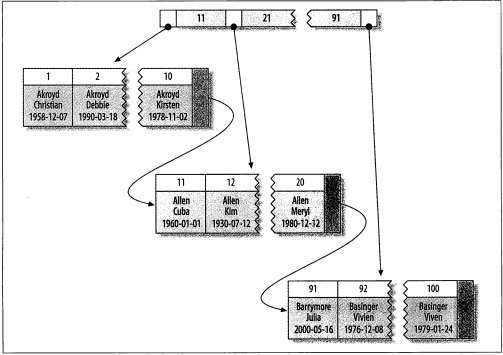
- 数据访问更快。聚簇索引将索引和数据保存在同一个B-Tree中,因此从聚簇索引中获取数据通常比在非聚簇索引中查找要快。
- 使用覆盖索引扫描的查询可以直接使用叶节点的主键值。
- 聚簇数据最大限度地提高了IO密集型应用的性能。但如果数据全部都放在内存中,则访问的顺序就没那么重要了,聚簇索引也就没了优势。
- 插入速度严重依赖插入顺序,按照主键的顺序是加载数据到InnoDB表中速度最快的方式。但如果不是按照主键顺序加载数据,那么在加载完成后最好使用optimize table命令重新组织一下表。
- 更新聚簇索引列的代价很高,因为会强制InnoDB将每个被更新的行移动到新的位置。
- 基于聚簇索引的表在插入新行,或者主键被更新导致需要移动行的时候,可能面临“页分裂”(page split)的问题。当行的主键值要求必须将这一行插入到某个已满的页中时,存储引擎会将该页分裂成两个页面来容纳该行,这就是一次页分裂操作。页分裂会导致表占用更多的磁盘空间。
- 聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。
- 二级索引(非聚簇索引)可能比想象的要更大,因为在二级索引的叶子节点包含了引用行的主键列。
- 二次索引访问需要两次索引查找,而不是一次。这是因为二级索引中保存的“行指针”的实质。二级索引叶子节点保存的不是指向行的物理位置的指针,而是行的主键值。通过二级索引查找行,存储引擎需要找到二级索引的叶子节点获得对应的主键值,然后根据这个值取聚簇索引中查找到对应的行。
- 索引条目通常远小于数据行大小,所以如果只需要读取索引,那MySQL就会极大地减少数据访问量。这对缓存的负载非常重要,因为这种情况下响应时间大部分花费在数据拷贝上。覆盖索引对于IO密集型的应用也有帮助,因为索引比数据更小,更容易全部放入内存中。
- 因为索引是按照列值顺序存储的(至少在单个数据页内是如此)所以对于IO密集型的范围查询会比随机从磁盘读取每一行数据的IO要少得多。
- 由于InnoDB的聚簇索引,覆盖索引对InnoDB表特别有用。InnoDB的二级索引在叶子节点中保存了行的主键值,所以如果二级索引能够覆盖查询,则可以比main对主键索引的二次查询。
| 排序 | 是否使用了索引扫描来做排序 |
| ORDER BY a | yes |
| ORDER BY a, b | yes |
| ORDER BY a, b desc | no |
| WHERE a = 1 ORDER BY b | yes |
| WHERE a > 1 ORDER BY a, b | yes |
| WHERE a =1 ORDER BY b, c | no |
| WHERE a > 1 ORDER BY b | no |
- 单行访问是很慢的。特别是在机械硬盘存储中(SSD固态硬盘的随意IO要快很多,不过这一点仍然适用)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引用以提升效率。
- 按顺序访问范围数据是很快的,这有两个原因。第一,顺序IO不需要多次磁盘寻道,所以比随机IO要快很多。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUP BY 查询也无须再做排序和将行按组进行聚合计算了。
- 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就不需要再回表查找行。这避免了大量的单行访问。
高性能MySQL笔记 第5章 创建高性能的索引的更多相关文章
- 《高性能MySQL》——第五章创建高性能索引
1.创建索引基本语法格 在MySQL中,在已经存在的表上,可以通过ALTER TABLE语句直接为表上的一个或几个字段创建索引.基本语法格式如下: ALTER TABLE 表名 ADD [UNIQUE ...
- 高性能MySQL笔记 第6章 查询性能优化
6.1 为什么查询速度会慢 查询的生命周期大致可按照顺序来看:从客户端,到服务器,然后在服务器上进行解析,生成执行计划,执行,并返回结果给客户端.其中“执行”可以认为是整个生命周期中最重要的阶段. ...
- 高性能MySQL笔记 第4章 Schema与数据类型优化
4.1 选择优化的数据类型 通用原则 更小的通常更好 前提是要确保没有低估需要存储的值范围:因为它占用更少的磁盘.内存.CPU缓存,并且处理时需要的CPU周期也更少. 简单就好 简 ...
- 高性能MySQL笔记-第1章MySQL Architecture and History-001
1.MySQL架构图 2.事务的隔离性 事务的隔离性是specific rules for which changes are and aren’t visible inside and outsid ...
- 高性能MySQL笔记-第5章Indexing for High Performance-004怎样用索引才高效
一.怎样用索引才高效 1.隔离索引列 MySQL generally can’t use indexes on columns unless the columns are isolated in t ...
- 高性能MySQL笔记-第5章Indexing for High Performance-002Hash indexes
一. 1.什么是hash index A hash index is built on a hash table and is useful only for exact lookups that u ...
- 高性能MySQL笔记-第5章Indexing for High Performance-001B-Tree indexes(B+Tree)
一. 1.什么是B-Tree indexes? The general idea of a B-Tree is that all the values are stored in order, and ...
- 高性能MySQL笔记-第4章Optimizing Schema and Data Types
1.Good schema design is pretty universal, but of course MySQL has special implementation details to ...
- 高性能MySQL笔记-第5章Indexing for High Performance-005聚集索引
一.聚集索引介绍 1.什么是聚集索引? InnoDB’s clustered indexes actually store a B-Tree index and the rows together i ...
随机推荐
- 【转】MyEclipse2015安装SVN插件
一.下载SVN插件subclipse 下载地址:http://subclipse.tigris.org/servlets/ProjectDocumentList?folderID=2240 在打开的网 ...
- c# datagridview禁止自动生成额外列
在某些时候,处于重用pojo的考虑,我们希望在不同的datagridview之间进行复用,这就涉及到pojo中的字段会比有些datagridview所需要的字段多,默认情况下,.net对于pojo中的 ...
- sql2012还原sql2008备份文件语句
--sql2012还原sql2008语句 --选择master数据库,新建查询 输入下面sql语句 --选择兼容模式(sql 2008)创建数据库db RESTORE DATABASE db FROM ...
- 【NodeJS 学习笔记03】先运行起来再说
前言 最近同事推荐了一个不错的网址:https://github.com/nswbmw/N-blog/wiki/_pages 里面的教程很是详细,我们现在跟着他的节奏学习下NodeJS,一个简单的博客 ...
- 每天checklist所用到的T-CODE
1.1重点检查 作业 事务码 检查过程 检查R/3系统是否已经启动 · 登录到R/3系统 检查每日备份是否正常 DB12-Backup Logs:Overview · 检查数据库备份 · 检查数据库备 ...
- ABAP中的数据校验-备注
通过 function module 检查日期是否合法(DDUT_INPUT_CHECK的校验会根据账户的时间设置格式) 日期校验方式一: CALL FUNCTION ‘DATE_CHECK_ ...
- ae_feature的插入、复制和删除
1.插入 /// <summary> ///向featureclass中批量插入features ,批量插入features,用buffer的方法,要比循环一个个Store的方法快 /// ...
- JavaScript滚动条插件源码
这是过年的时候自己写的js滚动条插件的源码,做出的效果自己并不满意,正因为做的并不满意所以回头重新巩固和深入学习js,这个插件有如下几个不太满意的地方: 内容的过度效果,可以参阅QQ客户端最近会话列表 ...
- [Android]使用AdapterTypeRender对不同类型的item数据到UI的渲染
以下内容为原创,转载请注明: 来自天天博客:http://www.cnblogs.com/tiantianbyconan/p/3992843.html 本文讲的工具均放在AndroidBucket开源 ...
- 在Ubuntu上安装Hadoop(单机模式)步骤
1. 安装jdk:sudo apt-get install openjdk-6-jdk 2. 配置ssh:安装ssh:apt-get install openssh-server 为运行hadoop的 ...