数据算法 --hadoop/spark数据处理技巧 --(5.移动平均 6. 数据挖掘之购物篮分析MBA)
五。移动平均
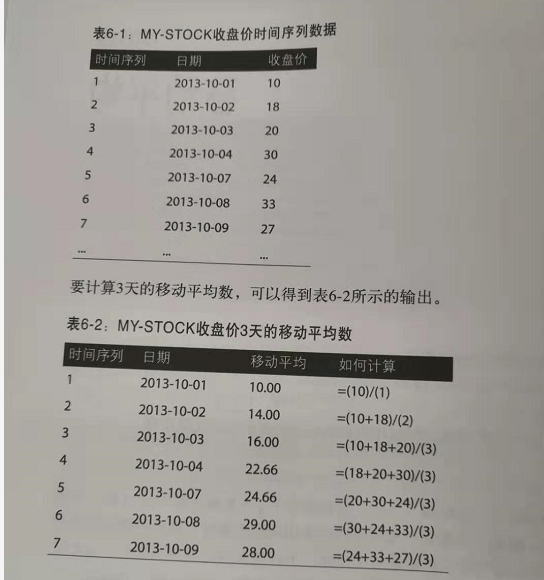
多个连续周期的时间序列数据平均值(按相同时间间隔得到的观察值,如每小时一次或每天一次)称为移动平均。之所以称之为移动,是因为随着新的时间序列数据的到来,要不断重新计算这个平均值,由于会删除最早的值同时增加最新的值,这个平均值会相应地“移动”。
例子:
java代码:


MR方案:
方案1:对于各个规约器键,在RAM种对时间序列数据排序,这个方法存在一个问题:如果没有足够的RAm来完成规约器的排序操作,这种方法就不可行。
方案2:让MRF完成时间序列数据的排序(MR框架的主要特性之一就是按键值排序和 分组,hadoop很擅长这个)。与方案1相比,这个方案可伸缩性要好得多,排序由MRF的sort和shuffle函数完成,如果采用这个方案,我们需要修改键值对,并编写一些定制插件类来完成二次排序。
方案1: map()函数将key进行拆分处理直接发送。 reduce()对key相同的数据进行排序,在进行window内的计算平均。
方案2:二次排序的必要设置: 分区器根据映射器输出键确定。哪个映射器输出发送到哪个规约器。一般的,不同的键会在不同的组中,不过有时我们希望不同的键在同一个组中,这种情况下要使用输出值分组比较器,用来对映射器输出分组。输出键比较器在排序阶段用来比较映射器输出键。

六。购物篮分析
MBA可以揭示不同商品或商品组之间的相似度。数据挖掘的一般目标是从庞大的数据集合中提取有趣的关联信息,例如数百万超市交易。MBA可以帮助我们找出很可能会在一起购买的商品,关联规则挖掘会发现一个交易集中商品之间的相关性。然后可以使用这些关联规则在商店货架上或在线将相关的商品摆放在相邻的位置。这属于计算密集型问题,很适合MRF。
1.对应N阶元祖的MR解决方案,这个放啊你可以查找频繁模式。
2.spark解决方案,不仅可以找出频繁模式,还会为他们生成关联规则。
在数据挖掘中,关联规则有两个度量标准。

1.MR解决方案。 生成频繁模式。
主要算法 :map -》 reduce

2.spark不仅生成频繁模式,同时生成规则。
流程:

流程中第一个MR: (也就是生成频繁模式) 第二个MR:


第二个MR不太好理解:
针对map的的输出(也就是生成所有频繁模式的子模式):
子模式的生成规则:


然后groupByKey():

然后再生成规则:

生成的规则代码为:


数据算法 --hadoop/spark数据处理技巧 --(5.移动平均 6. 数据挖掘之购物篮分析MBA)的更多相关文章
- 数据算法 --hadoop/spark数据处理技巧 --(13.朴素贝叶斯 14.情感分析)
十三.朴素贝叶斯 朴素贝叶斯是一个线性分类器.处理数值数据时,最好使用聚类技术(eg:K均值)和k-近邻方法,不过对于名字.符号.电子邮件和文本的分类,则最好使用概率方法,朴素贝叶斯就可以.在某些情况 ...
- 数据算法 --hadoop/spark数据处理技巧 --(1.二次排序问题 2. TopN问题)
一.二次排序问题. MR/hadoop两种方案: 1.让reducer读取和缓存给个定键的所有值(例如,缓存到一个数组数据结构中,)然后对这些值完成一个reducer中排序.这种方法不具有可伸缩性,因 ...
- 数据算法 --hadoop/spark数据处理技巧 --(9.基于内容的电影推荐 10. 使用马尔科夫模型的智能邮件营销)
九.基于内容的电影推荐 在基于内容的推荐系统中,我们得到的关于内容的信息越多,算法就会越复杂(设计的变量更多),不过推荐也会更准确,更合理. 本次基于评分,提供一个3阶段的MR解决方案来实现电影推荐. ...
- 数据算法 --hadoop/spark数据处理技巧 --(3.左外连接 4.反转排序)
三. 左外连接 考虑一家公司,比如亚马逊,它拥有超过2亿的用户,每天要完成数亿次交易.假设我们有两类数据,用户和交易: users(user_id,location_id) transactions( ...
- 数据算法 --hadoop/spark数据处理技巧 --(17.小文件问题 18.MapReuce的大容量缓存)
十七.小文件问题 十八.MR的大容量缓存 在MR中使用和读取大容量缓存,(也就是说,可能包括数十亿键值对,而无法放在一个商用服务器的内存中).本次提出的算法通用,可以在任何MR范式中使用.(eg:MR ...
- 数据算法 --hadoop/spark数据处理技巧 --(11.K-均值聚类 12. k-近邻)
十一.k-均值聚类 这个需要MR迭代多次. 开始时,会选择K个点作为簇中心,这些点成为簇质心.可以选择很多方法啦初始化质心,其中一种方法是从n个点的样本中随机选择K个点.一旦选择了K个初始的簇质心,下 ...
- 数据算法 --hadoop/spark数据处理技巧 --(15.查找、统计和列出大图中的所有三角形 16.k-mer计数)
十五.查找.统计和列出大图中的所有三角形 第一步骤的mr: 第二部mr: 找出三角形 第三部:去重 spark: 十六: k-mer计数 spark:
- 数据算法 --hadoop/spark数据处理技巧 --(7.共同好友 8. 使用MR实现推荐引擎)
七,共同好友. 在所有用户对中找出“共同好友”. eg: a b,c,d,g b a,c,d,e map()-> <a,b>,<b,c,d,g> ;< ...
- Apriori算法在购物篮分析中的运用
购物篮分析是一个很经典的数据挖掘案例,运用到了Apriori算法.下面从网上下载的一超市某月份的数据库,利用Apriori算法进行管理分析.例子使用Python+MongoDB 处理过程1 数据建模( ...
随机推荐
- python方法的重写
方法的重写: 在子类中重写定义一个父类拥有的方法, 调用时使用子类中重写定义的方法. 效果图: 代码: class Animal: def run(self): print('动物会跑~~~') de ...
- linux入门系列8--shell编程
本文将结合前面介绍的Linux命令.管道符等知识,通过VI编辑器编写Shell脚本,实现能自动化工作的脚本文件. 在讲解Linux常用命令"linux入门系列5--新手必会的linux命令& ...
- 前端笔记7-js3
1.方法: //创建一个对象var obj = {name:"孙悟空",age:18}; //对象的属性也可以是对象 obj.brother = {name:"猪八戒&q ...
- JMeter——jmx脚本文件解析
<!--Jmeter版本信息--> <?xml version="1.0" encoding="UTF-8"?> <jmeterT ...
- 关于爬虫的日常复习(18)——scrapy系列3
- C# 根据年月日计算周次
//day:要判断的日期,WeekStart:1 周一为一周的开始, 2 周日为一周的开始 public static int WeekOfMonth(DateTime day, int WeekSt ...
- CocoaPods中的头文件import导入时不能自动补齐的解决方法
1.选择target(就是左边你的工程target)-->BuildSettings-->search Paths下的User Header Search Paths 2.添加“$(POD ...
- Excel查找匹配函数的16种方法
作者:高顿初级会计链接:https://zhuanlan.zhihu.com/p/79795779来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处. 1.普通查找 查找李晓 ...
- Django自定义状态码
class BaseResponse: def __init__(self): self.code = 1000 self.data = None self.error = None @propert ...
- 5、python基本数据类型之数值类型
前言:python的基本数据类型可以分为三类:数值类型.序列类型.散列类型,本文主要介绍数值类型. 一.数值类型 数值类型有四种: 1)整数(int):整数 2)浮点数(float):小数 3)布尔值 ...