总结Flink状态管理和容错机制
本文来自8月11日在北京举行的 Flink Meetup会议,分享来自于施晓罡,目前在阿里大数据团队部从事Blink方面的研发,现在主要负责Blink状态管理和容错相关技术的研发。
- 有状态的流数据处理;
- Flink中的状态接口;
- 状态管理和容错机制实现;
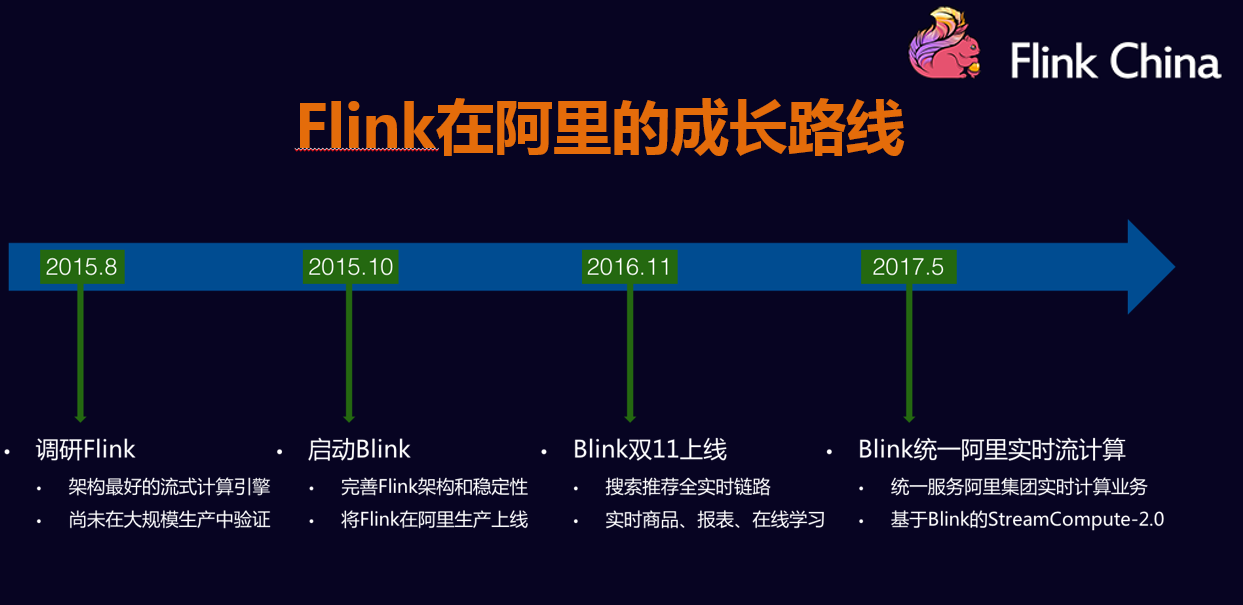
- 阿里相关工作介绍;
- 状态数据的存储和访问;
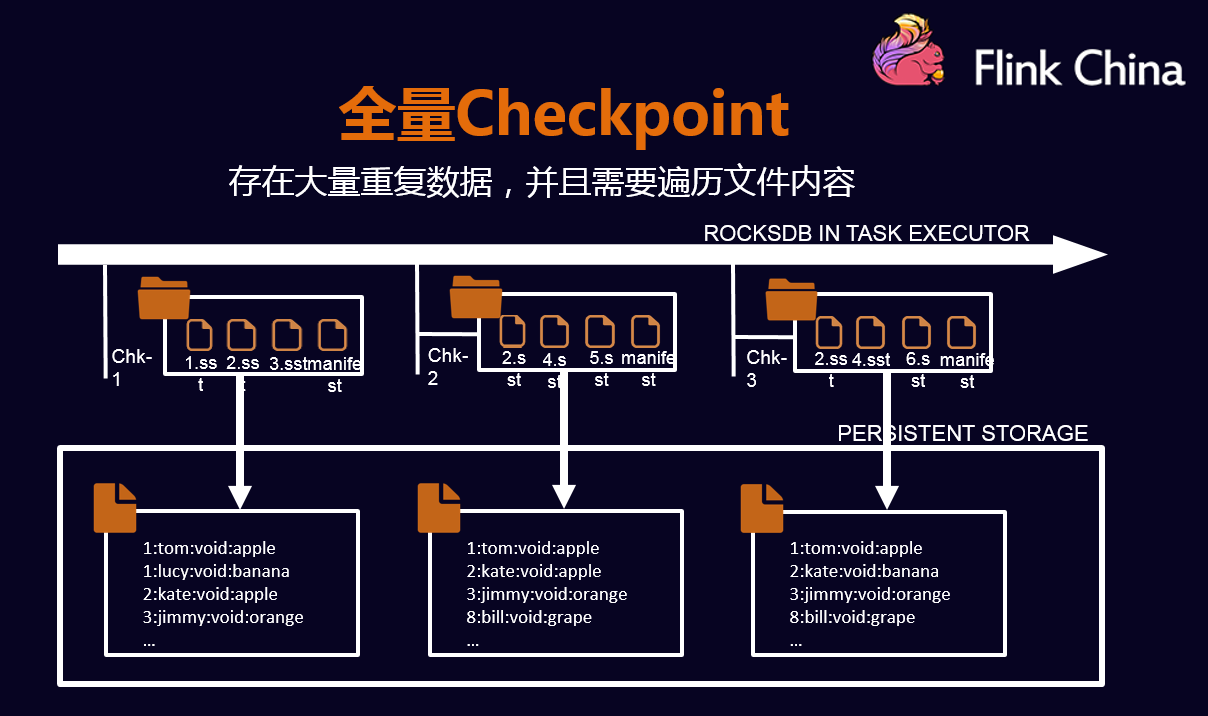
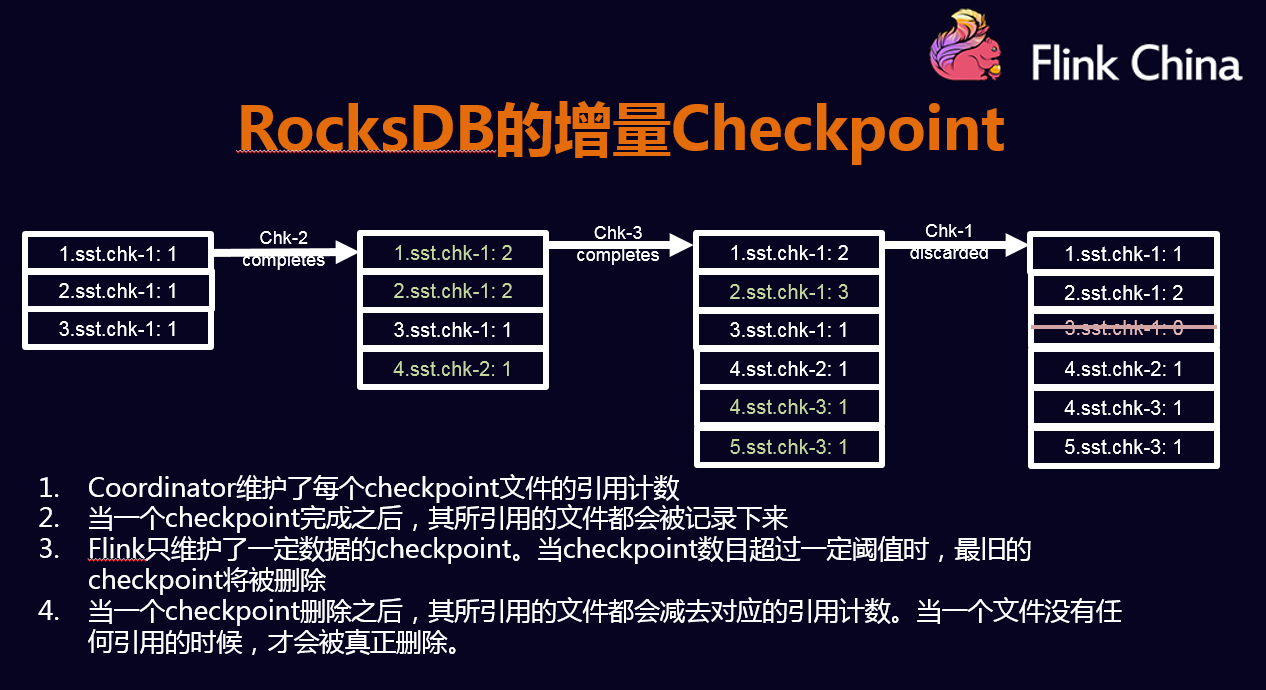
- 状态数据的备份和恢复;
- 状态数据的划分和动态扩容;

- 流计算系统的任务和Hbase的数据存储有可能不在同一台机器上,导致性能会很差。这样经常会做远端的访问,走网络和存储;
- 备份和恢复是比较困难,因为Hbase是没有回滚的,要做到Exactly onces很困难。在分布式环境下,如果程序出现故障,只能重启Storm,那么Hbase的数据也就无法回滚到之前的状态。比如广告计费的这种场景,Storm+Hbase是是行不通的,出现的问题是钱可能就会多算,解决以上的办法是Storm+mysql,通过mysql的回滚解决一致性的问题。但是架构会变得非常复杂。性能也会很差,要commit确保数据的一致性。
- 对于storm而言状态数据的划分和动态扩容也是非常难做,一个很严重的问题是所有用户都会在strom上重复的做这些工作,比如搜索,广告都要在做一遍,由此限制了部门的业务发展。

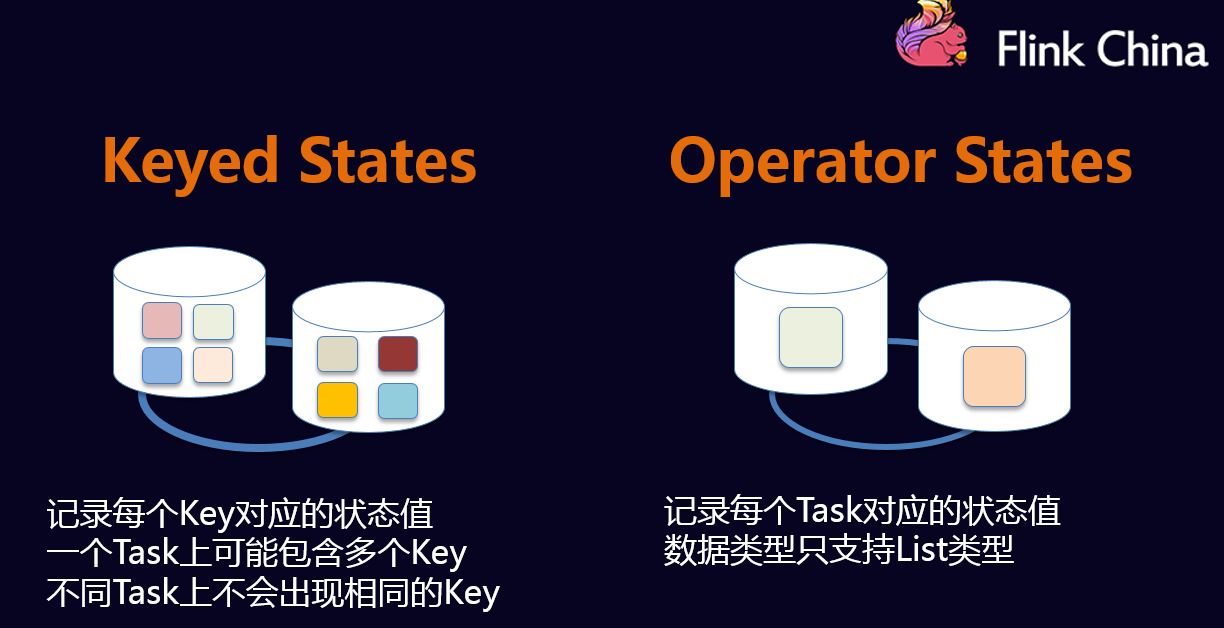
- Keyed States
- Operator States




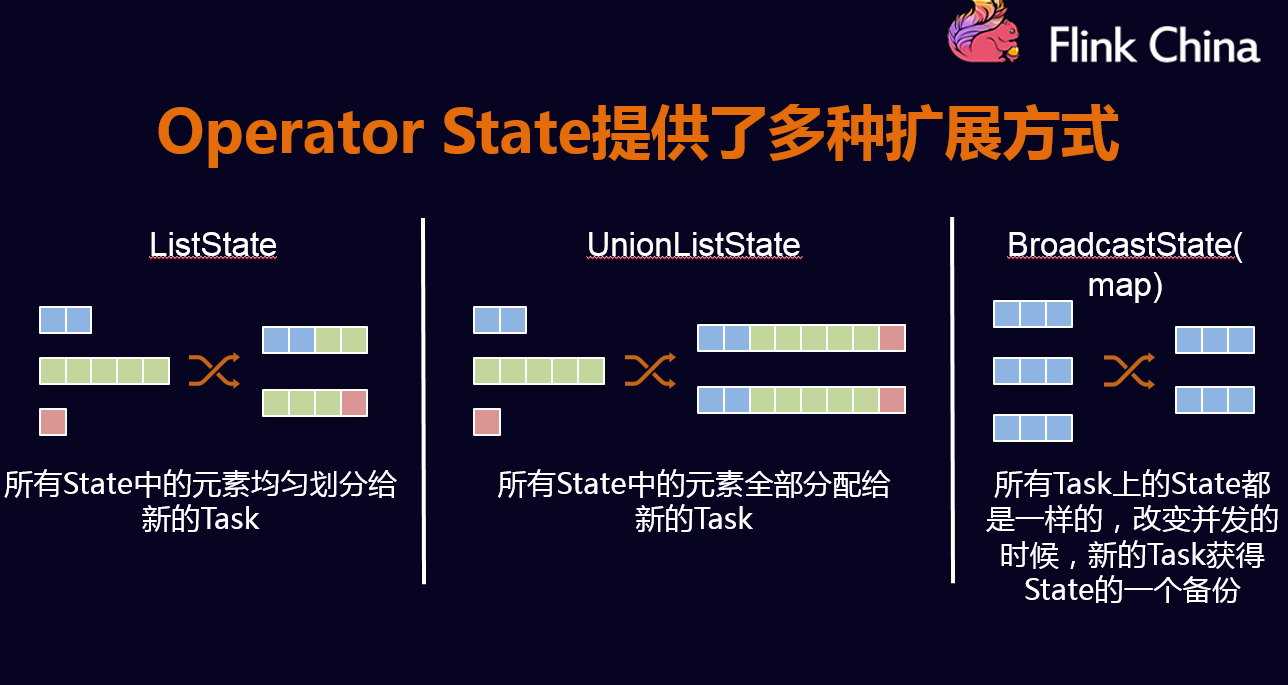
- ListState:并发度在改变的时候,会将并发上的每个List都取出,然后把这些List合并到一个新的List,然后根据元素的个数在均匀分配给新的Task;
- UnionListState:相比于ListState更加灵活,把划分的方式交给用户去做,当改变并发的时候,会将原来的List拼接起来。然后不做划分,直接交给用户;
- BroadcastState:如大表和小表做Join时,小表可以直接广播给大表的分区,在每个并发上的数据都是完全一致的。做的更新也相同,当改变并发的时候,把这些数据COPY到新的Task即可
- AT LEAST ONCE;
- Exactly once;

- Savepoint:是一种特殊的checkpoint,只不过不像checkpoint定期的从系统中去触发的,它是用户通过命令触发,存储格式和checkpoint也是不相同的,会将数据按照一个标准的格式存储,不管配置什么样,Flink都会从这个checkpoint恢复,是用来做版本升级一个非常好的工具;
- External Checkpoint:对已有checkpoint的一种扩展,就是说做完一次内部的一次Checkpoint后,还会在用户给定的一个目录中,多存储一份checkpoint的数据;

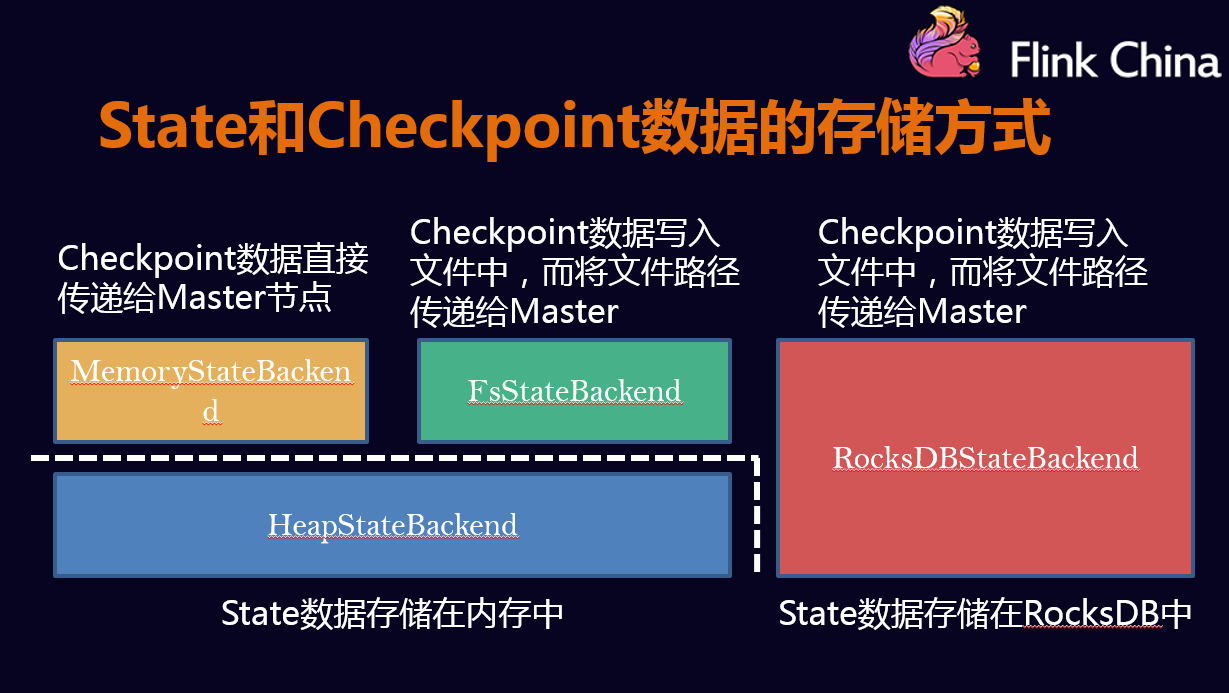
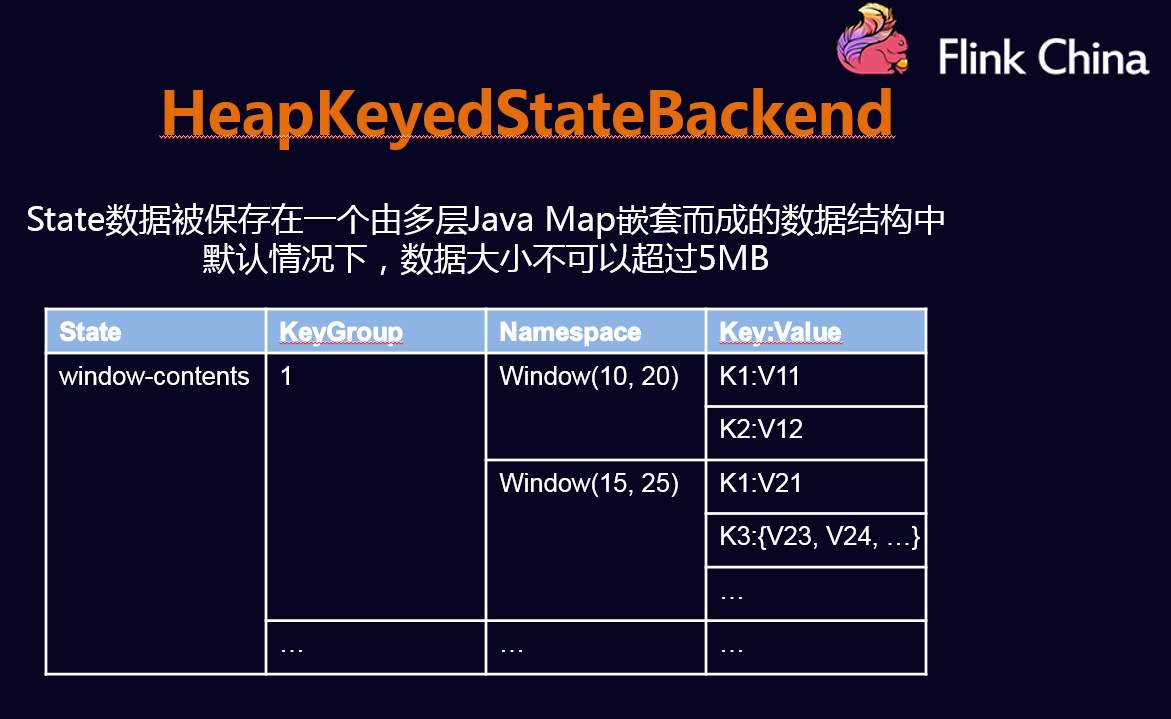
- MemoryStateBackend
- FsStateBackend
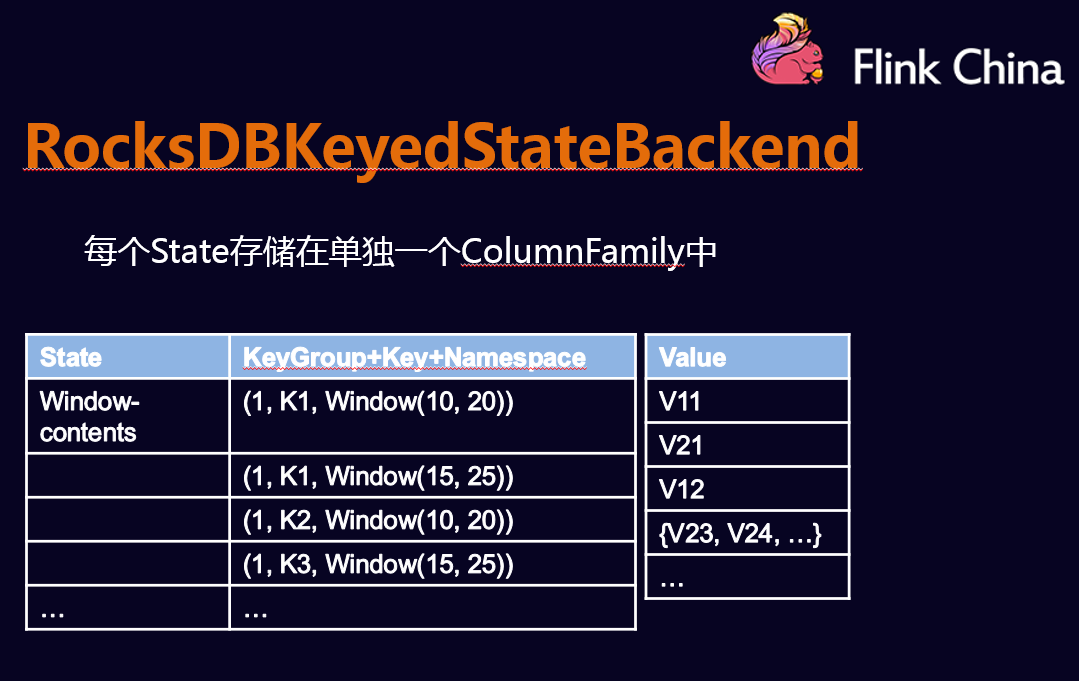
- RockDBStateBackend




总结Flink状态管理和容错机制的更多相关文章
- Flink状态管理和容错机制介绍
本文主要内容如下: 有状态的流数据处理: Flink中的状态接口: 状态管理和容错机制实现: 阿里相关工作介绍: 一.有状态的流数据处理# 1.1.什么是有状态的计算# 计算任务的结果不仅仅依赖于输入 ...
- 大数据计算引擎之Flink Flink状态管理和容错
这里将介绍Flink对有状态计算的支持,其中包括状态计算和无状态计算的区别,以及在Flink中支持的不同状态类型,分别有 Keyed State 和 Operator State .另外针对状态数据的 ...
- 「Flink」Flink的状态管理与容错
在Flink中的每个函数和运算符都是有状态的.在处理过程中可以用状态来存储数据,这样可以利用状态来构建复杂操作.为了让状态容错,Flink需要设置checkpoint状态.Flink程序是通过chec ...
- Flink状态管理与状态一致性(长文)
目录 一.前言 二.状态类型 2.1.Keyed State 2.2.Operator State 三.状态横向扩展 四.检查点机制 4.1.开启检查点 (checkpoint) 4.2.保存点机制 ...
- Flink的状态管理与恢复机制
参考地址:https://www.cnblogs.com/airnew/p/9544683.html 问题一.什么是状态? 问题二.Flink状态类型有哪几种? 问题三.状态有什么作用? 问题四.如何 ...
- Flink的状态编程和容错机制(四)
一.状态编程 Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据.例如 : ProcessWi ...
- Flutter 对状态管理的认知与思考
前言 由 编程技术交流圣地[-Flutter群-] 发起的 状态管理研究小组,将就 状态管理 相关话题进行为期 两个月 的讨论. 目前只有内定的 5 个人参与讨论,如果你对 状态管理 有什么独特的见解 ...
- Flink 容错机制与状态
简介 Apache Flink提供了一种容错机制,可以持续恢复数据流应用程序的状态. 该机制确保即使出现故障,经过恢复,程序的状态也会回到以前的状态. Flink 主持 at least once 语 ...
- 关于 Flink 状态与容错机制
Flink 作为新一代基于事件流的.真正意义上的流批一体的大数据处理引擎,正在逐渐得到广大开发者们的青睐.就从我自身的视角看,最近也是在数据团队把一些原本由 Flume.SparkStreaming. ...
随机推荐
- codeforces 161D Distance in Tree 树上点分治
链接:https://codeforces.com/contest/161/problem/D 题意:给一个树,求距离恰好为$k$的点对是多少 题解:对于一个树,距离为$k$的点对要么经过根节点,要么 ...
- Android应用内嵌unity3d游戏项目
在一个现有的Android项目中嵌入unity3d项目 1.将unity3d项目导出android工程 2.将第一步导出的Android工程中assets文件夹和libs文件夹下的所有内容复制到And ...
- redhat yum
背景 这个redhat可让我好一顿折腾,对于这个yum的安装,如果成功则罢,不成功可有的收拾的.还是centos比较好啊. 转载 1 下载下面四个软件包(可以从163下载,版本号自己搜索) wget ...
- Mysql支持哪几种索引
从数据结构角度 1.B+树索引(O(log(n))):关于B+树索引,可以参考 MySQL索引背后的数据结构及算法原理 2.hash索引:a 仅仅能满足"=","IN&q ...
- Git系列②之部署企业级开源仓库gitlab服务器
Git系列②之部署企业级开源仓库gitlab服务器 上一篇我们介绍了github的常见使用方法,下面开始部署本地开源仓库gitlab GitLab 是一个用于仓库管理系统的开源项目. 1.安装配置gi ...
- eclipse:显示堆内存
如下图 :
- LuoGu P2783 有机化学之神偶尔会做作弊
题目传送门 人生第一道黑题呢,虽然这题是黑题中的水题并且我调了一整节课,但是我还是很兴奋啊.毕竟人生第一道黑题啊 这个题根据题意,先把整个图进行tarjan缩点,建出一棵树,对于每一组询问,两点之间的 ...
- Servet
一.Servlet 是单例吗 不是. 1.你可以用多个 URL 映射同一个 Servlet.这样就会出现多个实例. 2.看看 Servlet 定义: 引用 For a servlet not host ...
- JdbcUtil
package com.todaytech.pwp.core.exception; public class BizException extends RuntimeException { publi ...
- ORACLE的数据类型的长度合集
-- ORACLE的数据类型常用的数据库字段类型如下:字段类型 中文说明 限制条件 其它说明CHAR 固定长度字符串 最大长度2000 bytesVARCHAR2 可变长度的字符串 最大长度4000 ...