Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
8. Dataset (DataFrame) 的基础操作
这一章节主要目的是介绍 Dataset 的基础操作, 当然, DataFrame 就是 Dataset, 所以这些操作大部分也适用于 DataFrame
有类型的转换操作
无类型的转换操作
基础
Action空值如何处理
统计操作
8.1. 有类型操作
| 分类 | 算子 | 解释 |
|---|---|---|
|
转换 |
|
通过 |
|
|
|
|
|
|
|
|
|
|
 |
|
|
|
|
|
|
过滤 |
|
|
|
聚合 |
|
其实这也印证了分组后必须聚合的道理 |
|
切分 |
|
|
|
|
|
|
|
排序 |
|
|
|
|
其实 |
|
|
分区 |
|
减少分区, 此算子和 |
|
|
|
|
|
去重 |
|
使用 |
|
|
当  所以, 使用 |
|
|
集合操作 |
|
|
|
|
求得两个集合的交集 |
|
|
|
求得两个集合的并集 |
|
|
|
限制结果集数量 |
8.2. 无类型转换
| 分类 | 算子 | 解释 |
|---|---|---|
|
选择 |
|
|
|
|
在 |
|
|
|
通过 |
|
|
|
修改列名 |
|
|
剪除 |
drop |
剪掉某个列 |
|
聚合 |
groupBy |
按照给定的行进行分组 |
8.5. Column 对象
Column 表示了 Dataset 中的一个列, 并且可以持有一个表达式, 这个表达式作用于每一条数据, 对每条数据都生成一个值, 之所以有单独这样的一个章节是因为列的操作属于细节, 但是又比较常见, 会在很多算子中配合出现
| 分类 | 操作 | 解释 |
|---|---|---|
|
创建 |
|
单引号 |
|
|
同理, |
|
|
|
|
|
|
|
|
|
|
|
前面的 |
|
|
|
可以通过
|
|
|
别名和转换 |
|
|
|
|
通过 |
|
|
添加列 |
|
通过 |
|
操作 |
|
通过 |
|
|
通过 |
|
|
|
在排序的时候, 可以通过 |
9. 缺失值处理
DataFrame中什么时候会有无效值DataFrame如何处理无效的值DataFrame如何处理null
- 缺失值的处理思路
-
如果想探究如何处理无效值, 首先要知道无效值从哪来, 从而分析可能产生的无效值有哪些类型, 在分别去看如何处理无效值
- 什么是缺失值
-
一个值本身的含义是这个值不存在则称之为缺失值, 也就是说这个值本身代表着缺失, 或者这个值本身无意义, 比如说
null, 比如说空字符串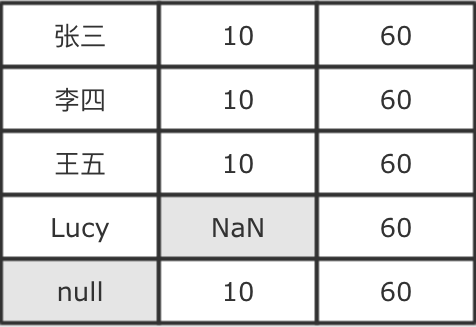
关于数据的分析其实就是统计分析的概念, 如果这样的话, 当数据集中存在缺失值, 则无法进行统计和分析, 对很多操作都有影响
- 缺失值如何产生的
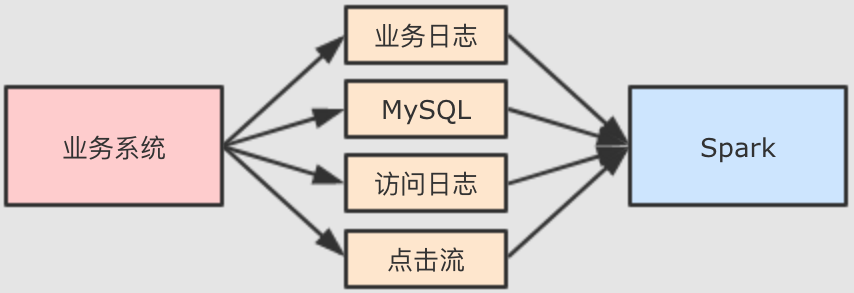
-
Spark 大多时候处理的数据来自于业务系统中, 业务系统中可能会因为各种原因, 产生一些异常的数据
例如说因为前后端的判断失误, 提交了一些非法参数. 再例如说因为业务系统修改
MySQL表结构产生的一些空值数据等. 总之在业务系统中出现缺失值其实是非常常见的一件事, 所以大数据系统就一定要考虑这件事. - 缺失值的类型
-
常见的缺失值有两种
null,NaN等特殊类型的值, 某些语言中null可以理解是一个对象, 但是代表没有对象,NaN是一个数字, 可以代表不是数字针对这一类的缺失值,
Spark提供了一个名为DataFrameNaFunctions特殊类型来操作和处理"Null","NA"," "等解析为字符串的类型, 但是其实并不是常规字符串数据针对这类字符串, 需要对数据集进行采样, 观察异常数据, 总结经验, 各个击破
DataFrameNaFunctions-
DataFrameNaFunctions使用Dataset的na函数来获取val df = ...
val naFunc: DataFrameNaFunctions = df.na当数据集中出现缺失值的时候, 大致有两种处理方式, 一个是丢弃, 一个是替换为某值,
DataFrameNaFunctions中包含一系列针对空值数据的方案DataFrameNaFunctions.drop可以在当某行中包含null或NaN的时候丢弃此行DataFrameNaFunctions.fill可以在将null和NaN充为其它值DataFrameNaFunctions.replace可以把null或NaN替换为其它值, 但是和fill略有一些不同, 这个方法针对值来进行替换
- 如何使用
SparkSQL处理null和NaN? -
首先要将数据读取出来, 此次使用的数据集直接存在
NaN, 在指定Schema后, 可直接被转为Double.NaNval schema = StructType(
List(
StructField("id", IntegerType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", IntegerType),
StructField("hour", IntegerType),
StructField("season", IntegerType),
StructField("pm", DoubleType)
)
) val df = spark.read
.option("header", value = true)
.schema(schema)
.csv("dataset/beijingpm_with_nan.csv")对于缺失值的处理一般就是丢弃和填充
- 丢弃包含
null和NaN的行 -
当某行数据所有值都是
null或者NaN的时候丢弃此行df.na.drop("all").show()当某行中特定列所有值都是
null或者NaN的时候丢弃此行df.na.drop("all", List("pm", "id")).show()当某行数据任意一个字段为
null或者NaN的时候丢弃此行df.na.drop().show()
df.na.drop("any").show()当某行中特定列任意一个字段为
null或者NaN的时候丢弃此行df.na.drop(List("pm", "id")).show()
df.na.drop("any", List("pm", "id")).show() - 填充包含
null和NaN的列 -
填充所有包含
null和NaN的列df.na.fill(0).show()填充特定包含
null和NaN的列df.na.fill(0, List("pm")).show()根据包含
null和NaN的列的不同来填充import scala.collection.JavaConverters._ df.na.fill(Map[String, Any]("pm" -> 0).asJava).show
- 丢弃包含
- 如何使用
SparkSQL处理异常字符串 ? -
读取数据集, 这次读取的是最原始的那个
PM数据集val df = spark.read
.option("header", value = true)
.csv("dataset/BeijingPM20100101_20151231.csv")使用函数直接转换非法的字符串
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season,
when('PM_Dongsi === "NA", 0)
.otherwise('PM_Dongsi cast DoubleType)
.as("pm"))
.show()使用
where直接过滤df.select('No as "id", 'year, 'month, 'day, 'hour, 'season, 'PM_Dongsi)
.where('PM_Dongsi =!= "NA")
.show()使用
DataFrameNaFunctions替换, 但是这种方式被替换的值和新值必须是同类型df.select('No as "id", 'year, 'month, 'day, 'hour, 'season, 'PM_Dongsi)
.na.replace("PM_Dongsi", Map("NA" -> "NaN"))
.show()
10. 聚合
groupByrollupcubepivotRelationalGroupedDataset上的聚合操作
groupBy
-
groupBy算子会按照列将Dataset分组, 并返回一个RelationalGroupedDataset对象, 通过RelationalGroupedDataset可以对分组进行聚合- Step 1: 加载实验数据
- Step 2: 使用
functions函数进行聚合 - Step 3: 除了使用
functions进行聚合, 还可以直接使用RelationalGroupedDataset的API进行聚合
- 多维聚合
-
我们可能经常需要针对数据进行多维的聚合, 也就是一次性统计小计, 总计等, 一般的思路如下
- Step 1: 准备数据
- Step 2: 进行多维度聚合
大家其实也能看出来, 在一个数据集中又小计又总计, 可能需要多个操作符, 如何简化呢? 请看下面
rollup操作符-
rollup操作符其实就是groupBy的一个扩展,rollup会对传入的列进行滚动groupBy,groupBy的次数为列数量+ 1, 最后一次是对整个数据集进行聚合- Step 1: 创建数据集
- Step 2: 如果使用基础的 groupBy 如何实现效果?
很明显可以看到, 在上述案例中,
rollup就相当于先按照city,year进行聚合, 后按照city进行聚合, 最后对整个数据集进行聚合, 在按照city聚合时,year列值为null, 聚合整个数据集的时候, 除了聚合列, 其它列值都为null - 使用
rollup完成pm值的统计 -
上面的案例使用
rollup来实现会非常的简单 cube-
cube的功能和rollup是一样的, 但也有区别, 区别如下rollup(A, B).sum©其结果集中会有三种数据形式:
A B C,A null C,null null C不知道大家发现没, 结果集中没有对
B列的聚合结果cube(A, B).sum©其结果集中会有四种数据形式:
A B C,A null C,null null C,null B C不知道大家发现没, 比
rollup的结果集中多了一个null B C, 也就是说,rollup只会按照第一个列来进行组合聚合, 但是cube会将全部列组合聚合
SparkSQL中支持的SQL语句实现cube功能-
SparkSQL支持GROUPING SETS语句, 可以随意排列组合空值分组聚合的顺序和组成, 既可以实现cube也可以实现rollup的功能 RelationalGroupedDataset-
常见的
RelationalGroupedDataset获取方式有三种groupByrollupcube
无论通过任何一种方式获取了
RelationalGroupedDataset对象, 其所表示的都是是一个被分组的DataFrame, 通过这个对象, 可以对数据集的分组结果进行聚合val groupedDF: RelationalGroupedDataset = pmDF.groupBy('year)需要注意的是,
RelationalGroupedDataset并不是DataFrame, 所以其中并没有DataFrame的方法, 只有如下一些聚合相关的方法, 如下这些方法在调用过后会生成DataFrame对象, 然后就可以再次使用DataFrame的算子进行操作了操作符 解释 avg求平均数
count求总数
max求极大值
min求极小值
mean求均数
sum求和
agg聚合, 可以使用
sql.functions中的函数来配合进行操作pmDF.groupBy('year)
.agg(avg('pm) as "pm_avg")
11. 连接
无类型连接
join连接类型
Join Types
- 无类型连接算子
join的API -
- Step 1: 什么是连接
-
按照 PostgreSQL 的文档中所说, 只要能在一个查询中, 同一时间并发的访问多条数据, 就叫做连接.
做到这件事有两种方式
一种是把两张表在逻辑上连接起来, 一条语句中同时访问两张表
select * from user join address on user.address_id = address.id还有一种方式就是表连接自己, 一条语句也能访问自己中的多条数据
select * from user u1 join (select * from user) u2 on u1.id = u2.id
- Step 2:
join算子的使用非常简单, 大致的调用方式如下 -
join(right: Dataset[_], joinExprs: Column, joinType: String): DataFrame - Step 3: 简单连接案例
-
表结构如下
+---+------+------+ +---+---------+
| id| name|cityId| | id| name|
+---+------+------+ +---+---------+
| 0| Lucy| 0| | 0| Beijing|
| 1| Lily| 0| | 1| Shanghai|
| 2| Tim| 2| | 2|Guangzhou|
| 3|Danial| 0| +---+---------+
+---+------+------+如果希望对这两张表进行连接, 首先应该注意的是可以连接的字段, 比如说此处的左侧表
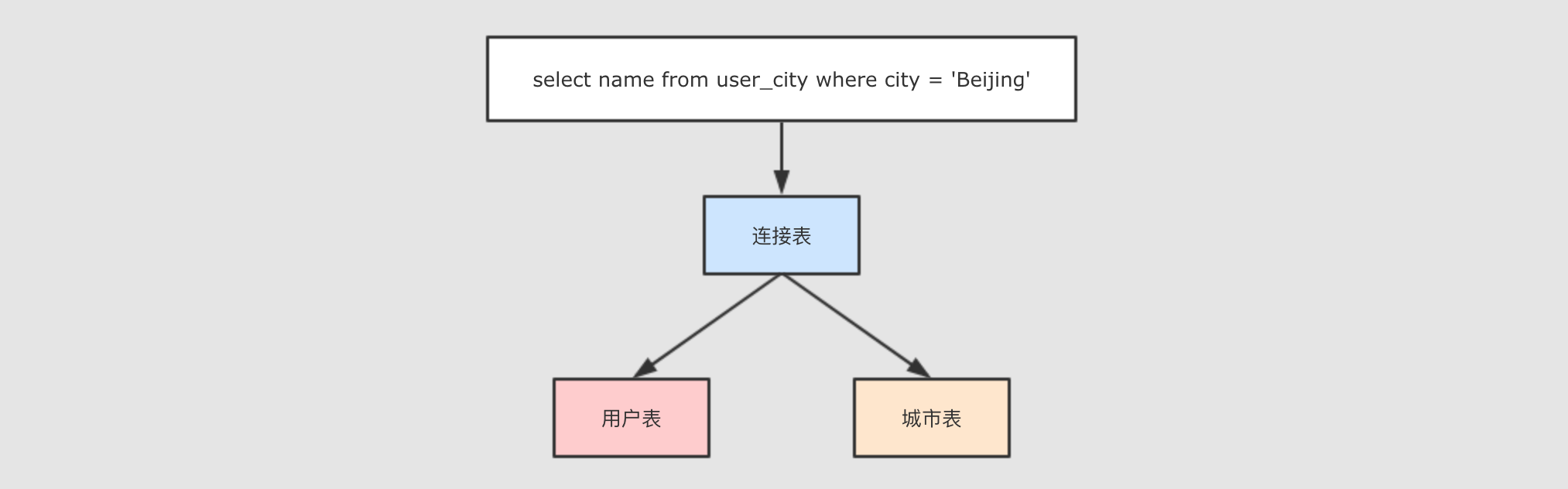
cityId和右侧表id就是可以连接的字段, 使用join算子就可以将两个表连接起来, 进行统一的查询 - Step 4: 什么是连接?
-
现在两个表连接得到了如下的表
+---+------+---------+
| id| name| city|
+---+------+---------+
| 0| Lucy| Beijing|
| 1| Lily| Beijing|
| 2| Tim|Guangzhou|
| 3|Danial| Beijing|
+---+------+---------+通过对这张表的查询, 这个查询是作用于两张表的, 所以是同一时间访问了多条数据
spark.sql("select name from user_city where city = 'Beijing'").show() /**
* 执行结果
*
* +------+
* | name|
* +------+
* | Lucy|
* | Lily|
* |Danial|
* +------+
*/
- 连接类型
-
如果要运行如下代码, 需要先进行数据准备
private val spark = SparkSession.builder()
.master("local[6]")
.appName("aggregation")
.getOrCreate() import spark.implicits._ val person = Seq((0, "Lucy", 0), (1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 3))
.toDF("id", "name", "cityId")
person.createOrReplaceTempView("person") val cities = Seq((0, "Beijing"), (1, "Shanghai"), (2, "Guangzhou"))
.toDF("id", "name")
cities.createOrReplaceTempView("cities")连接类型 类型字段 解释 交叉连接
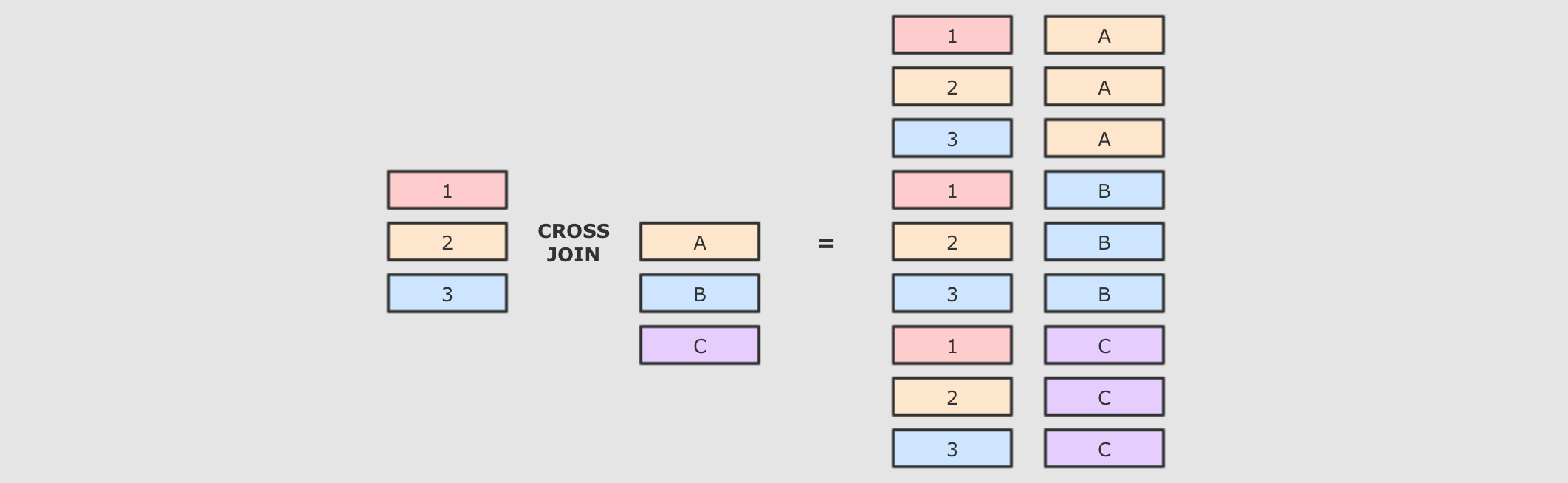
cross- 解释
-
交叉连接就是笛卡尔积, 就是两个表中所有的数据两两结对
交叉连接是一个非常重的操作, 在生产中, 尽量不要将两个大数据集交叉连接, 如果一定要交叉连接, 也需要在交叉连接后进行过滤, 优化器会进行优化
SQL语句-
select * from person cross join cities Dataset操作-
person.crossJoin(cities)
.where(person.col("cityId") === cities.col("id"))
.show()
内连接
inner- 解释
-
内连接就是按照条件找到两个数据集关联的数据, 并且在生成的结果集中只存在能关联到的数据

SQL语句-
select * from person inner join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "inner")
.show()
全外连接
outer,full,fullouter- 解释
-
内连接和外连接的最大区别, 就是内连接的结果集中只有可以连接上的数据, 而外连接可以包含没有连接上的数据, 根据情况的不同, 外连接又可以分为很多种, 比如所有的没连接上的数据都放入结果集, 就叫做全外连接

SQL语句-
select * from person full outer join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "full") // "outer", "full", "full_outer"
.show()
左外连接
leftouter,left- 解释
-
左外连接是全外连接的一个子集, 全外连接中包含左右两边数据集没有连接上的数据, 而左外连接只包含左边数据集中没有连接上的数据

SQL语句-
select * from person left join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "left") // leftouter, left
.show()
LeftAntileftanti- 解释
-
LeftAnti是一种特殊的连接形式, 和左外连接类似, 但是其结果集中没有右侧的数据, 只包含左边集合中没连接上的数据
SQL语句-
select * from person left anti join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "left_anti")
.show()
LeftSemileftsemi- 解释
-
和
LeftAnti恰好相反,LeftSemi的结果集也没有右侧集合的数据, 但是只包含左侧集合中连接上的数据
SQL语句-
select * from person left semi join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "left_semi")
.show()
右外连接
rightouter,right- 解释
-
右外连接和左外连接刚好相反, 左外是包含左侧未连接的数据, 和两个数据集中连接上的数据, 而右外是包含右侧未连接的数据, 和两个数据集中连接上的数据

SQL语句-
select * from person right join cities on person.cityId = cities.id Dataset操作-
person.join(right = cities,
joinExprs = person("cityId") === cities("id"),
joinType = "right") // rightouter, right
.show()
- [扩展] 广播连接
-
- Step 1: 正常情况下的
Join过程 -
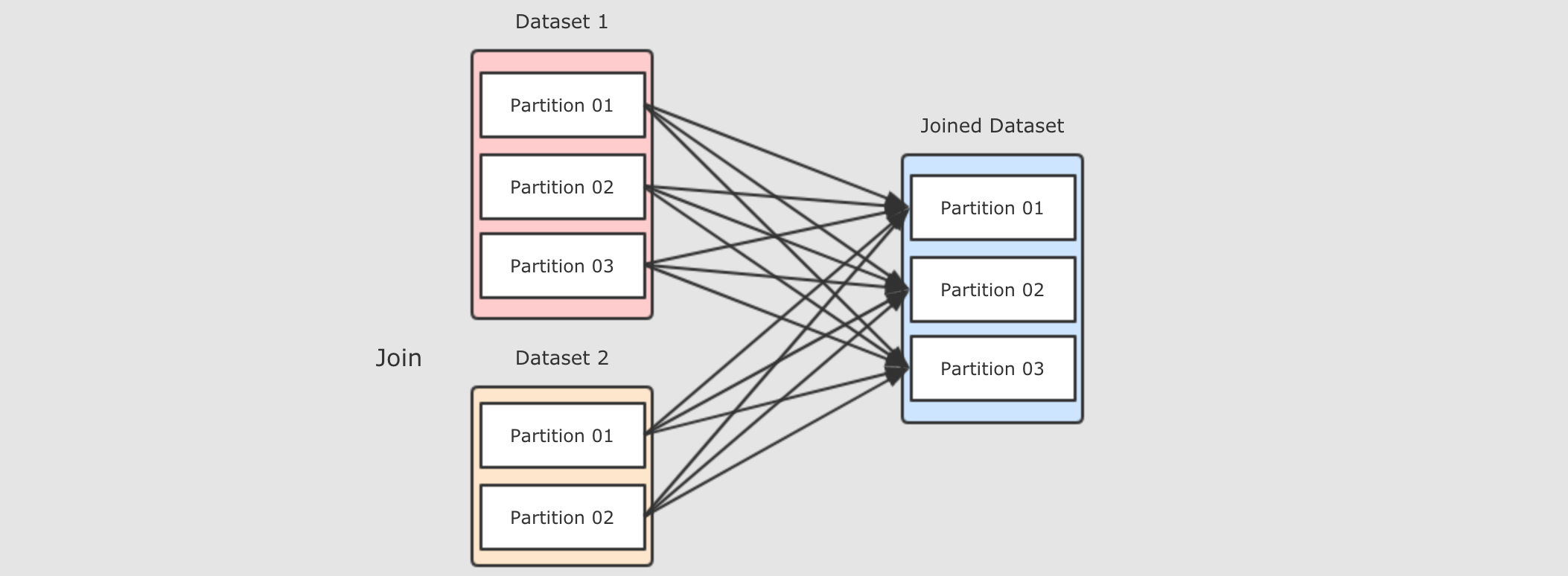
Join会在集群中分发两个数据集, 两个数据集都要复制到Reducer端, 是一个非常复杂和标准的ShuffleDependency, 有什么可以优化效率吗? - Step 2:
Map端Join -
前面图中看的过程, 之所以说它效率很低, 原因是需要在集群中进行数据拷贝, 如果能减少数据拷贝, 就能减少开销
如果能够只分发一个较小的数据集呢?
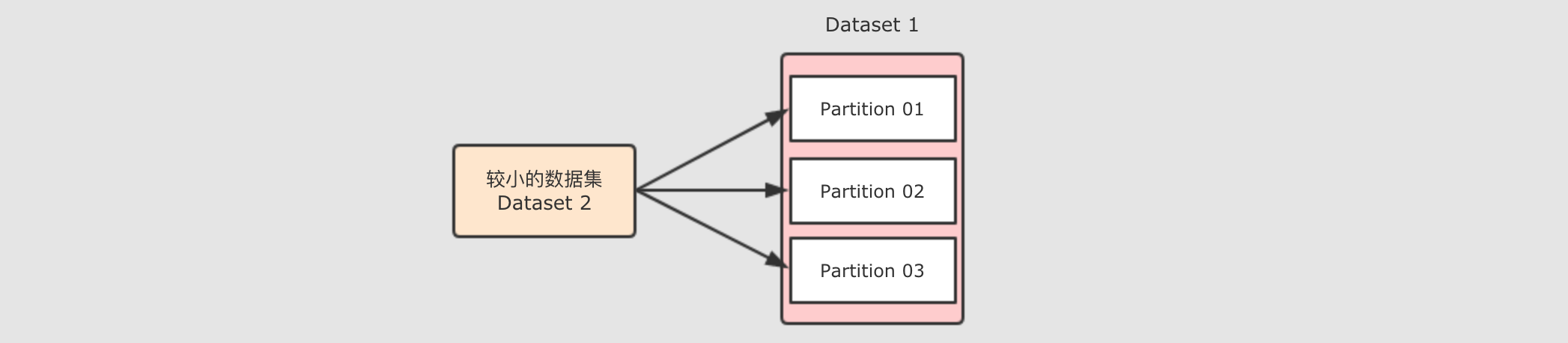
可以将小数据集收集起来, 分发给每一个
Executor, 然后在需要Join的时候, 让较大的数据集在Map端直接获取小数据集, 从而进行Join, 这种方式是不需要进行Shuffle的, 所以称之为Map端Join - Step 3:
Map端Join的常规实现 -
如果使用
RDD的话, 该如何实现Map端Join呢?val personRDD = spark.sparkContext.parallelize(Seq((0, "Lucy", 0),
(1, "Lily", 0), (2, "Tim", 2), (3, "Danial", 3))) val citiesRDD = spark.sparkContext.parallelize(Seq((0, "Beijing"),
(1, "Shanghai"), (2, "Guangzhou"))) val citiesBroadcast = spark.sparkContext.broadcast(citiesRDD.collectAsMap()) val result = personRDD.mapPartitions(
iter => {
val citiesMap = citiesBroadcast.value
// 使用列表生成式 yield 生成列表
val result = for (person <- iter if citiesMap.contains(person._3))
yield (person._1, person._2, citiesMap(person._3))
result
}
).collect() result.foreach(println(_)) - Step 4: 使用
Dataset实现Join的时候会自动进行Map端Join -
自动进行
Map端Join需要依赖一个系统参数spark.sql.autoBroadcastJoinThreshold, 当数据集小于这个参数的大小时, 会自动进行Map端Join如下, 开启自动
Joinprintln(spark.conf.get("spark.sql.autoBroadcastJoinThreshold").toInt / 1024 / 1024) println(person.crossJoin(cities).queryExecution.sparkPlan.numberedTreeString)当关闭这个参数的时候, 则不会自动 Map 端 Join 了
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
println(person.crossJoin(cities).queryExecution.sparkPlan.numberedTreeString) - Step 5: 也可以使用函数强制开启 Map 端 Join
-
在使用 Dataset 的 join 时, 可以使用 broadcast 函数来实现 Map 端 Join
import org.apache.spark.sql.functions._
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
println(person.crossJoin(broadcast(cities)).queryExecution.sparkPlan.numberedTreeString)即使是使用 SQL 也可以使用特殊的语法开启
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", -1)
val resultDF = spark.sql(
"""
|select /*+ MAPJOIN (rt) */ * from person cross join cities rt
""".stripMargin)
println(resultDF.queryExecution.sparkPlan.numberedTreeString)
- Step 1: 正常情况下的
12. 窗口函数
- 目标和步骤(详见代码)
-
- 目标
-
理解窗口操作的语义, 掌握窗口函数的使用
- 步骤
-
案例1, 第一名和第二名
窗口函数介绍
案例2, 最优差值
12.1. 第一名和第二名案例
- 目标和步骤
-
- 目标
-
掌握如何使用
SQL和DataFrame完成名次统计, 并且对窗口函数有一个模糊的认识, 方便后面的启发 - 步骤
-
需求介绍
代码编写
- 需求介绍
-
数据集
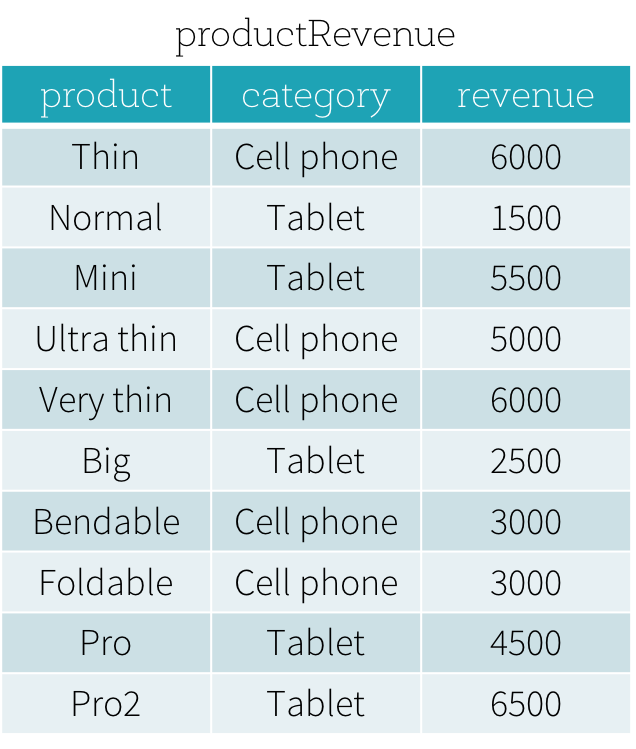
product: 商品名称categroy: 类别revenue: 收入
需求分析
- 需求
-
从数据集中得到每个类别收入第一的商品和收入第二的商品
关键点是, 每个类别, 收入前两名

- 方案1: 使用常见语法子查询
-
问题1:
Spark和Hive这样的系统中, 有自增主键吗? 没有问题2: 为什么分布式系统中很少见自增主键? 因为分布式环境下数据在不同的节点中, 很难保证顺序
解决方案: 按照某一列去排序, 取前两条数据
遗留问题: 不容易在分组中取每一组的前两个
SELECT * FROM productRevenue ORDER BY revenue LIMIT 2 - 方案2: 计算每一个类别的按照收入排序的序号, 取每个类别中的前两个
-
- 思路步骤
-
按照类别分组
每个类别中的数据按照收入排序
为排序过的数据增加编号
取得每个类别中的前两个数据作为最终结果
使用
SQL就不太容易做到, 需要一个语法, 叫做窗口函数
- 代码编写
-
创建初始环境
创建新的类
WindowFunction编写测试方法
初始化
SparkSession创建数据集
方式一:
SQL语句::方式二: 使用
DataFrame的命令式API::WindowSpec: 窗口的描述符, 描述窗口应该是怎么样的dense_rank() over window: 表示一个叫做dense_rank()的函数作用于每一个窗口
- 总结
-
在
Spark中, 使用SQL或者DataFrame都可以操作窗口窗口的使用有两个步骤
定义窗口规则
定义窗口函数
在不同的范围内统计名次时, 窗口函数非常得力
12.2. 窗口函数
- 目标和步骤
-
- 目标
-
了解窗口函数的使用方式, 能够使用窗口函数完成统计
- 步骤
-
窗口函数的逻辑
窗口定义部分
统计函数部分
- 窗口函数的逻辑
-
- 从 逻辑 上来讲, 窗口函数执行步骤大致可以分为如下几步
-
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank根据
PARTITION BY category, 对数据进行分组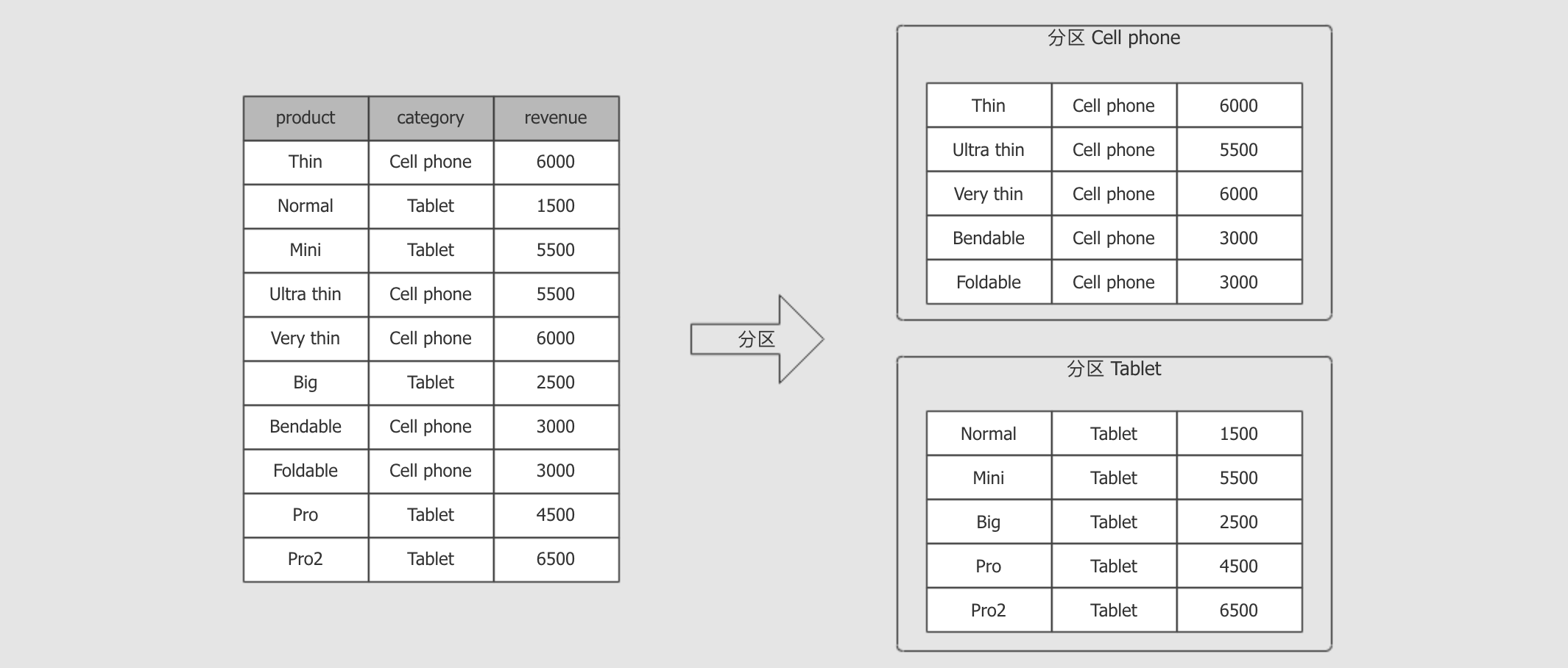
分组后, 根据
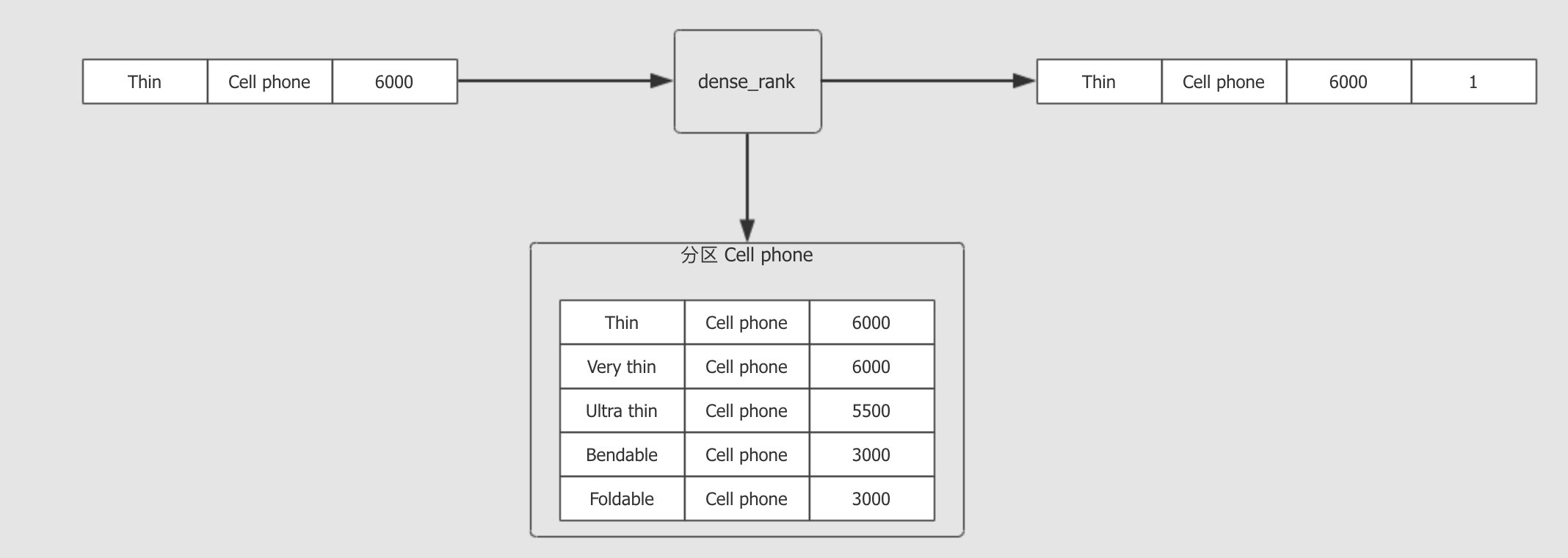
ORDER BY revenue DESC对每一组数据进行排序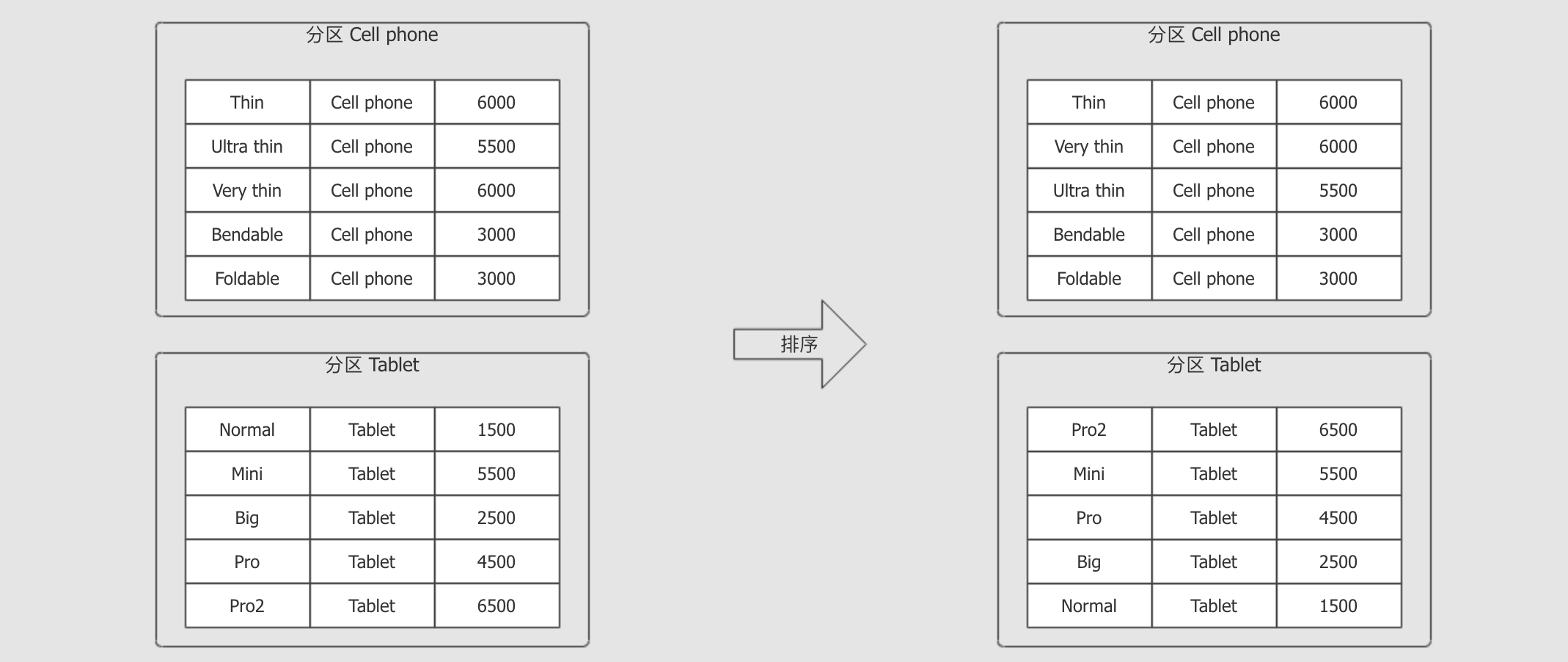
在 每一条数据 到达窗口函数时, 套入窗口内进行计算
- 从语法的角度上讲, 窗口函数大致分为两个部分
-
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank函数部分
dense_rank()窗口定义部分
PARTITION BY category ORDER BY revenue DESC
窗口函数和
GroupBy最大的区别, 就是GroupBy的聚合对每一个组只有一个结果, 而窗口函数可以对每一条数据都有一个结果说白了, 窗口函数其实就是根据当前数据, 计算其在所在的组中的统计数据
- 窗口定义部分
-
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rankPartition定义控制哪些行会被放在一起, 同时这个定义也类似于
Shuffle, 会将同一个分组的数据放在同一台机器中处理Order定义在一个分组内进行排序, 因为很多操作, 如
rank, 需要进行排序Frame定义- 释义
-
窗口函数会针对 每一个组中的每一条数据 进行统计聚合或者
rank, 一个组又称为一个Frame分组由两个字段控制,
Partition在整体上进行分组和分区而通过
Frame可以通过 当前行 来更细粒度的分组控制举个栗子, 例如公司每月销售额的数据, 统计其同比增长率, 那就需要把这条数据和前面一条数据进行结合计算了
- 有哪些控制方式?
-
Row Frame通过
"行号"来表示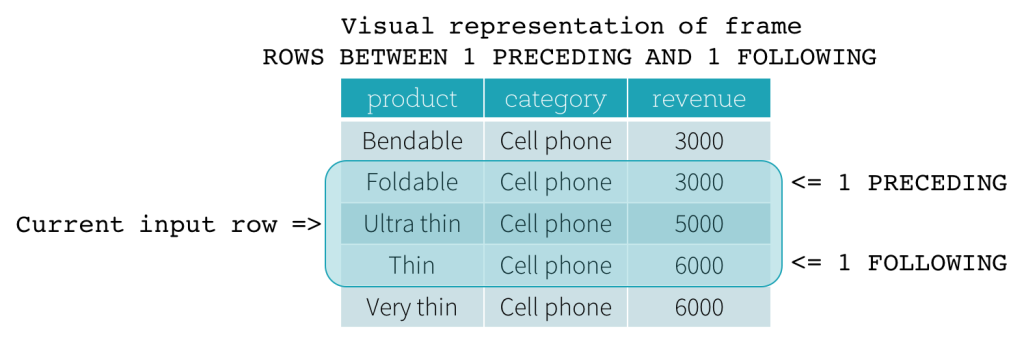
Range Frame通过某一个列的差值来表示

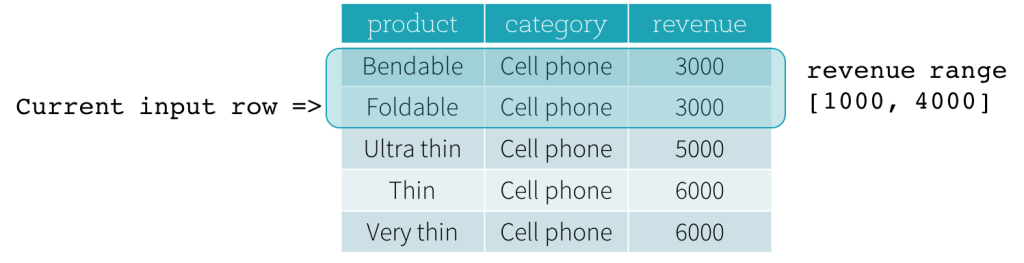
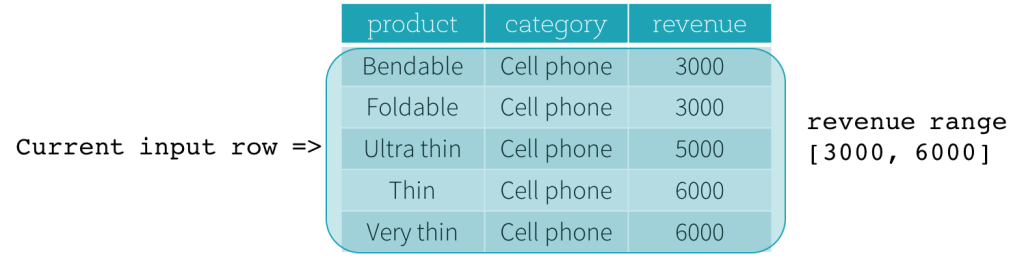

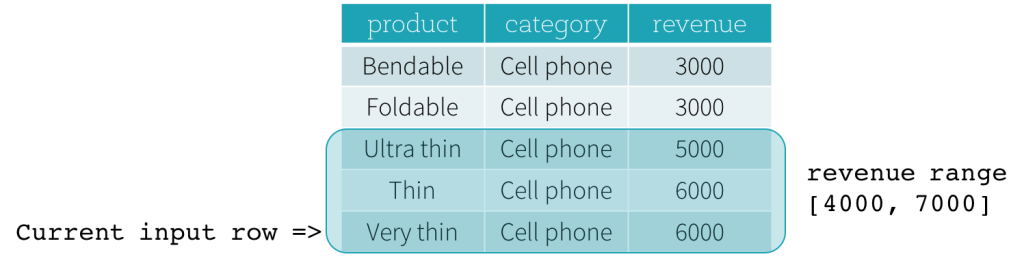
- 函数部分
-
dense_rank() OVER (PARTITION BY category ORDER BY revenue DESC) as rank如下是支持的窗口函数
类型 函数 解释 排名函数
rank排名函数, 计算当前数据在其
Frame中的位置如果有重复, 则重复项后面的行号会有空挡
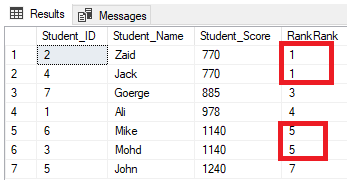
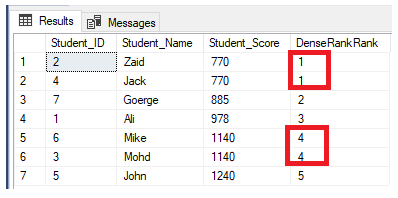
dense_rank和 rank 一样, 但是结果中没有空挡
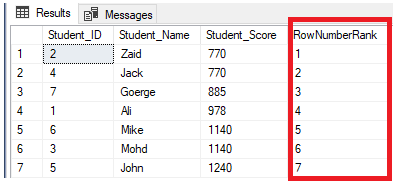
row_number和 rank 一样, 也是排名, 但是不同点是即使有重复想, 排名依然增长
分析函数
first_value获取这个组第一条数据
last_value获取这个组最后一条数据
laglag(field, n)获取当前数据的field列向前n条数据leadlead(field, n)获取当前数据的field列向后n条数据聚合函数
*所有的
functions中的聚合函数都支持 - 总结
-
窗口操作分为两个部分
窗口定义, 定义时可以指定
Partition,Order,Frame函数操作, 可以使用三大类函数, 排名函数, 分析函数, 聚合函数
12.3. 最优差值案例
- 目标和步骤
-
- 目标
-
能够针对每个分类进行计算, 求得常见指标, 并且理解实践上面的一些理论
- 步骤
-
需求介绍
代码实现
- 需求介绍
-
源数据集
需求
统计每个商品和此品类最贵商品之间的差值
目标数据集

- 代码实现
-
- 步骤
-
创建数据集
创建窗口, 按照
revenue分组, 并倒叙排列应用窗口
- (详见代码)
Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作的更多相关文章
- 第七节,TensorFlow编程基础案例-TensorBoard以及常用函数、共享变量、图操作(下)
这一节主要来介绍TesorFlow的可视化工具TensorBoard,以及TensorFlow基础类型定义.函数操作,后面又介绍到了共享变量和图操作. 一 TesnorBoard可视化操作 Tenso ...
- Update(Stage4):sparksql:第1节 SparkSQL_使用场景_优化器_Dataset & 第2节 SparkSQL读写_hive_mysql_案例
目标 SparkSQL 是什么 SparkSQL 如何使用 Table of Contents 1. SparkSQL 是什么 1.1. SparkSQL 的出现契机 1.2. SparkSQL 的适 ...
- Update(Stage4):spark_rdd算子:第2节 RDD_action算子_分区_缓存:算子和分区
一.reduce和reduceByKey: 二.:RDD 的算子总结 RDD 的算子大部分都会生成一些专用的 RDD map, flatMap, filter 等算子会生成 MapPartitions ...
- Update(Stage4):Structured Streaming_介绍_案例
1. 回顾和展望 1.1. Spark 编程模型的进化过程 1.2. Spark 的 序列化 的进化过程 1.3. Spark Streaming 和 Structured Streaming 2. ...
- Spark Dataset DataFrame 操作
Spark Dataset DataFrame 操作 相关博文参考 sparksql中dataframe的用法 一.Spark2 Dataset DataFrame空值null,NaN判断和处理 1. ...
- RDD/Dataset/DataFrame互转
1.RDD -> Dataset val ds = rdd.toDS() 2.RDD -> DataFrame val df = spark.read.json(rdd) 3.Datase ...
- Spark提高篇——RDD/DataSet/DataFrame(一)
该部分分为两篇,分别介绍RDD与Dataset/DataFrame: 一.RDD 二.DataSet/DataFrame 先来看下官网对RDD.DataSet.DataFrame的解释: 1.RDD ...
- Spark提高篇——RDD/DataSet/DataFrame(二)
该部分分为两篇,分别介绍RDD与Dataset/DataFrame: 一.RDD 二.DataSet/DataFrame 该篇主要介绍DataSet与DataFrame. 一.生成DataFrame ...
- RDD&Dataset&DataFrame
Dataset创建 object DatasetCreation { def main(args: Array[String]): Unit = { val spark = SparkSession ...
随机推荐
- 【网易官方】极客战记(codecombat)攻略-地牢-祸之火焰
关卡连接: https://codecombat.163.com/play/level/banefire 绕着火焰跳舞,否则你的骨头下次就会被烧着 默认代码 # 食人魔看上去又大又慢,这是你的机会. ...
- web前端-基础篇
该篇仅是本人学习前端时,做的备忘笔记: 一.背景图片设置: 设置背景图时的css代码:background-image:url(图片的url路径); ps:设置好这个背景后请一定要设置该背景图片的大小 ...
- 8.14-T1村通网(pupil)
题目大意 要建设一个村庄的网络 有两种操作可选 1.给中国移动交宽带费,直接连网,花费为 A. 2.向另外一座有网的建筑,安装共享网线,花费为 B×两者曼哈顿距离. 题解 显然的最小生成树的题 见 ...
- sqlmap使用教程(超详细)
-u 指定目标URL (可以是http协议也可以是https协议) -d 连接数据库 --dbs 列出所有的数据库 --current-db 列出当前数据库 --tables 列出当前的表 --col ...
- Maven安装与学习
一.安装 1.下载http://maven.apache.org/download.cgi 2.选择zip格式 安装完后解压到某一位置(E:\xitong\major\apache-maven-3.6 ...
- MySQL执行外部sql脚本文件的命令
sql脚本是包含一到多个sql命令的sql语句,我们可以将这些sql脚本放在一个文本文件中(我们称之为“sql脚本文件”),然后通过相关的命令执行这个sql脚本文件.基本步骤如下:1.创建包含sql命 ...
- 关于Spring+mybatis使用@Transactional注解事物没有生效的问题
控制台日志信息: was not registered for synchronization because synchronization is not active JDBC Connectio ...
- vue指令及组件
复习 """ vue: 为什么选择vue - 综合其他框架优点,轻量级,中文API,数据驱动,组件化开发,数据的双向绑定,虚拟DO 渐进式js框架 - 选择性控制 - 创 ...
- 数据库程序接口——JDBC——API解读第二篇——执行SQL的核心对象
结构图 核心对象 Statement Statement主要用来执行SQL语句.它执行SQL语句的步骤为: 第一步:创建statement对象. 第二步:配置statement对象,此步骤可以忽略. ...
- RedHat7 / CentOS 7 忘记root密码修改
摘自:https://blog.csdn.net/bubbleyang/article/details/91360856 进入互动式命令环境 开机出现 grub boot loader 开机选项菜单时 ...