Oja’s rule
Oja's rule
这俩天看了Oja的俩篇论文,被其中的证明弄得云里雾里,但愿我的理解没有出太大问题吧。
Oja's rule Wiki
Oja's rule 知乎
- A Simplified Neuron Model as a Principal Component Analyzer
- On Stochastic Approximation of Eigenvectors and Eigenvalues of the Expectation of a Random Matrix
背景
貌似是关于神经网络,权重的无监督训练的。有趣的是,由这个出发点,可以得到一种关于stream PCA的算法,即Oja's rule。
Hebbian learning
在Hebb的假说中,对于权重的调整为:
\(\bigtriangleup w_i = \eta x_iy\)
where:
\(y = \mathop{\sum}\limits_{j}w_jx_j\)
在stream PCA表述为这样的算法:
\(\widetilde{X}_k = X_{k-1} + A_kX_{k-1}\varGamma_k\)
\(X_k = \widetilde{X}_kR_k^{-1}\)
where:
\(X_k\)就是每一次迭代所得的正交矩阵,\(A_k\)为随机矩阵,在stream PCA里面,一般\(A_k = z_kz_k^{\top} \in \mathbb{R}^{d \times d}\), \(\varGamma_k\)是一个对角矩阵,每个对角元素表示对应列向量的学习率。\(R_k^{-1}\)怎么说呢,\(X_k=QR\)这个\(QR\)分解,\(R_k^{-1}\)就是\(R\)的逆。
当只需要最大特征值所对应的特征向量的时候:
\(\widetilde{x}_k = x_{k-1} + \gamma_kA_kx_{k-1}\)
\(x_k = \widetilde{x}_k/\|\widetilde{x}_k\|\)
这个式子到底啥含义呢,为什么会这样呢?
Oja给出的分析是(大概是这样):
\(x_k\)关于\(\gamma_k\)的泰勒展式(只到一次项)是:
\(x_k = x_{k-1} + \gamma_k[A_kx_{k-1}-(x_{k-1}^{\top}A_kx_{k-1})x_{k-1}] + \gamma_kb_k\)
where:
\(b_k = o(\gamma_k)\)这个地方我有个疑问,不知道是我对论文的理解不对还是如何,我觉得如果\(b_k = o(\gamma_k)\),那么前面就不必再乘上个\(\gamma_k\)了。
还要注意的一点是,上面的推导用到了:\(\|x_{k-1}\|=1\)的条件。
上面的式子还可以有另外一种写法:
\(x_k = x_{k-1} + \gamma_k[Ax_{k-1}-\frac{(x_{k-1}^{\top}Ax_{k-1})}{x_{k-1}^{\top}x_{k-1}}x_{k-1}] +\gamma_k[(A_k-A)x_{k-1}-(x_{k-1}^{\top}(A_k-A)x_{k-1})x_{k-1}] + \gamma_kb_k\)
这个式子只是对上面的加项减项处理,并不难推导。注意,请想象\(E(A_k) = A\)
保留右边前俩项:
\(\bigtriangleup x_k \approx \gamma_k[Ax_{k-1}-\frac{(x_{k-1}^{\top}Ax_{k-1})}{x_{k-1}^{\top}x_{k-1}}x_{k-1}]\)
连续情况下就可以得到形如下面的微分方程:
\(\frac{dz}{dt}=Az-\frac{(z^{\top}Az)}{z^{\top}z}z\)
微分方程的内容我忘得差不多了,这个方程的解法大概是这样的:
\(z := \mathop{\sum}\limits_{i}\eta^{(i)}(t)c_i\)
where:
\(c_i\)是矩阵\(A\)的按特征值由大到小排列的单位特征向量。
这时,上面的微分方程可以分解为\(d\)(论文里纬度是\(n\))个子微分方程:
\(\frac{d\eta^{(i)}}{dt}=\lambda^{(i)}\eta^{(i)}-\frac{(z^{\top}Az)}{z^{\top}z}\eta^{(i)}\)
令:\(\zeta^{(i)}=\eta^{(i)}/\eta^{(1)}\) (\(\eta^{(1)}(t) \neq \mathbf{0}\)),容易推得(是真的不是假的):
\(\frac{d\zeta^{(i)}}{dt}=(\lambda^{(i)} - \lambda^{(1)})\zeta^{(i)}\)
可以推得其解为:
\(\zeta^{(i)}(t)=exp[(\lambda^{(i)} - \lambda^{(1)})t]\zeta^{(i)}(0)\)
从这个式子可以看到,只要\(\eta^{(1)} (t)\neq \mathbf{0}\),那么其他成分,随着时间的增长,会趋于0,所以最后\(z\)会成为\(c_1\)。
上面的算法的内涵就是其线性主部满足这个性质。上面微分方程还有另外一个性质:
\(\|z(0)\|=1\)则\(\|z(t)\|=1,t>0\)(通过求导,导数为0可以验证!)
这也就是说,我们只要保证第一次,后面的大小也可以同样保证。当然,这些条件是在连续情况下推导的,实际在离散的情况下,我们要求\(\gamma_k\)足够小。
主要的一些理论
论文里面一些主要的假设

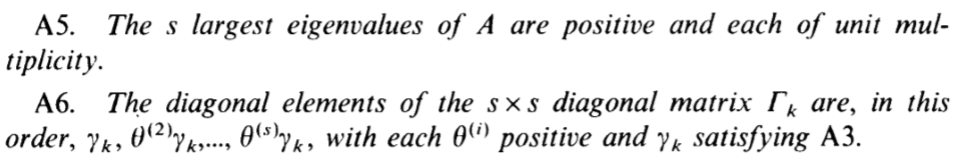
我不怎么理解的地方是这个unit multiplicity,是特征值是唯一的吗(从证明中看似乎是这样的)?
引理1
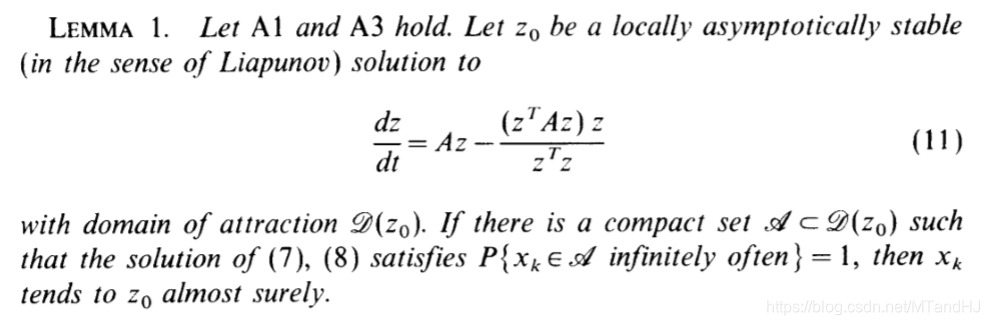
引理2
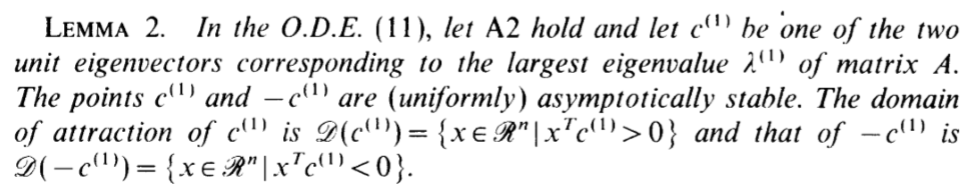
引理3

(7) (8)就是上面的\(x_k\)的迭代算法:
\(\widetilde{x}_k = x_{k-1} + \gamma_kA_kx_{k-1}\)
\(x_k = \widetilde{x}_k/\|\widetilde{x}_k\|\)
定理1
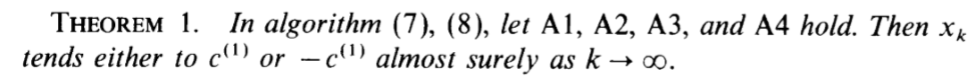
下面Oja开始讨论\(X_k\)的迭代算法:
LEMMA 3(ALL)
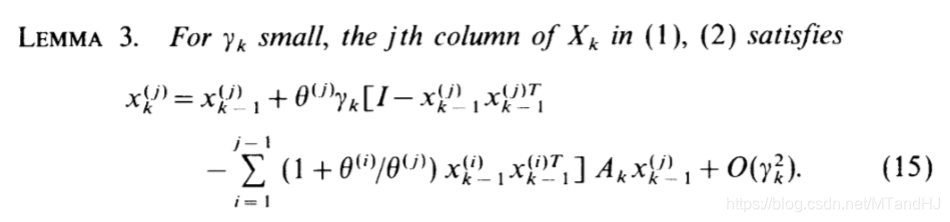
(1)(2)是关于\(X_k\)的迭代算法。
引理 4

定理 2

定理 3(关于特征值)
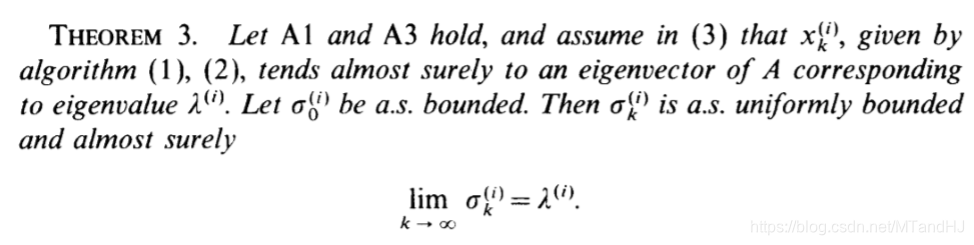
关于\(\sigma\)的迭代算法,即(3):
\(\sigma_k^{(i)}=(1-\gamma_k)\sigma_{k-1}^{(i)}+\gamma_k(x_{k-1}^{(i)}A_kx_{k-1}^{(i)})\)
Oja's rule
Oja's rule 是对 Hebbian learning 的改进:
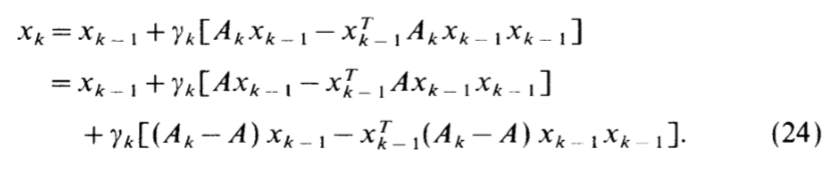
可以发现,其实Oja's rule就是取了前面的线性主部。
相应的微分方程变为:
\(\frac{dz}{dt}=Az-(z^{\top}Az)z\)
性质有所欠缺,但是,在一定条件下依然可以保证一些良性。
引理 5(关于\(\gamma_k\)的选择)

定理 3

注意,当推广到求解\(X_k\)的时候有俩种:
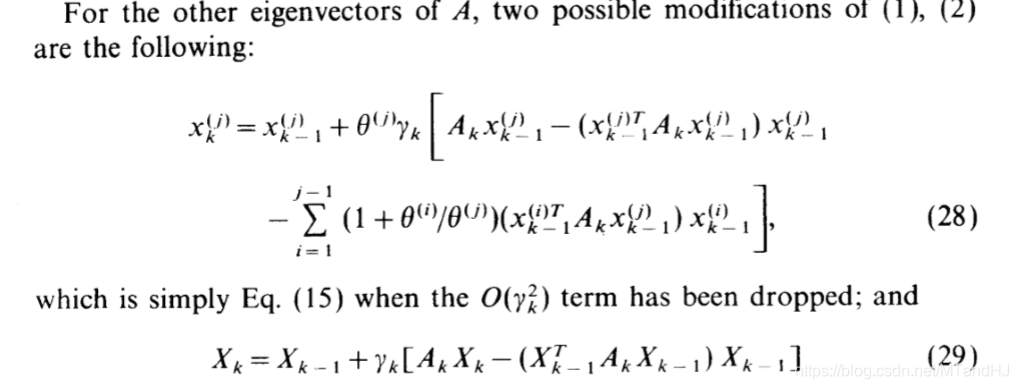
(29)的列不一定是相应的特征向量,但列所构成的子空间是一致的!
数值实验
我们先用均匀分布产生一个基础向量x,再在其上添加由标准正态分布所生成噪声,得到一串向量,来模拟数据。
dfv1: Hebbian方法得到的向量与特征向量的cos值
dfv2: Oja方法得到的向量与特征向量的cos值
dfx1: Hebbian方法得到的向量与x的cos值
dfx2: Oja方法得到的向量与x的cos值
dfAx: x与特征向量的cos值
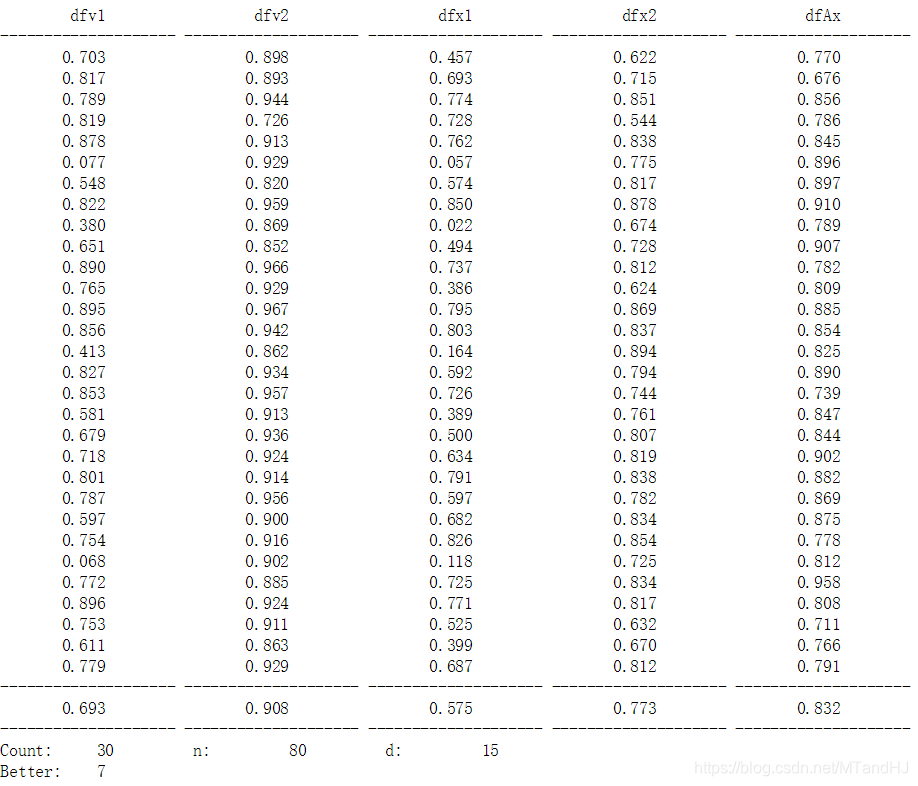
用Oja's rule 大概80次就能到达0.90的水准,与x的差距也不大,有7次比特征向量还要好!而Hebbian learning 大概300次。当然,这可能与我对步长的调整有关系,但是说实话,我已经尽力了。

代码
import numpy as np
def Oja_rule_1(x_old, z, r): #实际上好像不是Oja's 修正Hebbian learning
x = x_old + r * np.dot(x_old, z.T.dot(z))
x = x / np.sqrt(x @ x)
return x
def Oja_rule_2(x_old, z, r):
x = x_old + r * (x_old @ (z.T @ z) - x_old @ (z.T @ z) @ x_old * x_old)
return x
def D2D(x, y): #计算cos值,Oja的论文用的是2范数
return abs(x @ y)
def Main(d, n):
x = np.array([np.random.rand() for i in range(d)])
x = x / np.sqrt(x @ x)
A = np.array([ x + [np.random.randn() for j in range(d)] for i in range(n)])
#以上是生成数据
A_vector = np.linalg.eig(A.T.dot(A))[1][:,0] #数据的主特征向量
x_new_1 = np.array([np.random.rand() for i in range(d)])
#print(x_new_1)
x_new_1 = x_new_1 / np.sqrt(x_new_1 @ x_new_1)
x_new_2 = x_new_1
for i in range(n):
z = A[i,:]
r1 = np.log(i + 2) / (i + 1) # 按照论文的理解,是不需要加乘上log部分的,可是不加log部分的效果也忒差了
r2 = 2 / max((3 * z @ z), i + 1)
z.resize(1,len(z))
x_new_1 = Oja_rule_1(x_new_1, z, r1)
x_new_2 = Oja_rule_2(x_new_2, z, r2)
x_new_2 = x_new_2 / np.sqrt(x_new_2 @ x_new_2)
dfv1 = D2D(A_vector, x_new_1)
dfv2 = D2D(A_vector, x_new_2)
dfx1 = D2D(x, x_new_1)
dfx2 = D2D(x, x_new_2)
dfAx = D2D(A_vector, x)
return dfv1, dfv2, dfx1, dfx2, dfAx
def Summary(times, d, n):
print('{0:^20} {1:^20} {2:^20} {3:^20} {4:^20}'.format('dfv1', 'dfv2', 'dfx1', 'dfx2', 'dfAx'))
print('{0:-<20} {0:-<20} {0:-<20} {0:-<20} {0:-<20}'.format(''))
M = np.array([0.] * 5)
Better = 0
for time in range(times):
result = Main(d, n)
M += result
if result[-2] > result[-1]:
Better += 1
print('{0[0]:^20.3f} {0[1]:^20.3f} {0[2]:^20.3f} {0[3]:^20.3f} {0[4]:^20.3f}'.format(result))
print('{0:-<20} {0:-<20} {0:-<20} {0:-<20} {0:-<20}'.format(''))
print('{0[0]:^20.3f} {0[1]:^20.3f} {0[2]:^20.3f} {0[3]:^20.3f} {0[4]:^20.3f}'.format(M / times))
print('{0:-<20} {0:-<20} {0:-<20} {0:-<20} {0:-<20}'.format(''))
print('{0:<10} {1:<10} {2:<10} {3:<10} {4:<10} {5:<10}'.format('Count:', times, 'n:', n, 'd:', d))
print('{0:<10} {1:<20}'.format('Better:', Better))
Summary(30, 15, 300)
Oja’s rule的更多相关文章
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
- Salesforce的sharing Rule 不支持Lookup型字段解决方案
Salesforce 中 sharing rule 并不支持Look up 字段 和 formula 字段.但在实际项目中,有时会需要在sharing rule中直接取Look up型字段的值,解决方 ...
- yii2权限控制rbac之rule详细讲解
作者:白狼 出处:http://www.manks.top/yii2_rbac_rule.html 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留 ...
- RBAC中 permission , role, rule 的理解
Role Based Access Control (RBAC)——基于角色的权限控制 permission e.g. creating posts, updating posts role A ro ...
- jquery validate minlength rule is not working
Question: I have a form with a password field. The password has to be at least 8 characters long. &l ...
- SOLID rule in JAVA design.
Classes are the building blocks of your java application. If these blocks are not strong, your build ...
- make[2]: *** No rule to make target `/root/.pyenv/versions/anaconda3-2.4.0/lib/libpython3.5m.so', needed by `evaluation.so'. Stop.
当出现No rule to make target ,肯定是Makefile有问题. 有的makefile是脚本生成的,你得看脚本的配置文件对不对. 我的是这个脚本生成的.发现是Pythondir的配 ...
- AASM rule of scoring sleep stages using EEG signal
Reference: AASM (2007). The AASM Manual for the Scoring of Sleep and Associated Events: Rules, Termi ...
- yii2权限控制rbac之rule详细讲解(转)
在我们之前yii2搭建后台以及rbac详细教程中,不知道你曾经疑惑过没有一个问题,rule表是做什么的,为什么在整个过程中我们都没有涉及到这张表? 相信我不说,部分人也都会去尝试,或百度或google ...
随机推荐
- mysql 最左匹配 联合索引
mysql建立多列索引(联合索引)有最左前缀的原则,即最左优先,如: 如果有一个2列的索引(col1,col2),则已经对(col1).(col1,col2)上建立了索引:如果有一个3列索引(col1 ...
- FastCGI Error Number: 5 (0x80070005).
在访问网站的时候,出现了以上这个错误: 在网上搜了很多方法,归纳起来就如下几种: 1, 网站安全狗]的安全策略问题 解决方案: 主动防御/禁止IIS执行程序 添加"php\php-cgi.e ...
- ctf学习(web题二)
web 下面是做bugku上一些web的总结 内容链接
- LeetCode算法题-Convert Sorted Array to Binary Search Tree(Java实现)
这是悦乐书的第166次更新,第168篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第25题(顺位题号是108).给定一个数组,其中元素按升序排序,将其转换为高度平衡的二叉 ...
- SpringCloud之初识Hystrix熔断器 ----- 程序的保护机制
在上一篇的-负载均衡Robbin中,我们简单讲解到负债均衡的算法和策略.负载均衡就是分发请求流量到不同的服务器,以减小服务器的压力和访问效率,但是当负载均衡的某个服务器或是服务挂掉之后,那么程序会出现 ...
- grep正则表达式搜索
grep -n -e "INT32 *AdaptorPrmOp" --include "*.c" -r ./ 搜索函数的定义 中间有n个空格
- TLB的作用及工作过程
下面内容摘自<步步惊芯--软核处理器内部设计分析>一书 页表一般都非常大,而且存放在内存中,所以处理器引入MMU后,读取指令.数据须要訪问两次内存:首先通过查询页表得到物 ...
- 【css】css规范
说法一: 属性的书写顺序, 举个例子: .hotel-content { /* 定位 */ display: block; position: absolute; left: 0; top: 0; / ...
- 吴恩达课后作业学习2-week1-2正则化
参考:https://blog.csdn.net/u013733326/article/details/79847918 希望大家直接到上面的网址去查看代码,下面是本人的笔记 4.正则化 1)加载数据 ...
- jenkins+mail邮件配置
1.配置过程中出现的问题,“501 mail from address must be same as authorization user” 解决方案 2.还有一个问题,在配置jenkins的系统配 ...