一脸懵逼学习Hive(数据仓库基础构架)
Hive是什么?其体系结构简介*
Hive的安装与管理*
HiveQL数据类型,表以及表的操作*
HiveQL查询数据***
Hive的Java客户端**Hive的自定义函数UDF*
1:什么是Hive(一):
(1)Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 QL ,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
(2)Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行。
(3)Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹,可以直接在M/R Job里使用这些数据。
2:Hive的系统架构:
(1)用户接口,包括 CLI,JDBC/ODBC,WebUI(用户接口主要有三个:CLI,JDBC/ODBC和 WebUI:);
CLI,即Shell命令行;
JDBC/ODBC 是 Hive 的Java,与使用传统数据库JDBC的方式类似;
WebGUI是通过浏览器访问 Hive;
(2)元数据存储,通常是存储在关系数据库如 mysql, derby 中;
Hive 将元数据存储在数据库中(metastore),目前只支持 mysql、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等;
(3)解释器、编译器、优化器、执行器;
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划(plan)的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行;
(4)Hadoop:用 HDFS 进行存储,利用 MapReduce 进行计算;
Hive 的数据存储在 HDFS 中,大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务)
3:Hive的安装:
(1)把hive-0.9.0.tar.gz复制到/usr/local
(2)解压hive-0.9.0.tar.gz与重命名
#cd /usr/local
#tar -zxvf hive-0.9.0.tar.gz
#mv hive-0.9.0 hive
(3)修改/etc/profile文件。
#vi /etc/profile
增加
export HIVE_HOME=/usr/local/hive
修改
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HIVE_HOME/bin
保存退出
#source /etc/profile
(4)cd $HIVE_HOME
mv hive-env.sh.template hive-env.sh
mv hive-default.xml.template hive-site.xml
修改hadoop的hadoop-env.sh(否则启动hive汇报找不到类的错误)
export HADOOP_CLASSPATH=.:$CLASSPATH:$HADOOP_CLASSPATH:
$HADOOP_HOME/bin
修改$HIVE_HOME/bin的hive-config.sh,增加以下三行
export JAVA_HOME=/usr/local/jdk
export HIVE_HOME=/usr/local/hive
export HADOOP_HOME=/usr/local/hadoop
(5)启动
#hive
hive>show tables;
hive>create table test(id int,name string);
hive>quit;
观察:#hadoop fs -ls /user/hive
参数:hive.metastore.warehouse.dir
4:Hive的metastore:
(1)metastore是hive元数据的集中存放地。metastore默认使用内嵌的derby数据库作为存储引擎;
(2)Derby引擎的缺点:一次只能打开一个会话;
(3)使用Mysql作为外置存储引擎,多用户同时访问;
5:Hive的安装:
配置MySQL的metastore
(1)上传mysql-connector-java-5.1.10.jar到$HIVE_HOME/lib
(2)登录MYSQL,创建数据库hive
#mysql -uroot -padmin
mysql>create database hive;
mysql>GRANT all ON hive.* TO root@'%' IDENTIFIED BY 'admin';
mysql>flush privileges;
mysql>set global binlog_format='MIXED';
(3)把mysql的数据库字符类型改为latin1
(4)修改$HIVE_HOME/conf/hive-site.xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop0:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>admin</value>
</property>
6:Hive运行模式 :
(1)Hive的运行模式即任务的执行环境
(2)分为本地与集群两种
我们可以通过mapred.job.tracker 来指明
设置方式:
hive > SET mapred.job.tracker=local
7:Hive的启动方式:
(1)、hive 命令行模式,直接输入#/hive/bin/hive的执行程序,或者输入 #hive --service cli
(2)、 hive web界面的 (端口号9999) 启动方式
#hive --service hwi &
用于通过浏览器来访问hive
http://hadoop0:9999/hwi/
(3)、 hive 远程服务 (端口号10000) 启动方式
#hive --service hiveserver &
8:Hive与传统数据库: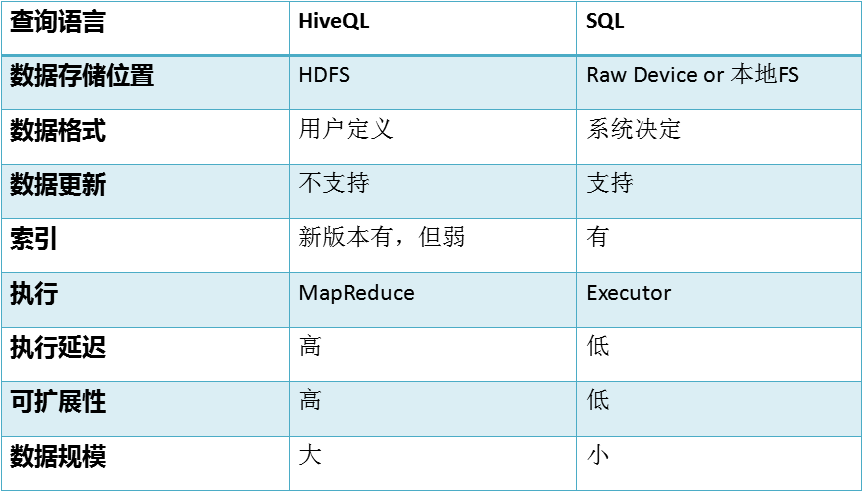
9:Hive的数据类型:
(1)基本数据类型:
tinyint/smallint/int/bigint
float/double
boolean
string
(2)复杂数据类型:
Array/Map/Struct
(3)没有date/datetime
10:Hive的数据存储:
(1)Hive的数据存储基于Hadoop HDFS;
(2)Hive没有专门的数据存储格式;
(3)存储结构主要包括:数据库、文件、表、视图;
(4)Hive默认可以直接加载文本文件(TextFile),还支持sequence file 、RC file;
(5)创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据;
11:Hive的数据模型-数据库:
(1)类似传统数据库的DataBase
(2)默认数据库"default"
使用#hive命令后,不使用hive>use <数据库名>,系统默认的数据库。可以显式使用hive> use default;
创建一个新库
hive > create database test_dw;
12:Hive的数据模型-表:
Table 内部表
Partition 分区表
External Table 外部表
Bucket Table 桶表
13:Hive的数据模型-内部表:
(1)与数据库中的 Table 在概念上是类似
(2)每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路径为:/ warehouse/test。 warehouse是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录
(3)所有的 Table 数据(不包括 External Table)都保存在这个目录中。
(4)删除表时,元数据与数据都会被删除
(5)创建数据文件inner_table.dat
(6)创建表:
hive>create table inner_table (key string);
(7)加载数据:
hive>load data local inpath '/root/inner_table.dat' into table inner_table;
(8)查看数据:
select * from inner_table
select count(*) from inner_table
(9)删除表 drop table inner_table
14:Hive的数据模型-分区表:
(1)Partition 对应于数据库的 Partition 列的密集索引
(2)在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中
例如:test表中包含 date 和 city 两个 Partition,
则对应于date=20130201, city = bj 的 HDFS 子目录为:
/warehouse/test/date=20130201/city=bj
对应于date=20130202, city=sh 的HDFS 子目录为;
/warehouse/test/date=20130202/city=sh
一些相关命令
SHOW TABLES; # 查看所有的表
SHOW TABLES '*TMP*'; #支持模糊查询
SHOW PARTITIONS TMP_TABLE; #查看表有哪些分区
DESCRIBE TMP_TABLE; #查看表结构
(3)创建数据文件partition_table.dat
(4)创建表
create table partition_table(rectime string,msisdn string) partitioned by(daytime string,city string) row format delimited fields terminated by '\t' stored as TEXTFILE;
(5)加载数据到分区
load data local inpath '/home/partition_table.dat' into table partition_table partition (daytime='2013-02-01',city='bj');
(6)查看数据
select * from partition_table
select count(*) from partition_table
(7)删除表 drop table partition_table
(8)alter table partition_table add partition (daytime='2013-02-04',city='bj');
通过load data 加载数据
(9)alter table partition_table drop partition (daytime='2013-02-04',city='bj')
元数据,数据文件删除,但目录daytime=2013-02-04还在
15:Hive的数据模型—桶表:
(1)桶表是对数据进行哈希取值,然后放到不同文件中存储。
(2)创建表
create table bucket_table(id string) clustered by(id) into 4 buckets;
(3)加载数据
set hive.enforce.bucketing = true;
insert into table bucket_table select name from stu;
insert overwrite table bucket_table select name from stu;
(4)数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。
(5)抽样查询
select * from bucket_table tablesample(bucket 1 out of 4 on id);
16:Hive的数据模型-外部表:
(1)指向已经在 HDFS 中存在的数据,可以创建 Partition;
(2)它和 内部表 在元数据的组织上是相同的,而实际数据的存储则有较大的差异;
(3)内部表 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除;
(4)外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个 外部表 时,仅删除该链接;
CREATE EXTERNAL TABLE page_view
( viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination‘
)
COMMENT 'This is the staging page view table'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '' LINES TERMINATED BY ''
STORED AS TEXTFILE
LOCATION 'hdfs://centos:9000/user/data/staging/page_view';
(5)创建数据文件external_table.dat
(6)创建表
hive>create external table external_table1 (key string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/home/external';
(7)在HDFS创建目录/home/external
#hadoop fs -put /home/external_table.dat /home/external
(8)加载数据
LOAD DATA INPATH '/home/external_table1.dat' INTO TABLE external_table1;
(9)查看数据
select * from external_table
select count(*) from external_table
(10)删除表
drop table external_table
17:视图操作:
视图的创建
CREATE VIEW v1 AS select * from t1;
18:表的操作:
(1)表的修改
alter table target_tab add columns (cols,string)
(2)表的删除
drop table
19:为什么选择Hive?
(1)基于Hadoop的大数据的计算/扩展能力;
(2)支持SQL like查询语言;
(3)统一的元数据管理;
(4)简单编程;
20:导入数据
(1)当数据被加载至表中时,不会对数据进行任何转换。Load 操作只是将数据复制/移动至 Hive 表对应的位置。
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
(2)把一个Hive表导入到另一个已建Hive表
INSERT OVERWRITE TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement FROM from_statement
CTAS
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
(col_name data_type, ...) …
AS SELECT …
例:create table new_external_test as select * from external_table1;
21:查询
select
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] | [ORDER BY col_list] ]
[LIMIT number]
(1)基于Partition的查询
一般 SELECT 查询是全表扫描。但如果是分区表,查询就可以利用分区剪枝(input pruning)的特性,类似“分区索引“”,只扫描一个表中它关心的那一部分。Hive 当前的实现是,只有分区断言(Partitioned by)出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝。例如,如果 page_views 表(按天分区)使用 date 列分区,以下语句只会读取分区为‘2008-03-01’的数据。
SELECT page_views.* FROM page_views WHERE page_views.date >= '2013-03-01' AND page_views.date <= '2013-03-01'
(2)LIMIT Clause
Limit 可以限制查询的记录数。查询的结果是随机选择的。下面的查询语句从 t1 表中随机查询5条记录:
SELECT * FROM t1 LIMIT 5
(3)Top N查询
下面的查询语句查询销售记录最大的 5 个销售代表。
SET mapred.reduce.tasks = 1 SELECT * FROM sales SORT BY amount DESC LIMIT 5
22:表连接
(1)导入ac信息表
hive> create table acinfo (name string,acip string) row format delimited fields terminated by '\t' stored as TEXTFILE;
hive> load data local inpath '/home/acinfo/ac.dat' into table acinfo;
(2)内连接
select b.name,a.* from dim_ac a join acinfo b on (a.ac=b.acip) limit 10;
(3)左外连接
select b.name,a.* from dim_ac a left outer join acinfo b on a.ac=b.acip limit 10;
23:Java客户端
(1)Hive远程服务启动#hive --service hiveserver >/dev/null 2>/dev/null &
(2)JAVA客户端相关代码
Class.forName("org.apache.hadoop.hive.jdbc.HiveDriver");
Connection con = DriverManager.getConnection("jdbc:hive://192.168.1.102:10000/wlan_dw", "", "");
Statement stmt = con.createStatement();
String querySQL="SELECT * FROM wlan_dw.dim_m order by flux desc limit 10";
ResultSet res = stmt.executeQuery(querySQL);
while (res.next()) {
System.out.println(res.getString() +"\t" +res.getLong()+"\t" +res.getLong()+"\t" +res.getLong()+"\t" +res.getLong());
}
24:UDF
1、UDF函数可以直接应用于select语句,对查询结构做格式化处理后,再输出内容。
2、编写UDF函数的时候需要注意一下几点:
a)自定义UDF需要继承org.apache.hadoop.hive.ql.UDF。
b)需要实现evaluate函数,evaluate函数支持重载。
3、步骤
a)把程序打包放到目标机器上去;
b)进入hive客户端,添加jar包:hive>add jar /run/jar/udf_test.jar;
c)创建临时函数:hive>CREATE TEMPORARY FUNCTION add_example AS 'hive.udf.Add';
d)查询HQL语句:
SELECT add_example(8, 9) FROM scores;
SELECT add_example(scores.math, scores.art) FROM scores;
SELECT add_example(6, 7, 8, 6.8) FROM scores;
e)销毁临时函数:hive> DROP TEMPORARY FUNCTION add_example;
注:UDF只能实现一进一出的操作,如果需要实现多进一出,则需要实现UDAF
一脸懵逼学习Hive(数据仓库基础构架)的更多相关文章
- 一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual Hive的数据存储 1.Hiv ...
- 一脸懵逼学习Hive的元数据库Mysql方式安装配置
1:要想学习Hive必须将Hadoop启动起来,因为Hive本身没有自己的数据管理功能,全是依赖外部系统,包括分析也是依赖MapReduce: 2:七个节点跑HA集群模式的: 第一步:必须先将Zook ...
- 一脸懵逼学习Hive的安装(将sql语句翻译成MapReduce程序的一个工具)
Hive只在一个节点上安装即可: 1.上传tar包:这个上传就不贴图了,贴一下上传后的,看一下虚拟机吧: 2.解压操作: [root@slaver3 hadoop]# tar -zxvf hive-0 ...
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置(三台机器跑集群)
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- 一脸懵逼学习Storm---(一个开源的分布式实时计算系统)
Storm的官方网址:http://storm.apache.org/index.html 1:什么是Storm? Storm是一个开源的分布式实时计算系统,可以简单.可靠的处理大量的数据流.被称作“ ...
- 一脸懵逼学习HBase---基于HDFS实现的。(Hadoop的数据库,分布式的,大数据量的,随机的,实时的,非关系型数据库)
1:HBase官网网址:http://hbase.apache.org/ 2:HBase表结构:建表时,不需要指定表中的字段,只需要指定若干个列族,插入数据时,列族中可以存储任意多个列(即KEY-VA ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
随机推荐
- 8种Nosql数据库系统对比(转)
导读:Kristóf Kovács 是一位软件架构师和咨询顾问,他最近发布了一片对比各种类型NoSQL数据库的文章. 虽然SQL数据库是非常有用的工具,但经历了15年的一支独秀之后垄断即将被打破.这只 ...
- mysql数据库基于linux的安装步骤及数据库操作
一.数据库安装 Ubuntu上安装MySQL非常简单只需要几条命令就可以完成. sudo apt-get install mysql-server sudo apt-get isntall mysql ...
- Unity-Rigidbody碰撞穿透
首先,说说碰撞的条件:1.rigidbody(刚体),一般用在主动移动的物体上,比如角色.2.collider,碰撞器,一般用于受力物体上,比如障碍块. 发生概率即触发方式: 1.刚体速度足够快,被撞 ...
- 032_nginx配置文件安全下载
一. server { listen 8866; server_name _; access_log /usr/local/etc/nginx/log/download.access.log main ...
- OTP
OTP 是 One Time Programable, 一次性可编程,一种存储器类型.顾名思义,只允许一次编程,后面无法修改. 在嵌入式系统当中,所有的代码和系统数据都是存储在flash芯片内部的,f ...
- ubuntu Qt linuxdeployqt打包
1.下载PatchELF 0.9.,https://nixos.org/patchelf.html 安装:./configure make sudo make install 2.终端命令设置设置环境 ...
- ES--03
第二十一讲! 1.上机动手实战演练基于_version进行乐观锁并发控制 (1)先构造一条数据出来 PUT /test_index/test_type/7{ "test_field" ...
- linux杀死僵尸进程
用下面的命令找出僵死进程 ps -A -o stat,ppid,pid,cmd | grep -e '^[Zz]' 命令注解: -A 参数列出所有进程 -o 自定义输出字段 我们设定显示字段为 sta ...
- CentOS7.5从零安装Python3.6.6
ps:环境如标题 安装可能需要的依赖 yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlit ...
- JSP的内置对象及方法
request表示HttpServletRequest 对象.它包含了有关浏览器请求的信息,并且提供了几个用于获取cookie,header, 和session 数据的有用的方法.response 表 ...