机器学习实战之k-近邻算法(3)---如何可视化数据
关于可视化:
《机器学习实战》书中的一个小错误,P22的datingTestSet.txt这个文件,根据网上的源代码,应该选择datingTestSet2.txt这个文件。主要的区别是最后的标签,作者原来使用字符串‘veryLike’作为标签,但是Python转换会出现ValueError: invalid literal for int() with base 10: 'largeDoses'的错误。所以改成后面的文件就可以了。后面直接用1 2 3 代表not like, general like, very like。这个错误一开始用百度查不到,改用Google(反向代理),第二个链接就是。哎。。。国内啊。。。
- from numpy import *
- import operator
- #创建数据集
- def createDataSet():
- group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
- labels = ['A', 'A', 'B', 'B']
- return group, labels
- #根据输入测试实例进行k-近邻分类
- def classify0(inX, dataSet, labels, k):
- dataSetSize = dataSet.shape[0]
- diffMat = tile(inX, (dataSetSize, 1)) - dataSet
- sqDiffMat = diffMat ** 2
- sqDistances = sqDiffMat.sum(axis=1)
- distances = sqDistances**0.5
- sortedDistIndicies = distances.argsort()
- classCount = {}
- for i in range(k):
- voteIlabel = labels[sortedDistIndicies[i]]
- classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
- sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1), reverse=True)
- return sortedClassCount[0][0]
- #处理输入格式问题,从文件中读取数据
- def file2matrix(filename, dim2):
- fr = open(filename)
- arrayOLines = fr.readlines()
- numberOfLines = len(arrayOLines)
- returnMat = zeros((numberOfLines, dim2))
- classLabelVector = []
- index = 0
- for line in arrayOLines:
- line = line.strip()
- listFromLine = line.split('\t')
- returnMat[index, :] = listFromLine[0:dim2]
- classLabelVector.append(int(listFromLine[-1]))
- index += 1
- return returnMat, classLabelVector
- >>>import kNN
- >>> reload(kNN)
- <module 'kNN' from 'kNN.pyc'>
- >>> datingDataMat, datingLabels = kNN.file2matrix('datingTestSet2.txt', 3)
得到了约会网站的数据之后,我们可以可视化出来。
利用Matplotlib创建散点图,python(x, y)内嵌这个,直接import即可。
- >>> mimport matplotlib.pyplot as plt
- >>> fig = plt.figure()
- >>> ax = fig.add_subplot(111) >>> ax.scatter(datingDataMat[:,1], datingDataMat[:,2])
- >>> plt.show()
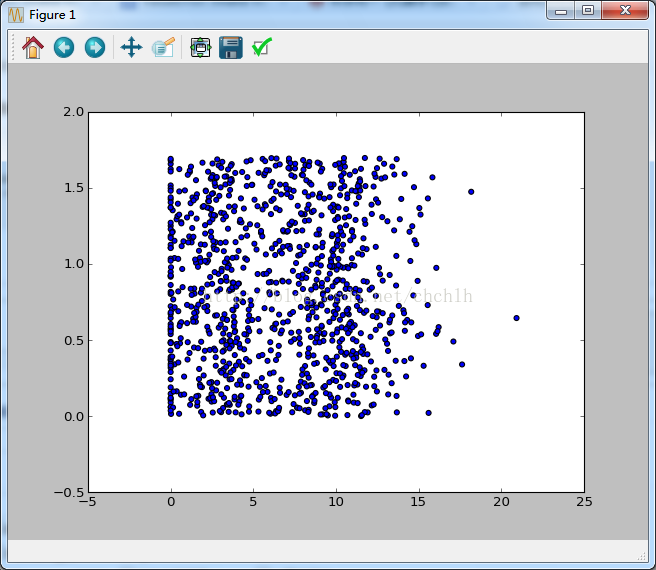
这个是“玩视频游戏消耗时间比”和“每周所消费的冰淇淋公升数”的二维图。
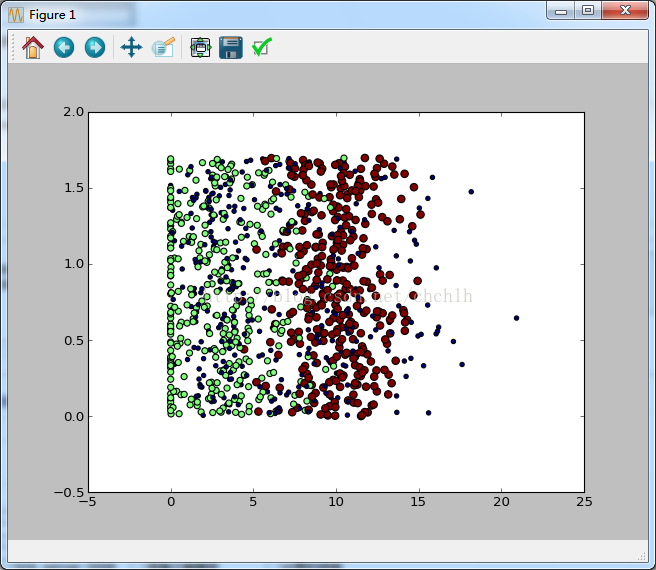
需要不同的颜色来得到更好的可视化效果。
scatter函数的使用。
- ax.scatter(datingDataMat[:,1], datingDataMat[:, 2], 15.0*array(datingLabels), 15.0*array(datingLabels))
这句代码替换前面的对应代码,如果出现name 'array' is not defined ,请在前面加这句:
- from numpy import *
下面是青色,暗红色,黑色三种点,是利用了15 * datingLabels的1, 2, 3作为不同点的颜色和尺寸。
机器学习实战之k-近邻算法(3)---如何可视化数据的更多相关文章
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 《机器学习实战》——K近邻算法
三要素:距离度量.k值选择.分类决策 原理: (1) 输入点A,输入已知分类的数据集data (2) 求A与数据集中每个点的距离,归一化,并排序,选择距离最近的前K个点 (3) K个点进行投票,票数最 ...
- 《机器学习实战》-k近邻算法
目录 K-近邻算法 k-近邻算法概述 解析和导入数据 使用 Python 导入数据 实施 kNN 分类算法 测试分类器 使用 k-近邻算法改进约会网站的配对效果 收集数据 准备数据:使用 Python ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 机器学习:1.K近邻算法
1.简单案例:预测男女,根据身高,体重,鞋码 import numpy as np import matplotlib import sklearn from skleran.neighbors im ...
- 机器学习实战笔记-2-kNN近邻算法
# k-近邻算法(kNN) 本质是(提取样本集中特征最相似数据(最近邻)的k个分类标签). K-近邻算法的优缺点 例 优点:精度高,对异常值不敏感,无数据输入假定: 缺点:计算复杂度高,空间复杂度高: ...
随机推荐
- AtCoder ABC 129F Takahashi's Basics in Education and Learning
题目链接:https://atcoder.jp/contests/abc129/tasks/abc129_f 题目大意 给定一个长度为 L ,首项为 A,公差为 B 的等差数列 S,将这 L 个数拼起 ...
- 第二周课堂笔记2th
---恢复内容开始--- 1. 2.索引取单个值 取多个值叫切片, 切片:取多个值 从左到右取值: 原则:顾头不顾尾 1, a[0:3] abc 2, a[-5:-2] abc 3, a[0:-2] ...
- 面试系列 30 如何自己设计一个类似dubbo的rpc框架
其实一般问到你这问题,你起码不能认怂,因为既然咱们这个课程是短期的面试突击训练课程,那我不可能给你深入讲解什么kafka源码剖析,dubbo源码剖析,何况我就算讲了,你要真的消化理解和吸收,起码个把月 ...
- java 测试时 程序的 运行时间
检测一个JAVA程序的运行时间方法:long startTime = System.currentTimeMillis();//获取当前时间//doSomeThing(); //要运行的java程 ...
- 2019-8-31-win2d-通过-CanvasActiveLayer-画出透明度和裁剪
title author date CreateTime categories win2d 通过 CanvasActiveLayer 画出透明度和裁剪 lindexi 2019-08-31 08:52 ...
- spring:常用的注解
bean.xml中配置依赖 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns=" ...
- Python全栈开发:选课系统实例
程序目录: bin文件夹下为可执行文件:administrator,students config文件夹下为设置文件,涉及系统参数配置:setting db文件夹为数据类文件,涉及系统的输入输出数据: ...
- leetcode-买卖股票最佳时机含冷冻期
题目描述: 方法一: class Solution: def maxProfit(self, prices: List[int]) -> int: n = len(prices) dp_i_0 ...
- 并发和多线程(四)--wait、notify、notifyAll、sleep、join、yield使用详解
wait.notify.notifyAll 这三个方法都是属于Object的,Java中的类默认继承Object,所以在任何方法中都可以直接调用wait(),notifyAll(),notify(), ...
- HZOI20190725 B 回家 tarjan
题目大意:https://www.cnblogs.com/Juve/articles/11226266.html 题解: 感觉挺水的,但考场上没打出来 题目翻译一下就是输出起点到终点必经的点 其实就是 ...