SQL Server INSET/UPDATE/DELETE的执行计划
DML操作符包括增删改查等操作方式。
- insert into Person.Address
- (AddressLine1,
- AddressLine2,
- City,
- StateProvinceID,
- PostalCode,
- rowguid,
- ModifiedDate)
- values(
- N'1313 Mockingbird Lane',
- N'Basement',
- N'Springfield',
- 79,
- N'02134',
- NEWID(),
- GETDATE()
- )

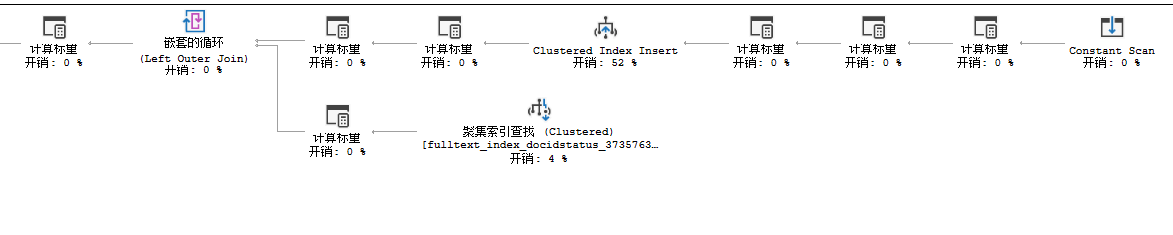
如此简单的INSERT语句,执行计划比前面的SELECT语句还要复杂,表中有自增列、外键约束和空间数据列。
出现新的操作符:常量扫描(Constant Scan),这个操作符会引入一个常量到查询中,由它创建了一列空行以便后面两个操作符有位置可以添加他们的输出。
这两个操作符一个是标量计算(Compute Scalar),调用getidentity函数,用于产生自增值和标量数据,当INSET失败时,可以通过这个值获取失败信息;另一个操作是标量(Scalar)操作,它会产生一个序列用于新的uniqueidentifier值(因为表中有NEWID()函数),同时会产生GETDATE()函数所需要的日期和时间,接下来就是聚集索引插入操作了,这个执行计划中最大开销的部分,然后进入Nested Loops中,由于有外键,所以需要额外关联一个表StateProvince获取与之关联的外键StateProvinceID,经过关联后产生一个新的表达式,用于被下一个操作符Assert检测,这个Assert操作是否存在特定的条件,如果限制条件不存在,就把符合条件的数据插入到Person.Address.StateProvinceID列,然后结束INSET操作。
2.UPDATE
- update Person.Address set City='Munro',ModifiedDate=GETDATE()
- where City='Monroe'

最右边是一个非聚集索引扫描,并不是什么高效的操作。
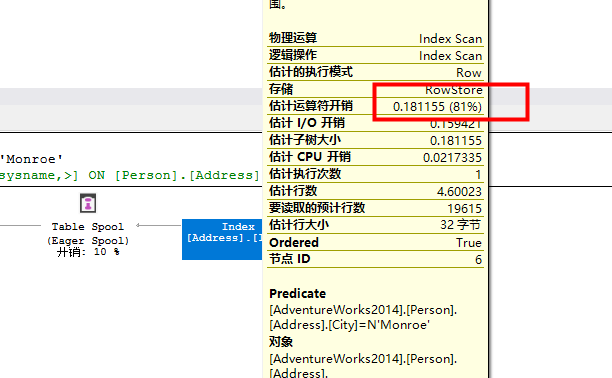
可以进行索引策略来提高性能。让优化器能快速定位City=‘Monroe’的那些数据。查出数据后,进入Top操作符。在Update语句中,TOP操作强制控制行数,但在本例中没有控制,因为UPDATE语句中没有用到Top条件。接下来是表假脱机(Talbe Spool)这个操作会把需要UPDATE的数据移到TempDB的隐藏临时对象中,这个操作有利于回滚操作。
然后进入一系列的标量计算操作符中。在这里主要用于评估表达式和计算表,比如GETDATE()函数生成的值。
最终进入UPDATE语句的核心步骤:聚集索引更新。由于表上有聚集索引,而聚集索引实际包含整个表,所以UPDATE操作会引起聚集索引的更新,最后一个就是标识UPDATE操作完成的操作符。
本例提升性能最重要的方式就是降低开销最大的非聚集索引扫描操作消耗的开销,可以通过调整列上的索引来提升。
3.DELETE
- begin tran
- delete from Person.EmailAddress where BusinessEntityID=42
- rollback tran

由于没有聚集索引,因此只需要把聚集索引的键删除即可。
二:复杂查询
包含存储过程、临时表、表变量、MERGE语句等的执行计划。
1.存储过程
- create procedure Sales.spTaxRateByState
- @CountryRegionCode nvarchar(3)
- as
- set nocount on;
- select st.SalesTaxRateID,
- st.Name,
- st.TaxRate,
- st.TaxType,
- sp.Name as StateName
- from Sales.SalesTaxRate st
- join Person.StateProvince sp on st.StateProvinceID =sp.StateProvinceID
- where sp.CountryRegionCode =@CountryRegionCode
- order by StateName
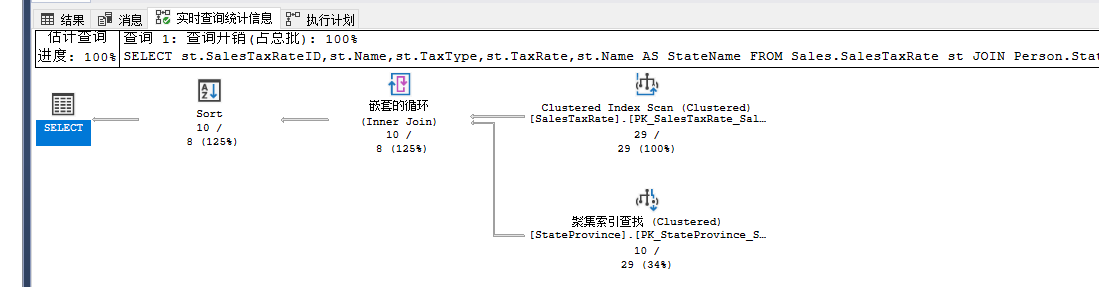
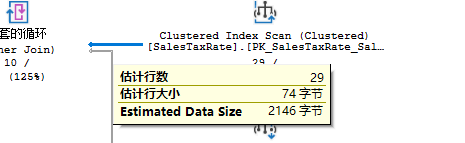
从右到左分析,第一个操作符是聚集索引扫描,用于获取Tax Rate的数据,这个可以从tooltips上查看。接下来通过参数查找Person.StateProvince上的表符号[sp].CountryRegionCode=@CountryRegionCode条件的,也就是调用过程中实际传入的数据sp.CountryRegionCode='US',可以看出由于表Person.StateProvince上有筛选条件,所以出现了聚集索引查找,而表SalesTaxRate上没有筛选条件,所以只能进行聚集索引扫描
然后以StateProvince表为inner set,SalesTaxRate为outer set进行Nested Loops关联,由于两表的数据量较少,选择了Nested Loops关联更为高效。
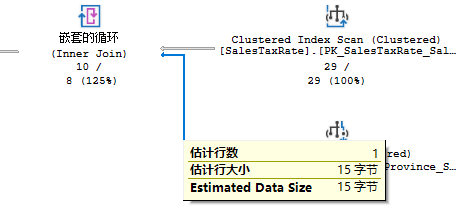
关联之后就是排序操作,排序是由于StateProvince.Name导致的,代码中的Order By使用的是别名,而真正的排序是基于基础表的。这个表的聚集索引在StateProvinceID,所以当使用Name排序时,优化器会引入一个Sort操作符,开销很大。达到了51%,要优化,要在Sort上做文章,比如调整聚集索引,检查是否有必要排序等。

2.子查询
- select p.Name,p.ProductNumber,ph.ListPrice
- from Production.Product p
- inner join Production.ProductListPriceHistory ph on
- p.ProductID=ph.ProductID
- where ph.StartDate=(
- select top(1) ph2.StartDate
- from Production.ProductListPriceHistory ph2
- where ph2.ProductID=p.ProductID
- order by ph2.StartDate desc
- );
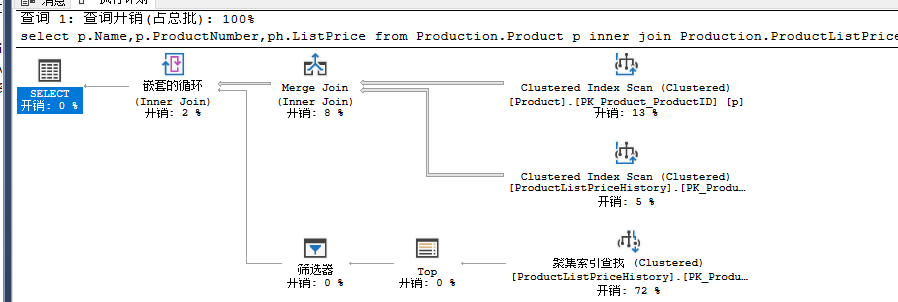
两个表Product和ProductListPriceHistory都进行了Merge Join,他们均有聚集索引,并且数据量相对前面来说比较大,所以优化器决定使用合并关联算法。然后对子查询进行Nested Loops关联,因为只需要取每个结果集的最近日期的数据,所以数据量相对较小,

本例中出现了非多对多的Merge join,从tooltips中的框线中看出,如果出现多对多的情况,优化器会创建一个Worktable的空间,这个空间位于TempDB,会导致额外的开销。

从filter操作符中可以看出,实现了对TOP 1 的处理,这个操作把两个数据集相等的数据进行对比,然后只取时间最大的那个。这个例子中最主要的地方就是进行了只查询的部分。在执行计划中这部分的操作演变成一个筛选操作,把符合where条件的数据返回。
3.使用APPLY的派生表
我们可以在SELECT过程中对创建的虚拟表进行数据操作,这种虚拟表叫作派生表。可以使用APPLY操作符来产生派生表,有CROSS APPLY和OUTER APPLY两种。
- select p.Name,p.ProductNumber,ph.ListPrice from Production.Product p
- cross apply (select TOP(1) ph2.ProductID,ph2.ListPrice from Production.ProductListPriceHistory ph2
- where ph2.ProductID=p.ProductID order by ph2.StartDate desc) ph;

通过APPLY,先对派生表中每行进行WHERE条件及其他条件的应用,产生的结果集和Product表进行聚集索引扫面后,得到的数据进行Nested Loops 关联,最后返回结果。
通过查看I/O情况,子查询开销更低。
如果加入where 条件 where p.ProductID='839'
当加入WHERE条件之后,派生表的数据集迅速降低,在JOIN的过程中更加快速和高效。
4.通用表表达式
它是SQL语句中的一个临时结果集
- ALTER PROCEDURE [dbo].[uspGetManagerEmployees]
- @BusinessEntityID [int]
- AS
- BEGIN
- SET NOCOUNT ON;
- WITH [EMP_cte] ( [BusinessEntityID], [OrganizationNode], [FirstName], [LastName], [RecursionLevel] )
- -- CTE name and columns
- AS ( SELECT e.[BusinessEntityID] ,
- e.[OrganizationNode] ,
- p.[FirstName] ,
- p.[LastName] ,
- 0 -- Get the initial list of Employees
- -- for Manager n
- FROM [HumanResources].[Employee] e
- INNER JOIN [Person].[Person] p ON p.[BusinessEntityID] = e.[BusinessEntityID]
- WHERE e.[BusinessEntityID] = @BusinessEntityID
- UNION ALL
- SELECT e.[BusinessEntityID] ,
- e.[OrganizationNode] ,
- p.[FirstName] ,
- p.[LastName] ,
- [RecursionLevel] + 1 -- Join recursive
- -- member to anchor
- FROM [HumanResources].[Employee] e
- INNER JOIN [EMP_cte] ON e.[OrganizationNode].GetAncestor(1) = [EMP_cte].[OrganizationNode]
- --GetAncestor 返回表示this的第n个祖先的 hierarchyid。
- INNER JOIN [Person].[Person] p ON p.[BusinessEntityID] = e.[BusinessEntityID]
- )
- SELECT [EMP_cte].[RecursionLevel] ,
- [EMP_cte].[OrganizationNode].ToString() AS [OrganizationNode] ,
- p.[FirstName] AS 'ManagerFirstName' ,
- p.[LastName] AS 'ManagerLastName' ,
- [EMP_cte].[BusinessEntityID] ,
- [EMP_cte].[FirstName] ,
- [EMP_cte].[LastName] -- Outer select from the CTE
- FROM [EMP_cte]
- INNER JOIN [HumanResources].[Employee] e ON [EMP_cte].[OrganizationNode].GetAncestor(1) = e.[OrganizationNode]
- INNER JOIN [Person].[Person] p ON p.[BusinessEntityID] = e.[BusinessEntityID]
- ORDER BY [RecursionLevel] ,
- [EMP_cte].[OrganizationNode].ToString()
- OPTION ( MAXRECURSION 25 ) --指定应在整个查询中使用所指定的查询提示
- END;
XML格式的执行计划
- set statistics xml ON;
- exec dbo.uspGetEmployeeManagers @businessEntityID=9;
- set statistics xml off
单击XML链接就可以看到图形化执行计划。

最右的执行计划:(从右到左)

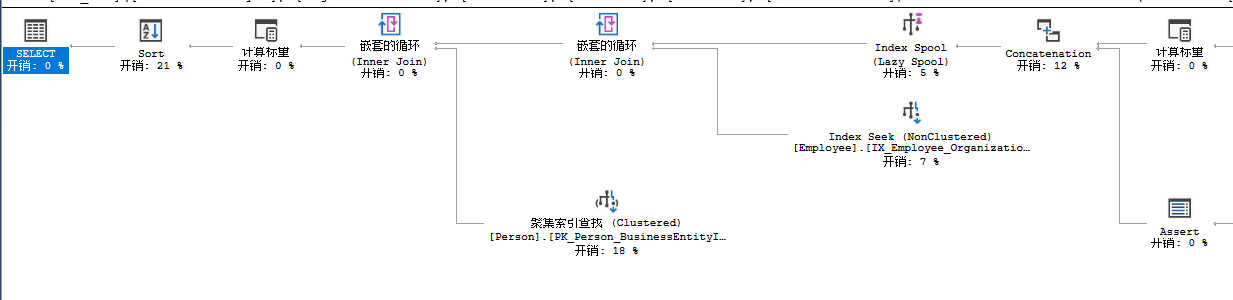
进行一联串的Inner Join Join 嵌套的循环之后,进入Concatenation操作,这个操作是针对代码中的UNION ALL 的,会把数据合成一个数据集。
执行计划中的假表脱机(Table Spool 操作符)。这个操作符可以让数据集被多次循环,而不需要在每次需要时都临时创建了。另外这个和索引假脱机类似,他们都是把数据存放在TempDb的隐藏临时表中,其实就是对CTE的UNION ALL操作进行重绕(可以理解为递归操作)
在Concatenation之后,就是索引假脱机(Index Spool)这个操作会把数据汇总到TempDb中一个叫Worktable的地方,然后与查询中返回的地方就行索引关联,以便实现递归操作。

5.视图
视图的本质就是一个查询,有两种视图:标准视图和索引视图
(1)标准视图
- select * from Sales.vIndividualCustomer where BusinessEntityID=8743
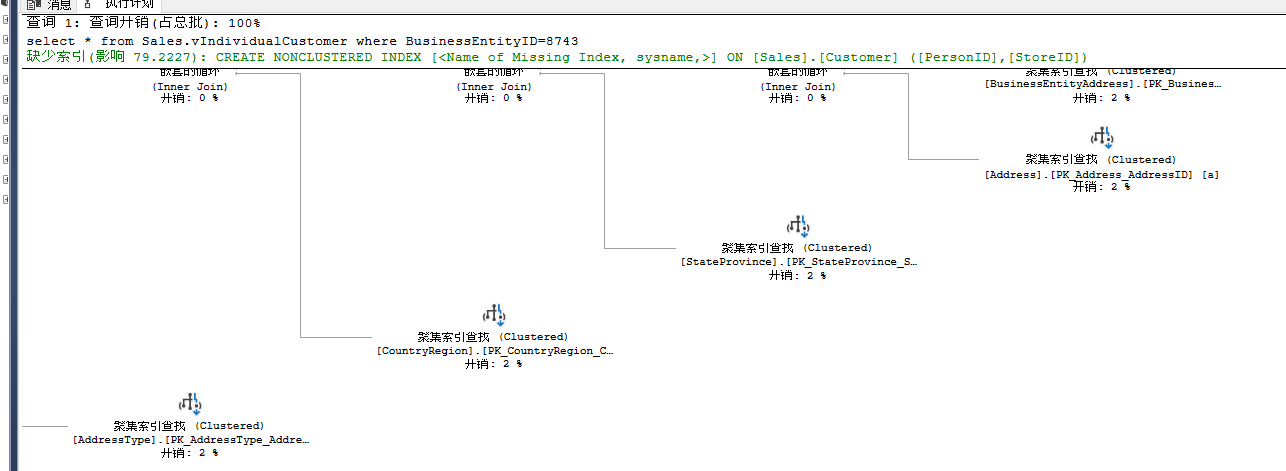


在标准视图中,SQL Server会认为这个视图仅仅是一个名称,优化器会忽略视图这个对象,取而代之的是直接处理底层表。
(2)索引视图
这类视图也叫物化视图,本质上就是视图加一个聚集索引,这种视图实际上等价于在数据库中创建了一个物理表,很多时候,索引视图能极大的提高性能,创建索引视图也是一个开销比较大的操作,只不过只需要创建一次。
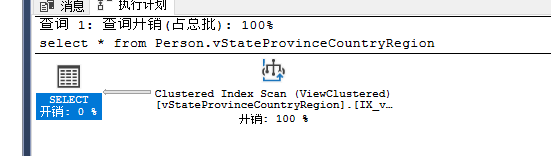
- select * from Person.vStateProvinceCountryRegion
没有where 条件,进行的是聚集索引扫描
SQL Server INSET/UPDATE/DELETE的执行计划的更多相关文章
- SQL Server 性能调优 之执行计划(Execution Plan)调优
SQL Server 存在三种 Join 策略:Hash Join,Merge Join,Nested Loop Join. Hash Join:用来处理没有排过序/没有索引的数据,它在内存中把 Jo ...
- SQL Server如何查看存储过程的执行计划
有时候,我们需要查看存储过程的执行计划,那么我们有什么方式获取存储过程的历史执行计划或当前的执行计划呢? 下面总结一下获取存储过程的执行计划的方法. 1:我们可以通过下面脚本查看存储过程的执行计划,但 ...
- SQL Server中UPDATE和DELETE语句结合INNER/LEFT/RIGHT/FULL JOIN的用法
在SQL Server中,UPDATE和DELETE语句是可以结合INNER/LEFT/RIGHT/FULL JOIN来使用的. 我们首先在数据库中新建两张表: [T_A] CREATE TABLE ...
- Sql Server 带参数的存储过程执行方法
Sql Server 带参数的存储过程执行方法 Visual C# 动态操作 SQL Server 数据库实例教程(4):带参数的存储过程执行方法 上一篇文章介绍了带参数的SQL语句执行方法和不带参数 ...
- ECSHOP后台SQL查询提示错误 this sql May contain UPDATE,DELETE,TRUNCATE,ALTER,DROP,FLUSH,INSERT
一).首先说一下错误现象:市面上流行的绝大部分ECSHOP模板,安装的时候都需要执行一段或几段SQL语句来修改数据结构或者初始化一些数据.大多数ECSHOP管理员为了省事,都会通过 “ECSHOP后台 ...
- SQL点滴27—性能分析之执行计划
原文:SQL点滴27-性能分析之执行计划 一直想找一些关于SQL语句性能调试的权威参考,但是有参考未必就能够做好调试的工作.我深信实践中得到的经验是最珍贵的,书本知识只是一个引导.本篇来源于<I ...
- 浅析SqlServer简单参数化模式下对sql语句自动参数化处理以及执行计划重用
我们知道,SqlServer执行sql语句的时候,有一步是对sql进行编译以生成执行计划, 在生成执行计划之前会去缓存中查找执行计划 如果执行计划缓存中有对应的执行计划缓存,那么SqlServer就会 ...
- SQL SERVER的update select语句的写法
需求: 要根据表A的数据来更新表B的某些字段,A和B要进行条件关联. 常规做法可能写个子查询 简单写法是用SQL Server的update select语法 update T_STOCK_INFO ...
- 利用SQL Server 2008 R2创建自动备份计划
本文主要利用SQL Server 2008 R2自带的"维护计划"创建一个自动备份数据的任务. 首先,启动 Sql Management studio,确保"SQL Se ...
随机推荐
- 20165231 2017-2018-2《Java程序设计》课程总结
每周作业链接汇总 预备作业一:我期待的师生关系 预备作业二:学习基础和C语言基础调查 预备作业三:linux安装及学习 第一周作业:初识JAVA,注册码云并配置Git 第二周作业:JAVA基本语法,标 ...
- HDOJ 3308 LCIS (线段树)
题目: Problem Description Given n integers.You have two operations:U A B: replace the Ath number by B. ...
- WindowsPE权威指南-PE文件头中的重定位表
PE加载的过程 任何一个EXE程序会被分配4GB的内存空间,用户层处理低2G的内存,驱动处理高2G的内存. 1.双击EXE程序,操作系统开辟一个4GB的空间. 2.从ImageBase决定了加载后的基 ...
- 3.2. 使用 CPUFREQ 调节器【转】
转自:https://access.redhat.com/documentation/zh-cn/red_hat_enterprise_linux/6/html/power_management_gu ...
- keepalived的vip无法ping通【原创】
今天收到redis的keepalived vip无法ping通的告警,查看服务器和服务时发现vip在服务器上,服务也正常.只能在本机ping通,跨网段无法ping通.切换keepalived vip至 ...
- linux dynamic lib
// test1.h ; struct AA { int a,b: }; AA b(5,6); int ball(); // test1.cpp # include"test1.h" ...
- python学习第16天。
内置函数是在原本已经有的序列的基础上,再生成新的. List的方是修改原列表. 内置函数中大部分函数的返回值大部分都是迭代器.生成器. Sorted需要遍历操作,不是单纯的迭代,所以不生成迭代器. 一 ...
- bootstrap Autocomplete
首先应用文件(已上传到文件,需要可自行下载) <link href="~/bower_components/select2/dist/css/select2.css" rel ...
- 深入理解ajax
http://www.imooc.com/code/13468 基础练习 http://www.imooc.com/video/5644 !ajax! 常用 for ...
- PID控制器开发笔记之十一:专家PID控制器的实现
前面我们讨论了经典的数字PID控制算法及其常见的改进与补偿算法,基本已经覆盖了无模型和简单模型PID控制经典算法的大部.再接下来的我们将讨论智能PID控制,智能PID控制不同于常规意义下的智能控制,是 ...