【54】目标检测之Bounding Box预测
Bounding Box预测(Bounding box predictions)
在上一篇笔记中,你们学到了滑动窗口法的卷积实现,这个算法效率更高,但仍然存在问题,不能输出最精准的边界框。在这个笔记中,我们看看如何得到更精准的边界框。

在滑动窗口法中,你取这些离散的位置集合,然后在它们上运行分类器,在这种情况下,这些边界框没有一个能完美匹配汽车位置,也许这个框(编号1)是最匹配的了。还有看起来这个真实值,最完美的边界框甚至不是方形,稍微有点长方形(红色方框所示),长宽比有点向水平方向延伸,有没有办法让这个算法输出更精准的边界框呢?

其中一个能得到更精准边界框的算法是YOLO算法,YOLO(You only look once)意思是你只看一次,这是由Joseph Redmon,Santosh Divvala,Ross Girshick和Ali Farhadi提出的算法。
这个算法是这么做的:
比如你的输入图像是100×100的,然后在图像上放一个网格。为了介绍起来简单一些,我用3×3网格,实际实现时会用更精细的网格,可能是19×19。基本思路是使用图像分类和定位算法(前几个笔记中介绍过的),然后将算法应用到9个格子上。(基本思路是,采用图像分类和定位算法,本周第一个笔记介绍过的,逐一应用在图像的9个格子中。)
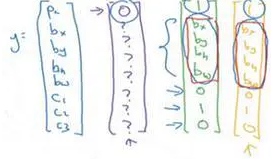
更具体一点,你需要这样定义训练标签,所以对于9个格子中的每一个指定一个标签y,y是8维的,和你之前看到的一样,

p_c等于0或1取决于这个绿色格子中是否有图像。
然后b_x、b_y、b_h和b_w作用就是,如果那个格子里有对象,那么就给出边界框坐标。
然后c_1、c_2和c_3就是你想要识别的三个类别,背景类别不算,所以你尝试在背景类别中识别行人、汽车和摩托车,那么c_1、c_2和c_3可以是行人、汽车和摩托车类别。这张图里有9个格子,所以对于每个格子都有这么一个向量。

我们看看左上方格子,这里这个(编号1),里面什么也没有,所以左上格子的标签向量y是
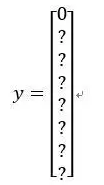
然后这个格子(编号2)的输出标签y也是一样,这个格子(编号3),还有其他什么也没有的格子都一样。
现在这个格子呢?
讲的更具体一点,这张图有两个对象,YOLO算法做的就是,取两个对象的中点,然后将这个对象分配给包含对象中点的格子。
所以左边的汽车就分配到这个格子上(编号4),然后这辆Condor(车型:神鹰)中点在这里,分配给这个格子(编号6)。所以即使中心格子(编号5)同时有两辆车的一部分,我们就假装中心格子没有任何我们感兴趣的对象,所以对于中心格子,分类标签y和这个向量类似,和这个没有对象的向量类似,即

而对于这个格子,这个用绿色框起来的格子(编号4),目标标签就是这样的,这里有一个对象,p_c=1,然后你写出b_x、b_y、b_h和b_w来指定边界框位置,然后还有
类别1是行人,那么c_1=0,
类别2是汽车,所以c_2=1,
类别3是摩托车,则数值c_3=0,即
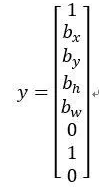
右边这个格子(编号6)也是类似的,因为这里确实有一个对象,它的向量应该是这个样子的,
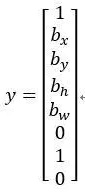
作为目标向量对应右边的格子。
所以对于这里9个格子中任何一个,你都会得到一个8维输出向量,因为这里是3×3的网格,所以有9个格子,总的输出尺寸是3×3×8,所以目标输出是3×3×8。因为这里有3×3格子,然后对于每个格子,你都有一个8维向量y,所以目标输出尺寸是3×3×8。

对于这个例子中,左上格子是1×1×8,对应的是9个格子中左上格子的输出向量。所以对于这3×3中每一个位置而言,对于这9个格子,每个都对应一个8维输出目标向量y,其中一些值可以是dont care-s(即?),如果这里没有对象的话。所以总的目标输出,这个图片的输出标签尺寸就是3×3×8。

如果你现在要训练一个输入为100×100×3的神经网络,现在这是输入图像,然后你有一个普通的卷积网络,卷积层,最大池化层等等,最后你会有这个,选择卷积层和最大池化层,这样最后就映射到一个3×3×8输出尺寸。
所以你要做的是,有一个输入x,就是这样的输入图像,然后你有这些3×3×8的目标标签y。当你用反向传播训练神经网络时,将任意输入x映射到这类输出向量y。
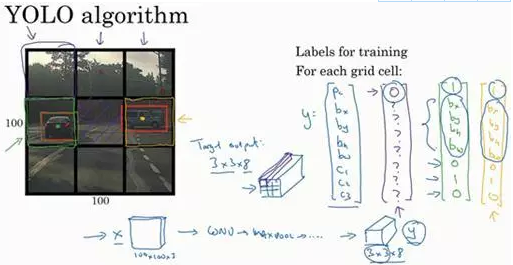
所以这个算法的优点在于神经网络可以输出精确的边界框,所以测试的时候,你做的是喂入输入图像x,然后跑正向传播,直到你得到这个输出y。然后对于这里3×3位置对应的9个输出,我们在输出中展示过的,你就可以读出1或0(编号1位置),你就知道9个位置之一有个对象。如果那里有个对象,那个对象是什么(编号3位置),还有格子中这个对象的边界框是什么(编号2位置)。只要每个格子中对象数目没有超过1个,这个算法应该是没问题的。一个格子中存在多个对象的问题,我们稍后再讨论。但实践中,我们这里用的是比较小的3×3网格,实践中你可能会使用更精细的19×19网格,所以输出就是19×19×8。这样的网格精细得多,那么多个对象分配到同一个格子得概率就小得多。
重申一下,把对象分配到一个格子的过程是,你观察对象的中点,然后将这个对象分配到其中点所在的格子,所以即使对象可以横跨多个格子,也只会被分配到9个格子其中之一,就是3×3网络的其中一个格子,或者19×19网络的其中一个格子。在19×19网格中,两个对象的中点(图中蓝色点所示)处于同一个格子的概率就会更低。
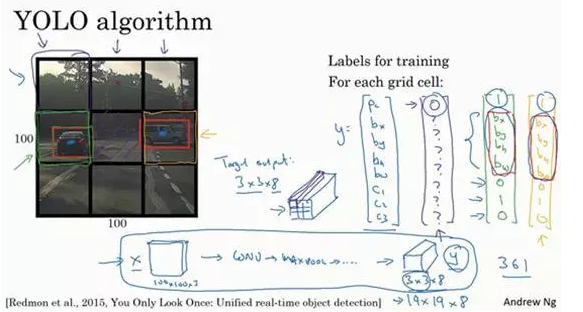
所以要注意,首先这和图像分类和定位算法非常像,我们在本周第一节课讲过的,就是它显式地输出边界框坐标,所以这能让神经网络输出边界框,可以具有任意宽高比,并且能输出更精确的坐标,不会受到滑动窗口分类器的步长大小限制。其次,这是一个卷积实现,你并没有在3×3网格上跑9次算法,或者,如果你用的是19×19的网格,19平方是361次,所以你不需要让同一个算法跑361次。相反,这是单次卷积实现,但你使用了一个卷积网络,有很多共享计算步骤,在处理这3×3计算中很多计算步骤是共享的,或者你的19×19的网格,所以这个算法效率很高。
事实上YOLO算法有一个好处,也是它受欢迎的原因,因为这是一个卷积实现,实际上它的运行速度非常快,可以达到实时识别。在结束之前我还想给你们分享一个小细节,如何编码这些边界框b_x、b_y、b_h和b_w,我们在下一张图上讨论。
这里有两辆车,我们有个3×3网格,我们以右边的车为例(编号1),红色格子里有个对象,所以目标标签y就是,p_c=1,然后b_x、b_y、b_h和b_w,然后c_1=0,c_2=1,c_3=0,即
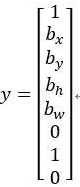
你怎么指定这个边界框呢?
Specify the bounding boxes:
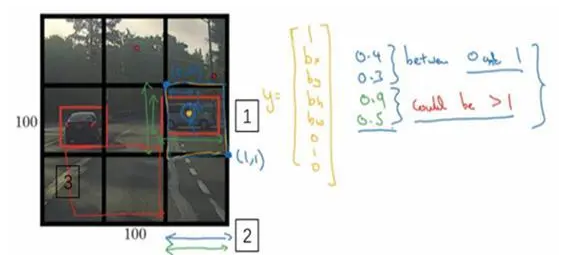
在YOLO算法中,对于这个方框(编号1所示),我们约定左上这个点是(0,0),然后右下这个点是(1,1),要指定橙色中点的位置,b_x大概是0.4,因为它的位置大概是水平长度的0.4,然后b_y大概是0.3,然后边界框的高度用格子总体宽度的比例表示,所以这个红框的宽度可能是蓝线(编号2所示的蓝线)的90%,所以b_h是0.9,它的高度也许是格子总体高度的一半,这样的话b_w就是0.5。换句话说,b_x、b_y、b_h和b_w单位是相对于格子尺寸的比例,所以b_x和b_y必须在0和1之间,因为从定义上看,橙色点位于对象分配到格子的范围内,如果它不在0和1之间,如果它在方块外,那么这个对象就应该分配到另一个格子上。这个值(b_h和b_w)可能会大于1,特别是如果有一辆汽车的边界框是这样的(编号3所示),那么边界框的宽度和高度有可能大于1。
指定边界框的方式有很多,但这种约定是比较合理的,如果你去读YOLO的研究论文,YOLO的研究工作有其他参数化的方式,可能效果会更好,我这里就只给出了一个合理的约定,用起来应该没问题。不过还有其他更复杂的参数化方式,涉及到sigmoid函数,确保这个值(b_x和b_y)介于0和1之间,然后使用指数参数化来确保这些(b_h和b_w)都是非负数,因为0.9和0.5,这个必须大于等于0。还有其他更高级的参数化方式,可能效果要更好一点,但我这里讲的办法应该是管用的。
这就是YOLO算法,你只看一次算法,在接下来的几个笔记中,我会告诉你一些其他的思路可以让这个算法做的更好。在此期间,如果你感兴趣,也可以看看YOLO的论文,在前几张幻灯片底部引用的YOLO论文(Redmon, Joseph, et al. "You Only Look Once: Unified, Real-Time Object Detection." (2015):779-788.)
【54】目标检测之Bounding Box预测的更多相关文章
- 目标检测中bounding box regression
https://zhuanlan.zhihu.com/p/26938549 RCNN实际包含两个子步骤,一是对上一步的输出向量进行分类(需要根据特征训练分类器):二是通过边界回归(bounding-b ...
- 第二十六节,滑动窗口和 Bounding Box 预测
上节,我们学习了如何通过卷积网络实现滑动窗口对象检测算法,但效率很低.这节我们讲讲如何在卷积层上应用这个算法. 为了构建滑动窗口的卷积应用,首先要知道如何把神经网络的全连接层转化成卷积层.我们先讲解这 ...
- DeepLearning.ai学习笔记(四)卷积神经网络 -- week3 目标检测
一.目标定位 这一小节视频主要介绍了我们在实现目标定位时标签该如何定义. 上图左下角给出了损失函数的计算公式(这里使用的是平方差) 如图示,加入我们需要定位出图像中是否有pedestrian,car, ...
- 目标检测之YOLO V1
前面介绍的R-CNN系的目标检测采用的思路是:首先在图像上提取一系列的候选区域,然后将候选区域输入到网络中修正候选区域的边框以定位目标,对候选区域进行分类以识别.虽然,在Faster R-CNN中利用 ...
- 论文阅读笔记四十七:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression(CVPR2019)
论文原址:https://arxiv.org/pdf/1902.09630.pdf github:https://github.com/generalized-iou 摘要 在目标检测的评测体系中,I ...
- 目标检测算法(1)目标检测中的问题描述和R-CNN算法
目标检测(object detection)是计算机视觉中非常具有挑战性的一项工作,一方面它是其他很多后续视觉任务的基础,另一方面目标检测不仅需要预测区域,还要进行分类,因此问题更加复杂.最近的5年使 ...
- 目标检测(七)YOLOv3: An Incremental Improvement
项目地址 Abstract 该技术报告主要介绍了作者对 YOLOv1 的一系列改进措施(注意:不是对YOLOv2,但是借鉴了YOLOv2中的部分改进措施).虽然改进后的网络较YOLOv1大一些,但是检 ...
- 目标检测-yolo
论文下载:http://arxiv.org/abs/1506.02640 代码下载:https://github.com/pjreddie/darknet 1.创新点 端到端训练及推断 + 改革区域建 ...
- 从YOLOv1到YOLOv3,目标检测的进化之路
https://blog.csdn.net/guleileo/article/details/80581858 本文来自 CSDN 网站,作者 EasonApp. 作者专栏: http://dwz.c ...
随机推荐
- Shell常用语句及结构
条件判断语句之if if 语句通过关系运算符判断表达式的真假来决定执行哪个分支:shell有三种if语句样式,如下: 语句1 if [ expression ] then Statement(s) t ...
- java 排序算法分析
一.冒泡排序(时间复杂度O(N^2)) public int[] bubbling(int[] arr){ ) return arr; ; i--){ 1 ; j < i-; j ++){ 2 ...
- learn more ,study less(三):超越整体性学习
高效率的学生 成为一名高效率学生或是自学者需 要掌握减少花在书本上时间的艺术,我上学时,除了全日制的上课学习,业余时间经营一家 企业,每周写大约 7000 字,健身以及主持一家演讲俱乐部,尽管如此,我 ...
- 推荐一本学习Groovy的书籍Groovy程序设计!
有朋友公司在用groovy开发,于是推荐我学习一下,搜到了这本书: 花了一个月时间读完了这本书!写的很棒,几乎没有废话,全书都是很重要的知识点和很好的讲解,确实像封面说的那样,使用的好可以提高开发效率 ...
- centos7下oracle11g详细的安装与建表操作
一.oracle的安装,在官网下载oracle11g R2 1.在桌面单击右键,选择“在终端中打开”,进入终端 输入命令:su 输入ROOT密码: 创建用户组oinstall:groupadd oin ...
- 四、Django学习之关系表介绍及使用
关系表介绍及使用 一对一关系 xx = models.OneToOneField(to='表名',to_field='字段名',on_delete=models.CASCADE) #on_delete ...
- 整合dubbo的依赖
<!-- 版本信息 --> <properties> <dubbo.version>2.7.3</dubbo.version> <maven-ja ...
- SDL多线程显示更新窗口
//初始化SDL2和创建一个窗口,并且将屏幕绘制成大红色 #include <iostream> extern "C" { #include <SDL.h> ...
- 【Qt学习笔记】Qt+VS2010的配置
http://blog.csdn.net/jocyln9026/article/details/8575218 关于Qt Qt是1991年由Trolltech公司开发的一个跨平台的C++图形用户界面应 ...
- SetConsoleTextAttribute设置颜色后的恢复
1. #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <string.h> #include <s ...