论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)

论文链接:https://arxiv.org/abs/1802.02611
tensorflow 官方实现: https: //github.com/tensorflow/models/tree/master/research/deeplab
实验代码:https://github.com/fourmi1995/IronSegExperiment-Deeplabv3_PLUS.git
摘要
分割任务中常见的结构有空间池化模型与编码-解码结构,前者主要通过不同的卷积和不同rate的池化操作和感受野对输入的feature map编码多尺寸信息。编码-解码结构可以通过逐渐恢复空间信息获得物体的边缘信息。该文的改进:(1)结合了上述两种结构的优点。DeepLabv3+ 在DeepLabv3的基础上增加了一个decoder 模型来是增强物体边缘的分割。(2)引用了Xception中的深度可分卷积,应用在ASPP与decoder提高了网络的训练速度。
介绍
通过引入空洞卷积可以生成更加密集的feature map,然而由于GPU内存的限制,提取输入图片分辨率小4倍甚至8倍的feature map在计算上是不被允许的。而decoder层由于没有卷积核没有被扩张,因此计算速度上可以提高很多。本文的贡献如下。
(1)让DeepLabv3作为encoder,用一个简单有效的decoder模型,形成encoder-decoder结构。
(2)可以通过空洞卷积随意控制编码层feature map的分辨率。
(3)将Xception的深层可分卷积应用在ASPP与decoder模型中,使网络更快速。
(4)在PASCAL VOC2012与Cityscapes上得到stae-of-art的效果。
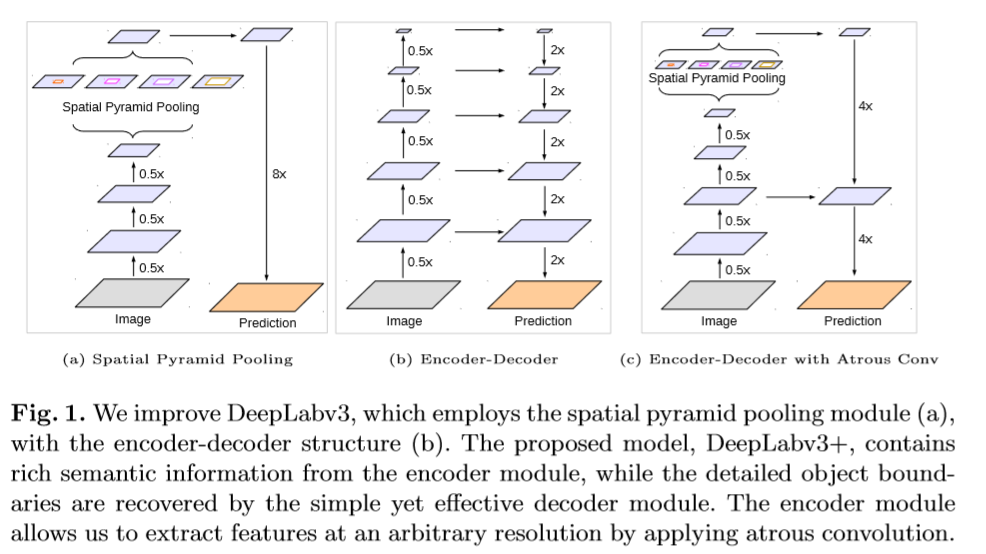
相关工作
Encoder-Decoder:(1)Encoder模型用于减少feature map的分辨率并捕捉更抽象的分割信息。(2)Decoder模型用于恢复空间信息。
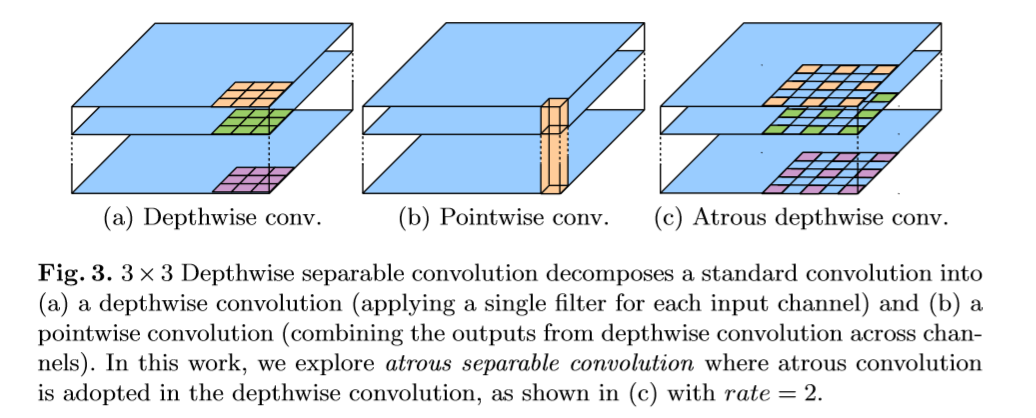
深度可分卷积(group 卷积):该卷积的一个优势是可以在保证性能相近的条件下尽可能的减少计算量和大量的可训练参数。
(参考博客:https://medium.com/@chih.sheng.huang821/%E6%B7%B1%E5%BA%A6%E5%AD%B8%E7%BF%92-mobilenet-depthwise-separable-convolution-f1ed016b3467)
方法
深度可分卷积,将标准的卷积拆为深度卷积,后接一个pointwise卷积(1x1卷积),极大的减少了计算量。深度卷积的功能是对每一个通道进行空间卷积,而pointwise卷积的功能是将深度卷积的输出进行融合。
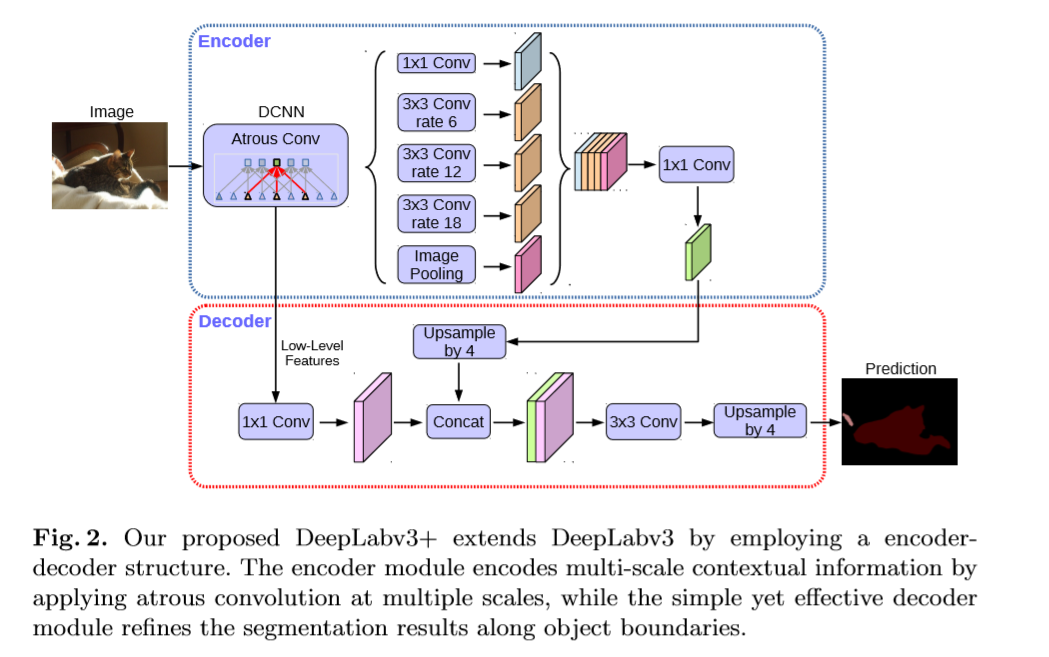
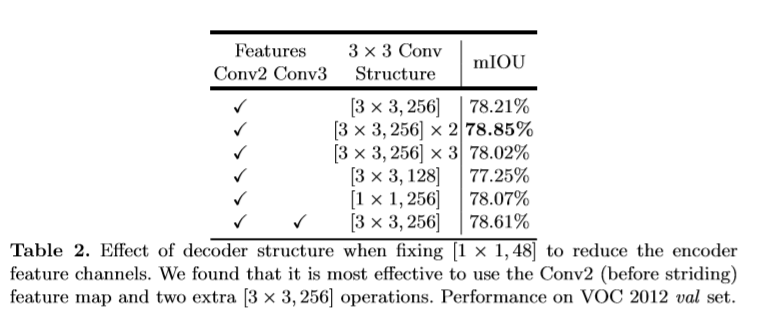
该文使用DeepLabv3中logits前最后一层的feature map作为encoder的输出。通常得到的out_stride为16,基于双线性插值上采样16倍作为decoder层比较常用,但有时可能得不到理想的效果(边界信息仍不准确)。该文提出如下模型。(1)首先通过双线性插值恢复4倍大小的分辨率。(2)然后与对应的低层次的feature map进行拼接,低层次的feature map首先用1x1的卷积处理降低通道数。(3)后接一个大小为3x3的卷积来增强feature maps(4)在通过一个插值来进一步恢复4倍分辨率至原图大小。
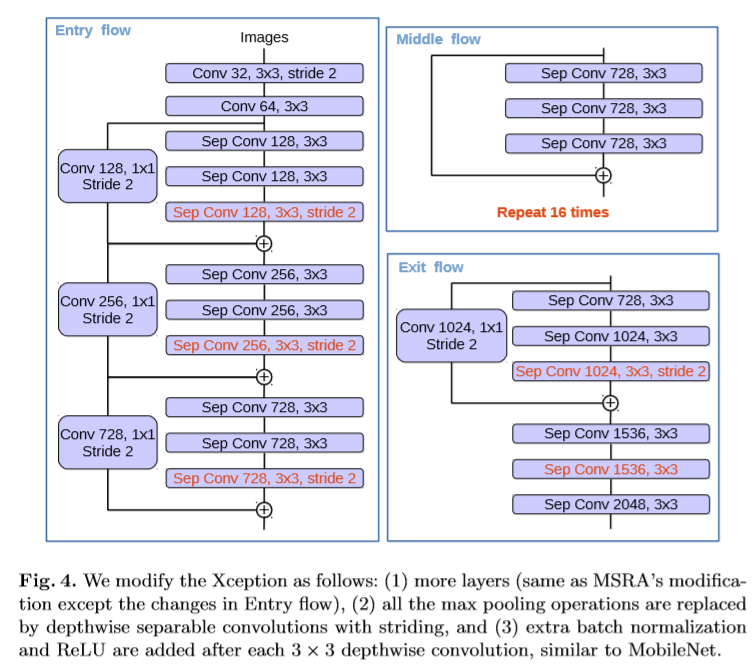
该文对Xception模型的改进,(1)加深了Xception(2)用深度可分卷积替换所有max pooling 减少了计算量,进而可以使用空洞卷积来提取feature(另一种方式是直接在max pooling 中应用空洞卷积)(3)在每个3x3的深度可分卷积后后接,BN层和ReLU。
实验
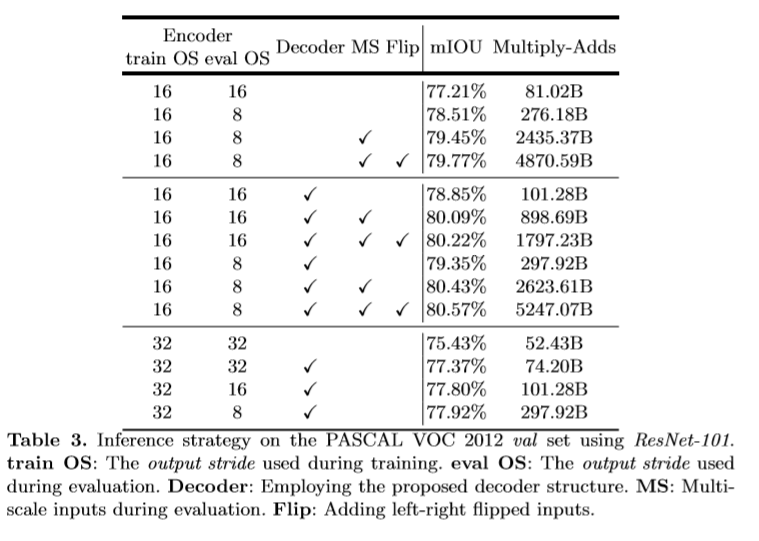
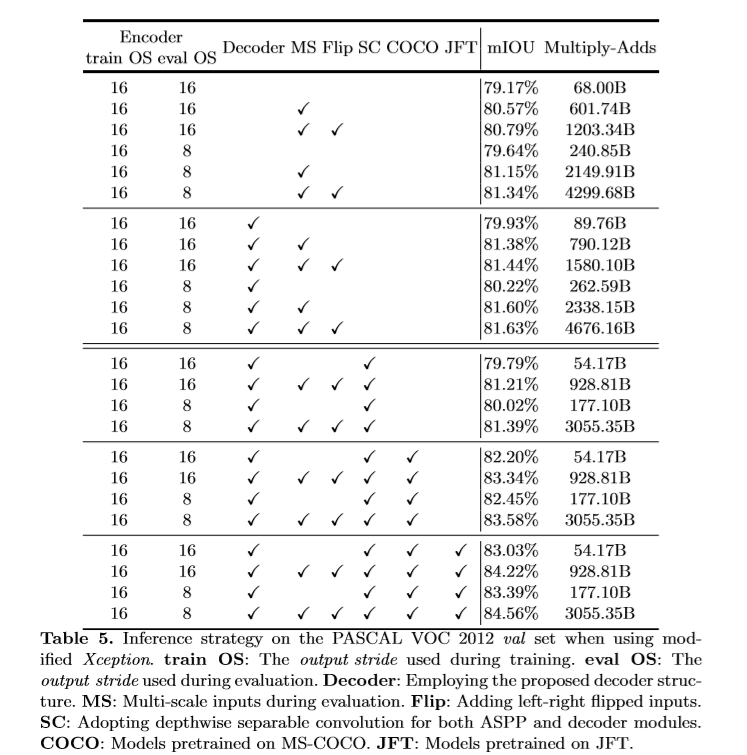
该文使用了预训练的ResNet-101和改进后的Xception通过空洞卷积来提取密集的特征。
learning rate policy: "poly" , learning rate: 0.007, crop size: 513x513 , output_stride = 16,random scale data augmentation


参考
1. Everingham, M., Eslami, S.M.A., Gool, L.V., Williams, C.K.I., Winn, J., Zisserman, A.: The pascal visual object classes challenge a retrospective. IJCV (2014)
2. Mottaghi, R., Chen, X., Liu, X., Cho, N.G., Lee, S.W., Fidler, S., Urtasun, R., Yuille, A.: The role of context for object detection and semantic segmentation in the wild. In: CVPR. (2014)
3. Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: CVPR. (2016)
个人实验结果

论文阅读笔记十二:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation(DeepLabv3+)(CVPR2018)的更多相关文章
- 论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
论文链接:https://arxiv.org/abs/1506.04924 摘要 该文提出了基于混合标签的半监督分割网络.与当前基于区域分类的单任务的分割方法不同,Decoupled 网络将分割与分类 ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记十九:PIXEL DECONVOLUTIONAL NETWORKS(CVPR2017)
论文源址:https://arxiv.org/abs/1705.06820 tensorflow(github): https://github.com/HongyangGao/PixelDCN 基于 ...
- 论文阅读笔记十六:DeconvNet:Learning Deconvolution Network for Semantic Segmentation(ICCV2015)
论文源址:https://arxiv.org/abs/1505.04366 tensorflow代码:https://github.com/fabianbormann/Tensorflow-Decon ...
- 论文阅读笔记十五:Pyramid Scene Parsing Network(CVPR2016)
论文源址:https://arxiv.org/pdf/1612.01105.pdf tensorflow代码:https://github.com/hellochick/PSPNet-tensorfl ...
- 论文阅读笔记(二十二)【CVPR2017】:See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks for Video-based Person Re-identification
Introduction 在视频序列中,有些帧由于被严重遮挡,需要被尽可能的“忽略”掉,因此本文提出了时间注意力模型(temporal attention model,TAM),注重于更有相关性的帧. ...
- 论文阅读笔记(二十)【AAAI2019】:Spatial and Temporal Mutual Promotion for Video-Based Person Re-Identification
Introduction (1)Motivation: 作者考虑到空间上的噪声可以通过时间信息进行弥补,其原因为:不同帧的相同区域可能是相似信息,当一帧的某个区域存在噪声或者缺失,可以用其它帧的相同区 ...
- 论文阅读笔记十八:ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation(CVPR2016)
论文源址:https://arxiv.org/abs/1606.02147 tensorflow github: https://github.com/kwotsin/TensorFlow-ENet ...
- 【学习笔记】Vins-Mono论文阅读笔记(二)
估计器初始化简述 单目紧耦合VIO是一个高度非线性的系统,需要在一开始就进行准确的初始化估计.通过将IMU预积分与纯视觉结构进行松耦合对齐,我们得到了必要的初始值. 理解:这里初始化是指通过之前imu ...
随机推荐
- 【转载】使用python库--Graphviz为论文画出漂亮的示意图
原文: Drawing Graphs using Dot and Graphviz 1 License Copyright (C) 2013, 2014, 2015, 2016, 2017, 2018 ...
- spring-session+Redis实现Session共享
关于session共享的方式有多种: (1)通过nginx的ip_hash,根据ip将请求分配到对应的服务器 (2)基于关系型数据库存储 (3)基于cookie存储 (4)服务器内置的session复 ...
- CF1091F New Year and the Mallard Expedition
题目地址:CF1091F New Year and the Mallard Expedition 题意比较复杂,整理一下: \(n\) 段,每段有两个属性:长度,地形(G,W,L) 有三种运动方式: ...
- Des加密解密算法java实现
package tech.fullink.eaglehorn.utils; import javax.crypto.Cipher; import javax.crypto.SecretKey; imp ...
- Shell-自动建立全国城市
Code: #!/bin/bash function mkdirFun() { if [ ! -d $1 ];then mkdir -p $1 fi } filename=city1.txt date ...
- Fusebox 类似WEBPACK 的工具,React Studio
Fusebox 类似WEBPACK 的工具, http://fuse-box.org/ React Studio: https://hackernoon.com/@reactstudio
- HTTP协议03-http特点及请求方式
无状态: HTTP是一种不保存状态,既无状态协议.HTTP自身不对请求和响应之间的通信状态进行保存,也就是说不做持久化处理.这是为了更快处理大量事务,确保协议的可伸缩性. 随着web的不断发展,无状态 ...
- Python3学习笔记34-pymongo模块
pymongo模块是python操作mongo数据的第三方模块,记录一下自己常用到的简单用法. 首先需要连接数据库: MongoClient():该方法第一个参数是数据库所在地址,第二个参数是数据库所 ...
- logging模块--日志文件
初级的使用配置模式类似与print 默认打印waring等级及以上--通过更改等级来测试代码 logging.debug("debug no china") #调试模式 loggi ...
- 词向量之Word2vector原理浅析
原文地址:https://www.jianshu.com/p/b2da4d94a122 一.概述 本文主要是从deep learning for nlp课程的讲义中学习.总结google word2v ...