我说我了解集合类,面试官竟然问我为啥HashMap的负载因子不设置成1!?
在Java基础中,集合类是很关键的一块知识点,也是日常开发的时候经常会用到的。比如List、Map这些在代码中也是很常见的。
个人认为,关于HashMap的实现,JDK的工程师其实是做了很多优化的,要说所有的JDK源码中,哪个类埋的彩蛋最多,那我想HashMap至少可以排前五。
也正是因为如此,很多细节都容易被忽视,今天我们就来关注其中一个问题,那就是:
为什么HashMap的负载因子设置成0.75,而不是1也不是0.5?这背后到底有什么考虑?
大家千万不要小看这个问题,因为负载因子是HashMap中很重要的一个概念,也是高端面试的一个常考点。
另外,这个值得设置,有些人会用错的,比如前几天我的《阿里巴巴Java开发手册建议创建HashMap时设置初始化容量,但是多少合适呢?》这篇文章中,就有读者这样回复:
 

 

既然有人会尝试着去修改负载因子,那么到底改成1是不是合适呢?为什么HashMap不使用1作为负载因子的默认值呢?
什么是loadFactor
首先我们来介绍下什么是负载因子(loadFactor),如果读者对这部分已经有了解,那么可以直接跨过这一段。
我们知道,第一次创建HashMap的时候,就会指定其容量(如果未显示制定,默认是16,详见为啥HashMap的默认容量是16?),那随着我们不断的向HashMap中put元素的时候,就有可能会超过其容量,那么就需要有一个扩容机制。
所谓扩容,就是扩大HashMap的容量:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length); }
createEntry(hash, key, value, bucketIndex);
}
从代码中我们可以看到,在向HashMap中添加元素过程中,如果 元素个数(size)超过临界值(threshold) 的时候,就会进行自动扩容(resize),并且,在扩容之后,还需要对HashMap中原有元素进行rehash,即将原来通中的元素重新分配到新的桶中。
在HashMap中,临界值(threshold) = 负载因子(loadFactor) * 容量(capacity)。
loadFactor是装载因子,表示HashMap满的程度,默认值为0.75f,也就是说默认情况下,当HashMap中元素个数达到了容量的3/4的时候就会进行自动扩容。(相见HashMap中傻傻分不清楚的那些概念)
为什么要扩容
还记得前面我们说过,HashMap在扩容到过程中不仅要对其容量进行扩充,还需要进行rehash!所以,这个过程其实是很耗时的,并且Map中元素越多越耗时。
rehash的过程相当于对其中所有的元素重新做一遍hash,重新计算要分配到那个桶中。
那么,有没有人想过一个问题,既然这么麻烦,为啥要扩容?HashMap不是一个数组链表吗?不扩容的话,也是可以无限存储的呀。为啥要扩容?
这其实和哈希碰撞有关。
哈希碰撞
我们知道,HashMap其实是底层基于哈希函数实现的,但是哈希函数都有如下一个基本特性:根据同一哈希函数计算出的散列值如果不同,那么输入值肯定也不同。但是,根据同一散列函数计算出的散列值如果相同,输入值不一定相同。
两个不同的输入值,根据同一散列函数计算出的散列值相同的现象叫做碰撞。
衡量一个哈希函数的好坏的重要指标就是发生碰撞的概率以及发生碰撞的解决方案。
而为了解决哈希碰撞,有很多办法,其中比较常见的就是链地址法,这也是HashMap采用的方法。详见全网把Map中的hash()分析的最透彻的文章,别无二家。
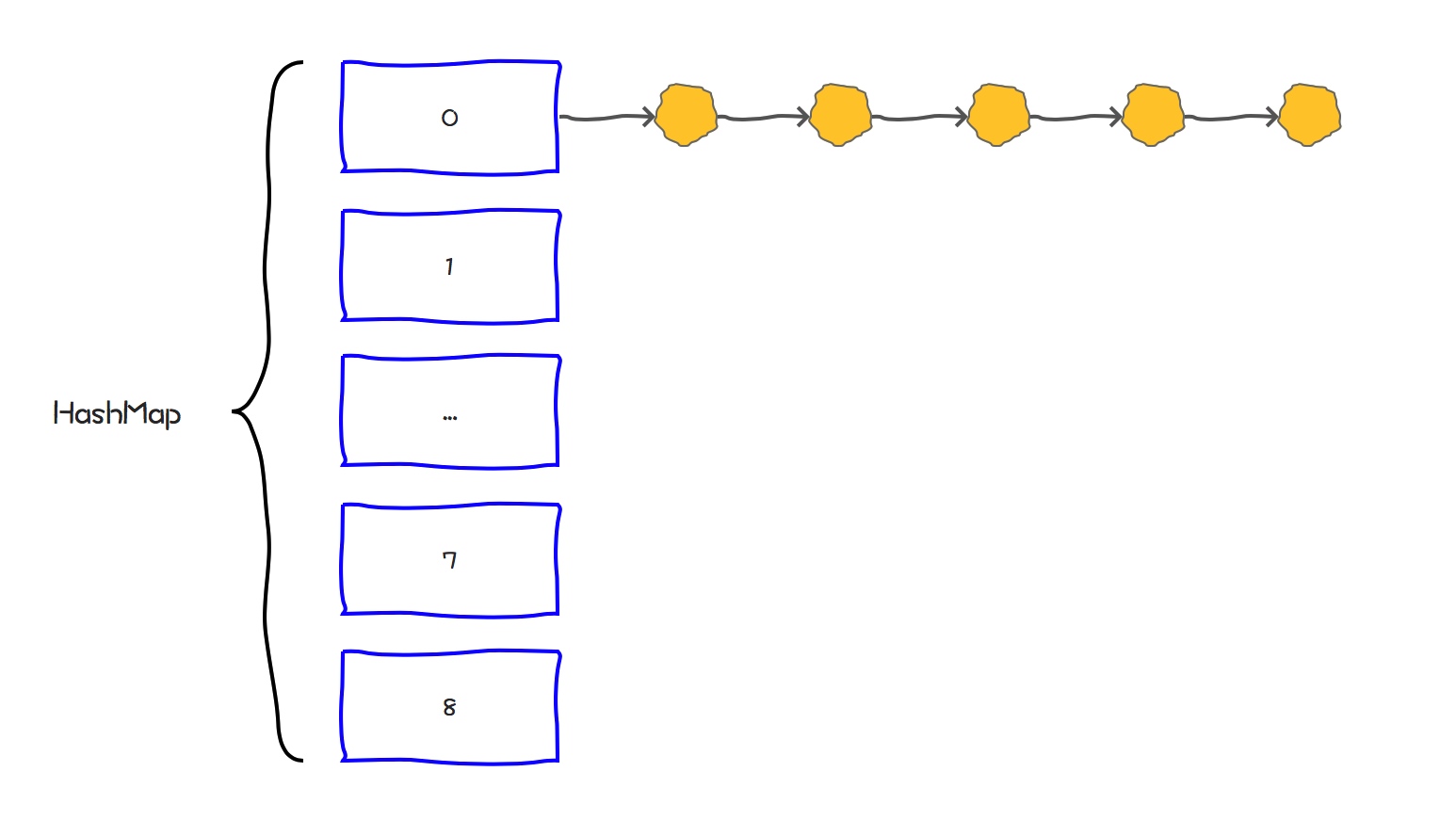
HashMap将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。
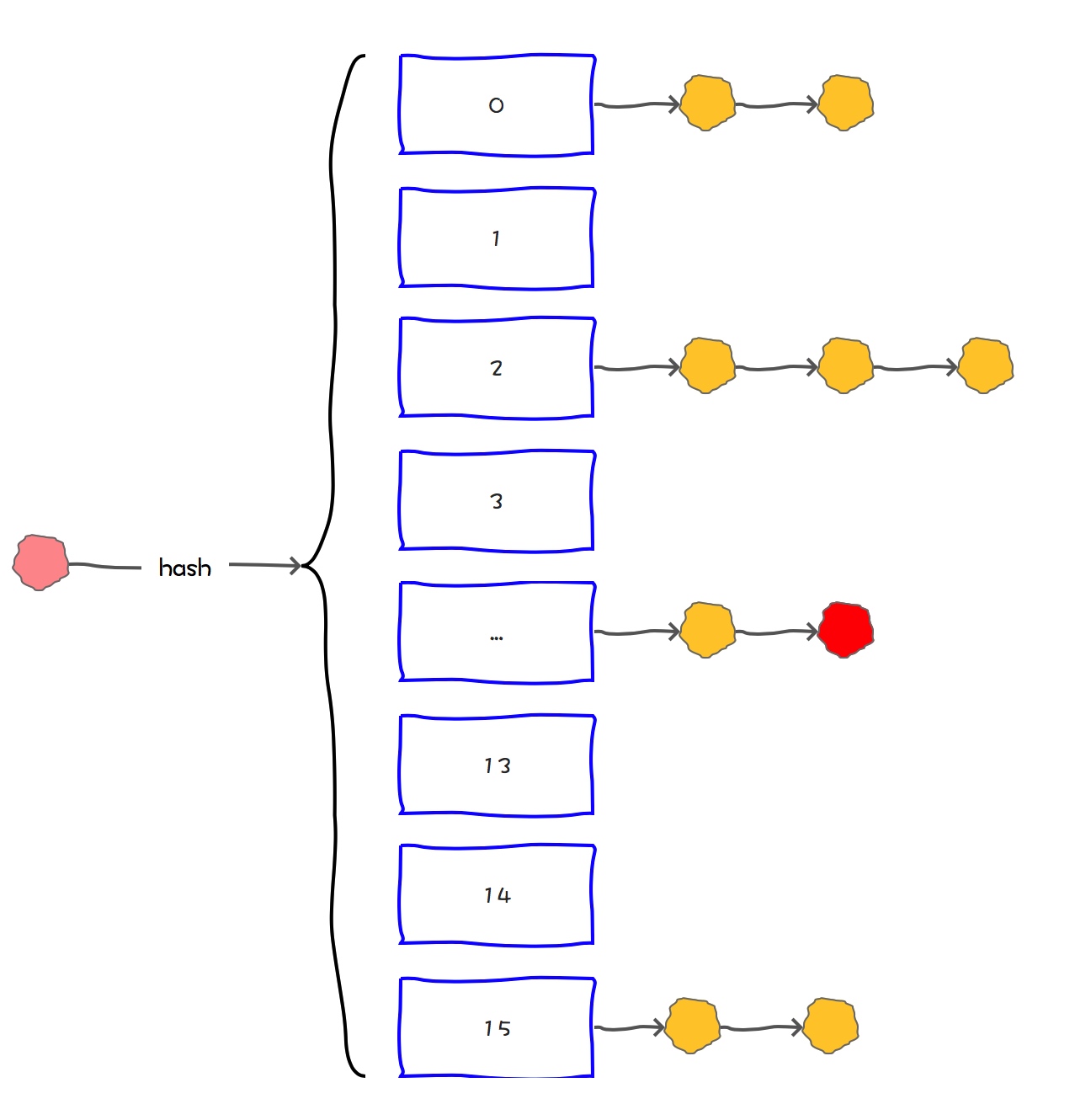 

HashMap基于链表的数组的数据结构实现的
我们在向HashMap中put元素的时候,就需要先定外到是数组中的哪条链表,然后把这个元素挂在这个链表的后面。
当我们从HashMap中get元素的时候,也是需要定位到是数组中的哪条链表,然后再逐一遍历链表中的元素,直到查找到需要的元素为止。
可见,HashMap通过链表的数组这种结构,解决了hash冲突的问题。
但是,如果一个HashMap中冲突太高,那么数组的链表就会退化为链表。这时候查询速度会大大降低。

所以,为了保证HashMap的读取的速度,我们需要想办法尽量保证HashMap的冲突不要太高。
扩容避免哈希碰撞
那么如何能有效的避免哈希碰撞呢?
我们先反向思维一下,你认为什么情况会导致HashMap的哈希碰撞比较多?
无外乎两种情况:
1、容量太小。容量小,碰撞的概率就高了。狼多肉少,就会发生争强。
2、hash算法不够好。算法不合理,就可能都分到同一个或几个桶中。分配不均,也会发生争强。
所以,解决HashMap中的哈希碰撞也是从这两方面入手。
这两点在HashMap中都有很好的提现。两种方法相结合,在合适的时候扩大数组容量,再通过一个合适的hash算法计算元素分配到哪个数组中,就可以大大的减少冲突的概率。就能避免查询效率低下的问题。
为什么默认loadFactor是0.75
至此,我们知道了loadFactor是HashMap中的一个重要概念,他表示这个HashMap最大的满的程度。
为了避免哈希碰撞,HashMap需要在合适的时候进行扩容。那就是当其中的元素个数达到临界值的时候,而这个临界值前面说过和loadFactor有关,换句话说,设置一个合理的loadFactor,可以有效的避免哈希冲突。
那么,到底loadFactor设置成多少算合适呢?
这个值现在在JDK的源码中是0.75:
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
那么,为什么选择0.75呢?背后有什么考虑?为什么不是1,不是0.8?不是0.5,而是0.75呢?
在JDK的官方文档中,有这样一段描述描述:
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put).
大概意思是:一般来说,默认的负载因子(0.75)在时间和空间成本之间提供了很好的权衡。更高的值减少了空间开销,但增加了查找成本(反映在HashMap类的大多数操作中,包括get和put)。
试想一下,如果我们把负载因子设置成1,容量使用默认初始值16,那么表示一个HashMap需要在"满了"之后才会进行扩容。
那么在HashMap中,最好的情况是这16个元素通过hash算法之后分别落到了16个不同的桶中,否则就必然发生哈希碰撞。而且随着元素越多,哈希碰撞的概率越大,查找速度也会越低。
0.75的数学依据
另外,我们可以通过一种数学思维来计算下这个值是多少合适。
我们假设一个bucket空和非空的概率为0.5,我们用s表示容量,n表示已添加元素个数。
用s表示添加的键的大小和n个键的数目。根据二项式定理,桶为空的概率为:
P(0) = C(n, 0) * (1/s)^0 * (1 - 1/s)^(n - 0)
因此,如果桶中元素个数小于以下数值,则桶可能是空的:
log(2)/log(s/(s - 1))
当s趋于无穷大时,如果增加的键的数量使P(0) = 0.5,那么n/s很快趋近于log(2):
log(2) ~ 0.693...
所以,合理值大概在0.7左右。
当然,这个数学计算方法,并不是在Java的官方文档中提现的,我们也无从考察到底有没有这层考虑,就像我们根本不知道鲁迅写文章时候怎么想的一样,只能推测。这个推测来源于Stack Overflor(https://stackoverflow.com/questions/10901752/what-is-the-significance-of-load-factor-in-hashmap)
0.75的必然因素
理论上我们认为负载因子不能太大,不然会导致大量的哈希冲突,也不能太小,那样会浪费空间。
通过一个数学推理,测算出这个数值在0.7左右是比较合理的。
那么,为什么最终选定了0.75呢?
还记得前面我们提到过一个公式吗,就是临界值(threshold) = 负载因子(loadFactor) * 容量(capacity)。
我们在《为啥HashMap的默认容量是16?》中介绍过,根据HashMap的扩容机制,他会保证capacity的值永远都是2的幂。
那么,为了保证负载因子(loadFactor) * 容量(capacity)的结果是一个整数,这个值是0.75(3/4)比较合理,因为这个数和任何2的幂乘积结果都是整数。
总结
HashMap是一种K-V结构,为了提升其查询及插入的速度,底层采用了链表的数组这种数据结构实现的。
但是因为在计算元素所在的位置的时候,需要使用hash算法,而HashMap采用的hash算法就是链地址法。这种方法有两个极端。
如果HashMap中哈希冲突概率高,那么HashMap就会退化成链表(不是真的退化,而是操作上像是直接操作链表),而我们知道,链表最大的缺点就是查询速度比较慢,他需要从表头开始逐一遍历。
所以,为了避免HashMap发生大量的哈希冲突,所以需要在适当的时候对其进行扩容。
而扩容的条件是元素个数达到临界值时。HashMap中临界值的计算方法:
临界值(threshold) = 负载因子(loadFactor) * 容量(capacity)
其中负载因子表示一个数组可以达到的最大的满的程度。这个值不宜太大,也不宜太小。
loadFactor太大,比如等于1,那么就会有很高的哈希冲突的概率,会大大降低查询速度。
loadFactor太小,比如等于0.5,那么频繁扩容没,就会大大浪费空间。
所以,这个值需要介于0.5和1之间。根据数学公式推算。这个值在log(2)的时候比较合理。
另外,为了提升扩容效率,HashMap的容量(capacity)有一个固定的要求,那就是一定是2的幂。
所以,如果loadFactor是3/4的话,那么和capacity的乘积结果就可以是一个整数。
所以,一般情况下,我们不建议修改loadFactor的值,除非特殊原因。
比如我明确的知道我的Map只存5个kv,并且永远不会改变,那么可以考虑指定loadFactor。
但是其实我也不建议这样用。我们完全可以通过指定capacity达到这样的目的。详见为啥HashMap的默认容量是16?
参考资料:
https://stackoverflow.com/questions/10901752/what-is-the-significance-of-load-factor-in-hashmap
https://docs.oracle.com/javase/6/docs/api/java/util/HashMap.html
https://preshing.com/20110504/hash-collision-probabilities/
我说我了解集合类,面试官竟然问我为啥HashMap的负载因子不设置成1!?的更多相关文章
- 【Nginx】面试官竟然问我Nginx如何生成缩略图,还好我看了这篇文章!!
写在前面 今天想写一篇使用Nginx如何生成缩略图的文章,想了半天题目也没想好,这个题目还是一名读者帮我起的.起因就是这位读者最近出去面试,面试官正好问了一个Nginx如何生成缩略图的问题.还别说,就 ...
- 我说精通字符串,面试官竟然问我 Java 中的 String 有没有长度限制?
String 是 Java 中很重要的一个数据类型,除了基本数据类型以外,String 是被使用的最广泛的了,但是,关于 String,其实还是有很多东西容易被忽略的. 就如本文我们要讨论的问题:Ja ...
- 我说我精通字符串,面试官竟然问我Java中的String有没有长度限制!?|附视频讲解
关于String有没有长度限制的问题,我之前单独写过一篇文章分析过,最近我又抽空回顾了一下这个问题,发现又有了一些新的认识.于是准备重新整理下这个内容. 这次在之前那篇文章的基础上除了增加了一些验证过 ...
- JVM工作原理和特点(一些二逼的逼神面试官会问的问题)
作为一种阅读的方式了解下jvm的工作原理 ps:(一些二逼的逼神面试官会问的问题) JVM工作原理和特点主要是指操作系统装入JVM是通过jdk中Java.exe来完毕,通过以下4步来完毕JVM环境. ...
- 面试官再问我如何保证 RocketMQ 不丢失消息,这回我笑了!
最近看了 @JavaGuide 发布的一篇『面试官问我如何保证Kafka不丢失消息?我哭了!』,这篇文章承接这个主题,来聊聊如何保证 RocketMQ 不丢失消息. 0x00. 消息的发送流程 一条消 ...
- 大厂面试官竟然这么爱问Kafka,一连八个Kafka问题把我问蒙了?
本文首发于公众号:五分钟学大数据 在面试的时候,发现很多面试官特别爱问Kafka相关的问题,这也不难理解,谁让Kafka是大数据领域中消息队列的唯一王者,单机十万级别的吞吐量,毫秒级别的延迟,这种天生 ...
- 我已经说了5种css居中实现的方式了,面试官竟然说还不够?
这是一篇关于居中对齐方式的总结 开篇之前,先问一下大家都知道几种居中的实现方式? 面试时答出来两三个就不错了,就怕面试官还让你继续说.今天就来总结一下这些居中的方式 使用flex布局设置居中. 使用f ...
- Android相关面试题---面试官常问问题
版权声明:本文为寻梦-finddreams原创文章,请关注: http://blog.csdn.net/finddreams/article/details/44513579 一般的面试流程是笔试完就 ...
- 程序员过关斩将--面试官再问你Http请求过程,怼回去!
菜菜哥,X总在产品部瞎指挥,作为程序媛的我都快撑不住了 不光你撑不住了,大家都要撑不住了,外行人指导内行人,呵呵 前天我偷偷的去面试了,结果挂了 出去转转其实是好事,面试官问你什么了? 他让我描述一个 ...
随机推荐
- 2次方的期望dp
某一天WJMZBMR在打osu~~~但是他太弱逼了,有些地方完全靠运气:( 我们来简化一下这个游戏的规则 有n次点击要做,成功了就是o,失败了就是x,分数是按comb计算的,连续a个com ...
- C#中的委托是什么
1.什么是委托?(方法作另一个方法的参数)delegate void MyDel(int value); //声明委托类型和类一样,委托是用户自定义的类型,但是类是数据和方法的集合,而委托是持有 ...
- VMware Workstation CentOS7 Linux 学习之路(5)--Docker安装与使用
一.安装与配置 1.安装依赖包 sudo yum install -y yum-utils device-mapper-persistent-data lvm2 2.设置阿里云镜像源 sudo yum ...
- ElasticSearch 倒排索引简析
内容概要 倒排索引是什么?为什么需要倒排索引? 倒排索引是怎么工作的? 1. 倒排索引是什么? 假设有一个交友网站,信息表如下: 美女1:"我要找在上海做 PHP 的哥哥." 需要 ...
- 「 从0到1学习微服务SpringCloud 」01 一起来学呀!
有想学微服务的小伙伴没?一起来从0开始学习微服务SpringCloud,我会把学习成果总结下来,供大家参考学习,有兴趣可以一起来学!如有错误,望指正! Spring .SpringBoot.Sprin ...
- 如何在GitHub上大显身手?
推荐一篇良许大佬的文章,如何在github上大显身手.拥有自己的github,且有所贡献,这是一件很有意义的的事情,在面试上也是加分项哦,赶紧搞起来. 转载至http://uee.me/aHAfN 这 ...
- 技术交流群和CSDN免费下载服务
1.最近很多新读者的关注,如果还没认识我或不清楚本公号能为你带来什么,可点击阅读你.我 2.本篇文章只为告诉新读者与不知道这些福利的旧读者 本公号其中为你提供的两大价值之处: 一个好的学习环境:技术交 ...
- intellij idea svn 切换分支
原文地址:https://blog.csdn.net/wangjun5159/article/details/75137964 切换分支 更新/切换svn的快捷键是ctrl+T,这个快捷键还是很好用的 ...
- 龙芯 3B1500 Fedora28 安装笔记
版权声明:原创文章,未经博主允许不得转载 龙芯 3A4000 已经发布,十年前的 3B1500 早就落伍了.但我还是打算把它作为寒假刷 ACM 题的主力机 并将此当作年后收到 4000 的预习. 龙芯 ...
- js----UTC时间于本地时间相差8小时问题
js----UTC时间于本地时间相差8小时问题 js获取周几有两个方法getDay() getUTCDay(),但是它们是有区别的,前者返回的本地时间,后者返回的UTC时间,一般情况下,两者相差8个小 ...