scrapy-redis分布式爬虫实战
Scrapy-Redis代码实战
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件)。
scrapy-redis在scrapy的架构上增加了redis,基于redis的特性拓展了如下四种组件:
- Scheduler
- Duplication Filter
- Item Pipeline
- Base Spider
scrapy-redis架构

Scheduler
Scrapy原本的queue是不支持多个spider共享一个队列的,scrapy-redis通过将queue改为redis实现队列共享。
Duplication Filter
Scrapy中通过Python中的集合实现request指纹去重,在scrapy-redis中去重是由Duplication Filter组件来实现的,它通过redis的set不重复的特性,巧妙的实现了DuplicationFilter去重。
Item Pipeline
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存入redis的 items queue。修改过Item Pipeline可以很方便的根据 key 从 items queue提取item,从而实现 items processes集群。
Base Spider
不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。
当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):一个是当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。一个是当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request
安装Scrapy-Redis
python3.6 -m pip install scrapy-redis
项目练习
首先修改配置文件
BOT_NAME = 'cnblogs'
SPIDER_MODULES = ['cnblogs.spiders']
NEWSPIDER_MODULE = 'cnblogs.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
DOWNLOAD_DELAY = 2 # 等待2s
MY_USER_AGENT = ["Mozilla/5.0+(Windows+NT+6.2;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/45.0.2454.101+Safari/537.36",
"Mozilla/5.0+(Windows+NT+5.1)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/28.0.1500.95+Safari/537.36+SE+2.X+MetaSr+1.0",
"Mozilla/5.0+(Windows+NT+6.1;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/50.0.2657.3+Safari/537.36"]
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'cnblogs.middlewares.UserAgentMiddleware': 543,
}
LOG_LEVEL = "ERROR"
ITEM_PIPELINES = {
'cnblogs.pipelines.MongoPipeline': 300,
}
#将结果保存到Mongo数据库
MONGO_HOST = "127.0.0.1" # 主机IP
MONGO_PORT = 27017 # 端口号
MONGO_DB = "spider_data" # 库名
MONGO_COLL = "cnblogs_title" # collection名
#需要将调度器的类和去重的类替换为 Scrapy-Redis 提供的类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 7001 #Redis集群中其中一个节点的端口
#配置持久化
#Scrapy-Redis 默认会在爬取全部完成后清空爬取队列和去重指纹集合。
#SCHEDULER_PERSIST = True
#设置重爬
#SCHEDULER_FLUSH_ON_START = True
代码要改的地方有两处:
第一处是继承的RedisSpider
第二处就是start_urls改为了redis_key。
# -*- coding: utf-8 -*-
import scrapy
import datetime
from scrapy_redis.spiders import RedisSpider
class CnblogSpider(RedisSpider):
name = 'cnblog'
redis_key = "myspider:start_urls"
#start_urls = [f'https://www.cnblogs.com/c-x-a/default.html?page={i}' for i in range(1,2)]
def parse(self, response):
main_info_list_node = response.xpath('//div[@class="forFlow"]')
content_list_node = main_info_list_node.xpath(".//a[@class='postTitle2']/text()").extract()
for item in content_list_node:
url = response.url
title=item
crawl_date = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
item = {}
item['url'] = url
item['title'] = title.strip() if title else title
item['crawl_date'] = crawl_date
yield item
因为Scrapy-Redis是以Redis为队列进行消息共享的,所以我们的任务需要提前插入到数据库,它的key就叫我们指定的"myspider:start_urls"。
在之前创建好的redis集群中插入任务,首先使用集群的模式连接数据库
redis-cli -c -p 7000 #我的redis集群的一个Master节点端口
执行下面的语句插入任务
lpush myspider:start_urls https://www.cnblogs.com/c-x-a/default.html?page=1
lpush myspider:start_urls https://www.cnblogs.com/c-x-a/default.html?page=2
然后查看
lrange myspider:start_urls 0 10
看到我们的任务,好了任务插入成功了。
接下来就是运行代码了,运行完代码之后,去查看三处。
第一处,查看redis的任务发现任务已经没有了
(empty list or set)
第二处,查看mongo数据库,发现我们成功保存了结果。
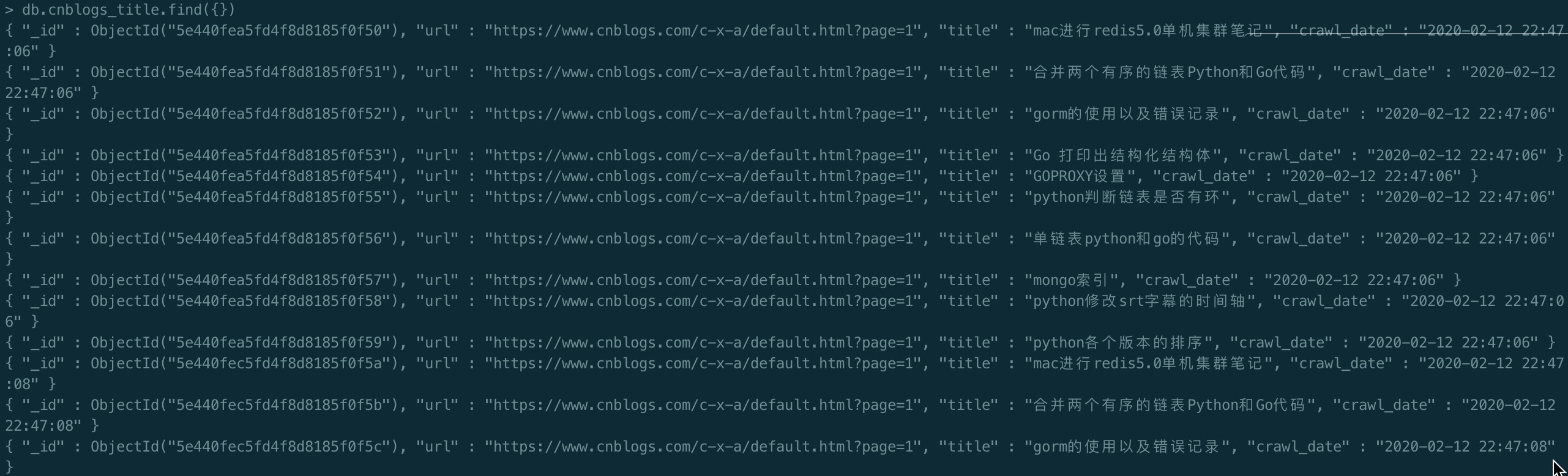
第三处,你会发现的你爬虫程序并没有结束,这个其实是正常的,因为我们使用了scrapy-redis之后,爬虫程序会一直取redis中的任务,如果没有任务了就等待,如果在redis插入了新的任务他就会继续进行爬虫程序,之后又进入等待任务的状态。
关注公众号:Python学习开发,后台回复:redis即可获取源码。
参考资料
https://segmentfault.com/a/1190000014333162?utm_source=channel-hottest
scrapy-redis分布式爬虫实战的更多相关文章
- scrapy进行分布式爬虫
今天,参照崔庆才老师的爬虫实战课程,实践了一下分布式爬虫,并没有之前想象的那么神秘,其实非常的简单,相信你看过这篇文章后,不出一小时,便可以动手完成一个分布式爬虫! 1.分布式爬虫原理 首先我们来看一 ...
- Scrapy 框架 分布式 爬虫
分布式 爬虫 scrapy-redis 实现 原生scrapy 无法实现 分布式 调度器和管道无法被分布式机群共享 环境安装 - pip install scrapy_redis 导包:from sc ...
- scrapy简单分布式爬虫
经过一段时间的折腾,终于整明白scrapy分布式是怎么个搞法了,特记录一点心得. 虽然scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘.有能人改变了scrapy的队列调度,将起始的网 ...
- 16 Scrapy之分布式爬虫
redis分布式部署 1.scrapy框架是否可以自己实现分布式? - 不可以.原因有二. 其一:因为多台机器上部署的scrapy会各自拥有各自的调度器,这样就使得多台机器无法分配start_urls ...
- scrapy补充-分布式爬虫
spiders 介绍:在项目中是创建爬虫程序的py文件 #1.Spiders是由一系列类(定义了一个网址或一组网址将被爬取)组成,具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. #2.换句 ...
- 【Python3爬虫】爬取美女图新姿势--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 【Python3爬虫】学习分布式爬虫第一步--Redis分布式爬虫初体验
一.写在前面 之前写的爬虫都是单机爬虫,还没有尝试过分布式爬虫,这次就是一个分布式爬虫的初体验.所谓分布式爬虫,就是要用多台电脑同时爬取数据,相比于单机爬虫,分布式爬虫的爬取速度更快,也能更好地应对I ...
- 从Redis分布式缓存实战入手到底层原理分析、面面俱到覆盖大厂面试考点
概述 官方说明 Redis官网 https://redis.io/ 最新版本6.2.6 Redis中文官网 http://www.redis.cn/ 不过中文官网的同步更新维护相对要滞后不少时间,但对 ...
- Redis分布式锁实战
什么是分布式锁 在单机部署的情况下,要想保证特定业务在顺序执行,通过JDK提供的synchronized关键字.Semaphore.ReentrantLock,或者我们也可以基于AQS定制化锁.单机部 ...
- 爬虫--scrapy+redis分布式爬取58同城北京全站租房数据
作业需求: 1.基于Spider或者CrawlSpider进行租房信息的爬取 2.本机搭建分布式环境对租房信息进行爬取 3.搭建多台机器的分布式环境,多台机器同时进行租房数据爬取 建议:用Pychar ...
随机推荐
- Echarts大数据可视化物流航向省份流向迁徙动态图,开发全解+完美参数注释
最近在研究Echarts的相关案例,毕竟现在大数据比较流行,比较了D3.js.superset等相关的图表插件,还是觉得echarts更简单上手些. 本文是以原生JS为基础,如果使用Vue.js的话, ...
- 微服务统计,分析,图表,监控一体化的HttpReports项目在.Net Core 中的使用
简单介绍 HttpReports 是 .Net Core 下的一个Web项目, 适用于WebAPI,Ocelot网关应用,MVC项目,非常适合针对微服务应用使用,通过中间件的形式集成到您的项目中,可以 ...
- SQL server 基本语句
--查询数据库是否存在 if exists ( select * from sysdatabases where [name]='TestDB') print 'Yes, the DB exists' ...
- Spring Boot2 系列教程(三十一)Spring Boot 构建 RESTful 风格应用
RESTful ,到现在相信已经没人不知道这个东西了吧!关于 RESTful 的概念,我这里就不做过多介绍了,传统的 Struts 对 RESTful 支持不够友好 ,但是 SpringMVC 对于 ...
- JWT (一):认识 JSON Web Token
JWT(一):认识 JSON WebToken JWT(二):使用 Java 实现 JWT 什么是 JWT? JSON Web Token(JWT)是一种开放标准(RFC 7519),它定义了一种紧凑 ...
- TensorFlow——Graph的基本操作
1.创建图 在tensorflow中,一个程序默认是建立一个图的,除了系统自动建立图以外,我们还可以手动建立图,并做一些其他的操作. 下面我们使用tf.Graph函数建立图,使用tf.get_defa ...
- docker-主从服务部署
欢迎访问我的博客http://www.liyblog.top 我的博客里会有更详细的信息,而且留言必回,手把手给你解释不懂的地方 1.mysql部署 mysql镜像拉取 docker pull ...
- Akka Java 文档 -- 容错
[转自: http://blog.csdn.net/zjw10wei321/article/details/46911825] 容错 实际中的故障处理 容错案例图解 容错案例所有源码 创建新的监管策略 ...
- 机器学习-决策树 Decision Tree
咱们正式进入了机器学习的模型的部分,虽然现在最火的的机器学习方面的库是Tensorflow, 但是这里还是先简单介绍一下另一个数据处理方面很火的库叫做sklearn.其实咱们在前面已经介绍了一点点sk ...
- Java电商支付系统手把手实现(二) - 数据库表设计的最佳实践
1 数据库设计 1.1 表关系梳理 仔细思考业务关系,得到如下表关系图 1.2 用户表结构 1.3 分类表结构 id=0为根节点,分类其实是树状结构 1.4 商品表结构 注意价格字段的类型为 deci ...