海量数据处理之BitMap
有这样一种场景:一台普通PC,2G内存,要求处理一个包含40亿个不重复并且没有排过序的无符号的int整数,给出一个整数,问如果快速地判断这个整数是否在文件40亿个数据当中?
问题思考:
40亿个int占(40亿*4)/1024/1024/1024 大概为14.9G左右,很明显内存只有2G,放不下,因此不可能将这40亿数据放到内存中计算。要快速的解决这个问题最好的方案就是将数据搁内存了,所以现在的问题就在如何在2G内存空间以内存储着40亿整数。一个int整数在java中是占4个字节的即要32bit位,如果能够用一个bit位来标识一个int整数那么存储空间将大大减少,算一下40亿个int需要的内存空间为40亿/8/1024/1024大概为476.83 mb,这样的话我们完全可以将这40亿个int数放到内存中进行处理。
具体思路(BitMap思想):
1个int占4字节即4*8=32位,那么我们只需要申请一个int数组长度为 int tmp[1+N/32]即可存储完这些数据,其中N代表要进行查找的总数,tmp中的每个元素在内存在占32位可以对应表示十进制数0~31,所以可得到BitMap表:
tmp[0]:可表示0~31
tmp[1]:可表示32~63
tmp[2]可表示64~95
.......
那么接下来就看看十进制数如何转换为对应的bit位:
假设这40亿int数据为:6,3,8,32,36,......,那么具体的BitMap表示为:
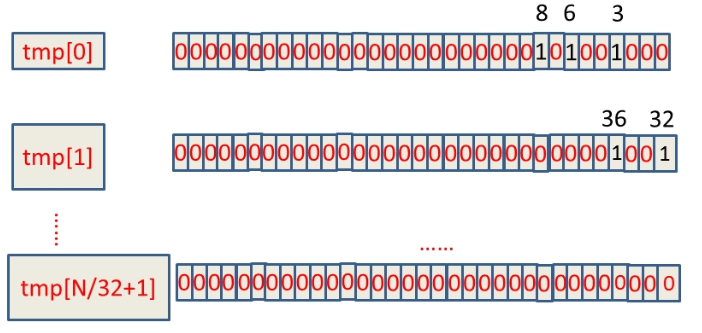
(1)如何判断int数字放在哪一个tmp数组中:将数字直接除以32取整数部分(x/32),例如:整数8除以32取整等于0,那么8就在tmp[0]上;
(2)如何确定数字放在32个位中的哪个位:将数字mod32(x%32)。上例中我们如何确定8在tmp[0]中的32个位中的哪个位,这种情况直接mod上32就ok,又如整数8,在tmp[0]中的第8 mod上32等于8,那么整数8就在tmp[0]中的第八个bit位(从右边数起)。
一、什么是BitMap
Bit-Map会用Bit来标记某个元素对应的value,如何标记的呢,见下例: 我们现在有(1,2,5,8,10)数组,常规来说是这样声明的:
int[] array = {1, 2, 5, 8, 10}
上面这样声明会占用4×5个字节,即20个字节,少量数据可能没有什么特别大的感觉,如果数组长度为10,000,000,这样的方式就会占用4G的内存。
如果用Bit-Map的话,可以这样来组织:
byte[] bytes = new bytes[2];
bytes[0] = 01100100; // 就直接写二进制了
bytes[1] = 10100000;
例如:用位向量来表示数据: 1 、 3 、 6 、 10 、 100
// 1 3 6 10 100
BitSet bitSet = new BitSet(100);
bitSet.set(1,true);
bitSet.set(3,true);
bitSet.set(6,true);
bitSet.set(100,true);
for(int i=0;i<bitSet.size();i++){
boolean b = bitSet.get(i);
if(b){
System.out.println(i);
}
}
}
二、Bit-Map建立
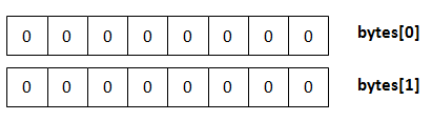
1、开辟定长数组
Bit-Map会声明一个定长的byte/int数组,之后将数组内元素的所有Bit位均置为0,如下图:
2、遍历数据,并插入Bit-Map
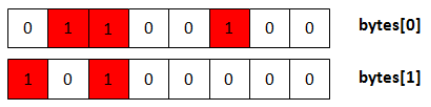
上例来说,就会遍历array{1, 2, 5, 8, 10},并将所有的元素均插入Bit-Map中。Bit-Map是Hash的极致,那么key即为array[i]/8,value即在byte中的位置array[i]%8。而实际中为了效率,hash函数可能会有些出入。如下:

遍历插入之后的数据应该是这样的:
三、Bit-Map的基本思想
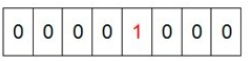
我们先来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1Bytes),首先我们开辟1Byte的空间,将这些空间的所有Bit位都置为0,如下图:

然后遍历这5个元素,首先第一个元素是4,那么就把4对应的位置为1(可以这样操作 p+(i/8)|(0x01<<(i%8)) 当然了这里的操作涉及到Big-ending和Little-ending的情况,这里默认为Big-ending),因为是从零开始的,所以要把第五位置为一(如下图):
然后再处理第二个元素7,将第八位置为1,,接着再处理第三个元素,一直到最后处理完所有的元素,将相应的位置为1,这时候的内存的Bit位的状态如下:
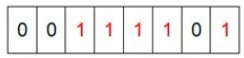
然后我们现在遍历一遍Bit区域,将该位是一的位的编号输出(2,3,4,5,7),这样就达到了排序的目的。
优点:1.运算效率高,不许进行比较和移位;
2.占用内存少,比如N=10000000;只需占用内存为N/8=1250000Byte=1.25M
缺点:
所有的数据不能重复。即不可对重复的数据进行排序和查找。
算法思想比较简单,但关键是如何确定十进制的数映射到二进制bit位的map图。
四、Map映射表
假设需要排序或者查找的总数N=10000000,那么我们需要申请内存空间的大小为int a[1 + N/32],其中:a[0]在内存中占32为可以对应十进制数0-31,依次类推:
bitmap表为:
a[0]--------->0-31
a[1]--------->32-63
a[2]--------->64-95
a[3]--------->96-127
..........
那么十进制数如何转换为对应的bit位,下面介绍用位移将十进制数转换为对应的bit位。
位移转换
申请一个int一维数组,那么可以当作为列为32位的二维数组,
| 32位 |
int a[0] |0000000000000000000000000000000000000|
int a[1] |0000000000000000000000000000000000000|
………………
int a[N] |0000000000000000000000000000000000000|
例如十进制0,对应在a[0]所占的bit为中的第一位: 00000000000000000000000000000001
五、BitMap应用场景扩展
建立了Bit-Map之后,就可以方便的使用了。一般来说Bit-Map可作为数据的查找、去重、排序等操作。
如上面提及的10,000,000个数据存储问题,用Integer存储,耗费4G内存。改成Bit-Map,耗费125MB内存。但是实际中,可能由于数据中最大最小值相差太大,如{1,2 99999},只有三个数,但是最大最小相差悬殊,该方法就不适用了。
查找和去重都好理解,至于排序,有点类似桶排序,每个byte都是一个桶。
1、在3亿个整数中找出重复的整数个数,限制内存不足以容纳3亿个整数
对于这种场景可以采用2-BitMap来解决,即为每个整数分配2bit,用不同的0、1组合来标识特殊意思,如00表示此整数没有出现过,01表示出现一次,11表示出现过多次,就可以找出重复的整数了,其需要的内存空间是正常BitMap的2倍,为:3亿*2/8/1024/1024=71.5MB。
具体的过程如下:扫描着3亿个整数,组BitMap,先查看BitMap中的对应位置,如果00则变成01,是01则变成11,是11则保持不变,当将3亿个整数扫描完之后也就是说整个BitMap已经组装完毕。最后查看BitMap将对应位为11的整数输出即可。
2、对没有重复元素的整数进行排序
对于非重复的整数排序BitMap有着天然的优势,它只需要将给出的无重复整数扫描完毕,组装成为BitMap之后,那么直接遍历一遍Bit区域就可以达到排序效果了。
举个例子:对整数4、3、1、7、6进行排序:

直接按Bit位输出就可以得到排序结果了
3、已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话。
4、2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数
将bit-map扩展一下,用2bit表示一个数即可:0表示未出现;1表示出现一次;2表示出现2次及以上,即重复,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
关于BitMap的运用请参见:http://my.oschina.net/cloudcoder/blog/294810?fromerr=62qBkJF5
http://blog.csdn.net/hguisu/article/details/7880288
注:bitSet.size()返回此BitSet表示位值时实际使用空间的位数;一般为64的整数倍;
new BitSet(950)并不等于建立了一个950大小的BitSet,只是说构建出来的BitSet初始大小至少能容纳950个Bit,大小永远是系统控制的,而且它的大小是64的倍数,就算BitSet(1),它的大小也是64
BitSet能够保证"如果判定结果为false,那么数据一定是不存在的,但是如果结果为true,那么数据可能存在,也可能不存在(冲突覆盖)",即false==yes;true==maybe
海量数据处理之BitMap的更多相关文章
- 海量数据处理算法—Bit-Map
原文:http://blog.csdn.net/hguisu/article/details/7880288 1. Bit Map算法简介 来自于<编程珠玑>.所谓的Bit-map就是用一 ...
- 海量数据处理算法—BitMap
1. Bit Map算法简介 来自于<编程珠玑>.所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素.由于采用了Bit为单位来存储数据,因此在存储空 ...
- 从hadoop框架与MapReduce模式中谈海量数据处理
http://blog.csdn.net/wind19/article/details/7716326 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显 ...
- 从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构) (转)
转自:http://blog.csdn.net/v_july_v/article/details/6704077 从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到 ...
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
- july教你如何迅速秒杀掉:99%的海量数据处理面试题
作者:July出处:结构之法算法之道blog 以下是原博客链接网址 http://blog.csdn.net/v_july_v/article/details/7382693 微软面试100题系列 h ...
- (面试)Hash表算法十道海量数据处理面试题
Hash表算法处理海量数据处理面试题 主要针对遇到的海量数据处理问题进行分析,参考互联网上的面试题及相关处理方法,归纳为三种问题 (1)数据量大,内存小情况处理方式(分而治之+Hash映射) (2)判 ...
- 海量数据处理面试题学习zz
来吧骚年,看看海量数据处理方面的面试题吧. 原文:(Link, 其实引自这里 Link, 而这个又是 Link 的总结) 另外还有一个系列,挺好的:http://blog.csdn.net/v_jul ...
- 海量数据处理的 Top K 相关问题
Top-k的最小堆解决方法 问题描述:有N(N>>10000)个整数,求出其中的前K个最大的数.(称作Top k或者Top 10) 问题分析:由于(1)输入的大量数据:(2)只要前K个,对 ...
随机推荐
- Scala知识点汇总
Scala数组小结 1.定长数组 定长数组:指长度不可变的数组Array.第一种方式:先声明一个数组,后初始化该数组: scala> val array = new Array[Double]( ...
- Openvswitch手册(3): sFlow, netFlow
这一节,我们重点看sFlow 采样流sFlow(Sampled Flow)是一种基于报文采样的网络流量监控技术,主要用于对网络流量进行统计分析. sFlow系统包含一个嵌入在设备中的sFlow Age ...
- 背水一战 Windows 10 (94) - 选取器: 自定义文件打开选取器
[源码下载] 背水一战 Windows 10 (94) - 选取器: 自定义文件打开选取器 作者:webabcd 介绍背水一战 Windows 10 之 选取器 自定义文件打开选取器 示例1.演示如何 ...
- 脑残式网络编程入门(六):什么是公网IP和内网IP?NAT转换又是什么鬼?
本文引用了“帅地”发表于公众号苦逼的码农的技术分享. 1.引言 搞网络通信应用开发的程序员,可能会经常听到外网IP(即互联网IP地址)和内网IP(即局域网IP地址),但他们的区别是什么?又有什么关系呢 ...
- 知乎技术分享:从单机到2000万QPS并发的Redis高性能缓存实践之路
本文来自知乎官方技术团队的“知乎技术专栏”,感谢原作者陈鹏的无私分享. 1.引言 知乎存储平台团队基于开源Redis 组件打造的知乎 Redis 平台,经过不断的研发迭代,目前已经形成了一整套完整自动 ...
- Python爬虫3-parse编码与利用parse模拟post请求
GitHub代码练习地址:①利用parse模拟post请求:https://github.com/Neo-ML/PythonPractice/blob/master/SpiderPrac04_pars ...
- CSS实现div高度自适应
1.有时候,我们希望容器有一个固定高度,但当其中的内容多的时候,又希望高度能够自适应,也即容器在纵向能被撑开,且如果有背景,也能够自适应.在一般情况下,使用min-height即可解决.但是广大网民的 ...
- [Postman]证书(13)
Postman的本机应用程序提供了一种基于每个域查看和设置SSL证书的方法. 要管理客户端证书,请单击标题工具栏右侧的扳手图标,选择“设置”,然后选择“ 证书”选项卡. 添加客户端证书 要添加新客户端 ...
- error) DENIED Redis is running in protected mode because protected mode is enabled报错
官网地址:https://redis.io/download 官方安装文档如下: Installation Download, extract and compile Redis with: $ wg ...
- .Net Core 2.0 preview1实现自定义认证方案
Microsoft.Authentication的使用方法在2.0中发生了比较大的变化,在1.1中认证配置是在Configure中完成. public void ConfigureServices(I ...