#ICCV2019论文阅读#Fully_convolutional_Features
一 知识背景
3D scan&cloud points(点云)patch-based features,fully convolutional network, deep metric learning, sparse tensors,sparse convolutions, hard negetive-mining, contrastive loss, triplet loss, batch normalization...
1.cloud points(点云)
“在逆向工程中通过测量仪器得到的产品外观表面的点数据集合也称之为点云,通常使用三维坐标测量机所得到的点数量比较少,点与点的间距也比较大,叫稀疏点云;而使用三维激光扫描仪或照相式扫描仪得到的点云,点数量比较大并且比较密集,叫密集点云,

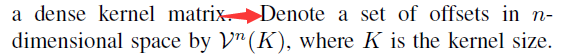

在稀疏的卷积中和权值${W}$相乘的${x}$必须在${C}$中,这样的系数卷积得到的也是一个稀疏的结果。文中的${V^(3){-1,0,1}}$我觉得其中的元素不必是固定的${{-1,0,1}}$,如果非要是这样,卷积(相关)就无法计算了(这也是我在阅读时遇到的困惑)。当然最主要的还是要在code中去实现这个系数卷积。[接下来的时间我会探索一下]。
文章正文:
从3D扫描或者是点云上提取几何特征是许多工作的第一步。例如注册(registration),重建(reconstruction)和跟踪(tracking)。现今的(state of art)方法需要将低阶(low-level)的特征作为输入来计算。
“低层次特征提取算法基于兴趣点所在表面及临近点的空间分布,提取基本的二维、三维几何属性作为兴趣点特征信息,如线性、平面性等。低层次特征提取算法复杂度低、运算效率高、内存消耗少,但领域尺寸的选择对识别效果影响较大。”
“高层次特征提取算法基于低层次几何特征及临近点空间分布,定义并计算更复杂的几何属性作为特征信息。根据几何属性的定义又可细分为基于显著性、基于直方图、基于显著性直方图与基于其他特征的四大类提取算法[1][2]。”
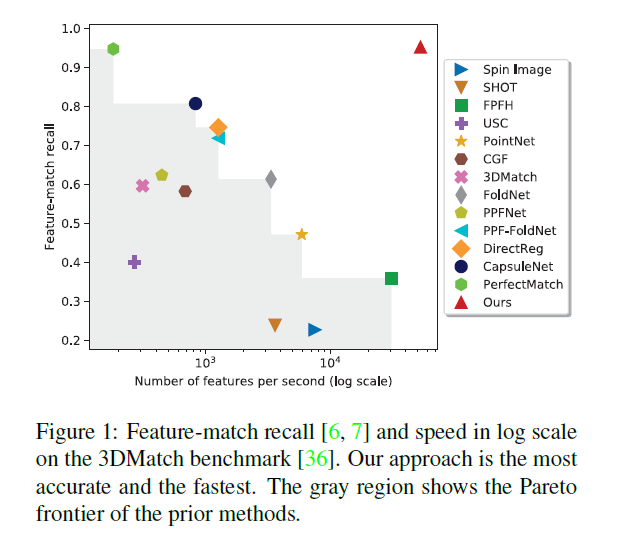
这里说明下指标:recall 中文叫查全率又叫召回率,其计算公式如下:
$recal{l_c} = \frac{{T{P_c}}}{{T{P_c} + F{N_c}}}$
意思是某一类判断正确占到该类总数的百分比。理所当然的想要提升recall可以遵循“宁可错杀一百,不可放过一人”的思想。嘿嘿~
接着我们给出作者用的网络框架:
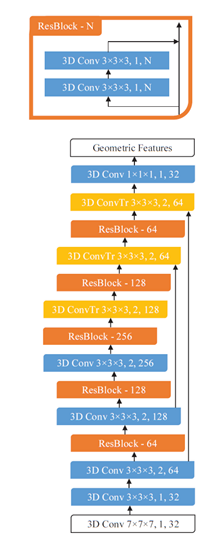
这是一个ResUNet的架构,两个白框是输入输出层,每个块用三个参数来描述:kernel size, stride, channel dimensionality.(核大小,步幅,和通道维度)除了最后一层其他的卷积层后面都有Batch normalization然后跟一个非线性(Relu).
那说了半天啥是全卷积特征啊?

全卷积特征作者说了:

我给你翻译翻译:
全卷积网络纯粹的由具有平移不变性的操作组成,像卷积和元素级别的非线性。(我不懂啥是元素级别的非线性啊?)同样,我们吧稀疏卷积网络(注这里是因为他用的稀疏卷积所以将这个网络将spase convolution network)给一个稀疏的tensor用上,我们得到的也是个稀疏的tensor,我们把这个稀疏的tensor输出叫做全卷积特征。
OK。
重头戏来了,嘿嘿~
作者自己说自己搞了个新的Metric learning的新的损失函数。在看他的新家伙式儿之前,我们不妨回顾下他站在谁的肩膀上搞了个大新闻。。
在前面的背景知识里有提到,就是negative mining 和标准的metric learning 的损失函数。这个作者说自己用全卷积网络了搞了个metric learning,而且还把negative mining整合到对比损失函数和三元组损失函数里了,他自己把整合后的这个新的损失函数叫做“Hardest contrastive"和”hardest-triplet"
网络:“我太难了(哭腔)"。
好言归正传,想要搞metric learning必须遵循两个约束,一个是类似的特征必须和彼此之间挨的足够近,对于分类来说,肯定是越近越好,那么有
$D({{f}_{i}},{{f}_{j}})\to 0\forall (i,j)\in P$
啥意思?${P}$是正确配对feature-match成功的特征,${(i,j)}$是其中的一个组合。相反的不相似的特征必然挨的越远越好,那我们就给他一个警戒线称之为margin(注:margin在英语里由差距,差额之意)用数学来说就是
$D({{f}_{i}},{{f}_{j}})>m\forall (i,j)\in N$
这里的${D}$是一种距离的衡量手段,原文没说啥距离,我觉得应该可以用欧氏距离。
文章说Lin等人说这些对于正例的约束会导致网络过拟合,然后搞出个针对正例的基于margin的损失函数。式子里右下角的+号代表着大于0时就取这个值,否则就取0。说实话,我因为一直吧这里边的${I_{ij}}$当是个示性函数,以为根据后边中括号里边的东西来取值,一直没搞懂,后来偶来见发现tm这两货是分开的。我真想吐槽这作者。。
作者的对正例加了个margin的约束后,可以解决网络过拟合的现像。
接着又弄个三元组(triplet loss)损失,我一并给出原文,瞅瞅:

在许多的文献了这篇文章后边也用了,这(4)里边的这个${f}$叫做anchor(中文名叫锚)而${f_+}$代表正例里边的元素。带负号的就不难说了。
在negative mining里边就说了,网络的性能会被小部分”人"左右,是谁呢?就是那些对于网络来说非常难啃的硬骨头——“hardest negatives"
接着作者讨论一个容易被人忽视,但却至关重要的存在:全卷积特征的特性
传统的Metric learning 认为特征是独立同分布的(iid),为啥?作者说了:

因为batch是随机采样来的。
这里需要和大家回顾下啥是epoch,batch,iteration???
- epoch:代表在整个数据集上的一次迭代(所有一切都包含在训练模型中);
- batch:是指当我们无法一次性将整个数据集输入神经网络时,将数据集分割成的一些更小的数据集批次;
- iteration:是指运行一个 epoch 所需的 batch 数。举个例子,如果我们的数据集包含 10000 张图像,批大小(batch_size)是 200,则一个 epoch 就包含 50 次迭代(10000 除以 200)。
虽说基础,但也要温故而知新嘛~
然而,然而...
在全卷积特征的提取过程中,相邻特征的位置是相关的。(我也不懂...)
#ICCV2019论文阅读#Fully_convolutional_Features的更多相关文章
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- 论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline
论文阅读:Prominent Object Detection and Recognition: A Saliency-based Pipeline 如上图所示,本文旨在解决一个问题:给定一张图像, ...
随机推荐
- ORA-01089: 即時シャットダウン処理中 - 操作はできません
一:当时的情景 SQL> shutdown immediate --无任何返回结果 二:问题定位过程 1.查询相关进程只有ORACLE的关键进程存在 ps -ef |grep ora_ soad ...
- Open Source Projects Released By Google
Open Source Projects Released By Google Google has released over 20 million lines of code and over 9 ...
- codeforces 616D
题意:给你n个数,找出一个最大的区间,满足:不同的数值个数不超过k; //我开始又看错题了. 以为是找出一个最大区间,里面的数的最大值不超过k; 思路:利用一个窗口滑动,左端点表示当前位置,右端点表示 ...
- c++ 基本使用
1 枚举 enum ShapeType { circle, square, rectangle }; int main() { ShapeType shape = circle; switch(sha ...
- js(三) ajax异步局部刷新技术底层代码实现
ajax 异步 javaScript and xml 开发五步骤: 1. 创建对象 XMLHttpRequest(chrome,firefox) ie... jquery 2. 找到连接, http的 ...
- jmeter登录配置
前言: jmeter, Apache下的测试工具, 常用来进行压测, 项目中, 接口通常都需要进行登录才能被调用, 直接调用将提示"登录失效", 下面介绍如何在jmeter中配置参 ...
- H5 canvas 绘图
H5的canvas绘图技术 canvas元素是HTML5中新添加的一个元素,该元素是HTML5中的一个亮点.Canvas元素就像一块画布,通过该元素自带的API结合JavaScript代码可以绘制 ...
- H3C RIPv2配置任务
- H3C 多路径网络中环路产生过程(3)
- vue-上传文件
<label for="exampleInputFile">头像</label> <img :src=" imgsrc != '' ? im ...