Mysql优化系列(0)--总结性梳理
对于一个网站来说,在运行很长一段时间后,数据库瓶颈问题会越来越暴露出来。作为运维人员,对数据库做必要的优化十分重要!
下面总结以往查阅到的以及自己工作中的一些优化操作经验,并根据OSI七层模型从下往上进行优化mysql数据库记录。
一:物理层面
1、cpu:2-16个 2*4双四核,L1L2越大越好
2、内存:越大越好
3、磁盘:SAS或者固态 300G*12磁盘越多IO越高
raid 0>10>5>1
4、网卡:千兆
5、slave的配置最好大于等于master
二、系统配置
如下,配置系统内核参数/etc/sysctl.conf(配置后,使用sysctl -p使之生效)
net.ipv4.tcp_fin_timeout = 2
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_keepalive_time =600
net.ipv4.ip_local_port_range = 4000 65000
net.ipv4.tcp_max_syn_backlog = 16384
net.ipv4.tcp_max_tw_buckets = 36000
net.ipv4.route.gc_timeout = 100
net.ipv4.tcp_syn_retries = 1
net.ipv4.tcp_synack_retries = 1
net.core.somaxconn = 16384
net.core.netdev_max_backlog = 16384
net.ipv4.tcp_max_orphans = 16384
vm.swappiness=0 //尽量不使用swap
vm.dirty_backgroud_ratio 5-10
vm.dirty_ratio //上面的值的两倍 将操作系统的脏数据刷到磁盘
三:mysql的安装
MySQL数据库的线上环境安装,建议采取编译安装的方式,这样性能会有较大的提升。服务器系统则建议CentOS6.7 X86_64,源码包的编译参数会默认以Debug模式生成二进制代码,而Debug模式给MySQL带来的性能损失是比较大的,所以当我们编译准备安装的产品代码时,一定不要忘记使用--without-debug参数禁止Debug模式。如果把--with-mysqld-ldflags和--with-client-ld-flags两个编译参数设置为--all-static的话,可以告诉编译器以静态的方式编译,编译结果将得到最高的性能。使用静态编译和使用动态编译的代码相比,性能差距可能会达到5%至10%之多。在后面我会跟大家分享我们线上MySQL数据库的编译参数,大家可以参考下,然后根据自己的线上环境自行修改内容。
下面是对mysql服务配置文件my.cnf的详解:
[client]
port = 3306
# 客户端端口号为3306
socket = /data/3306/mysql.sock
default-character-set = utf8
# 客户端字符集,(控制character_set_client、character_set_connection、character_set_results)
[mysql]
no-auto-rehash
# 仅仅允许使用键值的updates和deletes
[mysqld]
# 组包括了mysqld服务启动的参数,它涉及的方面很多,其中有MySQL的目录和文件,通信、网络、信息安全,内存管理、优化、查询缓存区,还有MySQL日志设置等。
user = mysql
# mysql_safe脚本使用MySQL运行用户(编译时--user=mysql指定),推荐使用mysql用户。
port = 3306
# MySQL服务运行时的端口号。建议更改默认端口,默认容易遭受攻击。
socket = /data/3306/mysql.sock
# socket文件是在Linux/Unix环境下特有的,用户在Linux/Unix环境下客户端连接可以不通过TCP/IP网络而直接使用unix socket连接MySQL。
basedir = /application/mysql
# mysql程序所存放路径,常用于存放mysql启动、配置文件、日志等
datadir = /data/3306/data
# MySQL数据存放文件(极其重要)
character-set-server = utf8
# 数据库和数据库表的默认字符集。(推荐utf8,以免导致乱码)
log-error=/data/3306/mysql.err
# mysql错误日志存放路径及名称(启动出现错误一定要看错误日志,百分之百都能通过错误日志排插解决。)
pid-file=/data/3306/mysql.pid
# MySQL_pid文件记录的是当前mysqld进程的pid,pid亦即ProcessID。
skip-locking
# 避免MySQL的外部锁定,减少出错几率,增强稳定性。
skip-name-resolv
# 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时候。但是需要注意的是,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式了,否则MySQL将无法正常处理连接请求!
skip-networking
# 开启该选项可以彻底关闭MySQL的TCP/IP连接方式,如果Web服务器是以远程连接的方式访问MySQL数据库服务器的,则不要开启该选项,否则无法正常连接!
open_files_limit = 1024
# MySQLd能打开文件的最大个数,如果出现too mant open files之类的就需要调整该值了。
back_log = 384
# back_log参数是值指出在MySQL暂时停止响应新请求之前,短时间内的多少个请求可以被存在堆栈中。如果系统在短时间内有很多连接,则需要增加该参数的值,该参数值指定到来的TCP/IP连接的监听队列的大小。不同的操作系统在这个队列的大小上有自己的限制。如果试图将back_log设置得高于操作系统的限制将是无效的,其默认值为50.对于Linux系统而言,推荐设置为小于512的整数。
max_connections = 800
# 指定MySQL允许的最大连接进程数。如果在访问博客时经常出现 Too Many Connections的错误提示,则需要增大该参数值。
max_connect_errors = 6000
# 设置每个主机的连接请求异常中断的最大次数,当超过该次数,MySQL服务器将禁止host的连接请求,直到MySQL服务器重启或通过flush hosts命令清空此host的相关信息。
wait_timeout = 120
# 指定一个请求的最大连接时间,对于4GB左右内存的服务器来说,可以将其设置为5~10。
table_cache = 614K
# table_cache指示表高速缓冲区的大小。当MySQL访问一个表时,如果在MySQL缓冲区还有空间,那么这个表就被打开并放入表缓冲区,这样做的好处是可以更快速地访问表中的内容。一般来说,可以查看数据库运行峰值时间的状态值Open_tables和Open_tables,用以判断是否需要增加table_cache的值,即如果Open_tables接近table_cache的时候,并且Opened_tables这个值在逐步增加,那就要考虑增加这个值的大小了。
external-locking = FALSE
# MySQL选项可以避免外部锁定。True为开启。
max_allowed_packet =16M
# 服务器一次能处理最大的查询包的值,也是服务器程序能够处理的最大查询
sort_buffer_size = 1M
# 设置查询排序时所能使用的缓冲区大小,系统默认大小为2MB。
# 注意:该参数对应的分配内存是每个连接独占的,如果有100个连接,那么实际分配的总排序缓冲区大小为100 x6=600MB。所以,对于内存在4GB左右的服务器来说,推荐将其设置为6MB~8MB
join_buffer_size = 8M
# 联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。
thread_cache_size = 64
# 设置Thread Cache池中可以缓存的连接线程最大数量,可设置为0~16384,默认为0.这个值表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中;如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多线程,增加这个值可以改善系统性能。通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。我们可以根据物理内存设置规则如下:1GB内存我们配置为8,2GB内存我们配置为16,3GB我们配置为32,4GB或4GB以上我们给此值为64或更大的值。
thread_concurrency = 8
# 该参数取值为服务器逻辑CPU数量x 2,在本例中,服务器有两个物理CPU,而每个物理CPU又支持H.T超线程,所以实际取值为4 x 2 = 8。这也是双四核主流服务器的配置。
query_cache_size = 64M
# 指定MySQL查询缓冲区的大小。可以通过在MySQL控制台观察,如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况;如果Qcache_hits的值非常大,则表明查询缓冲使用得非常频繁。另外如果改值较小反而会影响效率,那么可以考虑不用查询缓冲。对于Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多。
query_cache_limit = 2M
# 只有小于此设置值的结果才会被缓存
query_cache_min_res_unit = 2k
# 设置查询缓存分配内存的最小单位,要适当第设置此参数,可以做到为减少内存快的申请和分配次数,但是设置过大可能导致内存碎片数值上升。默认值为4K,建议设置为1K~16K。
default_table_type = InnoDB
# 默认表的类型为InnoDB
thread_stack = 256K
# 设置MySQL每个线程的堆栈大小,默认值足够大,可满足普通操作。可设置范围为128KB至4GB,默认为192KB
#transaction_isolation = Level
# 数据库隔离级别 (READ UNCOMMITTED(读取未提交内容) READ COMMITTED(读取提交内容) REPEATABLE
READ(可重读) SERIALIZABLE(可串行化))
tmp_table_size = 64M
# 设置内存临时表最大值。如果超过该值,则会将临时表写入磁盘,其范围1KB到4GB。
max_heap_table_size = 64M
# 独立的内存表所允许的最大容量。
table_cache = 614
# 给经常访问的表分配的内存,物理内存越大,设置就越大。调大这个值,一般情况下可以降低磁盘IO,但相应的会占用更多的内存,这里设置为614。
table_open_cache = 512
# 设置表高速缓存的数目。每个连接进来,都会至少打开一个表缓存。因此, table_cache 的大小应与 max_connections 的设置有关。例如,对于 200 个并行运行的连接,应该让表的缓存至少有 200 × N ,这里 N 是应用可以执行的查询的一个联接中表的最大数量。此外,还需要为临时表和文件保留一些额外的文件描述符。
long_query_time = 1
# 慢查询的执行用时上限,默认设置是10s,推荐(1s~2s)
log_long_format
# 没有使用索引的查询也会被记录。(推荐,根据业务来调整)
log-slow-queries = /data/3306/slow.log
# 慢查询日志文件路径(如果开启慢查询,建议打开此日志)
log-bin = /data/3306/mysql-bin
# logbin数据库的操作日志,例如update、delete、create等都会存储到binlog日志,通过logbin可以实现增量恢复
relay-log = /data/3306/relay-bin
# relay-log日志记录的是从服务器I/O线程将主服务器的二进制日志读取过来记录到从服务器本地文件,然后SQL线程会读取relay-log日志的内容并应用到从服务器
relay-log-info-file = /data/3306/relay-log.info
# 从服务器用于记录中继日志相关信息的文件,默认名为数据目录中的relay-log.info。
binlog_cache_size = 4M
# 在一个事务中binlog为了记录sql状态所持有的cache大小,如果你经常使用大的,多声明的事务,可以增加此值来获取更大的性能,所有从事务来的状态都被缓冲在binlog缓冲中,然后再提交后一次性写入到binlog中,如果事务比此值大,会使用磁盘上的临时文件来替代,此缓冲在每个链接的事务第一次更新状态时被创建。
max_binlog_cache_size = 8M
# 最大的二进制Cache日志缓冲尺寸。
max_binlog_size = 1G
# 二进制日志文件的最大长度(默认设置1GB)一个二进制文件信息超过了这个最大长度之前,MySQL服务器会自动提供一个新的二进制日志文件接续上。
expire_logs_days = 7
# 超过7天的binlog,mysql程序自动删除(如果数据重要,建议不要开启该选项)
key_buffer_size = 256M
# 指定用于索引的缓冲区大小,增加它可得到更好的索引处理性能。对于内存在4GB左右的服务器来说,该参数可设置为256MB或384MB。
# 注意:如果该参数值设置得过大反而会使服务器的整体效率降低!
read_buffer_size = 4M
# 读查询操作所能使用的缓冲区大小。和sort_buffer_size一样,该参数对应的分配内存也是每个连接独享。
read_rnd_buffer_size = 16M
# 设置进行随机读的时候所使用的缓冲区。此参数和read_buffer_size所设置的Buffer相反,一个是顺序读的时候使用,一个是随机读的时候使用。但是两者都是针对与线程的设置,每个线程都可以产生两种Buffer中的任何一个。默认值256KB,最大值4GB。
bulk_insert_buffer_size = 8M
# 如果经常性的需要使用批量插入的特殊语句来插入数据,可以适当调整参数至16MB~32MB,建议8MB。
myisam_sort_buffer_size = 8M
# 设置在REPAIR Table或用Create index创建索引或 Alter table的过程中排序索引所分配的缓冲区大小,可设置范围4Bytes至4GB,默认为8MB
lower_case_table_names = 1
# 实现MySQL不区分大小。(发开需求-建议开启)
slave-skip-errors = 1032,1062
# 从库可以跳过的错误数字值(mysql错误以数字代码反馈,全的mysql错误代码大全,以后会发布至博客)。
replicate-ignore-db=mysql
# 在做主从的情况下,设置不需要同步的库。
server-id = 1
# 表示本机的序列号为1,如果做主从,或者多实例,serverid一定不能相同。
myisam_sort_buffer_size = 128M
# 当需要对于执行REPAIR, OPTIMIZE, ALTER 语句重建索引时,MySQL会分配这个缓存,以及LOAD DATA INFILE会加载到一个新表,它会根据最大的配置认真的分配的每个线程。
myisam_max_sort_file_size = 10G
# 当重新建索引(REPAIR,ALTER,TABLE,或者LOAD,DATA,TNFILE)时,MySQL被允许使用临时文件的最大值。
myisam_repair_threads = 1
# 如果一个表拥有超过一个索引, MyISAM 可以通过并行排序使用超过一个线程去修复他们.
myisam_recover
# 自动检查和修复没有适当关闭的 MyISAM 表.
innodb_additional_mem_pool_size = 4M
# 用来设置InnoDB存储的数据目录信息和其他内部数据结构的内存池大小。应用程序里的表越多,你需要在这里面分配越多的内存。对于一个相对稳定的应用,这个参数的大小也是相对稳定的,也没有必要预留非常大的值。如果InnoDB用广了这个池内的内存,InnoDB开始从操作系统分配内存,并且往MySQL错误日志写警告信息。默认为1MB,当发现错误日志中已经有相关的警告信息时,就应该适当的增加该参数的大小。
innodb_buffer_pool_size = 64M
# InnoDB使用一个缓冲池来保存索引和原始数据,设置越大,在存取表里面数据时所需要的磁盘I/O越少。强烈建议不要武断地将InnoDB的Buffer Pool值配置为物理内存的50%~80%,应根据具体环境而定。
innodb_data_file_path = ibdata1:128M:autoextend
# 设置配置一个可扩展大小的尺寸为128MB的单独文件,名为ibdata1.没有给出文件的位置,所以默认的是在MySQL的数据目录内。
innodb_file_io_threads = 4
# InnoDB中的文件I/O线程。通常设置为4,如果是windows可以设置更大的值以提高磁盘I/O
innodb_thread_concurrency = 8
# 你的服务器有几个CPU就设置为几,建议用默认设置,一般设为8。
innodb_flush_log_at_trx_commit = 1
# 设置为0就等于innodb_log_buffer_size队列满后在统一存储,默认为1,也是最安全的设置。
innodb_log_buffer_size = 2M
# 默认为1MB,通常设置为8~16MB就足够了。
innodb_log_file_size = 32M
# 确定日志文件的大小,更大的设置可以提高性能,但也会增加恢复数据库的时间。
innodb_log_files_in_group = 3
# 为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3。
innodb_max_dirty_pages_pct = 90
# InnoDB主线程刷新缓存池中的数据。
innodb_lock_wait_timeout = 120
# InnoDB事务被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用locak tables 语句注意到锁定设置。默认值是50秒。
innodb_file_per_table = 0
# InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间。0关闭,1开启。
# 独立表空间优点:
# 1、每个表都有自己独立的表空间。
# 2 、每个表的数据和索引都会存在自己的表空间中。
# 3、可以实现单表在不同的数据库中移动。
# 4、空间可以回收(除drop table操作处,表空不能自己回收。)
[mysqldump]
quick
max_allowed_packet = 2M
# 设定在网络传输中一次消息传输量的最大值。系统默认值为1MB,最大值是1GB,必须设置为1024的倍数。单位为字节。
一些建议:
强烈建议不要武断地将InnoDB的Buffer Pool值配置为物理内存的50%~80%,应根据具体环境而定。
如果key_reads太大,则应该把my.cnf中的key_buffer_size变大,保持key_reads/key_read_re-quests至少在1/100以上,越小越好。
如果qcache_lowmem_prunes很大,就要增加query_cache_size的值。
不过很多时候需要具体情况具体分析,其他参数的变更我们可以等MySQL上线稳定一段时间后在根据status值进行调整。
配置范例
一份电子商务网站MySQL数据库调整后所运行的配置文件/etc/my.cnf(服务器为DELL R710、16GB内存、RAID10),大家可以根据实际的MySQL数据库硬件情况进行调整配置文件如下:
[client]
port = 3306
socket = /data/3306/mysql.sock
default-character-set = utf8
[mysqld]
user = mysql
port = 3306
character-set-server = utf8
socket = /data/3306/mysql.sock
basedir = /application/mysql
datadir = /data/3306/data
log-error=/data/3306/mysql_err.log
pid-file=/data/3306/mysql.pid
log_slave_updates = 1
log-bin = /data/3306/mysql-bin
binlog_format = mixed
binlog_cache_size = 4M
max_binlog_cache_size = 8M
max_binlog_size = 1G
expire_logs_days = 90
binlog-ignore - db = mysql
binlog-ignore - db = information_schema
key_buffer_size = 384M
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 16M
join_buffer_size = 2M
thread_cache_size = 8
query_cache_size = 32M
query_cache_limit = 2M
query_cache_min_res_unit = 2k
thread_concurrency = 32
table_cache = 614
table_open_cache = 512
open_files_limit = 10240
back_log = 600
max_connections = 5000
max_connect_errors = 6000
external-locking = FALSE
max_allowed_packet =16M
thread_stack = 192K
transaction_isolation = READ-COMMITTED
tmp_table_size = 256M
max_heap_table_size = 512M
bulk_insert_buffer_size = 64M
myisam_sort_buffer_size = 64M
myisam_max_sort_file_size = 10G
myisam_repair_threads = 1
myisam_recover
long_query_time = 2
slow_query_log
slow_query_log_file = /data/3306/slow.log
skip-name-resolv
skip-locking
skip-networking
server-id = 1
innodb_additional_mem_pool_size = 16M
innodb_buffer_pool_size = 512M
innodb_data_file_path = ibdata1:256M:autoextend
innodb_file_io_threads = 4
innodb_thread_concurrency = 8
innodb_flush_log_at_trx_commit = 2
innodb_log_buffer_size = 16M
innodb_log_file_size = 128M
innodb_log_files_in_group = 3
innodb_max_dirty_pages_pct = 90
innodb_lock_wait_timeout = 120
innodb_file_per_table = 0
[mysqldump]
quick
max_allowed_packet = 64M
[mysql]
no – auto - rehash
四:存储引擎的选择
关于存储引擎的选择请看博客:MySQL存储引擎之Myisam和Innodb总结性梳理
五:线上优化调整
MySQL数据库上线后,可以等其稳定运行一段时间后再根据服务器的status状态进行适当优化,我们可以用如下命令列出MySQL服务器运行的各种状态值。通过命令:show global status; 也可以通过 show status like '查询%';
1、慢查询
有时我们为了定位系统中效率比较低下的Query语法,需要打开慢查询日志,也就是Slow Query log。打开慢查询日志的相关命令如下:
mysql>show variables like '%slow%';
+---------------------+-----------------------------------------+
|
Variable_name | Value |
+---------------------+-----------------------------------------+
|
log_slow_queries | ON |
|
slow_launch_time | 2 |
+---------------------+-----------------------------------------+
mysql>show global status like '%slow%';
+---------------------+-------+
|
Variable_name | Value |
+---------------------+-------+
|
Slow_launch_threads | 0 |
|
Slow_queries | 2128 |
+---------------------+-------+
打开慢查询日志可能会对系统性能有一点点影响,如果你的MySQL是主从结构,可以考虑打开其中一台从服务器的慢查询日志,这样既可以监控慢查询,对系统性能影响也会很小。另外,可以用MySQL自带的命令mysqldumpslow进行查询。比如:下面的命令可以查出访问次数最多的20个SQL语句:
mysqldumpslow -s c -t 20 host-slow.log
2、连接数
我们如果经常遇见MySQL:ERROR1040:Too many connections的情况,一种情况是访问量确实很高,MySQL服务器扛不住了,这个时候就要考虑增加从服务器分散读压力,从架构层面。另外一种情况是MySQL配置文件中max_connections的值过小。来看一个例子。
mysql> show variables like 'max_connections';
+-----------------+-------+
|
Variable_name | Value |
+-----------------+-------+
|
max_connections | 800 |
+-----------------+-------+
#### 这台服务器最大连接数是256,然后查询一下该服务器响应的最大连接数;
mysql> show global status like 'Max_used_connections';
+----------------------+-------+
|
Variable_name | Value |
+----------------------+-------+
|
Max_used_connections | 245 |
+----------------------+-------+
#### MySQL服务器过去的最大连接数是245,没有达到服务器连接数的上线800,不会出现1040错误。
#### Max_used_connections /max_connections * 100% = 85%
#### 最大连接数占上限连接数的85%左右,如果发现比例在10%以下,则说明MySQL服务器连接数的上限设置得过高了。
3.key_buffer_size
key_buffer_size是设置MyISAM表索引缓存空间的大小,此参数对MyISAM表性能影响最大。下面是一台MyISAM为主要存储引擎服务器的配置:
mysql> show variables like 'key_buffer_size';
+-----------------+-----------+
|
Variable_name | Value |
+-----------------+-----------+
|
key_buffer_size | 536870912 |
+-----------------+-----------+
#### 从上面可以看出,分配了512MB内存给key_buffer_size。再来看key_buffer_size的使用情况:
mysql> show global status like 'key_read%';
+-------------------+--------------+
|
Variable_name | Value |
+-------------------+-------+
|
Key_read_requests | 27813678766 |
|
Key_reads | 6798830|
+-------------------+--------------+
一共有27813678766个索引读取请求,有6798830个请求在内存中没有找到,直接从硬盘读取索引。
key_cache_miss_rate = key_reads / key_read_requests * 100%
比如上面的数据,key_cache_miss_rate为0.0244%,4000%个索引读取请求才有一个直接读硬盘,效果已经很好了,key_cache_miss_rate在0.1%以下都很好,如果key_cache_miss_rate在0.01%以下的话,则说明key_buffer_size分配得过多,可以适当减少。
4.临时表
当执行语句时,关于已经被创建了隐含临时表的数量,我们可以用如下命令查询其具体情况:
mysql> show global status like 'created_tmp%';
+-------------------------+----------+
|
Variable_name | Value |
+-------------------------+----------+
|
Created_tmp_disk_tables | 21119 |
|
Created_tmp_files | 6 |
|
Created_tmp_tables | 17715532 |
+-------------------------+----------+
#### MySQL服务器对临时表的配置:
mysql> show variables where Variable_name in ('tmp_table_size','max_heap_table_size');
+---------------------+---------+
|
Variable_name | Value |
+---------------------+---------+
|
max_heap_table_size | 2097152 |
|
tmp_table_size | 2097152 |
+---------------------+---------+
每次创建临时表时,Created_tmp_table都会增加,如果磁盘上创建临时表,Created_tmp_disk_tables也会增加。Created_tmp_files表示MySQL服务创建的临时文件数,比较理想的配置是:
Created_tmp_disk_tables / Created_tmp_files *100% <= 25%
比如上面的服务器:
Created_tmp_disk_tables / Created_tmp_files *100% =1.20%,这个值就很棒了。
5.打开表的情况
Open_tables表示打开表的数量,Opened_tables表示打开过的表数量,我们可以用如下命令查看其具体情况:
mysql> show global status like 'open%tables%';
+---------------+-------+
|
Variable_name | Value |
+---------------+-------+
|
Open_tables | 351 |
|
Opened_tables | 1455 |
#### 查询下服务器table_open_cache;
mysql> show variables like 'table_open_cache';
+------------------+-------+
|
Variable_name | Value |
+------------------+-------+
|
table_open_cache | 2048 |
+------------------+-------+
如果Opened_tables数量过大,说明配置中table_open_cache的值可能太小。
比较合适的值为:
open_tables / opened_tables* 100% > = 85%
open_tables / table_open_cache* 100% < = 95%
6.进程使用情况
如果我们在MySQL服务器的配置文件中设置了thread_cache_size,当客户端断开时,服务器处理此客户请求的线程将会缓存起来以响应一下客户而不是销毁(前提是缓存数未达上线)Thread_created表示创建过的线程数,我们可以用如下命令查看:
mysql> show global status like 'thread%';
+-------------------+-------+
|
Variable_name | Value |
+-------------------+-------+
|
Threads_cached | 40|
|
Threads_connected | 1 |
|
Threads_created | 330 |
|
Threads_running | 1 |
+-------------------+-------+
#### 查询服务器thread_cache_size配置如下:
mysql> show variables like 'thread_cache_size';
+-------------------+-------+
|
Variable_name | Value |
+-------------------+-------+
|
thread_cache_size | 100 |
+-------------------+-------+
如果发现Threads_created的值过大的话,表明MySQL服务器一直在创建线程,这也是比较耗费资源的,可以适当增大配置文件中thread_cache_size的值。
7.查询缓存(query cache)
它主要涉及两个参数,query_cache_size是设置MySQL的Query Cache大小,query_cache_type是设置使用查询缓存的类型,我们可以用如下命令查看其具体情况:
mysql> show global status like 'qcache%';
+-------------------------+-----------+
|
Variable_name | Value |
+-------------------------+-----------+
|
Qcache_free_blocks | 22756 |
|
Qcache_free_memory | 76764704 |
|
Qcache_hits | 213028692 |
|
Qcache_inserts | 208894227 |
|
Qcache_lowmem_prunes | 4010916 |
|
Qcache_not_cached | 13385031 |
|
Qcache_queries_in_cache | 43560 |
|
Qcache_total_blocks | 111212 |
+-------------------------+-----------+
MySQL查询缓存变量的相关解释如下:
Qcache_free_blocks: 缓存中相领内存快的个数。数目大说明可能有碎片。flush query cache会对缓存中的碎片进行整理,从而得到一个空间块。
Qcache_free_memory:缓存中的空闲空间。
Qcache_hits:多少次命中。通过这个参数可以查看到Query Cache的基本效果。
Qcache_inserts:插入次数,没插入一次查询时就增加1。命中次数除以插入次数就是命中比率。
Qcache_lowmem_prunes:多少条Query因为内存不足而被清楚出Query Cache。通过Qcache_lowmem_prunes和Query_free_memory相互结合,能 够更清楚地了解到系统中Query Cache的内存大小是否真的足够,是否非常频繁地出现因为内存不足而有Query被换出的情况。
Qcache_not_cached:不适合进行缓存的查询数量,通常是由于这些查询不是select语句或用了now()之类的函数。
Qcache_queries_in_cache:当前缓存的查询和响应数量。
Qcache_total_blocks:缓存中块的数量。
query_cache的配置命令:
mysql> show variables like 'query_cache%';
+------------------------------+---------+
|
Variable_name | Value |
+------------------------------+---------+
|
query_cache_limit | 1048576 |
|
query_cache_min_res_unit | 2048 |
|
query_cache_size | 2097152 |
|
query_cache_type | ON |
|
query_cache_wlock_invalidate | OFF |
+------------------------------+---------+
字段解释如下:
query_cache_limit:超过此大小的查询将不缓存。
query_cache_min_res_unit:缓存块的最小值。
query_cache_size:查询缓存大小。
query_cache_type:缓存类型,决定缓存什么样的查询,示例中表示不缓存select sql_no_cache查询。
query_cache_wlock_invalidat:表示当有其他客户端正在对MyISAM表进行写操作,读请求是要等WRITE LOCK释放资源后再查询还是允许直接从Query Cache中读取结果,默认为OFF(可以直接从Query Cache中取得结果。)
query_cache_min_res_unit的配置是一柄双刃剑,默认是4KB,设置值大对大数据查询有好处,但如果你的查询都是小数据查询,就容易造成内存碎片和浪费。
查询缓存碎片率 = Qcache_free_blocks /Qcache_total_blocks * 100%
如果查询碎片率超过20%,可以用 flush query cache 整理缓存碎片,或者试试减少query_cache_min_res_unit,如果你查询都是小数据库的话。
查询缓存利用率 = (Qcache_free_size – Qcache_free_memory)/query_cache_size * 100%
查询缓存利用率在25%一下的话说明query_cache_size设置得过大,可适当减少;查询缓存利用率在80%以上而且Qcache_lowmem_prunes > 50的话则说明query_cache_size可能有点小,不然就是碎片太多。
查询命中率 = (Qcache_hits - Qcache_insert)/Qcache)hits * 100%
示例服务器中的查询缓存碎片率等于20%左右,查询缓存利用率在50%,查询命中率在2%,说明命中率很差,可能写操作比较频繁,而且可能有些碎片。
8.排序使用情况
它表示系统中对数据进行排序时所用的Buffer,我们可以用如下命令查看:
mysql> show global status like 'sort%';
+-------------------+----------+
|
Variable_name | Value |
+-------------------+----------+
|
Sort_merge_passes | 10 |
|
Sort_range | 37431240 |
|
Sort_rows | 6738691532 |
|
Sort_scan | 1823485 |
+-------------------+----------+
Sort_merge_passes包括如下步骤:MySQL首先会尝试在内存中做排序,使用的内存大小由系统变量sort_buffer_size来决定,如果它不够大则把所有的记录都读在内存中,而MySQL则会把每次在内存中排序的结果存到临时文件中,等MySQL找到所有记录之后,再把临时文件中的记录做一次排序。这次再排序就会增加sort_merge_passes。实际上,MySQL会用另外一个临时文件来存储再次排序的结果,所以我们通常会看sort_merge_passes增加的数值是建临时文件数的两倍。因为用到了临时文件,所以速度可能会比较慢,增大sort_buffer_size会减少sort_merge_passes和创建临时文件的次数,但盲目地增大sort_buffer_size并不一定能提高速度。
9.文件打开数(open_files)
我们现在处理MySQL故障时,发现当Open_files大于open_files_limit值时,MySQL数据库就会发生卡住的现象,导致Nginx服务器打不开相应页面。这个问题大家在工作中应注意,我们可以用如下命令查看其具体情况:
show global status like 'open_files';
+---------------+-------+
|
Variable_name | Value |
+---------------+-------+
|
Open_files | 1481 |
+---------------+-------+
mysql> show global status like 'open_files_limit';
+------------------+-------+
|
Variable_name | Value |
+------------------+--------+
|
Open_files_limit | 4509 |
+------------------+--------+
比较合适的设置是:Open_files / Open_files_limit * 100% < = 75%
10.InnoDB_buffer_pool_cache合理设置
InnoDB存储引擎的缓存机制和MyISAM的最大区别就在于,InnoDB不仅仅缓存索引,同时还会缓存实际的数据。此参数用来设置InnoDB最主要的Buffer的大小,也就是缓存用户表及索引数据的最主要缓存空间,对InnoDB整体性能影响也最大。
无论是MySQL官方手册还是网络上许多人分享的InnoDB优化建议,都是简单地建议将此值设置为整个系统物理内存的50%~80%。这种做法其实不妥,我们应根据实际的运行场景来正确设置此项参数。
很多时候我们会发现,通过参数设置进行性能优化所带来的性能提升,并不如许多人想象的那样会产生质的飞跃,除非是之前的设置存在严重不合理的情况。我们不能将性能调优完全依托与通过DBA在数据库上线后进行参数调整,而应该在系统设计和开发阶段就尽可能减少性能问题。(重点在于前期架构合理的设计及开发的程序合理)
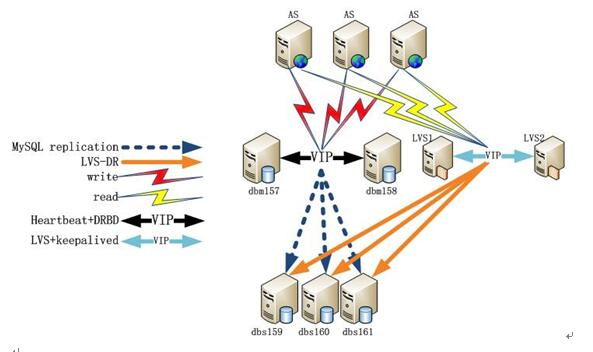
六:MySQL数据库的可扩展架构方案(即高可用方案) 可参考:mysql高可用方案总结性说明
如果凭借MySQL的优化任无法顶住压力,这个时候我们就必须考虑MySQL的可扩展性架构了(有人称为MySQL集群)它有以下明显的优势:
1)成本低,很容易通过价格低廉Pc server搭建出一个处理能力非常强大的计算机集群。
2)不太容易遇到瓶颈,因为很容易通过添加主机来增加处理能力。
3)单节点故障对系统的整体影响较小。
1、主从复制解决方案
这是MySQL自身提供的一种高可用解决方案,数据同步方法采用的是MySQL replication技术。MySQL replication就是从服务器到主服务器拉取二进制日志文件,然后再将日志文件解析成相应的SQL在从服务器上重新执行一遍主服务器的操作,通过这种方式保证数据的一致性。
为了达到更高的可用性,在实际的应用环境中,一般都是采用MySQL replication技术配合高可用集群软件keepalived来实现自动failover,这种方式可以实现95.000%的SLA。
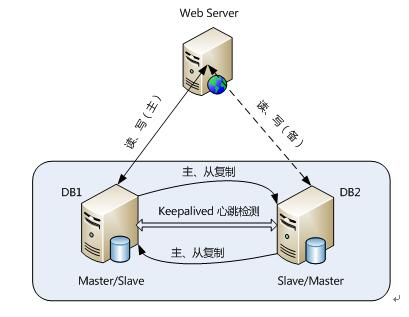
在实际应用场景中,MySQL Replication是使用最为广泛的一种提高系统扩展性的设计手段。众多的MySQL使用者通过Replication功能提升系统的扩展性后,通过 简单的增加价格低廉的硬件设备成倍 甚至成数量级地提高了原有系统的性能,是广大MySQL中低端使用者非常喜欢的功能之一,也是许多MySQL使用者选择MySQL最为重要的原因。
比较常规的MySQL Replication架构也有好几种,这里分别简单说明下:
MySQL Replication架构一:常规复制架构–Master-slaves
是由一个Master复制到一个或多个Salve的架构模式,主要用于读压力大的应用数据库端廉价扩展解决方案,读写分离,Master主要负责写方面的压力。
MySQL Replication架构二:级联复制架构
即Master-Slaves-Slaves,这个也是为了防止Slaves的读压力过大,而配置一层二级 Slaves,很容易解决Master端因为附属slave太多而成为瓶劲的风险。
MySQL Replication架构三:Dual Master与级联复制结合架构
即Master-Master-Slaves,最大的好处是既可以避免主Master的写操作受到Slave集群的复制带来的影响,而且保证了主Master的单点故障。
MySQL Replication的不足:
如果Master主机硬件故障无法恢复,则可能造成部分未传送到slave端的数据丢失。所以大家应该根据自己目前的网络 规划,选择自己合理的Mysql架构方案,跟自己的MySQL DBA和程序员多沟涌,多备份(备份我至少会做到本地和异地双备份),多测试,数据的事是最大的事,出不得半点差错,切记切记
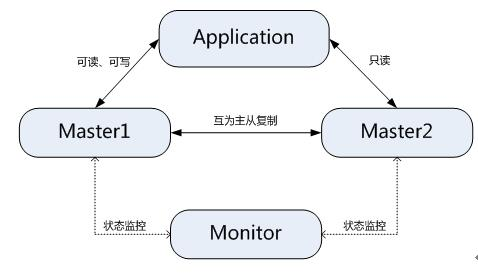
2、MMM/MHA高可用解决方案
MMM提供了MySQL主主复制配置的监控、故障转移和管理的一套可伸缩的脚本套件。在MMM高可用方案中,典型的应用是双主多从架构,通过MySQL replication技术可以实现两个服务器互为主从,且在任何时候只有一个节点可以被写入,避免了多点写入的数据冲突。同时,当可写的主节点故障时,MMM套件可以立刻监控到,然后将服务自动切换到另一个主节点,继续提供服务,从而实现MySQL的高可用。
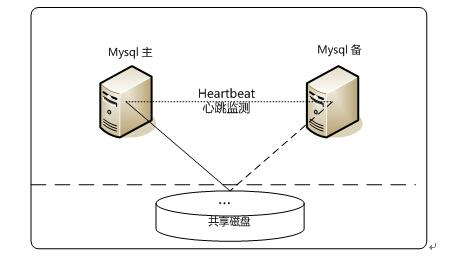
3、Heartbeat/SAN高可用解决方案
在这个方案中,处理failover的方式是高可用集群软件Heartbeat,它监控和管理各个节点间连接的网络,并监控集群服务,当节点出现故障或者服务不可用时,自动在其他节点启动集群服务。在数据共享方面,通过SAN(Storage Area Network)存储来共享数据,这种方案可以实现99.990%的SLA。
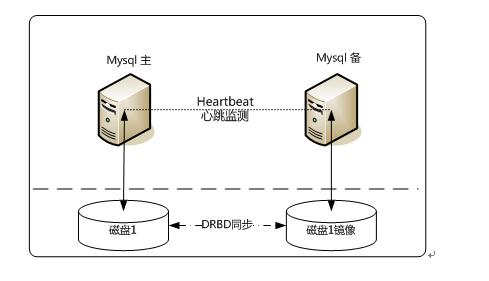
4、Heartbeat/DRBD高可用解决方案
此方案处理failover的方式上依旧采用Heartbeat,不同的是,在数据共享方面,采用了基于块级别的数据同步软件DRBD来实现。
DRBD是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。和SAN网络不同,它并不共享存储,而是通过服务器之间的网络复制数据。
5、percona xtradb cluster
Percona XtraDB Cluster(简称PXC集群)提供了MySQL高可用的一种实现方法。
1)集群是有节点组成的,推荐配置至少3个节点,但是也可以运行在2个节点上。
2)每个节点都是普通的mysql/percona服务器,可以将现有的数据库服务器组成集群,反之,也可以将集群拆分成单独的服务器。
3)每个节点都包含完整的数据副本。
PXC集群主要由两部分组成:Percona Server with XtraDB和Write Set Replication patches(使用了Galera library,一个通用的用于事务型应用的同步、多主复制插件)。
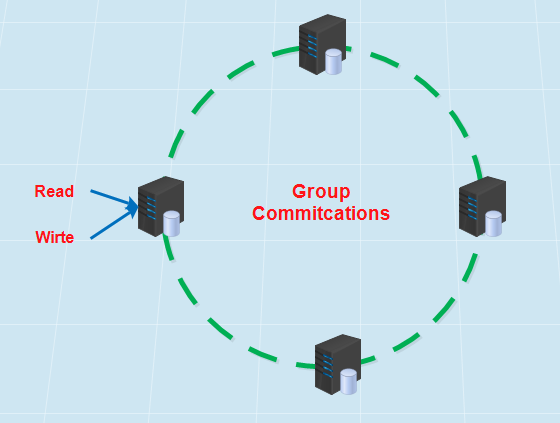
MYSQL经典应用架构
Mysql优化系列(0)--总结性梳理的更多相关文章
- Mysql优化系列(2)--通用化操作梳理
前面有两篇文章详细介绍了mysql优化举措:Mysql优化系列(0)--总结性梳理Mysql优化系列(1)--Innodb引擎下mysql自身配置优化 下面分类罗列下Mysql性能优化的一些技巧,熟练 ...
- (转)MySQL优化系列
原文:http://blog.csdn.net/jack__frost/article/details/71194208 数据库,后端开发者必学,而且现在以MySQL居多.这个系列将系统化MySQL一 ...
- Mysql优化系列之数据类型优化
本篇是优化系列的第一篇:数据类型 为了不产生赘述,尽量用简洁的语言来描述. 在选择数据类型之前,首先要知道几个原则: 更小的通常更好 尽量使用可以正确存储数据的最小数据类型.更小的数据类型意味着更快, ...
- Mysql优化系列之查询性能优化前篇1
前言 这是优化系列的最后一篇的第1小篇,我们其实可以直接从sql怎么写讲起,why not?但是我还是决定花2个篇幅 问一些问题,带着几个问题循序渐进的往下走. 一个sql语句是怎么被执行的? sql ...
- Mysql优化系列之——优化器对子查询的处理
根据子查询的类型和位置不同,mysql优化器会对查询语句中的子查询采取不同的处理策略,其中包括改写为连接(join),改写为半连接(semi-join)及进行物化处理等. 标量子查询(Scalar S ...
- Mysql优化系列(1)--Innodb引擎下mysql自身配置优化
1.简单介绍InnoDB给MySQL提供了具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎.InnoDB锁定在行级并且也在SELECT语句提供一个Oracle风格一致的非锁定读.这些特色 ...
- Mysql优化系列(1)--Innodb重要参数优化
1.简单介绍InnoDB给MySQL提供了具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎.InnoDB锁定在行级并且也在SELECT语句提供一个Oracle风格一致的非锁定读.这些特色 ...
- Mysql优化系列--Innodb引擎下mysql自身配置优化-转
原文链接:http://www.cnblogs.com/kevingrace/p/6133818.html 谢谢楼主 1.简单介绍 InnoDB给MySQL提供了具有提交,回滚和崩溃恢复能力的事务安全 ...
- MySQL优化系列之一
MySQL数据库常见的两个瓶颈是CPU和I/O. CPU在饱和的情况下一般发生在数据装入内存或者从磁盘上读取数据的时候,当装入的数据远大于 内存容量的时候,这时可能会发生I/O瓶颈, 如果是分布式应用 ...
随机推荐
- iOS开发工具篇-AppStore统计工具 (转载)
随着iOS开发的流行,针对iOS开发涉及的方方面面,早有一些公司提供了专门的解决方案或工具.这些解决方案或工具包括:用户行为统计工具(友盟,Flurry,Google Analytics等), App ...
- 浅谈FloatingActionButton(悬浮按钮)
一.介绍 这个类是继承自ImageView的,所以对于这个控件我们可以使用ImageView的所有属性 android.support.design.widget.FloatingActionButt ...
- 访客至上的Web、移动可用性设计--指导原则
文章出自:听云博客 关于可用性设计,之前写过一个“纸上谈兵”版本的,那篇帖子主要是根据A/B test的方式来进行的. 但是最近找了本Steve krug写的Don't make me think,我 ...
- 浅谈Java五大设计原则之观察者模式
定义一下观察者模式: 观察者模式又叫 发布-订阅 模式,定义的两个对象之间是一种一对多的强依赖关系,当一个对象的状态发生改变,所有依赖它的对象 将得到通知并自动更新(摘自Hand First). ...
- 【代码笔记】iOS-手机号验证
代码: - (void)viewDidLoad { [super viewDidLoad]; // Do any additional setup after loading the view. // ...
- Windows操作系统优化(Windows优化大师版) - 进阶者系列 - 学习者系列文章
Windows优化大师是一款不错的优化软件.笔者以前在使用XP的时候就使用该软件进行优化.下面就简要的介绍该软件优化的过程. 1. 下载该软件. http://dl.youhua.com/youhu ...
- ORA-00030: User session ID does not exist.
同事在Toad里面执行SQL语句时,突然无线网络中断了,让我检查一下具体情况,如下所示(有些信息,用xxx替换,因为是在处理那些历史归档数据,使用的一个特殊用户,所以可以用下面SQL找到对应的会话信息 ...
- 使用JUnit4测试Spring
测试DAO import static org.junit.Assert.*; import org.junit.Before; import org.junit.Ignore; import org ...
- WebApi深入学习--概述+路由查找
如何创建Controller这里就不说了,只写一些可能是高阶知识的内容 关于WebApi的官方介绍及示例 http://www.asp.net/web-api/ 1.跨域 Asp.NET有专门的跨域扩 ...
- RTP、RTCP协议学习-2015.04.15
最近做视频编解码部分,传输采用RTP协议.对学习做个记录 1.简介 实时传输协议(Real-time Transport Protocol或简写RTP)是一个网络传输协议,它是由IETF的多媒体传输工 ...