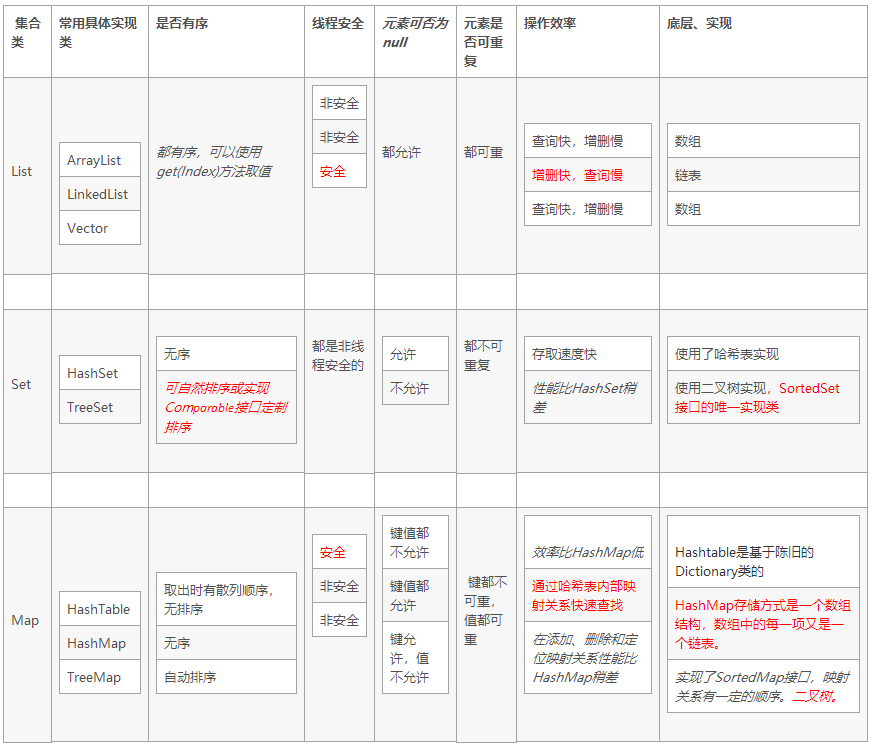
Day3 集合
数组与集合的区别
数组可以看作是一种集合,但是数组初始化后大小不可变;数组只能按索引顺序存取。
https://www.cnblogs.com/tiandi/p/10641773.html
Java标准库自带的java.util包提供了集合类:Collection,它是除Map外所有其他集合类的根接口。Java的java.util包主要提供了以下三种类型的集合
List,继承Collection,可重复、有序的对象
Set,继承Collection,不可重复、无序的对象
Map,键值对,提供key到value的映射。key无序、唯一;value无序,可重复

重写equals方法
如果你创建了一个自己编写的类List,那么你需要重写equals方法,不然无法正确的判断某个对象是否在List中(contains()、indexOf())。https://www.liaoxuefeng.com/wiki/1252599548343744/1265116446975264#0
Map
遍历
对Map来说,要遍历key可以使用for each循环遍历Map实例的keySet()方法返回的Set集合,它包含不重复的key的集合:
Map和List不同的是,Map存储的是key-value的映射关系,并且,它不保证顺序。在遍历的时候,遍历的顺序既不一定是put()时放入的key的顺序,也不一定是key的排序顺序。使用Map时,任何依赖顺序的逻辑都是不可靠的。以HashMap为例,假设我们放入"A","B","C"这3个key,遍历的时候,每个key会保证被遍历一次且仅遍历一次,但顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历的输出顺序都是不同的!
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (String key : map.keySet()) {
Integer value = map.get(key);
System.out.println(key + " = " + value);
}
}
}
hashMap 源码阅读
https://blog.csdn.net/crpxnmmafq/article/details/75331318
static final int MIN_TREEIFY_CAPACITY = 64;
-> 树形最小容量:哈希表的最小树形化容量,超过此值允许表中桶转化成红黑树
static final int TREEIFY_THRESHOLD = 8;
-> 树形阈值:当链表长度达到8时,将链表转化为红黑树
static final int UNTREEIFY_THRESHOLD = 6;
-> 树形阈值:当链表长度小于6时,将红黑树转化为链表
int threshold; -> 可存储key-value 键值对的临界值 需要扩充时;值 = 容量 * 加载因子
hashMap有一个十分有意思的函数 tableSizeFor();
https://www.liangzl.com/get-article-detail-28281.html
连接内的源码是java8的,现在的Java13的函数作用相同,但是实现方法已经是-1>>>n
-1补码为111111111(全为1),而>>>又是无符号操作。
2、“当两个对象的hashcode相同会发生什么?”
因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用LinkedList存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在LinkedList中。(当向 HashMap 中添加 key-value 对,由其 key 的 hashCode() 返回值决定该 key-value 对(就是 Entry 对象)的存储位置。当两个 Entry 对象的 key 的 hashCode() 返回值相同时,将由 key 通过 eqauls() 比较值决定是采用覆盖行为(返回 true),还是产生 Entry 链(返回 false)。),此时若你能讲解JDK1.8红黑树引入,面试官或许会刮目相看。
3、“如果两个键的hashcode相同,你如何获取值对象?”
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。如果有两个值对象储存在同一个bucket,将会遍历LinkedList直到找到值对象。找到bucket位置之后,会调用keys.equals()方法去找到LinkedList中正确的节点,最终找到要找的值对象。(当程序通过 key 取出对应 value 时,系统只要先计算出该 key 的 hashCode() 返回值,在根据该 hashCode 返回值找出该 key 在 table 数组中的索引,然后取出该索引处的 Entry,最后返回该 key 对应的 value 即可。)
hashCode()返回的int范围高达±21亿,先不考虑负数,HashMap内部使用的数组得有多大?
实际上HashMap初始化时默认的数组大小只有16,任何key,无论它的hashCode()有多大,都可以简单地通过:
int index = key.hashCode() & 0xf; // 0xf = 15
源码中的实现看https://blog.csdn.net/qq_42034205/article/details/90384772
为什么说hash之后的下标是均匀的(length-1)https://blog.csdn.net/yyyCHyzzzz/article/details/78516088
jdk1.7:
static int indexFor(int h, int length) {
return h & (length-1);
//由于length永远是2的幂次方,即补码为100……000,-1之后为111……111,这样&之后可以是奇数也可以是偶数
//在最小jdk中是get函数中的tab[i=(n-1)&hash]
}
jdk1.8
因为对自己改造过的哈希大量冲突时的红黑树有信心,所以简单一点,只是把高16异或下来(异或的操作是相同为0 不同为1)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h =key.hashCode()) ^ (h >>> 16);
}
为什么容量要是2的次方
https://blog.csdn.net/apeopl/article/details/88935422
treeMap
还有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意到SortedMap是接口,它的实现类是TreeMap。
使用TreeMap时,放入的Key必须实现Comparable接口。String、Integer这些类已经实现了Comparable接口,因此可以直接作为Key使用。作为Value的对象则没有任何要求。
优先队列
PriorityQueue和Queue的区别在于,它的出队顺序与元素的优先级有关,对PriorityQueue调用remove()或poll()方法,返回的总是优先级最高的元素。
Day3 集合的更多相关文章
- python_way,day3 集合、函数、三元运算、lambda、python的内置函数、字符转换、文件处理
python_way,day3 一.集合 二.函数 三.三元运算 四.lambda 五.python的内置函数 六.字符转换 七.文件处理 一.集合: 1.集合的特性: 特性:无序,不重复的序列 如果 ...
- 跟着ALEX 学python day3集合 文件操作 函数和函数式编程 内置函数
声明 : 文档内容学习于 http://www.cnblogs.com/xiaozhiqi/ 一. 集合 集合是一个无序的,不重复的数据组合,主要作用如下 1.去重 把一个列表变成集合 ,就自动去重 ...
- day3 集合set()实例分析
集合,我们在高中的时候专门学习过集合,并集,交集,差集等,下面来看一下集合的定义,如下: 集合(简称集)是数学中一个基本概念,它是集合论的研究对象,集合论的基本理论直到19世纪才被创立.最简单 ...
- python3.x Day3 集合
python中的集合 集合定义:一个无序的去重的数据集,主要特性就是去重和关系测试,关系测试不改变集合中的数据值 定义集合:set(list) 可以将list转化为集合set 示例: 定义一个集合:l ...
- day3 -- 集合、文件操作、函数
1.集合:集合无序,不重复,可以用set(列表) 方法将列表转换为集合,实现去重 对比列表:集合是{}包围,列表是[]包围 对比字典:集合是没有key的,字典是有key的 set_1 = {1, 2, ...
- Python之旅Day2 元组 字符串 字典 集合
元组(tuple) 元组其实跟列表差不多,也是存一组数,与列表相比,元组一旦创建,便不能再修改,所以又叫只读列表. 语法: names = ("Wuchunwei","Y ...
- python学习第三天 -----2019年4月23日
第三周-第03章节-Python3.5-集合及其运算 集合是一个无序的,不重复的数据组合,它的主要作用如下: 去重,把一个列表变成集合,就自动去重了 关系测试,测试两组数据之前的交集.差集.并集等关系 ...
- day3 字典,集合,文件
一.深浅copy 浅copy只copy第一层,不copy第二层.copy后,第一层指向不同内存地址.第二层指向相同的内存地址. 导入copy模块,deepcopy深copy.deepcopy后,均指向 ...
- day3 python 集合 文件
字典是无序的,列表是有序的 a='zhangsan' print (a[1]) a[2]=222 #字符串不能赋值 集合(set):把不同的元素组成一起形成集合 info=[1,2,34,5,6,7] ...
随机推荐
- ubuntu 开启对.htaccess的支持
1. 终端运行 sudo a2enmod 程序提示可供激活的模块名称,输入: rewrite 成功会提示 rewrite already load2. 修改/etc/apach ...
- nodejs使用promise实现sleep
个人博客 地址:http://www.wenhaofan.com/article/20181120180225 let sleep = function (delay) { return new Pr ...
- 二分-A - Cable master
A - Cable master Inhabitants of the Wonderland have decided to hold a regional programming contest. ...
- Pycharm操作数据库
Pymysql 用于连接mysql数据库 连接数据库 data_ip = "192.168.34.128" data_name = "lch" data_pwd ...
- JUC-多线程锁
多线程锁的练习题 1.标准访问,先打印短信还是邮件 class Phone { public synchronized void sendSMS() throws Exception { Thread ...
- VScode 编辑器快捷键被占用
在家办公这个开发环境实在是让人受不鸟 .mysql .vscode 对连QQ都没有运行还是不行.排查最终发现了这个家伙—搜狗输入法.微软输入法 这两个把系统快捷键占得那个全 我这个全局搜索死活用不了, ...
- Linux 虚拟机共享目录
1. 开启linux虚拟机 2. 菜单“虚拟机” -------“重新安装 Vm tools” 3. 桌面看到 VmTools 安装盘 4. 安装 5. 设置中添加共享目录 5. ...
- mediasoup-demo解析-服务端
1.启动server npm start启动服务,会执行脚本: "start": "DEBUG=${DEBUG:='*mediasoup* *INFO* *WARN* * ...
- C#中获取时间戳
{ 注意:下面是以毫秒为单位的13位 UTC 时间戳(非正规) }//先取得当前的UTC时间,然后转换成计算用的周期数(简称计时周期数),每个周期为100纳钞(ns)=0.1微秒(us)=0.00 ...
- java 判断数据是否为空
/** * 方法描述:自定义判断是否为空 * 创建作者:李兴武 * 创建日期:2017-06-22 19:50:01 * * @param str the str * @return the bool ...