Elasticsearch搜索调优
最近把搜索后端从AWS cloudsearch迁到了AWS ES和自建ES集群。测试发现search latency高于之前的benchmark,可见模拟数据远不如真实数据来的实在。这次在产线的backup ES上直接进行测试和优化,通过本文记录search调优的主要过程。
问题1:发现AWS ES shard级别的search latency是非常小的,符合期望,但是最终的查询耗时却非常大(ES response的took), 整体的耗时比预期要高出200ms~300ms。
troubleshooting过程:开始明显看出问题在coordinator node收集数据排序及fetch阶段。开始怀疑是因为AWS ES没有dedicated coordinator节点,data node的资源不足导致这部分耗时较多,后来给所有data node进行来比较大的升级,排除了CPU,MEM, search thread_pool等瓶颈,并且通过cloud watch排除了EBS IOPS配额不够的可能,但是,发现search latency并没有减少。然后就怀疑是network的延时, 就把集群从3个AV调整到1个AV,发现问题依旧。无奈,联系了AWS的support,AWS ES team拿我们的数据和query语句做了benchmark,发现没有某方面的资源瓶颈。这个开始让我们很疑惑,因为在自建ES集群上search latency明显小于AWS ES,两个集群的版本,规格,数据量都差不多。后来AWS回复说是他们那边的架构问题,比之自建集群,AWS ES为了适应公有云上的security, loadbalance要求,在整个请求链路上加了一些组件,导致了整体延时的增加。
确定方案:限于ES cluster不受控,我们只能从自身的数据存储和查询语句上去优化。
存储优化:
1. index sort。我们的查询结果返回都是按时间(created_time)排序的,所以存储的时候即按created_time进行有序存储,方便单segment内的查询提前中断查询,提升查询效率。
2. segment merge。索引是按季度存储的,把2019年之前的索引进行了force merge,进行段合并,2019年之前的索引确定都是只读的。
3. 索引优化。合并了一些小索引,2016,2017年的数据量比较少,把这两年的索引进行合并,减少总shard数。通过创建原索引的别名指向新索引,保证search和index的逻辑不用改动。
查询优化。
先通过profile API定位耗时的子查询语句。
1. 合并查询字段。一个比较耗时子查询查询如下,通常session_id的list size>100,receiver_id和sender_id也会匹配到n多条记录。
{
"minimum_should_match": "1"
"should": [
{
"terms": {
"session_id": [
"ab",
"cd"
],
"boost": 1
}
},
{
"term": {
"receiver_id": {
"value": "efg",
"boost": 1
}
}
},
{
"term": {
"sender_id": {
"value": "hij",
"boost": 1
}
}
}
]
}
新开一个字段session_receiver_sender_id,通过copy_to把每条记录的session_id,receiver_id, sender_id都放到这个字段上。把query语句改为
{
"terms": {
"session_receiver_sender_id": [
"ab",
"cd",
"efg",
"hij"
],
"boost": 1
}
}
不过,测试结论显示,合并之后query耗时并没有明显缩短,感觉改动意义不大。推测可能是我们的BoolQuery字段并不多(就3个),但是terms的size很多(100以上),因为不管是多个字段每个对应一个termQuery,还是一个terms query, 都是转成BoolQuery,最终都是多个termQuery做or。
2. 优化date range查询。另外一个比较耗时的查询是date range。Lucene会rewrite成一个DocValuesFieldExistsQuery。
"filter": [
{
"range": {
"created_time": {
"from": 1560993441118,
"to": null,
"include_lower": true,
"include_upper": true,
"boost": 1
}
}
},
...
]
这里匹配到的docId的确非常多,date range结果在构造docIdset与别的子查询语句做conjunction耗时较大。
采用的一个解决方案是尽量对这个子查询进行缓存,把这个date range查询拆成两段,分为3个月前到昨天,昨天到今天两段,一般昨天的数据不再变化,在没有触发segment merge的情况下3个月前到昨天到查询结果应该能缓存较长时间。
"constant_score": {
"filter": {
"bool": {
"should": [
{
"range": {
"created_time": {
"gte": "now-3M/d",
"lte": "now-1d/d"
}
}
},
{
"range": {
"created_time": {
"gte": "now-1d/d",
"lte": "now/d"
}
}
}
]
}
}
}
相应的,在用户可接受的前提下,调大索引的refresh_interval。
问题2: 在自建ES集群上,发现某个索引500ms以上的搜索耗时占比较多。
这个索引每日大概30w次查询,落在100ms以内的查询超过90%,但是依旧有1%的查询落在500ms以上。发现同样的query语句模版,但如果某些子查询条件匹配到的数据比较多,查询会变对特别慢。
troubleshooting过程:同样是通过profile参数分析比较耗时的查询子句。发现一个PointInSetQuery非常耗时,这个子查询是对一个名为user_type的Integer字段做terms查询,子查询内部又耗时在build_score阶段。
通过查找lucene的代码和相关文章,发现lucene把numeric类型的字段索引成BKD-tree,内部的docId是无序的,与其他查询结果做交集前构造Bitset比较耗时,从而把Integer类型改成keyword,把这个查询转成TermQuery,这样哪怕命中的数据很多,在build_score的时候因为倒排链的docId有序性,利用skiplist,可以更快速的构建一个Bitset。在把这个字段改成keyword后,50th的查询耗时并没有多大差异,但是90th、99th的search latency明显小于之前。

另一个优化,这个索引里的每条数据都是一个非空的accout_id字段,accout_id在query语句里会用于terms查询。遂把这个accout_id字段作为routing进行存储。同时可以对查询语句进行修改:
#原query
"filter": [
{
"terms": {
"account_id": [
"abc123"
],
"boost": 1
}
}
...
]
#改为
"filter": [
{
"terms": {
"_routing": [
"abc123"
]
}
}
...
]
查询改为_routing之后,发现整体的search latency大幅降低。
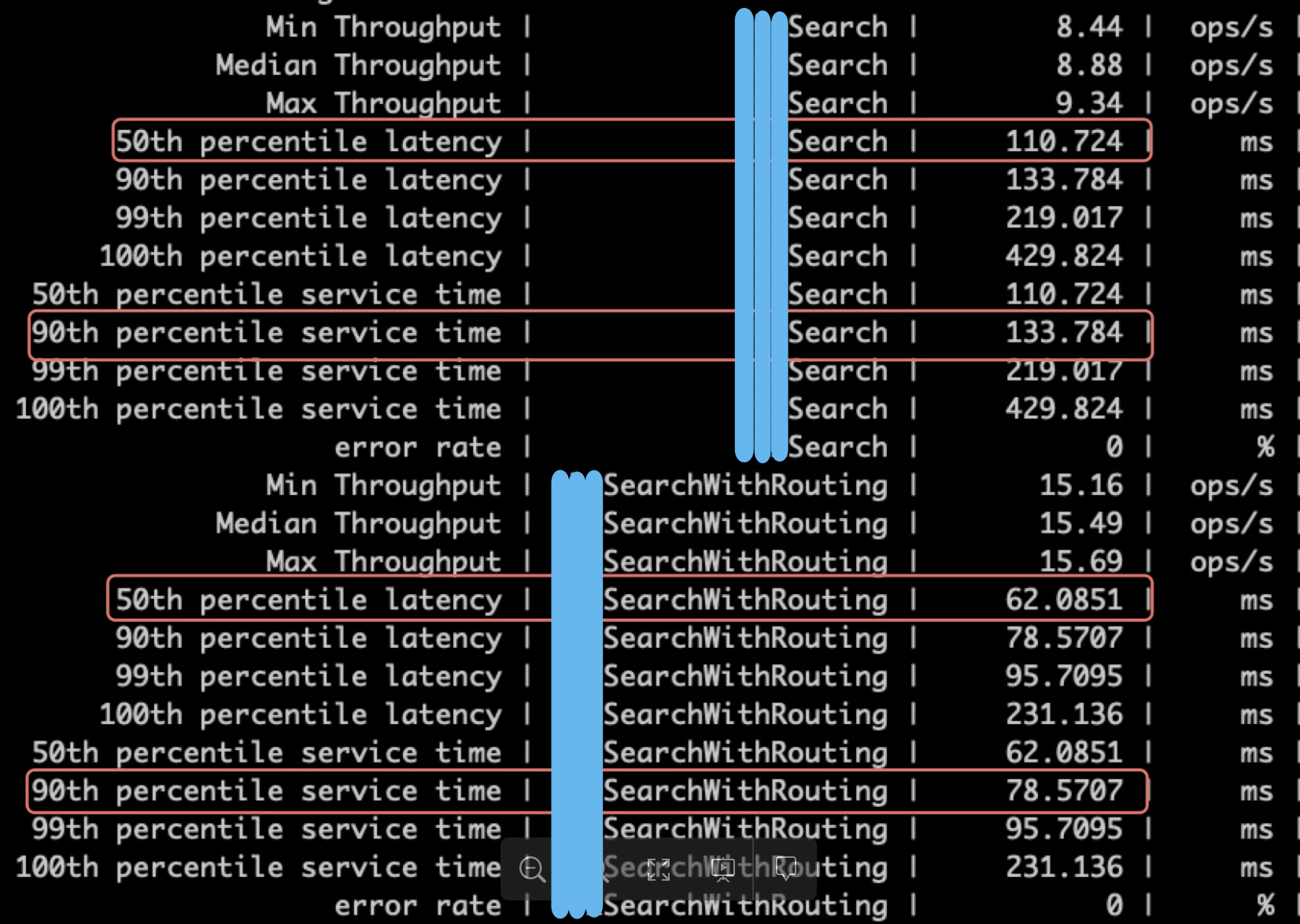
经过这两次改动,针对这个索引的search latency基本满足需求。
另外,还有一个小改动,通过preload docvalue, 可以减少首次查询的耗时。
Elasticsearch搜索调优的更多相关文章
- Elasticsearch搜索调优权威指南 (2/3)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/AAkVdzmkgdBisuQZldsnvg 英文原文:https://qbox.io/blog/el ...
- Elasticsearch搜索调优权威指南 (1/3)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/qwkZKLb_ghmlwrqMkqlb7Q英文原文:https://qbox.io/blog/ela ...
- elasticsearch性能调优
转载 http://www.cnblogs.com/hseagle/p/6015245.html 该es调优版本可能有低,但是思想主体不变,不合适的参数可以自己找最新的版本相应的替代,或者增删 ela ...
- elasticsearch 性能调优
所有的修改都可以在elasticsearch.yml里面修改,也可以通过api来修改.推荐用api比较灵活 1.不同分片之间的数据同步是一个很大的花费,默认是1s同步,如果我们不要求实时性,我们可以执 ...
- 腾讯健康码16亿亮码背后的Elasticsearch系统调优实践【>>戳文章免费体验Elasticsearch服务30天】
[活动]Elasticsearch Service免费体验馆>>Elasticsearch Service新用户特惠狂欢低至4折>>Elasticsearch Service企 ...
- filebeat的层次架构图和配置部署 -- 不错的文档 - elasticsearch 性能调优 + Filebeat配置
1.fielbeat的组件架构-看出层次感 2.工作流程:每个harvester读取新的内容一个日志文件,新的日志数据发送到spooler(后台处理程序),它汇集的事件和聚合数据发送到你已经配置了Fi ...
- elasticsearch运维实战之2 - 系统性能调优
elasticsearch性能调优 集群规划 独立的master节点,不存储数据, 数量不少于2 数据节点(Data Node) 查询节点(Query Node),起到负载均衡的作用 Linux系统参 ...
- ELASTIC SEARCH 性能调优
ELASTICSEARCH 性能调优建议 创建索引调优 1.在创建索引的使用使用批量的方式导入到ES. 2.使用多线程的方式导入数据库. 3.增加默认刷新时间. 默认的刷新时间是1秒钟,这样会产生太多 ...
- 一次看完28个关于ES的性能调优技巧,很赞,值得收藏!
因为总是看到很多同学在说Elasticsearch性能不够好.集群不够稳定,询问关于Elasticsearch的调优,但是每次都是一个个点的单独讲,很多时候都是case by case的解答,本文简单 ...
随机推荐
- 开发者总结的WatchKit App提交技巧
苹果4月初宣布所有注册开发者已经可以向App Store提交基于WatchKit开发的Apple Watch app了,不过不少开发者遇到了模拟器中没有发现的问题.这篇文章主要收集了一些提交tips和 ...
- jq 操作CSS
方式有两种,一种是操作元素className间接控制样式,一种是设置css属性值直接控制样式. jQuery 属性操作方法.jQuery CSS 操作函数 1.addClass() $(selecto ...
- 解决Python操作MySQL中文乱码的问题
原始代码: import os, sys, string import MySQLdb MYSQL_HOST = 'localhost' MYSQL_PORT = ' MYSQL_USER = 'ro ...
- 域名拆分 tld
概念 URL Universal Resource Locator ,统一资源定位符. 用处:用来标识互联网资源的唯一地址. 本质:提供了互联网上任一资源地址的通用表示方法. protocol://h ...
- SDUT-2130_数据结构实验之数组一:矩阵转置
数据结构实验之数组一:矩阵转置 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 数组--矩阵的转置 给定一个m*n的矩阵 ...
- HZOJ Drink
神仙题,打了个whs式暴力卡常卡A了(我没脸),正解还是要打的,然而作者的题解看不懂…… Drink: 看惯了罗马音的小朋友们都会知道r发l的音,题目名:D Link. 每次修改都会改变O( N ^ ...
- Header和Cookie相关内容
相信很多同学都对HTTP的header和cookie,和session都有疑问,因为我们开发的时候一般都需要请求网络获取数据,有时候还需要带cookie或者带特殊的字段发起请求. 现在我们就来简单的了 ...
- LeetCode80 Remove Duplicates from Sorted Array II
题目: Follow up for "Remove Duplicates":What if duplicates are allowed at most twice? (Mediu ...
- day5-python之递归与二分法
一.递归的定义 递归调用是函数嵌套调用的一种特殊形式,函数在调用时,直接或间接调用了自身,就是递归调用 二.递归分为两个阶段:递推,回溯 age(5) = age(4) + 2 age(4) = ag ...
- Jmeter处理数据库
安装环境: jmeter版本:3.1版本 java1.8版本 安装步骤: 1.下载连接mysql数据库jar包,地址:https://pan.baidu.com/s/10k6zD6CU4mo7xYJF ...