linux下mysql的配置问题
设置MySQL 复制以下配置信息到新建的my.ini(windows下的文件)文件中。
[mysqld]
# 设置3306端口
port=
# 设置mysql的安装目录
basedir=D:\Program Files\MySQL\mysql-8.0.-winx64
# 设置mysql数据库的数据的存放目录
datadir=D:\Program Files\MySQL\MySQLDataBase
# 允许最大连接数
max_connections=
# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统
max_connect_errors=
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 默认使用“mysql_native_password”插件认证
default_authentication_plugin=mysql_native_password
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[client]
# 设置mysql客户端连接服务端时默认使用的端口
port=
default-character-set=utf8
到此为止MySQL的下载配置工作已完成,下一步安装。
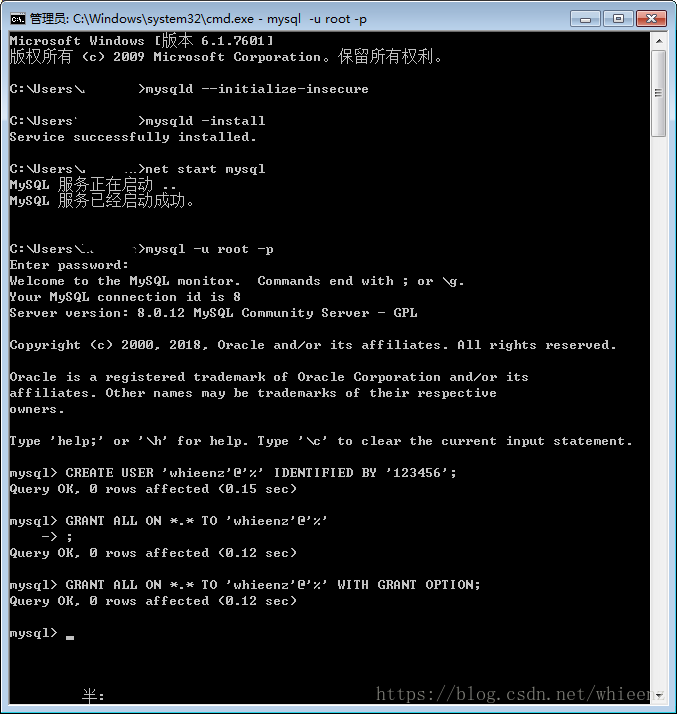
用管理员身份打开CMD!!!
用管理员身份打开CMD!!
用管理员身份打开CMD!
依次执行以下指令:
mysqld --initialize -insecure
mysqld -install
net start mysql
mysql -u root -p
回车(不用输入密码)
所有操作的情况见下图:
三. 创建用户
命令:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';
说明:
username: 你将创建的用户名
host: 指定该用户在哪个主机上可以登陆,如果是本地用户可用localhost,如果想让该用户可以从任意远程主机登陆,可以使用通配符%
password: 该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器
例子:
CREATE USER 'dog'@'localhost' IDENTIFIED BY '';
CREATE USER 'pig'@'192.168.1.101_' IDENDIFIED BY '';
CREATE USER 'pig'@'%' IDENTIFIED BY '';
CREATE USER 'pig'@'%' IDENTIFIED BY '';
CREATE USER 'pig'@'%';
四. 授权:
命令:
GRANT privileges ON databasename.tablename TO 'username'@'host'
说明:
privileges:用户的操作权限,如SELECT,INSERT,UPDATE等,如果要授予所的权限则使用ALL
databasename:数据库名
tablename:表名,如果要授予该用户对所有数据库和表的相应操作权限则可用表示,如.*
例子:
GRANT SELECT, INSERT ON test.user TO 'pig'@'%';
GRANT ALL ON *.* TO 'pig'@'%';
GRANT ALL ON maindataplus.* TO 'pig'@'%';
注意:
用以上命令授权的用户不能给其它用户授权,如果想让该用户可以授权,用以下命令:
GRANT privileges ON databasename.tablename TO 'username'@'host' WITH GRANT OPTION;
有的说明里面还写了下面这条语句(但是我在用的时候好像没写这条语句权限也生效了)
FLUSH PRIVILEGES
五.设置与更改用户密码
命令:
SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword');
如果是当前登陆用户用:
SET PASSWORD = PASSWORD("newpassword");
例子:
SET PASSWORD FOR 'pig'@'%' = PASSWORD("");
六. 撤销用户权限
命令:
REVOKE privilege ON databasename.tablename FROM 'username'@'host';
说明:
privilege, databasename, tablename:同授权部分
例子:
REVOKE SELECT ON *.* FROM 'pig'@'%';
注意:
假如你在给用户’pig’@’%‘授权的时候是这样的(或类似的):GRANT SELECT ON test.user TO ‘pig’@’%’,则在使用REVOKE SELECT ON . FROM ‘pig’@’%’;命令并不能撤销该用户对test数据库中user表的SELECT 操作。相反,如果授权使用的是GRANT SELECT ON . TO ‘pig’@’%’;则REVOKE SELECT ON test.user FROM ‘pig’@’%’;命令也不能撤销该用户对test数据库中user表的Select权限。
具体信息可以用命令SHOW GRANTS FOR ‘pig’@’%’; 查看。
七.删除用户
命令:
DROP USER 'username'@'host';
转载自:https://blog.csdn.net/whieenz/article/details/83015235
my.cnf是mysql的配置文件,我安装(mysql8.0)时默认安装在了 /etc 的目录下了。
Linux中MySQL配置文件my.cnf参数优化
MySQL参数优化这东西不好好研究还是比较难懂的,其实不光是MySQL,大部分程序的参数优化,是很复杂的。MySQL的参数优化也不例外,对于不同的需求,还有硬件的配置,优化不可能又最优选择,只能慢慢的进行优化,需要不断的调试,才能达到不同环境的最优选择。
首先介绍一下MySQL配置文件中不同模块
[client] MySQL客户端应用模块,只有MySQL附带的客户端应用程序保证可以读取此模块下的内容。
[mysqld] MySQL服务端应用模块
[client]
port = 3306
socket = /tmp/mysql.sock [mysqld]
user = mysql --- 表示MySQL的管理用户
port = 3306 --- 端口
socket = /tmp/mysql.sock -- 启动的sock文件
log-bin = /data/mysql-bin
basedir = /usr/local/mysql
datadir = /data/
pid-file = /data/mysql.pid
user = mysql
bind-address = 0.0.0.0
server-id = 1 #表示是本机的序号为1,一般来讲就是master的意思 skip-name-resolve
# 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,
# 则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求 #skip-networking back_log = 600
# MySQL能有的连接数量。当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用,
# 然后主线程花些时间(尽管很短)检查连接并且启动一个新线程。back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。
# 如果期望在一个短时间内有很多连接,你需要增加它。也就是说,如果MySQL的连接数据达到max_connections时,新来的请求将会被存在堆栈中,
# 以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。
# 另外,这值(back_log)限于您的操作系统对到来的TCP/IP连接的侦听队列的大小。
# 你的操作系统在这个队列大小上有它自己的限制(可以检查你的OS文档找出这个变量的最大值),试图设定back_log高于你的操作系统的限制将是无效的。 max_connections = 1000
# MySQL的最大连接数,如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。可以过'conn%'通配符查看当前状态的连接数量,以定夺该值的大小。 max_connect_errors = 6000
# 对于同一主机,如果有超出该参数值个数的中断错误连接,则该主机将被禁止连接。如需对该主机进行解禁,执行:FLUSH HOST。 open_files_limit = 65535
# MySQL打开的文件描述符限制,默认最小1024;当open_files_limit没有被配置的时候,比较max_connections*5和ulimit -n的值,哪个大用哪个,
# 当open_file_limit被配置的时候,比较open_files_limit和max_connections*5的值,哪个大用哪个。 table_open_cache = 128
# MySQL每打开一个表,都会读入一些数据到table_open_cache缓存中,当MySQL在这个缓存中找不到相应信息时,才会去磁盘上读取。默认值64
# 假定系统有200个并发连接,则需将此参数设置为200*N(N为每个连接所需的文件描述符数目);
# 当把table_open_cache设置为很大时,如果系统处理不了那么多文件描述符,那么就会出现客户端失效,连接不上 max_allowed_packet = 4M
# 接受的数据包大小;增加该变量的值十分安全,这是因为仅当需要时才会分配额外内存。例如,仅当你发出长查询或MySQLd必须返回大的结果行时MySQLd才会分配更多内存。
# 该变量之所以取较小默认值是一种预防措施,以捕获客户端和服务器之间的错误信息包,并确保不会因偶然使用大的信息包而导致内存溢出。 binlog_cache_size = 1M
# 一个事务,在没有提交的时候,产生的日志,记录到Cache中;等到事务提交需要提交的时候,则把日志持久化到磁盘。默认binlog_cache_size大小32K max_heap_table_size = 8M
# 定义了用户可以创建的内存表(memory table)的大小。这个值用来计算内存表的最大行数值。这个变量支持动态改变 tmp_table_size = 16M
# MySQL的heap(堆积)表缓冲大小。所有联合在一个DML指令内完成,并且大多数联合甚至可以不用临时表即可以完成。
# 大多数临时表是基于内存的(HEAP)表。具有大的记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。
# 如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。还可以通过设置tmp_table_size选项来增加临时表的大小。也就是说,如果调高该值,MySQL同时将增加heap表的大小,可达到提高联接查询速度的效果 read_buffer_size = 2M
# MySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。
# 如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能 read_rnd_buffer_size = 8M
# MySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,
# MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大 sort_buffer_size = 8M
# MySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。
# 如果不能,可以尝试增加sort_buffer_size变量的大小 join_buffer_size = 8M
# 联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享 thread_cache_size = 8
# 这个值(默认8)表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,
# 如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,
# 增加这个值可以改善系统性能.通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。(–>表示要调整的值)
# 根据物理内存设置规则如下:
# 1G —> 8
# 2G —> 16
# 3G —> 32
# 大于3G —> 64 query_cache_size = 8M
#MySQL的查询缓冲大小(从4.0.1开始,MySQL提供了查询缓冲机制)使用查询缓冲,MySQL将SELECT语句和查询结果存放在缓冲区中,
# 今后对于同样的SELECT语句(区分大小写),将直接从缓冲区中读取结果。根据MySQL用户手册,使用查询缓冲最多可以达到238%的效率。
# 通过检查状态值'Qcache_%',可以知道query_cache_size设置是否合理:如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,
# 如果Qcache_hits的值也非常大,则表明查询缓冲使用非常频繁,此时需要增加缓冲大小;如果Qcache_hits的值不大,则表明你的查询重复率很低,
# 这种情况下使用查询缓冲反而会影响效率,那么可以考虑不用查询缓冲。此外,在SELECT语句中加入SQL_NO_CACHE可以明确表示不使用查询缓冲 query_cache_limit = 2M
#指定单个查询能够使用的缓冲区大小,默认1M key_buffer_size = 4M
#指定用于索引的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,
# 系统将开始换页并且真的变慢了。对于内存在4GB左右的服务器该参数可设置为384M或512M。通过检查状态值Key_read_requests和Key_reads,
# 可以知道key_buffer_size设置是否合理。比例key_reads/key_read_requests应该尽可能的低,
# 至少是1:100,1:1000更好(上述状态值可以使用SHOW STATUS LIKE 'key_read%'获得)。注意:该参数值设置的过大反而会是服务器整体效率降低 ft_min_word_len = 4
# 分词词汇最小长度,默认4 transaction_isolation = REPEATABLE-READ
# MySQL支持4种事务隔离级别,他们分别是:
# READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE.
# 如没有指定,MySQL默认采用的是REPEATABLE-READ,ORACLE默认的是READ-COMMITTED log_bin = mysql-bin
binlog_format = mixed
expire_logs_days = 30 #超过30天的binlog删除 log_error = /data/mysql/mysql-error.log #错误日志路径
slow_query_log = 1
long_query_time = 1 #慢查询时间 超过1秒则为慢查询
slow_query_log_file = /data/mysql/mysql-slow.log performance_schema = 0
explicit_defaults_for_timestamp #lower_case_table_names = 1 #不区分大小写 skip-external-locking #MySQL选项以避免外部锁定。该选项默认开启 default-storage-engine = InnoDB #默认存储引擎 innodb_file_per_table = 1
# InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间
# 独立表空间优点:
# 1.每个表都有自已独立的表空间。
# 2.每个表的数据和索引都会存在自已的表空间中。
# 3.可以实现单表在不同的数据库中移动。
# 4.空间可以回收(除drop table操作处,表空不能自已回收)
# 缺点:
# 单表增加过大,如超过100G
# 结论:
# 共享表空间在Insert操作上少有优势。其它都没独立表空间表现好。当启用独立表空间时,请合理调整:innodb_open_files innodb_open_files = 500
# 限制Innodb能打开的表的数据,如果库里的表特别多的情况,请增加这个。这个值默认是300 innodb_buffer_pool_size = 64M
# InnoDB使用一个缓冲池来保存索引和原始数据, 不像MyISAM.
# 这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
# 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%
# 不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.
# 注意在32位系统上你每个进程可能被限制在 2-3.5G 用户层面内存限制,
# 所以不要设置的太高. innodb_write_io_threads = 4
innodb_read_io_threads = 4
# innodb使用后台线程处理数据页上的读写 I/O(输入输出)请求,根据你的 CPU 核数来更改,默认是4
# 注:这两个参数不支持动态改变,需要把该参数加入到my.cnf里,修改完后重启MySQL服务,允许值的范围从 1-64 innodb_thread_concurrency = 0
# 默认设置为 0,表示不限制并发数,这里推荐设置为0,更好去发挥CPU多核处理能力,提高并发量 innodb_purge_threads = 1
# InnoDB中的清除操作是一类定期回收无用数据的操作。在之前的几个版本中,清除操作是主线程的一部分,这意味着运行时它可能会堵塞其它的数据库操作。
# 从MySQL5.5.X版本开始,该操作运行于独立的线程中,并支持更多的并发数。用户可通过设置innodb_purge_threads配置参数来选择清除操作是否使用单
# 独线程,默认情况下参数设置为0(不使用单独线程),设置为 1 时表示使用单独的清除线程。建议为1 innodb_flush_log_at_trx_commit = 2
# 0:如果innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作(执行是由mysql的master thread线程来执行的。
# 主线程中每秒会将重做日志缓冲写入磁盘的重做日志文件(REDO LOG)中。不论事务是否已经提交)默认的日志文件是ib_logfile0,ib_logfile1
# 1:当设为默认值1的时候,每次提交事务的时候,都会将log buffer刷写到日志。
# 2:如果设为2,每次提交事务都会写日志,但并不会执行刷的操作。每秒定时会刷到日志文件。要注意的是,并不能保证100%每秒一定都会刷到磁盘,这要取决于进程的调度。
# 每次事务提交的时候将数据写入事务日志,而这里的写入仅是调用了文件系统的写入操作,而文件系统是有 缓存的,所以这个写入并不能保证数据已经写入到物理磁盘
# 默认值1是为了保证完整的ACID。当然,你可以将这个配置项设为1以外的值来换取更高的性能,但是在系统崩溃的时候,你将会丢失1秒的数据。
# 设为0的话,mysqld进程崩溃的时候,就会丢失最后1秒的事务。设为2,只有在操作系统崩溃或者断电的时候才会丢失最后1秒的数据。InnoDB在做恢复的时候会忽略这个值。
# 总结
# 设为1当然是最安全的,但性能页是最差的(相对其他两个参数而言,但不是不能接受)。如果对数据一致性和完整性要求不高,完全可以设为2,如果只最求性能,例如高并发写的日志服务器,设为0来获得更高性能 innodb_log_buffer_size = 2M
# 此参数确定些日志文件所用的内存大小,以M为单位。缓冲区更大能提高性能,但意外的故障将会丢失数据。MySQL开发人员建议设置为1-8M之间 innodb_log_file_size = 32M
# 此参数确定数据日志文件的大小,更大的设置可以提高性能,但也会增加恢复故障数据库所需的时间 innodb_log_files_in_group = 3
# 为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3 innodb_max_dirty_pages_pct = 90
# innodb主线程刷新缓存池中的数据,使脏数据比例小于90% innodb_lock_wait_timeout = 120
# InnoDB事务在被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用LOCK TABLES语句注意到锁定设置。默认值是50秒 bulk_insert_buffer_size = 8M
# 批量插入缓存大小, 这个参数是针对MyISAM存储引擎来说的。适用于在一次性插入100-1000+条记录时, 提高效率。默认值是8M。可以针对数据量的大小,翻倍增加。 myisam_sort_buffer_size = 8M
# MyISAM设置恢复表之时使用的缓冲区的尺寸,当在REPAIR TABLE或用CREATE INDEX创建索引或ALTER TABLE过程中排序 MyISAM索引分配的缓冲区 myisam_max_sort_file_size = 10G
# 如果临时文件会变得超过索引,不要使用快速排序索引方法来创建一个索引。注释:这个参数以字节的形式给出 myisam_repair_threads = 1
# 如果该值大于1,在Repair by sorting过程中并行创建MyISAM表索引(每个索引在自己的线程内) interactive_timeout = 28800
# 服务器关闭交互式连接前等待活动的秒数。交互式客户端定义为在mysql_real_connect()中使用CLIENT_INTERACTIVE选项的客户端。默认值:28800秒(8小时) wait_timeout = 28800
# 服务器关闭非交互连接之前等待活动的秒数。在线程启动时,根据全局wait_timeout值或全局interactive_timeout值初始化会话wait_timeout值,
# 取决于客户端类型(由mysql_real_connect()的连接选项CLIENT_INTERACTIVE定义)。参数默认值:28800秒(8小时)
# MySQL服务器所支持的最大连接数是有上限的,因为每个连接的建立都会消耗内存,因此我们希望客户端在连接到MySQL Server处理完相应的操作后,
# 应该断开连接并释放占用的内存。如果你的MySQL Server有大量的闲置连接,他们不仅会白白消耗内存,而且如果连接一直在累加而不断开,
# 最终肯定会达到MySQL Server的连接上限数,这会报'too many connections'的错误。对于wait_timeout的值设定,应该根据系统的运行情况来判断。
# 在系统运行一段时间后,可以通过show processlist命令查看当前系统的连接状态,如果发现有大量的sleep状态的连接进程,则说明该参数设置的过大,
# 可以进行适当的调整小些。要同时设置interactive_timeout和wait_timeout才会生效。 [mysqldump]
quick
max_allowed_packet = 16M #服务器发送和接受的最大包长度 [myisamchk]
key_buffer_size = 8M
sort_buffer_size = 8M
read_buffer = 4M
write_buffer = 4M
转载自:https://www.cnblogs.com/lyq863987322/p/8074749.html
linux下mysql的配置问题的更多相关文章
- Linux下MySQL忘记密码
系统:CentOS6.6 64位 参考文档(截图请看原网址): Linux下MySQL忘记root密码怎么办_百度经验 http://jingyan.baidu.com/article/1709ad8 ...
- linux 下mysql的启动 、调试、排错
Linux 下 MySQL 启动与关闭 说明 一.启动 1.1 MySQL 进程 可以用ps 命令查看进程: [root@rac2 ~]# ps -ef|grep mysql root 21 ...
- linux下mysql远程访问
// */ // ]]> linux下mysql远程访问 Mysql默认root用户只能本地访问,不能远程连接管理mysql数据库,但项目中必须要远程导 入导出数据,所以研究了一下. Tab ...
- linux下mysql字符集编码问题的修改
安装完的MySQL的默认字符集为 latin1 ,为了要将其字符集改为用户所需要的(比如utf8),就必须改其相关的配置文件:由于linux下MySQL的默认安装目录分布在不同的文件下:不像windo ...
- Linux下MySQL的备份与还原
Linux下MySQL的备份与还原 1. 备份 [root@localhost ~]# cd /var/lib/mysql (进入到MySQL库目录,根据自己的MySQL的安装情况调整目录) [roo ...
- linux下mysql定时备份数据库
linux下mysql定时备份数据库 (2010-10-21 12:40:17) 转载▼ 标签: 杂谈 一.用命令实现备份 首页进入mysql的bin目录 1.备份数据#mysqldump -uu ...
- 设置Linux下Mysql表名不区分大小写
1.Linux下mysql安装完后是默认:区分表名的大小写,不区分列名的大小写:2.用root帐号登录后,在/etc/my.cnf中的[mysqld]后添加添加lower_case_table_nam ...
- linux下MySQL 5.6源码安装
linux下MySQL 5.6源码安装 1.下载:当前mysql版本到了5.6.20 http://dev.mysql.com/downloads/mysql 选择Source Code 2.必要软件 ...
- linux下mysql的表名问题
最近从win转移到了linux,在本机跑好的程序但在linux下一个SQL语句报了错误,发现是表名未找到,错误原因是在linux下mysql的表名是严格区分大小写的.. MYSQL在LINUX下数据库 ...
随机推荐
- JAVA POI XSSFWorkbook导出扩展名为xlsx的Excel,附带weblogic 项目导出Excel文件错误的解决方案
现在很多系统都有导出excel的功能,总结一下自己之前写的,希望能帮到其他人,这里我用的是XSSFWorkbook,我们项目在winsang 用的Tomcat,LInux上用的weblogic服务器, ...
- MVC到底是设计模式还是一种框架还是一种架构? https://www.zhihu.com/question/31079945
具体知乎讨论内容:https://www.zhihu.com/question/31079945 MVC到底是设计模式还是一种框架还是一种架构? 我认为它是3种设计模式的演变和组合:观察者模式(Obs ...
- MongoDB后台运行
文章目录 命令方式(推荐) 命令行和配置文件方式 命令行: 配置文件: 命令方式(推荐) 如果想在后台运行,启动时只需添加 --fork函数即可. fork: 以守护进程的方式运行MongoDB. 指 ...
- Python中%r和%s的详解及区别_python_脚本之家
Python中%r和%s的详解及区别_python_脚本之家 https://www.jb51.net/article/108589.htm
- 用原生js封装轮播图
原生js封装轮播图 对于初学js的同学来说,轮播图还是一个难点,尤其是原生js封装轮播图代码,下面是我之前做的一个轮播图项目中封装好的一些代码,有需要的同学可以看一下,有什么不懂的可以看注释,注释看不 ...
- web.xml中多个Servlet执行顺序的问题!
1.两个servlet或者两个servlet-mapping,其中的servlet-name名称不能存在相同. 2.所有的servlet-mapping标签下,url-pattern中包含的文本不能相 ...
- LoadRunner例子:检查点为参数的一个例子
LoadRunner例子:检查点为参数的一个例子 检查点是LoadRunner的一个功能,用来验证业务功能的正确性.如果检查的内容是变化的,脚本该如何写呢? 问题提出:LoadRunner订票网站例子 ...
- Spring 框架中Http请求处理流程
Spring Web http request请求流程: 首先介绍这边你需要知道的继承体系,DispacherServlet继承自FrameworkServlet,FrameworkServlet继承 ...
- jQuery实现contains方法不区分大小写的方法教程
jQuery.expr[':'].Contains = function(a, i, m){ return jQuery(a).text().toUpperCase() .indexOf(m[3].t ...
- Android之shape属性简介和使用
1.shape标签简介 shape的形状,默认为矩形,可以设置为矩形(rectangle).椭圆形(oval).线性形状(line).环形(ring) ! 设置形状: <shape xmln ...