TFIDF<细读>
概念
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
<TF-IDF是一种统计方法,用以评估每个字词对于一个文件集或一个语料库中的其中一份文件的重要程度: 评价一个语料库中的每一个词,对于每个文档的重要性,其中这个语料库是所有文档中词的汇总>
原理
在一份给定的文件里,词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(分子一般小于分母 区别于IDF),以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)归一化,是该词出现的次数除以该文档所有词的个数。
逆向文件频率 (inverse document frequency, IDF) 是一个词语普遍重要性的度量。某一特定词语的IDF,可以由(总文件数目除以包含该词语之文件的数目)>1,再将得到的商取对数得到。
<总文件数目除以包含该词语之文件的数目: 假如一个词在所有文件中都出现,那么这个商就接近1,log后的值接近0,重要度接近0.如果一个词就在很少的文件中出现,那么这个商值很大,就是重要性也很大> ,这样看来,TF-IDF倾向于过滤掉常见的词语,保留重要的词语>
 TF:表达一个词在一个文件的出现频率程度
TF:表达一个词在一个文件的出现频率程度
 IDF:表达一个词在所有文件份中出现的频率程度
IDF:表达一个词在所有文件份中出现的频率程度
|D|:语料库中的文件总数
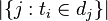 :包含词语
:包含词语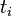 的文件数目(即
的文件数目(即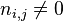 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用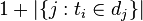
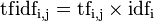
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。
因此,TF-IDF倾向于过滤掉[通过设置TFIDF值的阈值]常见的词语,保留重要的词语。
TFIDF<细读>的更多相关文章
- TF-IDF算法学习报告
TF-IDF是一种统计方法,这个算法在我们项目提取关键词的模块需要被用到,TF-IDF算法是用来估计 一个词汇对于一个文件集中一份文件的重要程度.从算法的定义中就可以看到,这个算法的有效实现是依靠 一 ...
- tf-idf知多少?
1.最完整的解释 TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度.字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反 ...
- TF-IDF提取行业关键词
1. TF-IDF简介 TF-IDF(Term Frequency/Inverse Document Frequency)是信息检索领域非常重要的搜索词重要性度量:用以衡量一个关键词\(w\)对于查询 ...
- 细读cow.osg
细读cow.osg 转自:http://www.cnblogs.com/mumuliang/archive/2010/06/03/1873543.html 对,就是那只著名的奶牛. //Group节点 ...
- Lucene TF-IDF 相关性算分公式(转)
Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序 TF:词频,IDF:逆向文档频率,TF-IDF是一种统计方法,或者被称为向量空间模型,名字听起来很 ...
- TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术.TF-IDF是一种统计方法,用以评估一字词对于一个文件集或 ...
- TF-IDF 加权及其应用
TF-IDF 加权及其应用 TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索的常用加权技术.TF-IDF是一种统计方法,用以评估某个 ...
- TF-IDF算法
转自:http://www.cnblogs.com/eyeszjwang/articles/2330094.html TF-IDF(term frequency–inverse document fr ...
- TF-IDF 文本相似度分析
前阵子做了一些IT opreation analysis的research,从产线上取了一些J2EE server运行状态的数据(CPU,Menory...),打算通过训练JVM的数据来建立分类模型, ...
随机推荐
- 牛客练习赛44C
链接:https://ac.nowcoder.com/acm/contest/634/C来源:牛客网 题目描述 给出一个区间[L,R],求出[L,R]中孪生质数有多少对. 由于这是一个区间筛质数的模板 ...
- Ubuntu16.04 藍牙連上,但是聲音裏面找不到設備
解決辦法: 1. sudo apt-get install blueman bluez* 2. sudo vim /etc/pulse/default.pa 注釋掉下面的代碼: #.ifexists ...
- Hillstone目的地址转换DNAT配置
目的地址映射主要用于将内网的服务器对外进行发布(如http服务,ftp服务,数据库服务等),使外网用户能够通过外网地址访问需要发布的服务. 常用的DNAT映射有一对一IP映射,一对一端口映射,多对多端 ...
- python note 10 函数变量
1.命名空间 #内置命名空间 —— python解释器 # 就是python解释器一启动就可以使用的名字存储在内置命名空间中 # 内置的名字在启动解释器的时候被加载进内存里#全局命名空间 —— 我们写 ...
- 摘选改善Python程序的91个建议
1.理解Pythonic概念 Pythonic Tim Peters 的 <The Zen of Python>相信学过 Python 的都耳熟能详,在交互式环境中输入import thi ...
- jq 字符串去除空格
1.去除首尾空格: var txt = $('#Txt').val().trim(); txt = txt.replace(/(^\s*)|(\s*$)/g, ""); 2.去除所 ...
- thinkphp 响应对象
<?php namespace app\admin\controller; use think\Request; class Index{ public function index(Reque ...
- asp.net asp.net application 升级到 asp.net web 解决找不到控件 批量生成.designer文件
颇费周折后,其实很简单,只需要生成designer文件后,重新保存所有页面即可.就是懒得写.懒真的是一种病,手上不能懒,脑子里更不能懒,否则就是给自己挖坑,仔细认真,注意细节!!!! PS:注意修改p ...
- HTML5学习路线导航
一.基本标签元素 1.基础标签第一篇 2.基础标签第二篇 3.表单form的使用 4.新增表单验证 二.CSS样式表 4.CSS插入样式表的三种格式 5.六大选择器 6.样式内容详细讲解 7.背景渐进 ...
- Python_格式化字符
%% 百分号标记 #就是输出一个%%c 字符及其ASCII码%s 字符串 %r 是不管是什么打印出来%d 有符号整数(十进制)%u 无符号整数(十进制)%o 无符号整数(八进制)%x 无符号整数(十六 ...