深入理解KMP算法之续篇
前言:
纠结于KMP已经两天了,相较于本人之前博客中提到的几篇博文,本人感觉这篇文章更清楚地说明了KMP算法的来龙去脉。
http://www.cnblogs.com/goagent/archive/2013/05/16/3068442.html
1、传统的字符串匹配算法

/*
* 从s中第sIndex位置开始匹配p
* 若匹配成功,返回s中模式串p的起始index
* 若匹配失败,返回-1
*/
int index(const std::string &s, const std::string &p, const int sIndex = 0)
{
int i = sIndex, j = 0; if (s.length() < 1 || p.length() < 1 || sIndex < 0)
{
return -1;
} while (i != s.length() && j != p.length())
{
if (s[i] == p[j])
{
++i;
++j;
}
else
{
i = i - j + 1;
j = 0;
}
}
return j == p.length() ? i - j: -1;
}
2、传统字符串匹配算法的性能问题
用模式串P去匹配字符串S,在i=6,j=4时发生失配:
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=4
此时,按照传统算法,应当将P的第 1 个字符 a(j=0) 滑动到与S中第4个字符 b(i=3) 对齐再进行匹配:
i=3
S: a b a b c a a d a c b a b
P: a b c a c
j=0
这个过程中,对字符串S的访问发生了“回朔”(从 i=6 移回到 i=3)。
我们不希望发生这样的回朔,而是试图通过尽可能的“向右滑动”模式串P,让P中index为 j 的字符对齐到S中 i=5 的字符,然后试图匹配S中 i=6 的字符与P中index为 j+1 的字符。
在这个测试用例中,我们直接将P向右滑动3个字符,使S中 i=5 的字符与P中 j=0 的字符对齐,再匹配S中 i=6 的字符与P中 j=1 的字符。
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=0
3、kmp算法的一般性讨论
下面讨论在一般性的情况下,如何实现在“不回朔”访问S、仅依靠“滑动”P的前提下实现字符串匹配,即“kmp算法”。
i=6
S: a b a b c a d c a c b a b
P: a b c a c
k=1
i=6
S: a b a b c a d c a c b a b
P: a b c a c
j=4
对于任意的S和P,当S中index为 i 的字符和P中index为 j 的字符失配时,我们假定应当滑动P使其index为 k 的字符与S中index为 i 的字符“对齐”并继续比较。
那么,这个 k 是多少?
我们知道,所谓的对齐,就是要让S和P满足以下条件(上图中的蓝色字符):
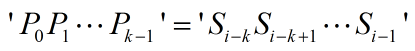 ……(1)
……(1)
另一方面,在失配时我们已经有了一些部分匹配结果(上图中的绿色字符):
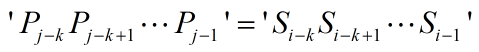 ……(2)
……(2)
由(1)、(2)可以得到:
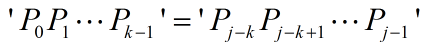 ……(3)
……(3)
即如下图所示效果:
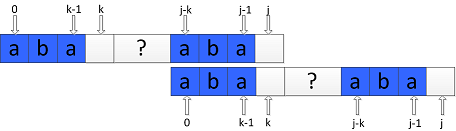
定义next[j]=k,k表示当模式串P中index为 j 的字符与主串S中index为 i 的字符发生失配时,应将P中index为 k 的字符继续与主串S中index为 i 的字符比较。
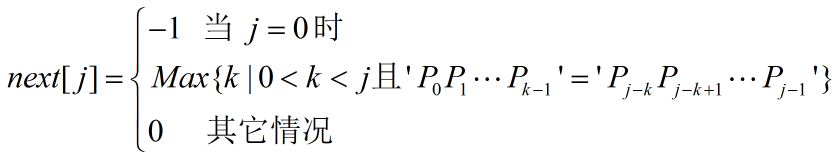 ……(4)
……(4)
按上述定义给出next数组的一个例子:
j 0 1 2 3 4 5 6 7
P a b a a b c a c
next[j] -1 0 0 1 1 2 0 1
在已知next数组的前提下,字符串匹配的步骤如下:
i 和 j 分别表示在主串S和模式串P中当前正待比较的字符的index,i 的初始值为sIndex,j 的初始值为0。
在匹配过程中的每一次循环,若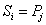 ,i 和 j 分别增 1,
,i 和 j 分别增 1,
else,j 退回到 next[j]的位置,此时下一次循环是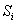 与
与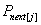 相比较。
相比较。
4、kmp算法的实现
在已知next函数的前提下,根据上面的步骤,kmp算法的实现如下:
int kmp(const std::string& s, const std::string& p, const int sIndex = 0)
{
std::vector<int>next(p.size());
getNext(p, next);//获取next数组,保存到vector中 int i = sIndex, j = 0;
while(i != s.length() && j != p.length())
{
if (j == -1 || s[i] == p[j])
{
++i;
++j;
}
else
{
j = next[j];
}
} return j == p.length() ? i - j: -1;
}
ok,下面的问题是怎么求模式串 P 的next数组。
next数组的初始条件是next[0] = -1,设next[j] = k,则有:
那么,next[j+1]有两种情况:
①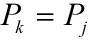 ,则有:
,则有: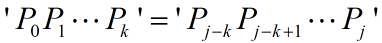
此时next[j+1] = next[j] + 1 = k + 1
②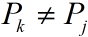 , 如图所示:
, 如图所示:
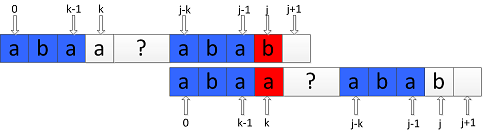
此时需要将P向右滑动之后继续比较P中index为 j 的字符与index为 next[k] 的字符:
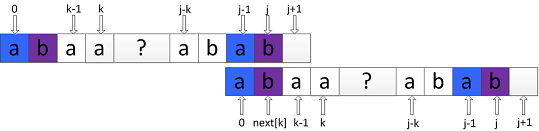
值得注意的是,上面的“向右滑动”本身就是一个kmp在失配情况下的滑动过程,将这个过程看 P 的自我匹配,则有:

如果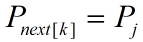 ,则next[j+1] = next[k] + 1;
,则next[j+1] = next[k] + 1;
否则,继续将 P 向右滑动,直至匹配成功,或者不存在这样的匹配,此时next[j+1] = 0。
getNext函数的实现如下:
void getNext(const std::string &p, std::vector<int> &next)
{
next.resize(p.size());
next[0] = -1; int i = 0, j = -1; while (i != p.size() - 1)
{
//这里注意,i==0的时候实际上求的是next[1]的值,以此类推
if (j == -1 || p[i] == p[j])
{
++i;
++j;
next[i] = j;
}
else
{
j = next[j];
}
}
}
至此,一个完整的kmp已经实现。
5、getNext函数的进一步优化
注意到,上面的getNext函数还存在可以优化的地方,比如:
i=3
S: a a a b a a a a b
P: a a a a b
j=3
此时,i=3、j=3时发生失配,next[3]=2,此时还需要进行 3 次比较:
i=3, j=2;
i=3, j=1;
i=3, j=0。
而实际上,因为i=3, j=3时就已经知道a!=b,而之后的三次依旧是拿 a 和 b 比较,因此这三次比较都是多余的。
此时应当直接将P向右滑动4个字符,进行 i=4, j=0的比较。
一般而言,在getNext函数中,next[i]=j,也就是说当p[i]与S中某个字符匹配失败的时候,用p[j]继续与S中的这个字符比较。
如果p[i]==p[j],那么这次比较是多余的(如同上面的例子),此时应该直接使next[i]=next[j]。
完整的实现代码如下:
void getNextUpdate(const std::string& p, std::vector<int>& next)
{
next.resize(p.size());
next[0] = -1; int i = 0, j = -1; while (i != p.size() - 1)
{
//这里注意,i==0的时候实际上求的是nextVector[1]的值,以此类推
if (j == -1 || p[i] == p[j])
{
++i;
++j;
//update
//next[i] = j;
//注意这里是++i和++j之后的p[i]、p[j]
next[i] = p[i] != p[j] ? j : next[j];
}
else
{
j = next[j];
}
}
}
对应的,只需要在kmp算法中将 getNext(p, next); 替换成 getNextUpdate(p, next); 即可。
6、时间复杂度分析
下面以getNext函数为例,分析kmp算法的时间复杂度。
1 void getNext(const std::string& p, std::vector<int>& next)
2 {
3 next.resize(p.size());
4 next[0] = -1;
5
6 int i = 0, j = -1;
7
8 while (i != p.size() - 1)
9 {
10 if (j == -1 || p[i] == p[j])
11 {
12 ++i;
13 ++j;
14 next[i] = j;
15 }
16 else
17 {
18 j = next[j];
19 }
20 }
21 }
假定p.size()为m,分析其时间复杂度的困惑在于,在while里面不是每次循环都执行 ++i 操作,所以整个while的执行次数不一定为m。
换个角度,注意到在每次循环中,无论 if 还是 else 都会修改 j 的值且每次循环仅对 j 进行一次修改,所以在整个while中 j 被修改的次数即为getNext函数的时间复杂度。
每次成功匹配时,++i; ++j; , 由于 ++i 最多执行 m-1 次,故++j也最多执行 m-1 次,即 j 最多增加m-1次;
对应的,只有在 j=next[j]; 处 j 的值一定会变小,由于 j 最多增加m-1次,故 j 最多减小m-1次。
综上所述,getNext函数的时间复杂度为O(m),若带匹配串S的长度为n,则kmp函数的时间负责度为O(m+n)。
7、kmp的应用优势
①快,O(m+n)的线性最坏时间复杂度;
②无需回朔访问待匹配字符串S,所以对处理从外设输入的庞大文件很有效,可以边读入边匹配。
深入理解KMP算法之续篇的更多相关文章
- 理解 KMP 算法
KMP(The Knuth-Morris-Pratt Algorithm)算法用于字符串匹配,从字符串中找出给定的子字符串.但它并不是很好理解和掌握.而理解它概念中的部分匹配表,是理解 KMP 算法的 ...
- 深入理解KMP算法
前言:本人最近在看<大话数据结构>字符串模式匹配算法的内容,但是看得很迷糊,这本书中这块的内容感觉基本是严蔚敏<数据结构>的一个翻版,此书中给出的代码实现确实非常精炼,但是个人 ...
- KMP算法详解 --- 彻头彻尾理解KMP算法
前言 之前对kmp算法虽然了解它的原理,即求出P0···Pi的最大相同前后缀长度k. 但是问题在于如何求出这个最大前后缀长度呢? 我觉得网上很多帖子都说的不是很清楚,总感觉没有把那层纸戳破, 后来翻看 ...
- 从头到尾测地理解KMP算法【转】
本文转载自:http://blog.csdn.net/v_july_v/article/details/7041827 1. 引言 本KMP原文最初写于2年多前的2011年12月,因当时初次接触KMP ...
- 真正理解KMP算法
作者:jostree 转载请注明出处 http://www.cnblogs.com/jostree/p/4403560.html 所谓KMP算法,就是判断一个模式串是否是一个字符串的子串,通常的算法当 ...
- 理解KMP算法
母串:S[i] 模式串:T[i] 标记数组:Next[i](Next[i]表示T[0~i]最长前缀/后缀数) 先来讲一下最长前缀/后缀的概念 例如有字符串T[6]=abcabd接下来讨论的全部是真前缀 ...
- KMP算法 --- 深入理解next数组
在KMP算法中有个数组,叫做前缀数组,也有的叫next数组. 每一个子串有一个固定的next数组,它记录着字符串匹配过程中失配情况下可以向前多跳几个字符. 当然它描述的也是子串的对称程度,程度越高,值 ...
- 从有限状态机的角度去理解Knuth-Morris-Pratt Algorithm(又叫KMP算法)
转载请加上:http://www.cnblogs.com/courtier/p/4273193.html 在开始讲这个文章前的唠叨话: 1:首先,在阅读此篇文章之前,你至少要了解过,什么是有限状态机, ...
- KMP算法的一次理解
1. 引言 在一个大的字符串中对一个小的子串进行定位称为字符串的模式匹配,这应该算是字符串中最重要的一个操作之一了.KMP本身不复杂,但网上绝大部分的文章把它讲混乱了.下面,咱们从暴力匹配算法讲起,随 ...
随机推荐
- 3.kvm的基本管理
1.查看KVM虚拟机配置文件 #KVM虚拟机默认配置文件位置 [root@kvm qemu]# pwd /etc/libvirt/qemu [root@kvm qemu]# ll total 12 # ...
- android快速开发--常用utils类
1.日志工具类L.java package com.zhy.utils; import android.util.Log; /** * Log统一管理类 * * * */ public class L ...
- POJ 2965 The Pilots Brothers' refrigerator
题目链接 题意:一个冰箱上有4*4共16个开关,改变任意一个开关的状态(即开变成关,关变成开)时,此开关的同一行.同一列所有的开关都会自动改变状态.要想打开冰箱,要所有开关全部打开才行. 输入:一个4 ...
- Could not find Developer Disk Image
测试机系统版本 iOS9.3,而Xcode7.2不支持 iOS9.3的真机测试,由于升级 Xcode 版本太慢,又急着看效果,怎么办呢?没事儿,只要找得到原因的问题就不是问题,现附上解决办法: 1)c ...
- August 11th 2016, Week 33rd Thursday
A particular fine spring came around. 转眼又是一番分外明媚的春光. Hey, it is hot outside, sometimes even unbearab ...
- 设计模式之构建者模式(Builder):初步理解
构建者(Builder)设计模式(又叫生成器设计模式): 当一个类的内部数据过于复杂的时候(通常是负责持有数据的类,比如Config.VO.PO.Entity...),要创建的话可能就需要了解这个类的 ...
- sql server 常用脚本(日常查询所需)
1:查看sql server代理中作业的运行状况的脚本 -- descr : a simple sql script to view sql server jobs run status -- las ...
- Spring学习笔记—最小化Spring XML配置
自动装配(autowiring)有助于减少甚至消除配置<property>元素和<constructor-arg>元素,让Spring自动识别如何装配Bean的依赖关系. 自动 ...
- CNN初步-1
Convolution: 个特征,则这时候把输入层的所有点都与隐含层节点连接,则需要学习10^6个参数,这样的话在使用BP算法时速度就明显慢了很多. 所以后面就发展到了局部连接网络,也就是说每个隐 ...
- javascript 面向对象编程小记
虽然平常用jquery用的很熟,但是基本都是面向过程的写法.一个事件一个function,很少有面向对象的写法.今天得写一个日期控件,不得不用上面向对象编程. 刚开始我的想法是: var datepi ...