kafka一些问题点的分析
kakfka架构图:
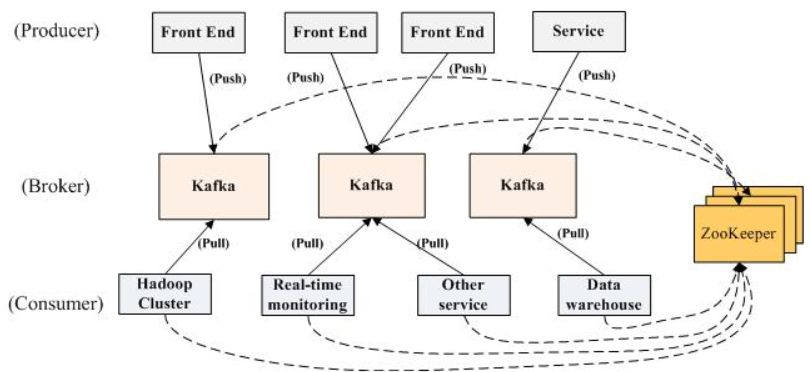
理解kafka需要理解三个问题。
1.producer,broker,consumer,ZK的工作模式。
broker,ZK是作为一个后台服务,而producer和consumer是作为一个SDK提供给开发者进行开发用。
2.producer和consumer的交互类型。
一般的队列模式是采用push模式,传统设计认为push更具备实时性。但是kafka使用的是consumer通过pull去和producer进行交互,这样设计的好处有两个。(1)使用pull可以让系统设计更为简单,producer不用去感知地下consumer的状态,代码设计上会简单许多。(2)通过pullconsumer可以进行消息峰值的控制,避免数据量太大时候压垮cunsumer。宁愿消息暂时性延迟也不愿意consumer宕机。
3.producer是如何知道broker的存在,producer是如何知道发送消息给哪个broker,同样consumer是怎么感知broker的存在,如何知道从那个consumer取数据
从架构图的两个虚线到ZK,是因为kafka从0.8版本开始,kafka开始不用从ZK获取broker的元信息。之前的版本是需要的。0.8版本后,producer可以只指定一个或者多个broker的URL,来获取kafka集群的元信息。(比如集群有300个broker,但是producer只需要指定三个就可以获取到整个broker的集群的活动的列表,每个broker,topic有多少partition,每个partition在哪个broker上,该信息会存储到broker的内存之中进行维护)。而consumer是通过连接ZK,发现kafka集群的元信息(broker的集群的活动的列表,每个broker,topic有多少partition,每个partition在哪个broker上)。
Topic 概念

1.topic可以拥有不同的partition数量,在broker上均匀分配。进行负载均衡
partition的概念
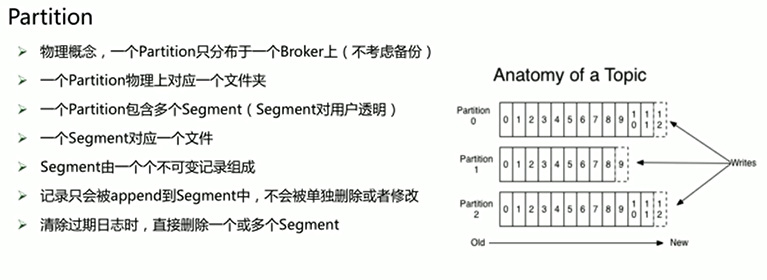
partition之间的序号可以重复,但是partition自己中的segment序号是不可重复的。(定位一条消息需要知道partition的位置,和offset位置才能找)
kafka清理机制有两个(1.基于时间,超过时间删除。2.基于size大小),满足条件会删除整个segment,比如我segment设置100M,超过1G删除,那么10文件就是1000MB,那么当超过1024时候,kafka就会把最后的segment删除,就是剩下924MB,这时候不满足1GB,就停止删除,继续运转。而且删除不是实时性清楚,会有个后台线程进行实时扫描。满足则运行·

参数解析:topic1有三个partition。
kafka存储数据地方:在配置文件里面找到log.dirs(dirs表示可以挂多个磁盘可能对应的多个目录,以便多个磁盘可以加速写入) 路径。
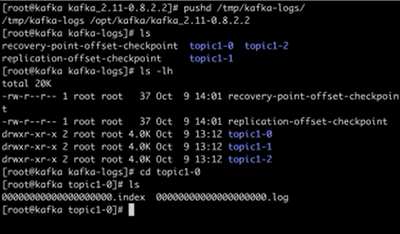
log是消息存储的文件,而index是存储消息的索引。offset对应条目位置。文件名字是以offset最小的条目编号作为文件名字。
partition的分配方式。
策略1:hashPartitioner(相同key会被分配到同一个partition中)
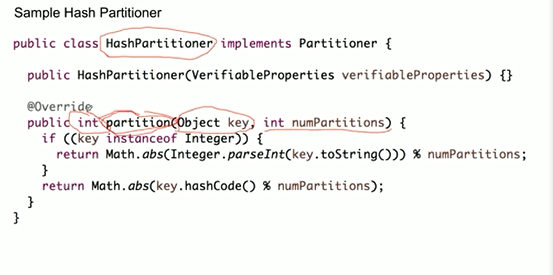
策略2:roundRobinPartition(保证消息的均匀分布)

策略3:随机分配(默认)
producer的两种方式(同步producer和异步producer)

同步是发送一条跟踪一条,异步是直接把数据发送到一个queue中,后台有一个进程不断去处理这个queue,因为不是马上发送到broder,而是等待这个queue达到一定的数据尺寸才进行处理发送到broker中。如果queue满了kafka会选择把新的数据直接丢掉(-1等待,1数据丢失有参数设置),所以异步的模式会造成数据丢失。
kafka一些问题点的分析的更多相关文章
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台(elk5.2+filebeat2.11)
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台 参考:http://www.tuicool.com/articles/R77fieA 我在做ELK日志平台开始之初选择为 ...
- 使用Akka、Kafka和ElasticSearch等构建分析引擎 -- good
本文翻译自Building Analytics Engine Using Akka, Kafka & ElasticSearch,已获得原作者Satendra Kumar和网站授权. 在这篇文 ...
- Kafka 0.10 SocketServer源代码分析
1概要设计 Kafka SocketServer是基于Java NIO来开发的,采用了Reactor的模式,其中包含了1个Acceptor负责接受客户端请求,N个Processor负责读写数据,M个H ...
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
日志分析平台,架构图如下: 架构解读 : (整个架构从左到右,总共分为5层) 第一层.数据采集层 最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logs ...
- 使用Flume+Kafka+SparkStreaming进行实时日志分析
每个公司想要进行数据分析或数据挖掘,收集日志.ETL都是第一步的,今天就讲一下如何实时地(准实时,每分钟分析一次)收集日志,处理日志,把处理后的记录存入Hive中,并附上完整实战代码 1. 整体架构 ...
- 消息队列——Kafka基本使用及原理分析
文章目录 一.什么是Kafka 二.Kafka的基本使用 1. 单机环境搭建及命令行的基本使用 2. 集群搭建 3. Java API的基本使用 三.Kafka原理浅析 1. topic和partit ...
- Kafka控制器事件处理全流程分析
前言 大家好,我是 yes. 这是Kafka源码分析第四篇文章,今天来说说 Kafka控制器,即 Kafka Controller. 源码类的文章在手机上看其实效果很差,这篇文章我分为两部分,第一部分 ...
- Kafka 探险 - 生产者源码分析: 核心组件
这个 Kafka 的专题,我会从系统整体架构,设计到代码落地.和大家一起杠源码,学技巧,涨知识.希望大家持续关注一起见证成长! 我相信:技术的道路,十年如一日!十年磨一剑! 往期文章 Kafka 探险 ...
- Kafka 0.8源码分析—ZookeeperConsumerConnector
1.HighLevelApi High Level Api是多线程的应用程序,以Topic的Partition数量为中心.消费的规则如下: 一个partition只能被同一个ConsumersGrou ...
- Kafka高性能吞吐关键技术分析
Apache Kafka官网提供的性能说明: Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machin ...
随机推荐
- 转: https原理:证书传递、验证和数据加密、解密过程解析
原本连接:http://www.cnblogs.com/zhuqil/archive/2012/07/23/2604572.html 我们都知道HTTPS能够加密信息,以免敏感信息被第三方获取.所以很 ...
- Python学习笔记(四)——文件永久存储
文件的永久存储 pickle模块的使用 pickle的实质就是将数据对象以二进制的形式存储 存储数据 pickle.dump(data,file) data表示想要存储的数据元素,file表示要将数据 ...
- 7.spark运行模式
sparkbin目录下 ./pyspark --help http://spark.apache.org/docs/latest/submitting-applications.h ...
- php设置时区和strtotime转化为时间戳函数
date_default_timezone_set('PRC');//设置中华人民共和国标准时间 strtotime — 将任何英文文本的日期时间描述解析为 Unix 时间戳 格式:int strto ...
- tomcat下文件路径
第一种:复制要访问的文件a.txt至tomcat安装路径下的webapps/ROOT文件夹下: 访问路径为:localhost:8080/a.txt 或者在webapps文件夹下新建一个文件夹(tes ...
- service资源
service的作用:帮助外界用户访问k8s内的服务,并且提供负载均衡 创建一个service vim k8s_svc.yml apiVersion: v1 kind: Service metadat ...
- 20.multi_case06
# coding:utf-8 import asyncio # 通过create_task()方法 async def a(t): print('-->', t) await asyncio.s ...
- spring AOP 编程--AspectJ注解方式 (4)
1. AOP 简介 AOP(Aspect-Oriented Programming, 面向切面编程): 是一种新的方法论, 是对传统 OOP(Object-Oriented Programming, ...
- web系统基础
网络标准体系架构 B/S(browser/server浏览器)服务器有iis.apache.Tomcat.Ngix.Lighttp等 C/S(client/server客户端)如微信.QQ.Outlo ...
- sql 分组统计查询并横纵坐标转换
关于sql 分组统计查询,我们在做报表的时候经常需要用到;今天就在这里整理下; 先附上一段sql代码: if object_id(N'#mytb',N'U') is not null drop tab ...