【笔记】机器学习 - 李宏毅 - 4 - Gradient Descent
梯度下降 Gradient Descent
梯度下降是一种迭代法(与最小二乘法不同),目标是解决最优化问题:\({\theta}^* = arg min_{\theta} L({\theta})\),其中\({\theta}\)是一个向量,梯度是偏微分。
为了让梯度下降达到更好的效果,有以下这些Tips:
1.调整学习率
梯度下降的过程,应当在刚开始的时候,应该步长大一些,以便更快迭代,当靠近目标时,步长调小一些。
虽然式子中的微分有这个效果,但同时改变一下学习率的值,可以很大程度加速这个过程。
比如说用 \(1/t\) 衰减:\({\eta}^t = {\eta}/\sqrt{(t + 1)}\)
另外,不同的参数应当给不同的学习率。
Adagrad方法
Adagrad是再除以一个参数之前所有微分的均方根。

消去\(\sqrt{(t + 1)}\)参数后得到:
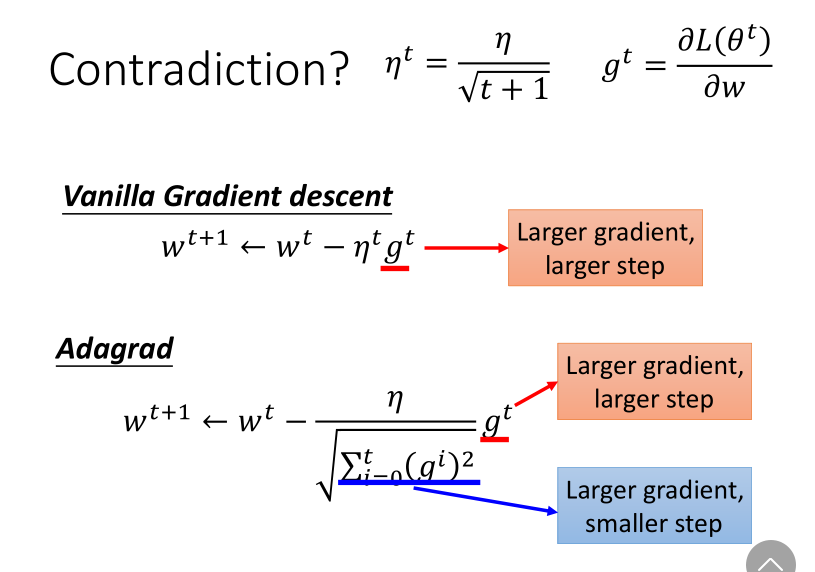
分子分母的作用形成了反差,一个增加步长,一个减小步长。
对此的一种解释是,为了避免迭代突然加快,或者突然减慢。
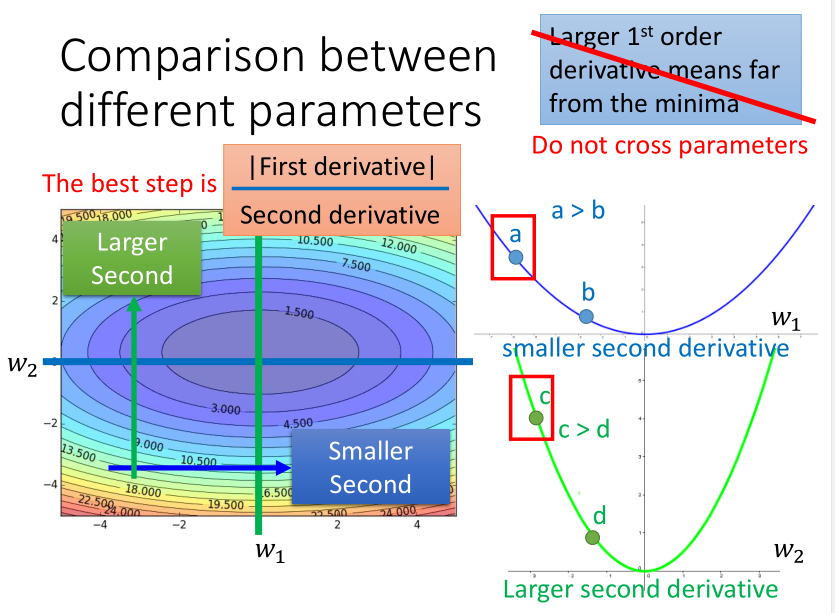
另外一种解释是,以二次凸函数举例,最佳迭代步长直观看是与一次微分成正比的。
但如果考虑跨参数比较的话(不仅看\(x\)),又会发现这个结论不完善,其实它又与二次微分成反比,所以要综合考虑两者。
而二次微分比较难计算,需要更多的时间,所以一般就采用一次微分的均方根来模拟它了。
2.随机梯度下降

随机梯度下降和批量梯度下降不同的是,它不需要把所有训练数据都考虑进来再迭代,而是算出其中一个样本的梯度就迭代一次。
这种方法虽然很快,但数据的震荡也很明显。(小批量梯度下降mini-batch gradient descent是算出其中一部分样本的梯度,是一种折中方法)
3.特征缩放

两个参数的变化范围不同,则在考虑学习率的时候需要分别考虑,比较难处理,而右边的情形就比较容易更新参数,这就是进行特征缩放的原因。
最常见的做法就是直接将其正则化。

梯度下降的原理
为什么每次迭代时,损失函数一定会变小呢?不一定。
可以用泰勒公式可以做解释,一阶的形式非常类似,无论是微分还是偏微分。所以只有当步长较小时,才符合条件。

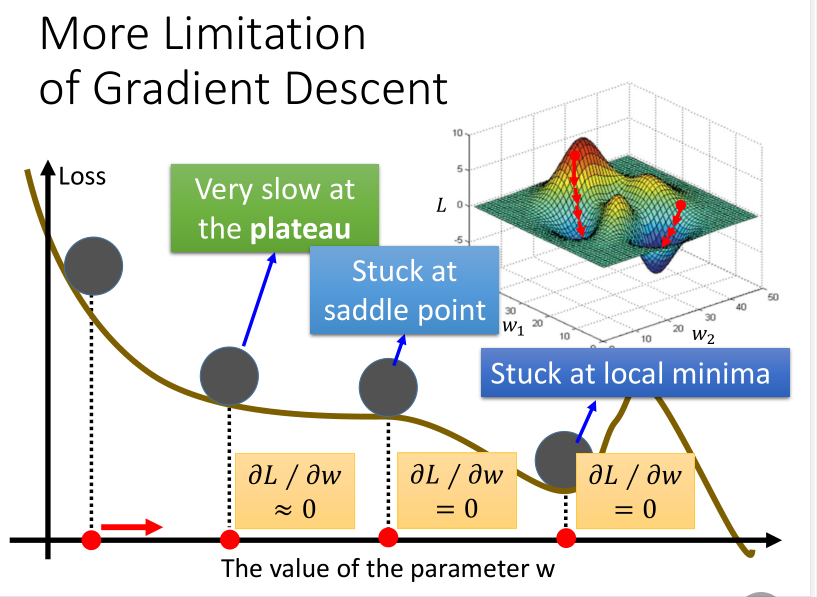
梯度下降的局限
梯度下降方法也有它自身的局限性,如下图所示:
【笔记】机器学习 - 李宏毅 - 4 - Gradient Descent的更多相关文章
- 深度学习课程笔记(四)Gradient Descent 梯度下降算法
深度学习课程笔记(四)Gradient Descent 梯度下降算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 李宏毅老师机器学习课程笔记_ML Lecture 3-1: Gradient Descent
引言: 这个系列的笔记是台大李宏毅老师机器学习的课程笔记 视频链接(bilibili):李宏毅机器学习(2017) 另外已经有有心的同学做了速记并更新在github上:李宏毅机器学习笔记(LeeML- ...
- 吴恩达机器学习笔记 - cost function and gradient descent
一.简介 cost fuction是用来判断机器预算值和实际值得误差,一般来说训练机器学习的目的就是希望将这个cost function减到最小.本文会介绍如何找到这个最小值. 二.线性回归的cost ...
- 李宏毅机器学习笔记2:Gradient Descent(附带详细的原理推导过程)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 机器学习笔记:Gradient Descent
机器学习笔记:Gradient Descent http://www.cnblogs.com/uchihaitachi/archive/2012/08/16/2642720.html
- 斯坦福机器学习视频笔记 Week1 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 斯坦福机器学习视频笔记 Week1 线性回归和梯度下降 Linear Regression and Gradient Descent
最近开始学习Coursera上的斯坦福机器学习视频,我是刚刚接触机器学习,对此比较感兴趣:准备将我的学习笔记写下来, 作为我每天学习的签到吧,也希望和各位朋友交流学习. 这一系列的博客,我会不定期的更 ...
- 李宏毅机器学习课程---4、Gradient Descent (如何优化 )
李宏毅机器学习课程---4.Gradient Descent (如何优化) 一.总结 一句话总结: 调整learning rates:Tuning your learning rates 随机Grad ...
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
随机推荐
- 通过欧拉计划学Rust编程(第54题)
由于研究Libra等数字货币编程技术的需要,学习了一段时间的Rust编程,一不小心刷题上瘾. 刷完欧拉计划中的63道基础题,能学会Rust编程吗? "欧拉计划"的网址: https ...
- AWS的边缘计算平台GreenGrass和IoT
AWS的边缘计算平台GreenGrass和IoT 为什么需要有边缘计算? 如今公有云和私有云平台提供的服务已经连接上了绝大多数的桌面设备和移动设备.但是更多的设备比如,车辆,工程机械,医疗设备,无人机 ...
- Java中的8种基本数据类型
JAVA中的8种基本数据类型:byte short int long float double char boolean 特别说明: 1)char类型占2个字节,可以表示汉字.汉字和英文字符都占2个字 ...
- How to make as map two or more device located in the same media pool by using ddboost + nw
How to make as map two or more device located in the same media pool by using ddboost + nw ? That is ...
- Shell: 定期存档日志文件
简介 对于日志的分割删除我们一般会使用logratate,但对于项目较多的情况下,会让开发直接将日志分割写在代码里面,对于分割后过期的日志定期删除就很有必要,不然膨胀的日志会占满你的磁盘,将多余的日志 ...
- OpenCV3入门(八)图像边缘检测
1.边缘检测基础 图像的边缘是图像的基本特征,边缘点是灰度阶跃变化的像素点,即灰度值的导数较大或极大的地方,边缘检测是图像识别的第一步.用图像的一阶微分和二阶微分来增强图像的灰度跳变,而边缘也就是灰度 ...
- LwIP与IPv6
2.0.0中才开始支持IPv6,在此版本中改写了SNMP,但还没有IPv6的统计量.目前最新版本是2.0.2,其中SNMP也没有IPv6统计量(哪些?与IP的统计量有何区别?) 1.4.1中虽然有ip ...
- zabbix-mysql迁移分离
io过高,迁移mysql 停掉zabbix 导出数据库的zabbix库 导入到新机器,并启动mysql 1:修改zabbix_server.conf文件里DB相关的地址,用户名和密码. vim /et ...
- light oj 1214 - Large Division 大数除法
1214 - Large Division Given two integers, a and b, you should check whether a is divisible by b or n ...
- 计算机网络 From Mr.Liu
引言 本博客摘自Mr.Liu,原帖请点击这里. 感谢Mr.Liu,这个文章很充分的描述了计算机网络的核心知识点. 我还在学习中,所以没有进行自己的转述.图片因为是copy代码而没有获得,想看更详尽的, ...