Python之列表
一、列表的特点
- 列表也是一种数据类型
- 列表元素是有序的,有编号的
- 列表元素的下标从0开始
- 列表中的每一个值叫一个元素,编号叫下标(索引/角标):
stu_name=['崔海龙','杨帆','lrx',1,1.5]
这里,崔海龙是一个元素,它的索引是0。
二、列表操作
1、增删改查操作
#增:
使用.append()方法:
stu_name.append('杨月') #list的末尾追加元素
使用.insert()方法:
stu_name.insert(2,'小军')#在指定位置之前添加元素,要指定元素下标
- 区别:
.append()是只能追加到list末尾,而.insert()可以指定角标位置。
- 重复执行一条语句多次,会不会添加多个相同的值?
# #由于写代码都是在内存中运行的,一旦执行完毕就会释放变量,因此重复执行多次都只插入一个变量值,不会重复插入同样的值。
# # 列表定义的变量是在内存中执行的,一旦关闭程序就会丢失,而文件则是在磁盘中保存的,关闭程序不会丢失数据。
- 重复添加多次,会不会添加多个相同的值?
会。一条语句就是添加一个值:
stu_name.insert(2,'小军')
stu_name.insert(2,'小军')
#结果为[x,x,'小军','小军',x]
#改:
直接赋新值,覆盖原值:
stu_name[5]='孔垂顶'
#删:
- 使用.pop()方法:
.pop()方法默认删的是最后一个元素。
stu_name.pop()#删除最后一个元素
stu_name.pop(4)#删除指定下标的元素
- 使用.remove()方法:
stu_name.remove('小军')#删除指定的元素,如果有一样的元素,只会删掉第一个
- 使用del方式:
del stu_name[-1]#下标从右往左数,-1代表最后一个,-2代表倒数第二个
区别:
- .pop()里面是元素的下标,而.remove()里面是元素。
- .pop()里面如果写的是不存在的下标,则运行会报错。
- 如果存在多个相同的元素,.remove()只会删除第一个。
- 如果想删除多个元素,就需要用到列表循环了。
下标:
- 下标从右往左数,-1代表最后一个,-2代表倒数第二个;
下标从左往右数,0代表第一个,1代表第2个。
#查:
- 指定下标查:
my_list=['小黑','小白',1,1,2,1.5]
print(my_list[-1])
print(my_list[0])
- 使用.index()方法查询指定元素的下标:
print('index方法:',my_list.index(3))#查找下标的元素
使用.index()方法,如果输入不存在的下标,则执行会报错。
- 使用.count()方法查询某个元素在list里出现的次数:
print(my_list.count(5))#查询某个元素在list里面出现的次数
.count()的应用场景:可以用于校验用户名
.count()里面是元素,而不是下标!
2、反转
使用.reverse()方法:
print('reverse:',my_list.reverse())#结果是None
print(my_list)#.reverse()本身不会给出结果,需要打印列表
.reverse()本身不会给出结果,没有返回值,需要打印列表
3、清空列表
使用.clear()方法:
my_list.clear()#清空整个list
4、排序
- 使用.sort()方法,默认为升序排序:
nums.sort()#排序,默认升序
- 使用.sort()方法,指定reverse=True,则降序排列:
nums.sort(reverse=True)#排序,如果指定了reverse=True,那么就降序排列了
- 使用.reverse()方法,降序排序:
nums.reverse()
5、将其他列表里的元素加入到本列表中
使用.extend()方法:
nums.extend(my_list)#把一个list里面的元素加入到nums列表里面
6、合并列表
使用“+”进行列表合并:
new_list=nums+my_list
## extend和+的区别:extend是将my_list的内容加入到nums里;而+是nums和my_list内容不变,重新建立一个新的list。
7、复制列表
使用“*”进行列表复制:
print(new_list*3) #复制3个new_list
8、取列表长度,也就是list里面元素的个数
使用len()方法:
passwords =['','','','password']
print(len(passwords)) #取长度,也就是list里面元素的个数
三、列表应用
#校验手机号是否存在,使用.count()或 in not in都可以
users =[]
for i in range(5):
username=input('请输入用户名:')
#如果用户不存在的话,就说明可以注册
# if users.count(username)>0:
#关键字in not in--------------------------------------------
if username not in users:
print('用户未注册,可以注册')
users.append(username)
else:
print('用户已经被注册')
四、数组
nums1=[1,2,3] #一维数组
nums2=[1,2,3,[4,56]] #二维数组
nums=[1,2,3,4,['a','b','c','d','e',['一','二','三']],['四','五']] #三维数组
nums4=[1,2,3,4,['a','b','c','d','e',['一','二','三',[1,2,3]]]]#四维数组
- 多维数组取值:
三维数组取“五”:print(nums[-1][-1])
四维数组取“2”:print(nums4[-1][-1][-1][1])
五、列表循环
原理
#循环list取值
count=0 #最原始的list取值方式,是通过每次计算下标来获取元素的
while count<len(passwords):
s=passwords[count]
print('每次循环的时候',s)
count+=1
利用元素下标进行循环
index = 0
for p in passwords:#for循环直接循环一个list,那么循环的时候就是每次计算下标获取元素
print('每次循环的值'+p)
passwords[index]='abc_'+p
index+=1
print(passwords)
Python中的列表循环内置了列表下标,因此只用一个变量p就可以,p就是每次取下标时对应的元素值。
使用enumerate()枚举函数
使用enumerate()函数,会自动将list的下标和元素都显示出来:
for index,p in enumerate(passwords):#使用枚举函数时,它会帮你计算下标和元素
passwords[index]='abc_'+p
print('enumerate每次循环的时候',index,p)
print(passwords)
列表循环删除元素
循环删list元素的时候,会导致下标错位:
1、现象:
l=[1,1,1,2,3,4,5]
#1,1,2,3,4,5
#0 1 2 3 4 5 6
for i in l:
if i%2!=0:
l.remove(i) #.remove()里面是元素;.pop()里面是下标
print(l) #结果为[1,2,4]
#循环删list元素的时候,会导致下标错位
2、解决方法:
l1=[1,1,1,2,3,4,5]
#1,1,2,3,4,5
#0 1 2 3 4 5 6
l2=[1,1,1,2,3,4,5]
for i in l2: #使用l2中的元素判断,删除l1里的元素,由于l1没有参与判断,因此下标不会错位
if i%2!=0:
l1.remove(i)
print(l) #结果为[2,4]
循环删除列表元素时,要定义两个相同的列表,一个判断,另一个删除。
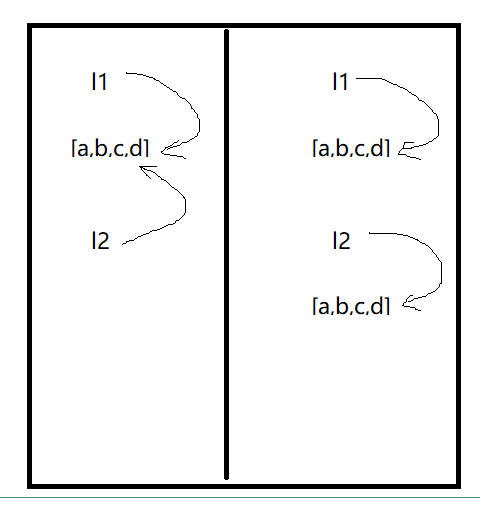
- 存址方式:
列表中:
1、现象:
l1=[1,1,1,2,3,4,5]
#1,1,2,3,4,5
#0 1 2 3 4 5 6
l2=l1
for i in l2:
if i%2!=0:
l1.remove(i)
print(l1) #结果为[1,2,4]
#l1和l2其实指向的是同一块内存地址,因此删除l1的元素时,l2也会跟着变
2、原因:
字符串中:
1、现象:
a='tanailing'
b=a
a='niuniu'
print(b)#结果为tanailing
print(a)#结果为niuniu
2、原因:
- 字符串是直接开辟新的内存空间,不会共用一块内存空间,因此修改了a的内容后,b不会变。
六、深拷贝与浅拷贝
1、现象:
l1=[1,1,1,2,3,4,5]
#1,1,2,3,4,5
#0 1 2 3 4 5 6
l2=l1 #浅拷贝
for i in l2:
if i%2!=0:
l1.remove(i)
print(l1) #打印内存地址
print(id(l1)) #结果为:1986281423432
print(id(l2)) #结果为:1986281423432
2、用法:
import copy #引入copy模块
l1=[1,1,1,2,3,4,5]
#1,1,2,3,4,5
#0 1 2 3 4 5 6
l2=l1 #浅拷贝方式1
l4=l1.copy() #浅拷贝方式2 l3=copy.deepcopy() #深拷贝 #打印内存地址
print(id(l1)) #结果:2629934030152
print(id(l2)) #结果:2629934030152
print(id(l3)) #结果:2629934028872
3、区别:
- 浅拷贝内存地址不变,深拷贝内存地址改变。
- 循环删除列表元素时,使用深拷贝方式。
七、切片
1、range()生成器
就是list取值的一种方式。
- 生成器range(),用于写列表的范围,如果只写一个数,就表示从0开始,到写入的值-1:
l=list(range(10))#生成的是[0,1,2,3,4,5,6,7,8,9]
- 如果写入范围,则是从写入的第一个数值开始,从写入的第二个数-1结束:
l=list(range(1,11))
l=['a','b','c','d','e','j','k','l','m','n','o']
# 0 1 2 3 4 5 6 7 8 9 10
print(l[2:8])#顾头不顾尾
print(l[:5])#如果冒号前面没写的话,代表从0开始取的
print(l[4:])#如果冒号后面没写的话,代表取到最后
print(l[:])#如果冒号前后都没写的话,代表取全部
切片操作的特点:
- 顾头不顾尾
- 使用range()生成器时,如果冒号前面没写的话,代表从0开始取元素
- 使用range()生成器时,如果冒号后面没写的话,代表取到最后的元素
- 如果冒号前后都没写的话,代表取全部
2、 步长
步长是从自己元素开始,再走几步到想要的元素:
nums=list(range(1,11))
print(nums[1::2])#打印偶数
#1 2 3 4 5 6 ...10
print(nums[::2])#打印奇数
print(nums[::-2]) #取偶数,从右往左取值
步长特点:
- 如果步长是正数的话,就从前往后开始取值;
- 如果步长是负数的话,就从后往前开始取值,类似于reverse()。
Python之列表的更多相关文章
- Python list列表的排序
当我们从数据库中获取一写数据后,一般对于列表的排序是经常会遇到的问题,今天总结一下python对于列表list排序的常用方法: 第一种:内建函数sort() 这个应该是我们使用最多的也是最简单的排序函 ...
- python中列表和元组以及字符串的操作
python中列表是非常好用的.不过有一些使用小细节还需要注意一下. tag[32:-4] 从index为32到tag的倒数第4个字符. 如果索引为32的值在倒数第4个字符的右边,那么将输出为空.只要 ...
- python基础——列表生成式
python基础——列表生成式 列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式. 举个例子,要生成list [1, 2, 3, 4 ...
- Python的列表排序
Python的列表排序 本文为转载,源地址为:http://blog.csdn.net/horin153/article/details/7076321 在 Python 中, 当需要对一个 list ...
- python中列表 元组 字典 集合的区别
列表 元组 字典 集合的区别是python面试中最常见的一个问题.这个问题虽然很基础,但确实能反映出面试者的基础水平. (1)列表 什么是列表呢?我觉得列表就是我们日常生活中经常见到的清单.比如,统计 ...
- python对列表的联想
python的列表与字典,已经接触无数次了.但是很多用法都记不住,个人觉得归根原因都是只是学了知识点而少用,也少思考.在此试图用宫殿记忆法对它们的用法做个简单的梳理. 首先,说说列表的删除,删除有三种 ...
- Python统计列表中的重复项出现的次数的方法
本文实例展示了Python统计列表中的重复项出现的次数的方法,是一个很实用的功能,适合Python初学者学习借鉴.具体方法如下:对一个列表,比如[1,2,2,2,2,3,3,3,4,4,4,4],现在 ...
- python之列表(list)的使用方法介绍
python之列表(list)介绍 在python的使用过程中,我们经常会用到列表,然而经常会遇到疑惑,下面我将详细介绍下列表使用方法. 一.列表 列表经常用到的功能使增.删.改和查功能. 1. 增 ...
- Python的列表
1. Python的列表简介 1. 1 列表的定义 列表是Python中最基本的数据结构,列表是最常用的Python数据类型,列表的数据项不需要具有相同的类型.列表中的每个元素都分配一个数字 ,即它的 ...
- python基础——列表推导式
python基础--列表推导式 1 列表推导式定义 列表推导式能非常简洁的构造一个新列表:只用一条简洁的表达式即可对得到的元素进行转换变形 2 列表推导式语法 基本格式如下: [expr for va ...
随机推荐
- 【PAT】B1012 数字分类
注意逻辑的描述,只要认真看题,就能做对,如果自己结果一直不正确,请仔细推一下样例结果 #include<stdio.h> int arr[1005]; int main(){ int N, ...
- jquery.qrcode.js 生成二维码并支持中文的方法
GitHub地址: https://github.com/jeromeetienne/jquery-qrcode <div class="QR"></div> ...
- IntelliJ IDEA 创建Spring+SpringMVC+mybatis+maven项目
参考自:https://www.cnblogs.com/hackyo/p/6646051.html 第一步: 创建maven项目 输入项目名和工程id 选择maven 默认就可以了 刚开始时间比较长, ...
- 聚类——KFCM的matlab程序
聚类——KFCM的matlab程序 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 在聚类——KFCM文章中已介绍了KFCM-F算法的理论知识,现在用m ...
- Spring的jdbc模板2:使用开源的连接池
上篇简要介绍了如何在spring中配置默认的连接池和jdbc模板,这篇来介绍开源的连接池配置与属性引入 C3P0连接池配置: 引入jar包 配置c3p0连接池 <?xml version=&qu ...
- Java监听器Listener使用详解
监听器用于监听web应用中某些对象.信息的创建.销毁.增加,修改,删除等动作的发生,然后作出相应的响应处理.当范围对象的状态发生变化的时候,服务器自动调用监听器对象中的方法.常用于统计在线人数和在线用 ...
- 机器学习算法总结(三)——集成学习(Adaboost、RandomForest)
1.集成学习概述 集成学习算法可以说是现在最火爆的机器学习算法,参加过Kaggle比赛的同学应该都领略过集成算法的强大.集成算法本身不是一个单独的机器学习算法,而是通过将基于其他的机器学习算法构建多个 ...
- BZOJ3237:[AHOI2013]连通图(线段树分治,并查集)
Description Input Output Sample Input 4 5 1 2 2 3 3 4 4 1 2 4 3 1 5 2 2 3 2 1 2 Sample Output Connec ...
- Apache 项目列表功能分类便于技术选型
big-data (49): Apache Accumulo Apache Airavata Apache Ambari Apache Apex Apache Avro Apache Be ...
- 第11章 AOF持久化
AOF持久化在硬盘上保存的是对Redis进行的逻辑操作,类似InnoDB中的bin log.说白了就是你对一个Redis输入了哪些语句,AOF文件都会原封不动的保存起来,等到需要回复Redis的时候再 ...