[一本通学习笔记] AC自动机
AC自动机可以看作是在Trie树上建立了fail指针,在这里可以看作fail链。如果u的fail链指向v,那么v的对应串一定是u对应串在所给定字符串集合的后缀集合中的最长的后缀。
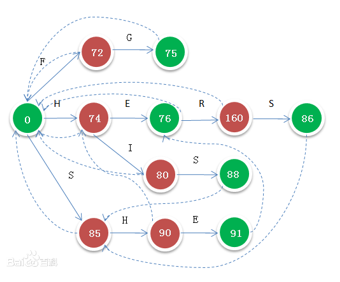
我们考虑一下如何实现这个东西。



以上数组实现的过程中我们让0号结点充当了根,这样会省去很多边界的处理。
我们考虑如何用指针去实现AC自动机,这看起来要更加自然。在指针实现的过程中,为了严谨起见,我们定义:节点的ch指针在默认情况下为NULL,fail指针在默认情况下为root(根节点自身除外)
这样的话就更加严格,各种边界情况都非常清晰。
#10057. 「一本通 2.4 例 1」Keywords Search

#include <bits/stdc++.h>
using namespace std; namespace ACA {
struct Node {
Node *ch[], *fail;
int val;
// Default value: fail=root ch=NULL
Node* clear(Node* defFail) {
fail = defFail;
for (int i = ; i < ; i++) ch[i] = ;
val = ;
return this;
}
};
Node *root = NULL, pool[];
int index;
Node* newnode() { return pool[index++].clear(root); }
void insert(string str) {
Node* p = root;
for (int i = ; i < str.length(); i++) {
int v = str[i] - 'a';
if (!p->ch[v])
p->ch[v] = newnode();
p = p->ch[v];
}
p->val++;
}
void build() {
queue<Node*> q;
for (int i = ; i < ; i++)
if (root->ch[i])
q.push(root->ch[i]);
while (!q.empty()) {
Node* p = q.front();
q.pop(); for (int i = ; i < ; i++) {
if (p->ch[i] != NULL)
p->ch[i]->fail = (p->fail->ch[i]) ? ((p->fail->ch[i])) : root, q.push(p->ch[i]);
else
p->ch[i] = p->fail->ch[i];
}
}
}
int query(string str) {
Node* p = root;
int ans = ;
for (int i = ; i < str.length(); i++) {
p = p->ch[str[i] - 'a'];
if (p == NULL)
p = root; // Attention!
for (Node* t = p; t != root && ~(t->val); t = t->fail) ans += t->val, t->val = -;
}
return ans;
}
void solve() {
int n;
cin >> n;
index = ;
root = newnode();
for (int i = ; i <= n; i++) {
string tmp;
cin >> tmp;
insert(tmp);
}
build();
string art;
cin >> art;
cout << query(art) << endl;
}
} // namespace ACA int main() {
int T;
// ios::sync_with_stdio(false);
cin >> T;
while (T--) ACA::solve();
}
#10058. 「一本通 2.4 练习 1」玄武密码

我们考虑query()中的那个while循环,它沿着当前节点到根的fail链跳,跳到不能再跳或者遇到已经处理过的节点为止。所谓处理节点,相当于标记这个节点对应的串已经被匹配。根据这个特性很容易构造出算法。
#include <bits/stdc++.h>
using namespace std; namespace ACA {
struct Node {
Node *ch[], *fail;
int val;
// Default value: fail=root ch=NULL
Node* clear(Node* defFail) {
fail = defFail;
for (int i = ; i < ; i++) ch[i] = ;
val = ;
return this;
}
};
Node *root = NULL, pool[];
int index;
Node* newnode() { return pool[index++].clear(root); }
void insert(string str) {
Node* p = root;
for (int i = ; i < str.length(); i++) {
int v = str[i];
if (!p->ch[v])
p->ch[v] = newnode();
p = p->ch[v];
p->val = max(p->val, i);
}
}
void build() {
queue<Node*> q;
for (int i = ; i < ; i++)
if (root->ch[i])
q.push(root->ch[i]);
while (!q.empty()) {
Node* p = q.front();
q.pop();
for (int i = ; i < ; i++) {
if (p->ch[i] != NULL)
p->ch[i]->fail = (p->fail->ch[i]) ? ((p->fail->ch[i])) : root, q.push(p->ch[i]);
else
p->ch[i] = p->fail->ch[i];
}
}
}
void query(string str) {
Node* p = root;
for (int i = ; i < str.length(); i++) {
p = p->ch[str[i]];
if (p == NULL)
p = root; // Attention!
for (Node* t = p; t != root && ~(t->val); t = t->fail) t->val = -;
}
}
int getans(string str) {
Node* p = root;
for (int i = ; i < str.length(); i++) {
p = p->ch[str[i]];
if (p->val >= )
return i;
}
return str.length();
}
string pat[];
void solve() {
int n;
cin >> n;
cin >> n;
index = ;
root = newnode();
string art;
cin >> art;
for (int j = ; j < art.length(); j++) {
if (art[j] == 'S')
art[j] = ;
if (art[j] == 'N')
art[j] = ;
if (art[j] == 'W')
art[j] = ;
if (art[j] == 'E')
art[j] = ;
}
for (int i = ; i <= n; i++) {
string tmp;
cin >> tmp;
for (int j = ; j < tmp.length(); j++) {
if (tmp[j] == 'S')
tmp[j] = ;
if (tmp[j] == 'N')
tmp[j] = ;
if (tmp[j] == 'W')
tmp[j] = ;
if (tmp[j] == 'E')
tmp[j] = ;
}
insert(tmp);
pat[i] = tmp;
}
build();
query(art);
for (int i = ; i <= n; i++) cout << getans(pat[i]) << endl;
}
} // namespace ACA int main() {
ios::sync_with_stdio(false);
int T;
ACA::solve();
}
#10059. 「一本通 2.4 练习 2」Censoring
之前KMP专题里面出现过一个censoring的题目,只不过在这里我们把单串换成了多串,但思想是一致的。
搞一个输出栈,每次删除时候弹栈,栈中同时记录一下匹配到的节点即可。
注意到这里由于子串不会互相包含,所以query中的while就可以去掉了。
写的时候忘记给staj[0]赋值T掉了,要注意边界
#include <bits/stdc++.h>
using namespace std; namespace ACA {
struct Node {
Node *ch[], *fail;
int val;
// Default value: fail=root ch=NULL
Node* clear(Node* defFail) {
fail = defFail;
for (int i = ; i < ; i++) ch[i] = ;
val = ;
return this;
}
};
Node *root = NULL, pool[];
int index;
int sta[], top = ;
Node* stap[];
Node* newnode() { return pool[index++].clear(root); }
void insert(string& str) {
Node* p = root;
for (int i = ; i < str.length(); i++) {
int v = str[i] - 'a';
if (!p->ch[v])
p->ch[v] = newnode();
p = p->ch[v];
}
p->val = str.length();
}
void build() {
queue<Node*> q;
for (int i = ; i < ; i++)
if (root->ch[i])
q.push(root->ch[i]);
while (!q.empty()) {
Node* p = q.front();
q.pop();
for (int i = ; i < ; i++) {
if (p->ch[i] != NULL)
p->ch[i]->fail = (p->fail->ch[i]) ? ((p->fail->ch[i])) : root, q.push(p->ch[i]);
else
p->ch[i] = p->fail->ch[i];
}
}
}
int query(string& str) {
Node* p = root;
int ans = ;
stap[] = root; // Warning!!!
for (int i = ; i < str.length(); i++) {
p = p->ch[str[i] - 'a'];
if (p == NULL)
p = root; // Attention!
++top;
sta[top] = i;
stap[top] = p;
if (p->val > ) {
top -= p->val;
p = stap[top];
}
}
for (int i = ; i <= top; i++) cout << str[sta[i]];
return ans;
}
void solve() {
string art;
cin >> art;
int n;
cin >> n;
index = ;
root = newnode();
for (int i = ; i <= n; i++) {
string tmp;
cin >> tmp;
insert(tmp);
}
build();
query(art);
}
} // namespace ACA int main() {
ios::sync_with_stdio(false);
ACA::solve();
}
#10060. 「一本通 2.4 练习 3」单词
某人读论文,一篇论文是由许多单词组成。但他发现一个单词会在论文中出现很多次,现在想知道每个单词分别在论文中出现多少次。
正常插入所有单词串,不过对每个位置都要打标记,这样相当于插入了所有的前缀。构建fail树完成后,对fail树求树上前缀和(自底向上),此后每个节点的值就是这个节点代表的串在整个字典中的出现次数。
#include <bits/stdc++.h>
using namespace std; namespace ACA {
struct Node {
Node *ch[], *fail;
int val, cnt;
vector<Node*> cf;
// Default value: fail=root ch=NULL
Node* clear(Node* defFail) {
fail = defFail;
for (int i = ; i < ; i++) ch[i] = ;
val = ;
cnt = ;
return this;
}
};
Node *root = NULL, pool[];
Node* epos[];
int index;
Node* newnode() { return pool[index++].clear(root); }
void insert(int id, string str) {
Node* p = root;
for (int i = ; i < str.length(); i++) {
int v = str[i] - 'a';
if (!p->ch[v])
p->ch[v] = newnode();
p = p->ch[v];
p->val++;
} epos[id] = p;
}
void build() {
queue<Node*> q;
vector<Node*> tq;
for (int i = ; i < ; i++)
if (root->ch[i])
q.push(root->ch[i]), tq.push_back(root->ch[i]);
while (!q.empty()) {
Node* p = q.front();
q.pop();
for (int i = ; i < ; i++) {
if (p->ch[i] != NULL)
p->ch[i]->fail = (p->fail->ch[i]) ? ((p->fail->ch[i])) : root, q.push(p->ch[i]),
tq.push_back(p->ch[i]);
else
p->ch[i] = p->fail->ch[i];
}
}
for (int i = tq.size() - ; i >= ; --i)
if (tq[i]->fail)
tq[i]->fail->val += tq[i]->val;
}
string s[];
void solve() {
int n;
cin >> n;
index = ;
root = newnode();
for (int i = ; i <= n; i++) {
string tmp;
cin >> tmp;
insert(i, tmp);
s[i] = tmp;
}
build();
for (int i = ; i <= n; i++) cout << epos[i]->val << endl;
}
} // namespace ACA int main() {
ios::sync_with_stdio(false);
ACA::solve();
}
#10061. 「一本通 2.4 练习 4」最短母串
输入N个串,找到它们的最短母串,输出可行解中字典序最小的。
第一次写这种题真的卡了很久。
我们最终应当是在AC自动机上跑记忆化BFS,状态的表示上需要借助状态压缩。
建树的时候,对于每一条fail边,假设从u指向v,即v是u的后缀,那么如果v是一个单词的结尾,那么u也应当是。这样看来我们需要对节点自身的状态做一下fail树上自顶向下的前缀和。
搜索的时候,维护BFS队列,顺便记录每个状态的来源信息方便输出。
#include <bits/stdc++.h>
using namespace std; const int N = ; int ch[N][], fi[N], val[N], n, m, t1, t2, t3, t4, ind; void ins(char *s, int id) {
int len = strlen(s), p = ;
for (int i = ; i < len; i++) {
if (ch[p][s[i] - 'A'] == )
ch[p][s[i] - 'A'] = ++ind;
p = ch[p][s[i] - 'A'];
}
val[p] |= << (id - );
} void build() {
queue<int> q;
for (int i = ; i < ; i++)
if (ch[][i])
q.push(ch[][i]);
while (!q.empty()) {
int p = q.front();
q.pop();
for (int i = ; i < ; i++)
if (ch[p][i])
fi[ch[p][i]] = ch[fi[p]][i], q.push(ch[p][i]);
else
ch[p][i] = ch[fi[p]][i];
int t = fi[p];
while (t && !val[t]) t = fi[t];
val[p] |= val[t];
}
} char str[N];
struct Status {
int pos = , state = , cnt = ;
Status(int a, int b, int c) : pos(a), state(b), cnt(c){};
};
int u[][ << ];
pair<int, int> fa[][ << ];
char o[][ << ];
string out;
int main() {
cin >> n;
for (int i = ; i <= n; i++) cin >> str, ins(str, i);
build();
queue<Status> q;
q.push((Status){ , val[], });
while (!q.empty()) {
Status p = q.front();
q.pop();
int node = p.pos, cnt = p.cnt, state = p.state;
if (state == ( << n) - ) {
while (node) {
out += o[node][state];
pair<int, int> tmp = fa[node][state];
node = tmp.first;
state = tmp.second;
}
reverse(out.begin(), out.end());
cout << out << endl;
return ;
}
for (int i = ; i < ; i++) {
int newstate = state | val[ch[node][i]];
int newnode = ch[node][i];
if (u[newnode][newstate])
continue;
u[newnode][newstate] = ;
o[newnode][newstate] = i + 'A';
fa[newnode][newstate] = make_pair(node, state);
q.push((Status){ newnode, newstate, });
}
}
}
#10062. 「一本通 2.4 练习 5」病毒
找到一个最小的不包含任何给定串的无限长串。
很显然这个串一定从某个位置开始循环。我们先对所有的终止节点打一个禁止标记,然后再fail树上跑自顶向下前缀和(因为终止节点再fail树上的所有孩子都应该被禁止),然后在所有没有被静止的节点间DFS,直到找到一条后向边。
#include <bits/stdc++.h>
using namespace std; const int N = ; int ch[N][], fail[N], val[N], u[N], n, m, t1, t2, t3, t4, ind;
vector<int> g[N]; void insert(char *s) {
int len = strlen(s), p = ;
for (int i = ; i < len; i++) {
if (ch[p][s[i] - ''] == )
ch[p][s[i] - ''] = ++ind;
p = ch[p][s[i] - ''];
}
val[p]++;
}
void build() {
queue<int> q;
for (int i = ; i < ; i++)
if (ch[][i])
q.push(ch[][i]);
while (!q.empty()) {
int p = q.front();
q.pop();
for (int i = ; i < ; i++) {
if (ch[p][i])
fail[ch[p][i]] = ch[fail[p]][i], q.push(ch[p][i]);
else
ch[p][i] = ch[fail[p]][i];
}
val[p] |= val[fail[p]];
}
for (int i = ; i <= ind; i++) {
// if(fail[i]) g[i].push_back(fail[i]);
g[i].push_back(ch[i][]);
g[i].push_back(ch[i][]);
}
}
bool dfs(int p) {
if (val[p])
return false;
// cout<<"dfs in "<<p<<endl;
u[p] = ;
for (int i = ; i < g[p].size(); i++) {
if (u[g[p][i]] == )
continue;
if (u[g[p][i]] == )
return true;
if (dfs(g[p][i]))
return true;
}
u[p] = ; // cout<<"dfs out "<<p<<endl;
return false;
}
char str[N];
int main() {
ios::sync_with_stdio(false);
cin >> n;
for (int i = ; i <= n; i++) cin >> str, insert(str);
build();
cout << (dfs() ? "TAK" : "NIE") << endl;
}
#10063. 「一本通 2.4 练习 6」文本生成器
老套路打禁止标记后做出自顶向下前缀和,然后暴力递推,设f[i][j]表示i步走到第j个节点,每次利用f[i][j]去刷所有f[i][j]的儿子,遇到禁止节点就将它的f[i][j]强行弄成0.最后求和即可。
#include <bits/stdc++.h>
using namespace std; const int N = ; int ch[N][], fail[N], val[N], u[N], n, m, t1, t2, t3, t4, ind;
vector<int> g[N];
int f[N][];
void insert(char *s) {
int len = strlen(s), p = ;
for (int i = ; i < len; i++) {
if (ch[p][s[i] - 'A'] == )
ch[p][s[i] - 'A'] = ++ind;
p = ch[p][s[i] - 'A'];
}
val[p]++;
}
void build() {
queue<int> q;
for (int i = ; i < ; i++)
if (ch[][i])
q.push(ch[][i]);
while (!q.empty()) {
int p = q.front();
q.pop();
for (int i = ; i < ; i++) {
if (ch[p][i])
fail[ch[p][i]] = ch[fail[p]][i], q.push(ch[p][i]);
else
ch[p][i] = ch[fail[p]][i];
}
val[p] |= val[fail[p]];
}
for (int i = ; i <= ind; i++) {
for (int j = ; j < ; j++) g[i].push_back(ch[i][j]);
}
} char str[N];
int main() {
ios::sync_with_stdio(false);
cin >> n >> m;
for (int i = ; i <= n; i++) cin >> str, insert(str);
build();
f[][] = ;
for (int j = ; j <= m; j++) {
for (int i = ; i <= ind; i++) {
if (val[i]) {
f[i][j] = ;
continue;
}
for (int k = ; k < g[i].size(); k++) {
(f[g[i][k]][j + ] += f[i][j]) %= ;
}
}
}
int ans = ;
for (int i = ; i <= ind; i++) (ans += f[i][m]) %= ;
int tot = ;
for (int i = ; i <= m; i++) (tot *= ) %= ;
cout << ((tot - ans) % + ) % << endl;
}
总结
AC自动机的这个专题是到目前为止做的最艰难的一个专题。原因在于一些基本的性质理解得不透彻,以及在指针实现的几道题目中因为对边界考虑得不够清楚导致各种诡异情况。
从实际角度来看,数组版本其实比较适合绝大多数题目。
应用方面,我们用AC自动机来解决的基本问题其实就是多串匹配,即给定一个单词本,看文章中出现了单词本中的多少个单词。这是很容易的。
如果我们要分别统计每个单词出现了多少次,就需要用到fail树上前缀和的处理技巧。我们知道,从某个节点沿着fail树走到根,经过的节点都是这个节点的后缀(这里我们已经用节点来直接指代节点对应的串),那么如果某个节点出现,它到根的fail链上所有的节点都应当已经出现,如果这些节点是某个单词的结尾,那么这个单词也应该被统计。因此,我们每次修改实际上修改的是fail树上某个点到根的一条链,我们很容易想到把这转化为在该点上打一个标记然后自底向上前缀和。
这个思路非常重要,练习3中我们要统计每个单词在单词本里以子串形式出现的次数时,我们用的就是这种思路。如果p点出现,那么显然fail[p],fail[fail[p]]都也出现。所以去做自底向上前缀和。
对于Censoring这样的问题,我们需要把输出构建成一个栈,并且维护栈中每个位置对应的当时所在自动机上节点的编号,这样如果弹出我们就可以很快的转移到弹出后的状态。
AC自动机上进行搜索和dp的难度就会稍高一些。总得来说,这类问题需要去记录状态,这个状态通常包含对节点的描述和对某些其它信息的描述。通常还需要结合树上前缀和。
#include <bits/stdc++.h>
using namespace std;
const int N = 1000005;
int ch[N][26], fi[N], val[N], n, m, t1, t2, t3, t4, ind;
void ins(char *s, int id) {
int len = strlen(s), p = 0;
for (int i = 0; i < len; i++) {
if (ch[p][s[i] - 'A'] == 0)
ch[p][s[i] - 'A'] = ++ind;
p = ch[p][s[i] - 'A'];
}
val[p] |= 1 << (id - 1);
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (ch[0][i])
q.push(ch[0][i]);
while (!q.empty()) {
int p = q.front();
q.pop();
for (int i = 0; i < 26; i++)
if (ch[p][i])
fi[ch[p][i]] = ch[fi[p]][i], q.push(ch[p][i]);
else
ch[p][i] = ch[fi[p]][i];
int t = fi[p];
while (t && !val[t]) t = fi[t];
val[p] |= val[t];
}
}
char str[N];
struct Status {
int pos = 0, state = 0, cnt = 0;
Status(int a, int b, int c) : pos(a), state(b), cnt(c){};
};
int u[1005][1 << 12];
pair<int, int> fa[1005][1 << 12];
char o[1005][1 << 12];
string out;
int main() {
cin >> n;
for (int i = 1; i <= n; i++) cin >> str, ins(str, i);
build();
queue<Status> q;
q.push((Status){ 0, val[0], 0 });
while (!q.empty()) {
Status p = q.front();
q.pop();
int node = p.pos, cnt = p.cnt, state = p.state;
if (state == (1 << n) - 1) {
while (node) {
out += o[node][state];
pair<int, int> tmp = fa[node][state];
node = tmp.first;
state = tmp.second;
}
reverse(out.begin(), out.end());
cout << out << endl;
return 0;
}
for (int i = 0; i < 26; i++) {
int newstate = state | val[ch[node][i]];
int newnode = ch[node][i];
if (u[newnode][newstate])
continue;
u[newnode][newstate] = 1;
o[newnode][newstate] = i + 'A';
fa[newnode][newstate] = make_pair(node, state);
q.push((Status){ newnode, newstate, 0 });
}
}
}[一本通学习笔记] AC自动机的更多相关文章
- 学习笔记::AC自动机
最先开始以为和自动刷题机是一个东西... 其实就是kmp的一个拓展.学完kmp再学这个就会发现其实不难 1.kmp是一个串匹配一个串,但是当我们想用多个串匹配一个文本的时候,kmp就不行了,因此我们有 ...
- SAM学习笔记&AC自动机复习
形势所迫,一个对字符串深恶痛绝的鸽子又来更新了. SAM 后缀自动机就是一个对于字符串所有后缀所建立起的自动机.一些优良的性质可以使其完成很多字符串的问题. 其核心主要在于每个节点的状态和$endpo ...
- [学习笔记]后缀自动机SAM
好抽象啊,早上看了两个多小时才看懂,\(\%\%\%Fading\) 早就懂了 讲解就算了吧--可以去看看其他人的博客 1.[模板]后缀自动机 \(siz\) 为该串出现的次数,\(l\) 为子串长度 ...
- [一本通学习笔记] 最近公共祖先LCA
本节内容过于暴力没什么好说的.借着这个专题改掉写倍增的陋习,虽然写链剖代码长了点不过常数小还是很香. 10130. 「一本通 4.4 例 1」点的距离 #include <bits/stdc++ ...
- [一本通学习笔记] RMQ专题
傻傻地敲了好多遍ST表. 10119. 「一本通 4.2 例 1」数列区间最大值 #include <bits/stdc++.h> using namespace std; const i ...
- [一本通学习笔记] 字典树与 0-1 Trie
字典树中根到每个结点对应原串集合的一个前缀,这个前缀由路径上所有转移边对应的字母构成.我们可以对每个结点维护一些需要的信息,这样即可以去做很多事情. #10049. 「一本通 2.3 例 1」Phon ...
- [一本通学习笔记] KMP算法
KMP算法 对于串s[1..n],我们定义fail[i]表示以串s[1..i]的最长公共真前后缀. 我们首先考虑对于模式串p,如何计算出它的fail数组.定义fail[0]=-1. 根据“真前后缀”的 ...
- AC自动机--summer-work之我连模板题都做不出
这章对现在的我来说有点难,要是不写点东西,三天后怕是就一无所有了. 但写这个没有营养的blog的目的真的不是做题或提升,只是学习学习代码和理解一些概念. 现在对AC自动机的理解还十分浅薄,这里先贴上目 ...
- Keywords Search - HDU 2222(AC自动机模板)
题目大意:输入几个子串,然后输入一个母串,问在母串里面包含几个子串. 分析:刚学习的AC自动机,据说这是个最基础的模板题,所以也是用了最基本的写法来完成的,当然也借鉴了别人的代码思想,确实是个很神 ...
随机推荐
- ASP.NET Learning Center---学习ASP.NET(1)
1,学习地址---微软官网 2,目标:学习Razor,以及建立Web应用. 3,https://docs.microsoft.com/zh-cn/aspnet/core/tutorials/razor ...
- 有关css编写文字动态下划线
<div class="main_text">哈哈这就是我的小视频</div> 上面为html代码 接下来进行css的编写 .main_text{ posi ...
- 【MVC+EasyUI实例】对数据网格的增删改查(上)
前言 此案例是针对之前做的一个小例子的后台框架的修改,从以前的三层框架改为现在的MVC框架,也是做了一次MVC和EasyUI的结合,分为2篇文章来阐述. 界面如下: 点击"添加"按 ...
- 纪中21日c组T1 1575. 二叉树
1575. 二叉树 (File IO): input:tree.in output:tree.out 时间限制: 1000 ms 空间限制: 262144 KB 具体限制 Goto Probl ...
- 剑指offer-面试题44-数字序列中某一位的数字-脑筋急转弯
/* 题目: 数字以0123456789101112131415…的格式序列化到一个字符序列中. 在这个序列中,第5位(从0开始计数,即从第0位开始)是5,第13位是1,第19位是4,等等. 请写一个 ...
- P1308 统计单词数(cin,getline() ,transform() )
题目描述 一般的文本编辑器都有查找单词的功能,该功能可以快速定位特定单词在文章中的位置,有的还能统计出特定单词在文章中出现的次数. 现在,请你编程实现这一功能,具体要求是:给定一个单词,请你输出它在给 ...
- Redis的各个数据的类型基本命令
什么是Redis: 概念: Redis (REmote DIctionary Server) 是用 C 语言开发的一个开源的高性能键值对(key-value)数据库. 特征:1. 数据间没有必然的关联 ...
- C# WPF 时钟动画(1/2)
微信公众号:Dotnet9,网站:Dotnet9,问题或建议:请网站留言, 如果对您有所帮助:欢迎赞赏. C# WPF 时钟动画(1/2) 内容目录 实现效果 业务场景 编码实现 本文参考 源码下载 ...
- WebApp开发-Zepto
zepto.js自己去官网下载哈. DOM操作 $(document).ready(function(){ var $cr = $("<div class='cr'>插入的div ...
- 在Docker中部署Confluence和jira-software
-------谢谢您的参考,如有疑问,欢迎交流 version: centos==7.2 jdk==1.8 confluence==6.15.4 jira-software==8.2.1 docker ...