Dubbo常用配置文件分析及核心源码阅读(SPI.Extension)
关于 Dubbo SPI:
在Dubbo中,SPI是一个非常核心的机制,贯穿在几乎所有的流程中。Dubbo是基于Java原生SPI机制思想的一个改进,所以,先从JAVA SPI机制开始了解什么是SPI以后再去学习Dubbo的SPI,就比较容易了
关于JAVA 的SPI机制:
SPI全称(service provider interface),是JDK内置的一种服务提供发现机制,目前市面上有很多框架都是用它来做服务的扩展发现,大家耳熟能详的如JDBC、日志框架都有用到;简单来说,它是一种动态替换发现的机制。举个简单的例子,如果我们定义了一个规范,需要第三方厂商去实现,那么对于我们应用方来说,只需要集成对应厂商的插件,既可以完成对应规范的实现机制。 形成一种插拔式的扩展手段。
SPI的实际应用
SPI在很多地方有应用,大家可以看看最常用的java.sql.Driver驱动。JDK官方提供了java.sql.Driver这个驱动扩展点,但是你们并没有看到JDK中有对应的Driver实现。 那在哪里实现呢?以连接Mysql为例,我们需要添加mysql-connector-java依赖。然后,你们可以在这个jar包中找到SPI的配置信息。如下图,所以java.sql.Driver由各个数据库厂商自行实现。这就是SPI的实际应用。当然除了这个意外,大家在spring的包中也可以看到相应的痕迹
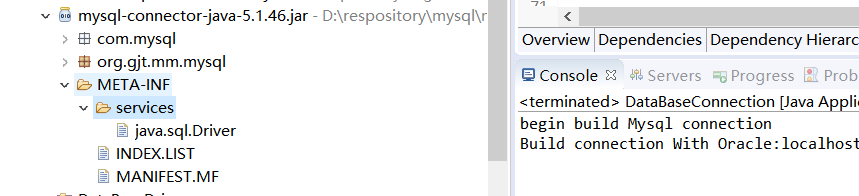
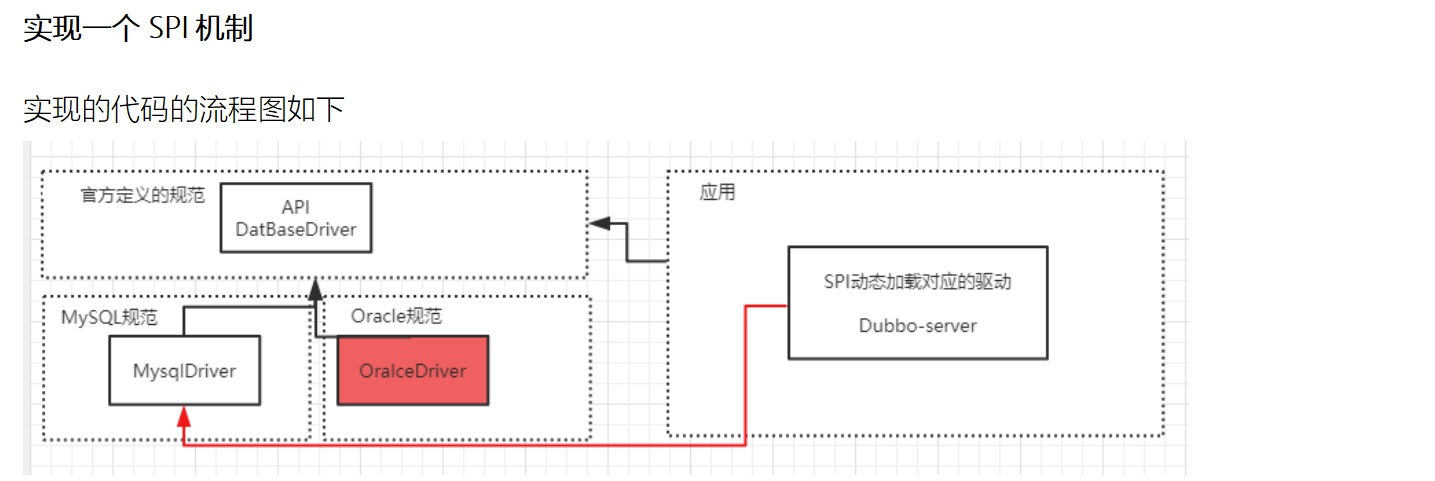
已数据库连接为例,接下来创建3个工程分别是 DataBaseDriver,MysqlDriver,OracleDriver。其中mysql,oracle两个工程的pom文件都引用了DataBaseDriver。这样使得DataBaseDriver所定义的规范能让其他两个要实现的厂商去实现。先看一下所定义的接口:
public interface DataBaseDriver {
String connect(String host);
}
没有花头,就是顶一个接口,这就类似于 java.sql包下的driver 接口是一样的。接下去是MysqlDriver对其实现:
public class MysqlDriver implements DataBaseDriver{
@Override
public String connect(String s) {
return "begin build Mysql connection" +s;
}
}
实现SPI,就需要按照SPI本身定义的规范来进行配置,SPI规范如下
1. 需要在classpath下创建一个目录,该目录命名必须是:META-INF/services
2. 在该目录下创建一个properties文件,该文件需要满足以下几个条件
a) 文件名必须是扩展的接口的全路径名称
b) 文件内部描述的是该扩展接口的所有实现类
c) 文件的编码格式是UTF-8
3. 通过java.util.ServiceLoader的加载机制来发现
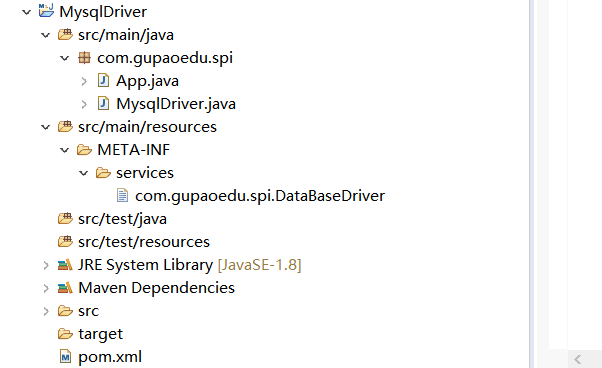
而 com.gupaoedu.spi.DataBaseDriver 文件的内容就是 com.gupaoedu.spi.MysqlDriver,最后写一个 main方法去测试,不过需要所在工程pom文件引入MysqlDriver的依赖。:
public static void main(String[] args) {
ServiceLoader<DataBaseDriver> serviceLoader=
ServiceLoader.load(DataBaseDriver.class);
for(DataBaseDriver driver:serviceLoader){
System.out.println(driver.connect("localhost"));
}
}
这样就完成 SPI的简单应用,如果想做OracleDriver的实现也是一样的道理,但是当我们同时引入了mysql跟oracle 两个驱动包,发现在main方法执行的时候会同时调用两个实现。
SPI的缺点
1. JDK标准的SPI会一次性加载实例化扩展点的所有实现,什么意思呢?就是如果你在META-INF/service下的文件里面加了N个实现类,那么JDK启动的时候都会一次性全部加载。那么如果有的扩展点实现初始化很耗时或者如果有些实现类并没有用到,那么会很浪费资源
2. 如果扩展点加载失败,会导致调用方报错,而且这个错误很难定位到是这个原因
Dubbo的SPI机制规范
大部分的思想都是和SPI是一样,只是下面两个地方有差异。
1. 需要在resource目录下配置META-INF/dubbo或者META-INF/dubbo/internal或者META-INF/services,并基于SPI接口去创建一个文件。
2. 文件名称和接口名称保持一致,文件内容和SPI有差异,内容是Key对应Value。
在dubbo 的官方开发文档中,有个SPI拓展,现在我们演示一个小例子,比如对协议拓展,那么就要实现 dubbo官方定义的协议默认规范接口:
public class DefineProtocol implements Protocol {
@Override
public int getDefaultPort() {
return 8888;
}
@Override
public <T> Exporter<T> export(Invoker<T> invoker) throws RpcException {
return null;
}
@Override
public <T> Invoker<T> refer(Class<T> type, URL url) throws RpcException {
return null;
}
@Override
public void destroy() {
}
}
其中什么都没有实现,仅仅是把端口号修改成8888,然后按照SPI的规范 ,新建一个规范路劲

要提供一个配置文件:com.alibaba.dubbo.rpc.Protocol ,这个就是dubbo所提供的拓展接口,内容如下:
myProtocol=com.gupaoedu.dubbo.DefineProtocol
然后启用 dubbo 的 ExtensionLoader 去加载我们自定义的 protocol:
Protocol protocol =ExtensionLoader.getExtensionLoader(Protocol.class).getExtension("myProtocol");
System.out.println(protocol.getDefaultPort());
输出 8888 .完成一个很基础的 SPI 拓展例子。这里面的实现原理是怎么回事呢? 来看看 dubbo 的源码来一探究竟把。通过如下代码进入切入点:
Protocol protocol2 =ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();
Protocol源码
在这个源码中可以看到有两个注解,一个是在类级别上的@SPI(“dubbo”). 另一个是@Adaptive
@SPI 表示当前这个接口是一个扩展点,可以实现自己的扩展实现,默认的扩展点是DubboProtocol。
@Adaptive 表示一个自适应扩展点,在方法级别上,会动态生成一个适配器类
@SPI("dubbo")
public interface Protocol {
/**
* 获取缺省端口,当用户没有配置端口时使用。
*
* @return 缺省端口
*/
int getDefaultPort();
/**
* 暴露远程服务:<br>
* 1. 协议在接收请求时,应记录请求来源方地址信息:RpcContext.getContext().setRemoteAddress();<br>
* 2. export()必须是幂等的,也就是暴露同一个URL的Invoker两次,和暴露一次没有区别。<br>
* 3. export()传入的Invoker由框架实现并传入,协议不需要关心。<br>
*
* @param <T> 服务的类型
* @param invoker 服务的执行体
* @return exporter 暴露服务的引用,用于取消暴露
* @throws RpcException 当暴露服务出错时抛出,比如端口已占用
*/
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
/**
* 引用远程服务:<br>
* 1. 当用户调用refer()所返回的Invoker对象的invoke()方法时,协议需相应执行同URL远端export()传入的Invoker对象的invoke()方法。<br>
* 2. refer()返回的Invoker由协议实现,协议通常需要在此Invoker中发送远程请求。<br>
* 3. 当url中有设置check=false时,连接失败不能抛出异常,并内部自动恢复。<br>
*
* @param <T> 服务的类型
* @param type 服务的类型
* @param url 远程服务的URL地址
* @return invoker 服务的本地代理
* @throws RpcException 当连接服务提供方失败时抛出
*/
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
/**
* 释放协议:<br>
* 1. 取消该协议所有已经暴露和引用的服务。<br>
* 2. 释放协议所占用的所有资源,比如连接和端口。<br>
* 3. 协议在释放后,依然能暴露和引用新的服务。<br>
*/
void destroy();
}
根据 SPI的规则,这里注解@SPI(“dubbo”),应该会有个类似resource目录下配置META-INF/dubbo或者META-INF/dubbo/internal或者META-INF/services,并基于SPI接口去创建一个文件。dubbo框架里面也有:

在其 jar 包中找出了蛛丝马迹,文件目录在 META-INF/dubbo/internal 之下。在该文件目录下还存在着好多的SPI拓展。这就不一一举例了。我们可以看看其默认的Protocol的实现:main方法中执行如下代码
// 拓展点loader 获取 Protocol 拓展点loader 获得默认拓展点 获得默认端口
int port = ExtensionLoader.getExtensionLoader(Protocol.class).getDefaultExtension().getDefaultPort();
System.out.println(port);
输出 20880 ,着正是我们所期待的。在加载拓展点的过程中无非涉及两个方法:getExtensionLoader,getAdaptiveExtension这两个比较核心的两个方法:
getExtensionLoader(Class<T> type):
public static <T> ExtensionLoader<T> getExtensionLoader(Class<T> type) {
if (type == null)
throw new IllegalArgumentException("Extension type == null");
if (!type.isInterface()) {
throw new IllegalArgumentException("Extension type(" + type + ") is not interface!");
}
if (!withExtensionAnnotation(type)) {
throw new IllegalArgumentException("Extension type(" + type +
") is not extension, because WITHOUT @" + SPI.class.getSimpleName() + " Annotation!");
}
ExtensionLoader<T> loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
if (loader == null) {
EXTENSION_LOADERS.putIfAbsent(type, new ExtensionLoader<T>(type));
loader = (ExtensionLoader<T>) EXTENSION_LOADERS.get(type);
}
return loader;
}
private ExtensionLoader(Class<?> type) {
this.type = type;
objectFactory = (type == ExtensionFactory.class ? null : ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension());
}
参数是拓展点的类型,根据类型去获得拓展点的loader,上诉代码就是初始化一个 ExtensionLoader (拓展点loader),该方法需要一个Class类型的参数,该参数表示希望加载的扩展点类型,该参数必须是接口,且该接口必须被@SPI注解注释,否则拒绝处理。检查通过之后首先会检查ExtensionLoader缓存中是否已经存在该扩展对应的ExtensionLoader,如果有则直接返回,否则创建一个新的ExtensionLoader负责加载该扩展实现,同时将其缓存起来。可以看到对于每一个扩展,dubbo中只会有一个对应的ExtensionLoader实例。
getAdaptiveExtension():获得自适应拓展点
public T getAdaptiveExtension() {
Object instance = cachedAdaptiveInstance.get();
if (instance == null) { // 第一次进来一定是null
if (createAdaptiveInstanceError == null) {
//这里可以看到跟单例实现方法里面的双重检查锁机制是一样的
synchronized (cachedAdaptiveInstance) {
// 从缓存中拿
instance = cachedAdaptiveInstance.get();
if (instance == null) {
try {
// 创建出一个自适应拓展点 并且设置进入缓存
instance = createAdaptiveExtension();
cachedAdaptiveInstance.set(instance);
} catch (Throwable t) {
createAdaptiveInstanceError = t;
throw new IllegalStateException("fail to create adaptive instance: " + t.toString(), t);
}
}
}
} else {
throw new IllegalStateException("fail to create adaptive instance: " + createAdaptiveInstanceError.toString(), createAdaptiveInstanceError);
}
}
return (T) instance;
}
createAdaptiveExtension():创建自适应拓展点
private T createAdaptiveExtension() {
try { // 类似Spring的依赖注入
return injectExtension((T) getAdaptiveExtensionClass().newInstance());// ((T) getAdaptiveExtensionClass().newInstance()这个是获取到自定义的适配器类或者自动生成的Protocol$Adaptive
} catch (Exception e) {
throw new IllegalStateException("Can not create adaptive extenstion " + type + ", cause: " + e.getMessage(), e);
}
}
这个方法之中嵌套了一个 injectExtension 方法,其中有个 getAdaptiveExtensionClass 获取自适应拓展点class的方法去创建自适应拓展点实例的方法getAdaptiveExtensionClass()。
getAdaptiveExtensionClass():获得自适应拓展点class
private Class<?> getAdaptiveExtensionClass() {
getExtensionClasses();// 获取拓展点Class
// 不一定为 null
//这里涉及到的@Adaptive注解,如果注到类级别上,说明我自定义了自适应拓展点,
//代码在上一行getExtensionClasses中的 clazz.isAnnotationPresent(Adaptive.class)判断中体现,
// 如果有 这里就不为 null 直接返回,如果没有,就需要自动生成适配器类
if (cachedAdaptiveClass != null) {
return cachedAdaptiveClass;
}// 创建一个自适应拓展点
return cachedAdaptiveClass = createAdaptiveExtensionClass();
}
createAdaptiveExtensionClass(): 创建自适应拓展点 创建一个动态的字节码文件 生成了一个Protocol$Adaptive类
private Class<?> createAdaptiveExtensionClass() {
// 生成字节码代码
String code = createAdaptiveExtensionClassCode();
//获得类加载器
ClassLoader classLoader = findClassLoader();
com.alibaba.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(com.alibaba.dubbo.common.compiler.Compiler.class).getAdaptiveExtension();
//动态编译字节码
return compiler.compile(code, classLoader);
}
这个字节码文件到底时什么呢? 我们通过调用以下代码通过dbug来看看:Protocol protocol2 =ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();,可以发现最后输出的String code = createAdaptiveExtensionClassCode(); 这个code的结果就是一个类的信息,如下:
package com.alibaba.dubbo.rpc;
import com.alibaba.dubbo.common.extension.ExtensionLoader;
public class Protocol$Adaptive implements com.alibaba.dubbo.rpc.Protocol {
public void destroy() {
throw new UnsupportedOperationException(
"method public abstract void com.alibaba.dubbo.rpc.Protocol.destroy() of interface com.alibaba.dubbo.rpc.Protocol is not adaptive method!");
} public int getDefaultPort() {
throw new UnsupportedOperationException(
"method public abstract int com.alibaba.dubbo.rpc.Protocol.getDefaultPort() of interface com.alibaba.dubbo.rpc.Protocol is not adaptive method!");
} public com.alibaba.dubbo.rpc.Invoker refer(java.lang.Class arg0, com.alibaba.dubbo.common.URL arg1)
throws com.alibaba.dubbo.rpc.RpcException {
if (arg1 == null)
throw new IllegalArgumentException("url == null");
com.alibaba.dubbo.common.URL url = arg1;
String extName = (url.getProtocol() == null ? "dubbo" : url.getProtocol());
if (extName == null)
throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.rpc.Protocol) name from url("
+ url.toString() + ") use keys([protocol])");
com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol) ExtensionLoader
.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.refer(arg0, arg1);
} public com.alibaba.dubbo.rpc.Exporter export(com.alibaba.dubbo.rpc.Invoker arg0)
throws com.alibaba.dubbo.rpc.RpcException {
if (arg0 == null)
throw new IllegalArgumentException("com.alibaba.dubbo.rpc.Invoker argument == null");
if (arg0.getUrl() == null)
throw new IllegalArgumentException("com.alibaba.dubbo.rpc.Invoker argument getUrl() == null");
com.alibaba.dubbo.common.URL url = arg0.getUrl();
String extName = (url.getProtocol() == null ? "dubbo" : url.getProtocol());
if (extName == null)
throw new IllegalStateException("Fail to get extension(com.alibaba.dubbo.rpc.Protocol) name from url("
+ url.toString() + ") use keys([protocol])");
com.alibaba.dubbo.rpc.Protocol extension = (com.alibaba.dubbo.rpc.Protocol) ExtensionLoader
.getExtensionLoader(com.alibaba.dubbo.rpc.Protocol.class).getExtension(extName);
return extension.export(arg0);
}
}
我们可以发现这个类实现了Protocol 接口并且对两个标注了@Adaptive注解的方法做了一个简单实现,生成了该适配器的类,对Protocol进行了一个包装。其中两个方法 refer(引用),export(发布),方法做了简单的包装,其中refer基于URL参数,来判断该使用什么协议。为什么要进行这么一个操作呢?是因为在服务的发布过程中 ,在ServiceConfig<T> 类中的doExportUrlsFor1Protocol(ProtocolConfig protocolConfig, List<URL> registryURLs)方法做服务发布的时候调用了一个protocol.export(invoker) ,protocol有很多的实现,而这个protocol 正是在初始化的时候通过private static final Protocol protocol = ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension();得到,也就是那个动态生成的字节码代码的类 Protocol$Adaptive,所以通过ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension()所创建的Protocol 对象正是这个 Protocol$Adaptive 类。
Protocol$Adaptive的主要功能
1. 从url或扩展接口获取扩展接口实现类的名称;
2.根据名称,获取实现类ExtensionLoader.getExtensionLoader(扩展接口类).getExtension(扩展接口实现类名称),然后调用实现类的方法。
需要明白一点dubbo的内部传参基本上都是基于Url来实现的,也就是说Dubbo是基于URL驱动的技术
所以,适配器类的目的是在运行期获取扩展的真正实现来调用,解耦接口和实现,这样的话不用我们自己实现适配器类,dubbo帮我们生成,而这些都是通过Adpative来实现。
代码看到这里,其实还有一个点,也就是根据SPI规范在指定路径下配置好配置文件在哪里加载呢? 其实是getAdaptiveExtensionClass():获得自适应拓展点class 这个方法里的 getExtensionClasses 通过配置文件加载拓展点实现类。
private Map<String, Class<?>> getExtensionClasses() {
// 这个map对应的key为拓展点的全路径名如:com.alibaba.dubbo.rpc.Protocol
// 而value则是对应实现类的全路径名
Map<String, Class<?>> classes = cachedClasses.get();
if (classes == null) { // double check
synchronized (cachedClasses) {
classes = cachedClasses.get();
if (classes == null) {
classes = loadExtensionClasses();
cachedClasses.set(classes);
}
}
}
return classes;
}
loadExtensionClasses():
private Map<String, Class<?>> loadExtensionClasses() {
// type 就是我们传进来的 Protocol.class
final SPI defaultAnnotation = type.getAnnotation(SPI.class);
// 判断其是不是拓展点
if (defaultAnnotation != null) {// 如果不等于空 即是拓展点
String value = defaultAnnotation.value();// 默认情况就是@SPI("dubbo")中的dubbo
if (value != null && (value = value.trim()).length() > 0) {
String[] names = NAME_SEPARATOR.split(value);
if (names.length > 1) {
throw new IllegalStateException("more than 1 default extension name on extension " + type.getName()
+ ": " + Arrays.toString(names));
}// 默认情况长度等于1 就把这个dubbo 赋值给cachedDefaultName
if (names.length == 1) cachedDefaultName = names[0];
}
}
Map<String, Class<?>> extensionClasses = new HashMap<String, Class<?>>();
// 去三个规定路径下加载拓展点文件,加载完会赋值到extensionClasses map里面
loadFile(extensionClasses, DUBBO_INTERNAL_DIRECTORY);
loadFile(extensionClasses, DUBBO_DIRECTORY);
loadFile(extensionClasses, SERVICES_DIRECTORY);
return extensionClasses;
}
loadExtensionClasses
从不同目录去加载扩展点的实现,在最开始的时候讲到过的。META-INF/dubbo ;META-INF/internal ; META-INF/services主要逻辑
1. 获得当前扩展点的注解,也就是Protocol.class这个类的注解,@SPI
2. 判断这个注解不为空,则再次获得@SPI中的value值
3. 如果value有值,也就是@SPI(“dubbo”),则讲这个dubbo的值赋给cachedDefaultName。这就是为什么我们能够通过ExtensionLoader.getExtensionLoader(Protocol.class).getDefaultExtension() ,能够获得DubboProtocol这个扩展点的原因
4. 最后,通过loadFile去加载指定路径下的所有扩展点。也就是META-INF/dubbo;META-INF/internal;META-INF/services
在获得了Protocol$Adaptive自适应适配器类之后,dubbo对该类进行了依赖注入:injectExtension :
private T injectExtension(T instance) {
try { // 这个objectFactory在getExtensionLoader的时候在私有的构造方法中就创建了,并且判断参数是否是ExtensionFactory.class
// 如果是,就返回null,如果不是则进入下一步创建
if (objectFactory != null) {
for (Method method : instance.getClass().getMethods()) {
if (method.getName().startsWith("set") // 这里是判断是否有个以set开头的方法,通过set进行动态注入
// 这个set方法的参数是一个拓展点属性。然后进入流程
&& method.getParameterTypes().length == 1
&& Modifier.isPublic(method.getModifiers())) {
Class<?> pt = method.getParameterTypes()[0];// 获得set方法的参数类型
try {
String property = method.getName().length() > 3 ? method.getName().substring(3, 4).toLowerCase() + method.getName().substring(4) : "";
// 根据类型,名称。通过这个objectFactory 获取拓展点实例,
Object object = objectFactory.getExtension(pt, property);
if (object != null) {// 注入
method.invoke(instance, object);
}
} catch (Exception e) {
logger.error("fail to inject via method " + method.getName()
+ " of interface " + type.getName() + ": " + e.getMessage(), e);
}
}
}
}
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return instance;
}
objectFactory.getExtension(pt, property);
这里先要看一下 objectFactory :
@SPI
public interface ExtensionFactory { /**
* Get extension.
*
* @param type object type.
* @param name object name.
* @return object instance.
*/
<T> T getExtension(Class<T> type, String name); }
本身他就是一个拓展点,其实现有3个:
spring=com.alibaba.dubbo.config.spring.extension.SpringExtensionFactory
adaptive=com.alibaba.dubbo.common.extension.factory.AdaptiveExtensionFactory
spi=com.alibaba.dubbo.common.extension.factory.SpiExtensionFactory
这里的objectFactory.getExtension(pt, property); 具体调用哪个实现由参数决定,因为在objectFactory初始化的时候是通过ExtensionLoader.getExtensionLoader(ExtensionFactory.class).getAdaptiveExtension()这段代码,可以很明确的知道这里的自适应拓展点就是AdaptiveExtensionFactory, 这里看一下com.alibaba.dubbo.common.extension.factory.AdaptiveExtensionFactory 这个实现
@Adaptive
public class AdaptiveExtensionFactory implements ExtensionFactory { private final List<ExtensionFactory> factories; public AdaptiveExtensionFactory() {
ExtensionLoader<ExtensionFactory> loader = ExtensionLoader.getExtensionLoader(ExtensionFactory.class);
List<ExtensionFactory> list = new ArrayList<ExtensionFactory>();
for (String name : loader.getSupportedExtensions()) {
list.add(loader.getExtension(name));
}
factories = Collections.unmodifiableList(list);
} public <T> T getExtension(Class<T> type, String name) {
for (ExtensionFactory factory : factories) {
T extension = factory.getExtension(type, name);
if (extension != null) {
return extension;
}
}
return null;
} }
可以看到该实现是一个静态的自适应适配器 ,因为@Adaptive注解在类级别上。这也是上面提到的 objectFactory的自适应拓展点为什么是AdaptiveExtensionFactory,在构造方法中其实就是将ExtensionFactory的实现加载到factories 里面。AdaptiveExtensionFactory 是个自适应适配器的拓展点,我们先不理会。然后 factories 的值应该就是 :
factories =[spring=com.alibaba.dubbo.config.spring.extension.SpringExtensionFactory,
spi=com.alibaba.dubbo.common.extension.factory.SpiExtensionFactory]
然后根据 type 跟name 去匹配,objectFactory.getExtension(pt, property) 获取拓展点,spring 也好,spi也可以。最后通过method.invoke(instance, object); 注入。
最后 ExtensionLoader.getExtensionLoader(Protocol.class).getAdaptiveExtension() 的整个流程就走完了。
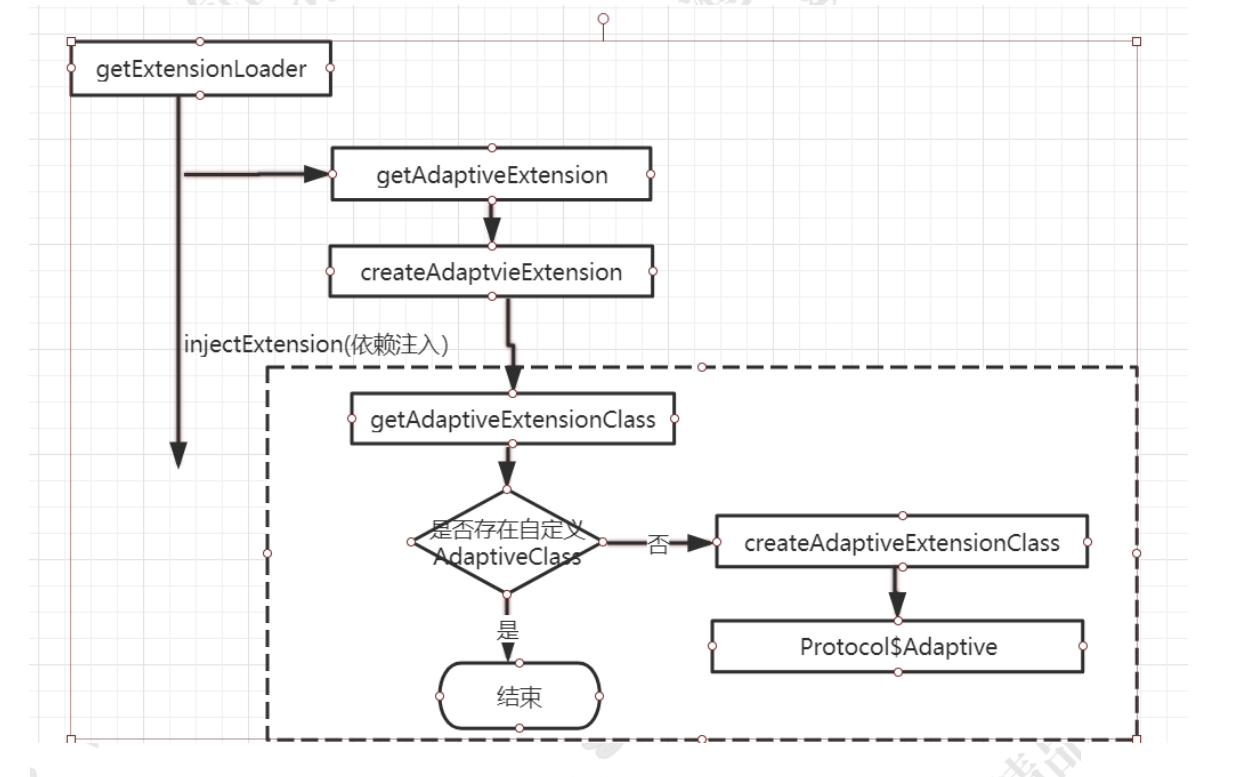
这也正是dubbo所提供的各大拓展点的核心原理。上一张流程图
Dubbo常用配置文件分析及核心源码阅读(SPI.Extension)的更多相关文章
- Dubbo(2)--Dubbo常用配置文件解析及核心源码阅读
1.多版本支持 服务端 创建第二个接口实现类 package com.lf; public class HelloImpl2 implements IHello{ @Override public S ...
- 聊聊Dubbo(六):核心源码-Filter链原理
转载:https://www.jianshu.com/p/6dd76ce7338f 0 前言 对于Java WEB应用来说,Spring的Filter可以拦截WEB接口调用,但对于Dubbo接口,Sp ...
- Linux核心源码阅读方法
首次阅读Linux4.0.5内核源代码时,一脸茫然,它的代码不仅复杂,而且庞大,找不到从哪里开始阅读. 通常Linux会有以下目录 arch 子目录包括所有和体系结构相关的核心代码.它还有更深的子目录 ...
- 1 手写Java ArrayList核心源码
手写ArrayList核心源码 ArrayList是Java中常用的数据结构,不光有ArrayList,还有LinkedList,HashMap,LinkedHashMap,HashSet,Queue ...
- 并发编程之 SynchronousQueue 核心源码分析
前言 SynchronousQueue 是一个普通用户不怎么常用的队列,通常在创建无界线程池(Executors.newCachedThreadPool())的时候使用,也就是那个非常危险的线程池 ^ ...
- HashMap的结构以及核心源码分析
摘要 对于Java开发人员来说,能够熟练地掌握java的集合类是必须的,本节想要跟大家共同学习一下JDK1.8中HashMap的底层实现与源码分析.HashMap是开发中使用频率最高的用于映射(键值对 ...
- Android版数据结构与算法(五):LinkedHashMap核心源码彻底分析
版权声明:本文出自汪磊的博客,未经作者允许禁止转载. 上一篇基于哈希表实现HashMap核心源码彻底分析 分析了HashMap的源码,主要分析了扩容机制,如果感兴趣的可以去看看,扩容机制那几行最难懂的 ...
- iOS 开源库系列 Aspects核心源码分析---面向切面编程之疯狂的 Aspects
Aspects的源码学习,我学到的有几下几点 Objective-C Runtime 理解OC的消息分发机制 KVO中的指针交换技术 Block 在内存中的数据结构 const 的修饰区别 block ...
- Java内存管理-掌握类加载器的核心源码和设计模式(六)
勿在流沙筑高台,出来混迟早要还的. 做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 上一篇文章介绍了类加载器分类以及类加载器的双亲委派模型,让我们能够从整体上对类加载器有 ...
随机推荐
- sqlAlchemy语法增删改查
更多参见:https://www.cnblogs.com/tangpg/p/8528835.html?tdsourcetag=s_pcqq_aiomsg sqlalchemy-查询 User这个类创建 ...
- Java中常见的锁分类以及对应特点
对于 Java 锁的分类没有严格意义的规则,我们常说的分类一般都是依据锁的特性.锁的设计.锁的状态等进行归纳整理的,所以常见的分类如下: 公平锁和非公平锁:公平锁是多线程按照锁申请的顺序获取锁,非公平 ...
- C++ 仿函数
先考虑一个简单的例子:假设有一个vector<string>,你的任务是统计长度小于5的string的个数,如果使用count_if函数的话,你的代码可能长成这样: 1 bool Leng ...
- sort和uniq去重操作【转】
去除重复行 sort file |uniq 查找非重复行 sort file |uniq -u 查找重复行 sort file |uniq -d 统计 sort file | uniq - ...
- python打印朱莉娅集合
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt # 複素数列の計算回数を出力する関数loopmax ...
- 题解-bzoj4320 Homework
Problem bzoj4320 Solution 前置技能:分块+线段树+卡常+一点小小的数学知识 考试时A的 这种题无论怎么处理总有瓶颈,套路分块,设\(k\)以下的插入时直接暴力预处理,查询时直 ...
- 发布自己的类库到NuGet
NuGet是一个为大家所熟知的Visual Studio扩展,通过这个扩展,开发人员可以非常方便地在Visual Studio中安装或更新项目中所需要的第三方组件,同时也可以通过NuGet来安装一些V ...
- This Product is covered by one or more of the following......的问题
DELL台式机安装ubuntu后无法正常启动,黑屏显示:This Product is covered by one or more of the following...... 解决方案:进入BIO ...
- c 中打印格式%g
C语言中打印float或double类型最常用的是%f格式,最近看书时看到有使用%g格式打印. %f 表示按浮点数的格式打印. 小数点后固定6位 %e 表示以指数形式的浮点数格式输出. %g 表示自 ...
- luci 中require函数包含的路径
在 lua 脚本中常用的包含某个文件就是 require 函数. 例如: #!/usr/bin/lua // 表明使用的是lua脚本,像shell脚本一样 lo ...