060 SparkStream 的wordcount示例
1.SparkStream
入口:StreamingContext
抽象:DStream
2.SparkStreaming内部原理
当一个批次到达的时候,会产生一个rdd,这个rdd的数据就是这个批次所接收/应该处理的数据内容,内部具体执行是rdd job的调度
batchDuration: 产生RDD的间隔时间(定时任务,间隔给定时间后会生产一个RDD),产生的RDD会缓存到一个Map<Time, RDD>;RDD的调度当集合中有一个rdd的time时间超过当前时间的时候(>=),对应的rdd被触发操作
一:安装nc
1.说明
netcat(nc)是一个简单而有用的工具,被誉为网络安全界的“瑞士均道”。
不仅可以通过使用TCP或UDP协议的网络连接读写数据,同时还是一个功能强大的网络调试和探测工具,能够建立你需要的几乎所有类型的网络连接。
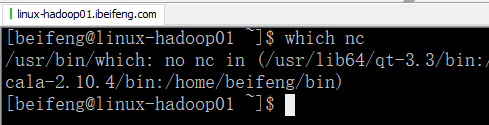
2.检测nc
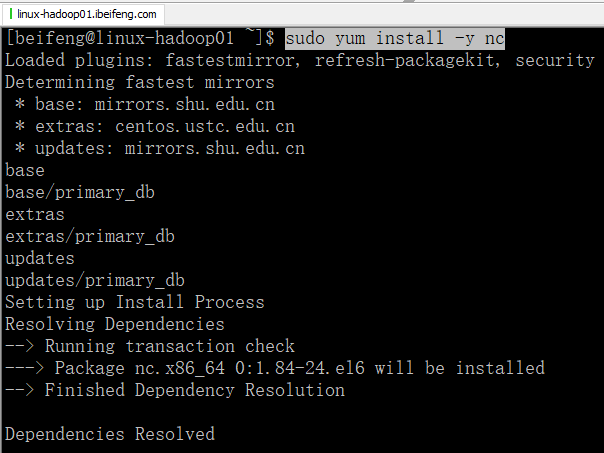
3.安装
sudo yum install -y nc
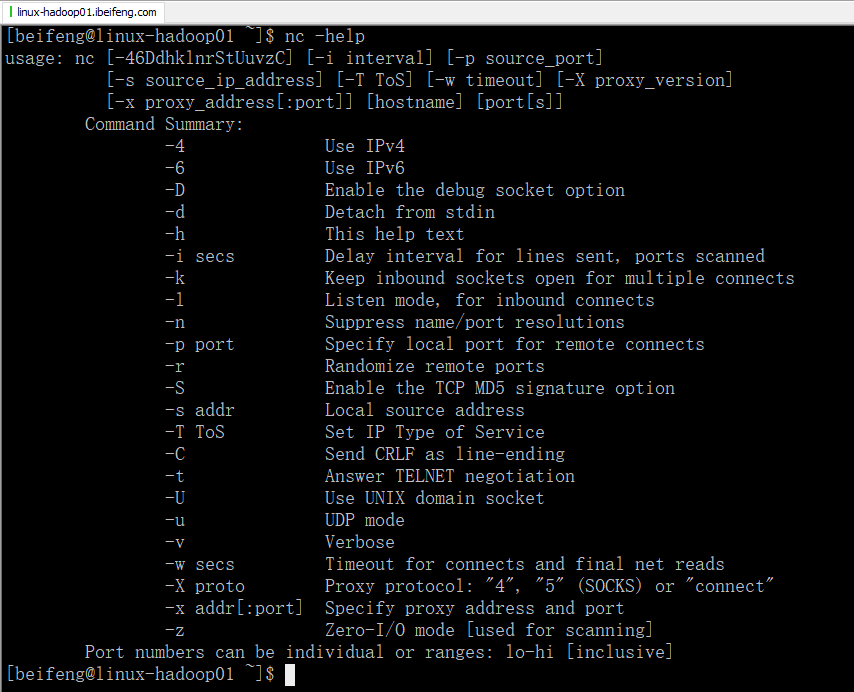
4.检查是否可以使用
5.使用数据进行测试
在一个终端输入数据:

6.解决问题
因为,这里安装了高版本的nc,centos在6.4不适合nc。
不建议使用nc这种yum的方式。
7.卸载
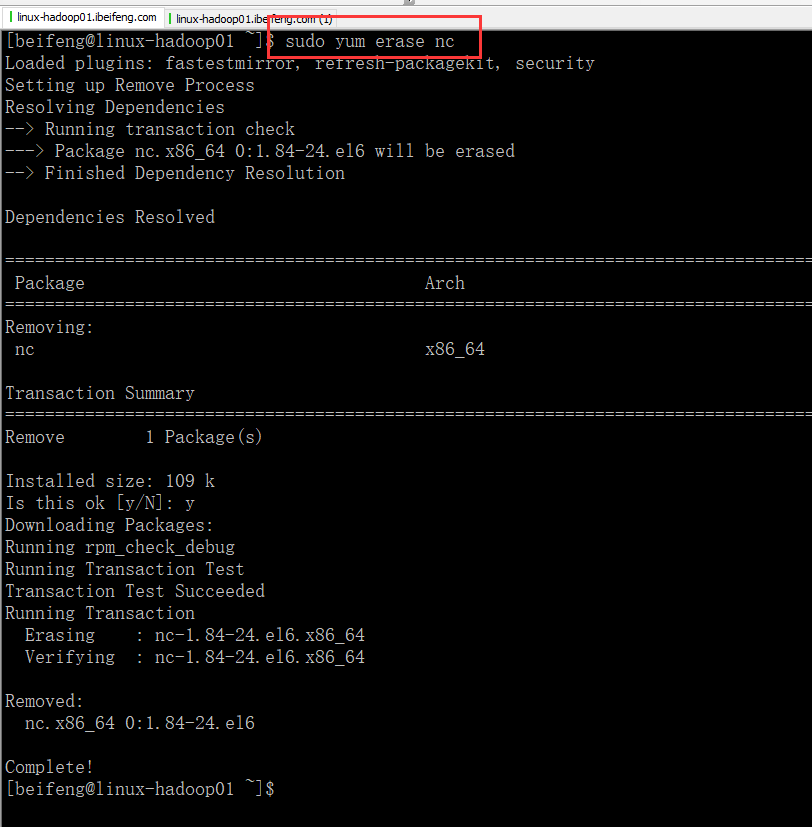
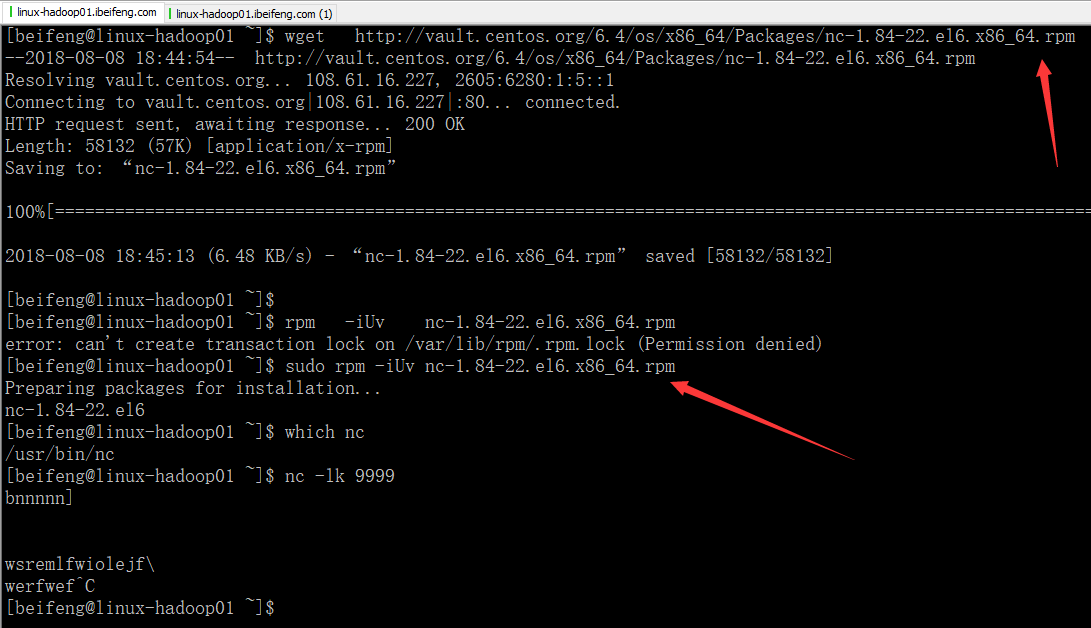
8.重新安装
下载合适的版本
wget http://vault.centos.org/6.4/os/x86_64/Packages/nc-1.84-22.el6.x86_64.rpm
rpm -iUv nc-1.84-22.el6.x86_64.rpm
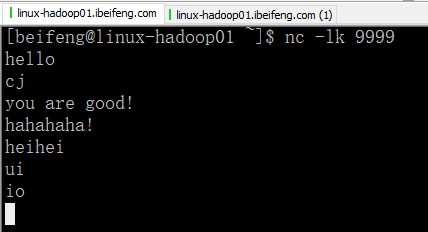
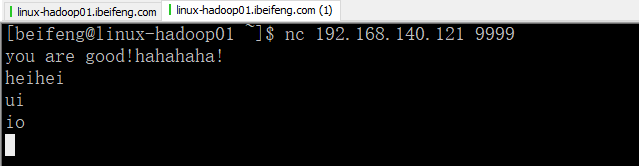
9.测试接受数据
发送:
接收:
10.yum install nc.x86_64
这样下载的nc版本是nc-1.84-24.e
版本还是高,和直接yum install nc的版本一样。
二:程序
1.程序
package com.stream.it
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkStreamWordcount {
def main(args: Array[String]): Unit = {
val conf=new SparkConf()
.setAppName("spark-streaming-wordcount")
.setMaster("local[*]")
val sc=SparkContext.getOrCreate(conf)
val ssc=new StreamingContext(sc,Seconds(15))
val hostname="linux-hadoop01.ibeifeng.com"
val port=9999
val dstream=ssc.socketTextStream(hostname,port)
/**
* 80%的RDD上的方法可以在DStream上直接使用
*/
val resultWordcount=dstream
.filter(line=>line.nonEmpty)
.flatMap(line=>line.split(" ").map((_,1)))
.reduceByKey(_+_)
resultWordcount.foreachRDD(rdd=>{
rdd.foreachPartition(iter=>iter.foreach(println))
})
//启动
ssc.start()
//等到
ssc.awaitTermination()
}
}
2.发送数据
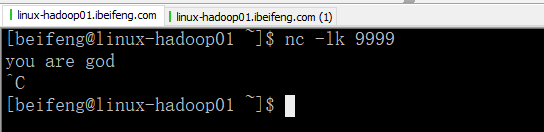
3.控制台

060 SparkStream 的wordcount示例的更多相关文章
- WordCount示例深度学习MapReduce过程(1)
我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测试Hadoop安装是否成功.在终端中用命令创建一个文件夹,简单的向两个文件中各写入一段话,然后运行Hadoop,Wou ...
- WordCount示例深度学习MapReduce过程
转自: http://blog.csdn.net/yczws1/article/details/21794873 . 我们都安装完Hadoop之后,按照一些案例先要跑一个WourdCount程序,来测 ...
- hadoop学习第三天-MapReduce介绍&&WordCount示例&&倒排索引示例
一.MapReduce介绍 (最好以下面的两个示例来理解原理) 1. MapReduce的基本思想 Map-reduce的思想就是“分而治之” Map Mapper负责“分”,即把复杂的任务分解为若干 ...
- MapReduce 编程模型 & WordCount 示例
学习大数据接触到的第一个编程思想 MapReduce. 前言 之前在学习大数据的时候,很多东西很零散的做了一些笔记,但是都没有好好去整理它们,这篇文章也是对之前的笔记的整理,或者叫输出吧.一来是加 ...
- 九、sparkStream的scala示例
简介 sparkStream官网:http://spark.apache.org/docs/latest/streaming-programming-guide.html#overview spark ...
- Storm入门(四)WordCount示例
一.关联代码 使用maven,代码如下. pom.xml 和Storm入门(三)HelloWorld示例相同 RandomSentenceSpout.java /** * Licensed to t ...
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- 初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
- Erlang基础 -- 介绍 -- Wordcount示例演示
在前两个blog中,已经说了Erlang的历史.应用场景.特点,这次主要演示一个Wordcount的示例,就是给定一个文本文件,统计这个文本文件中的单词以及该单词出现的次数. 今天和群友们讨论了一个问 ...
随机推荐
- 什么是java序列化,如何实现java 序列化?
序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化. 可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间.序列化是为了解决在对对象流进行读写操作时所引发的问题. ...
- 用sqlplus为oracle创建用户和表空间
用Oracle自带的企业管理器或PL/SQL图形化的方法创建表空间和用户以及分配权限是相对比较简单的, 本文要介绍的是另一种方法就是使用Oracle所带的命令行工具SQLPLUS来创建表空间. 打开S ...
- Confluence 6 隐藏人员目录
人员目录提供了你 Confluence 中所有用户的列表. 如果你希望禁用人员目录,请在你应用程序命令行中的 Configuring System Properties 进行设置. 希望为匿名用户禁用 ...
- Java并发编程基础-线程安全问题及JMM(volatile)
什么情况下应该使用多线程 : 线程出现的目的是什么?解决进程中多任务的实时性问题?其实简单来说,也就是解决“阻塞”的问题,阻塞的意思就是程序运行到某个函数或过程后等待某些事件发生而暂时停止 CPU 占 ...
- LeetCode(107): 二叉树的层次遍历 II
Easy! 题目描述: 给定一个二叉树,返回其节点值自底向上的层次遍历. (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历) 例如:给定二叉树 [3,9,20,null,null,15,7], ...
- Laravel 中通过自定义分页器分页方法实现伪静态分页链接以利于 SEO
我们知道,Laravel 自带的分页器方法包含 simplePaginate 和 paginate 方法,一个返回不带页码的分页链接,另一个返回带页码的分页链接,但是这两种分页链接页码都是以带问号的动 ...
- java方法重载和重写
1.java的方法重载和重写,表示两种不同的类型.this关键字,出现在类的构造方法中,代表使用该构造方法所创建的对象.,this可以出现在实例方法中核构造方法中.但是不能出现在类方法中.实例方法只能 ...
- hdu4370 dijkstra矩阵转单向边最短路矩阵+自环闭环
/* 矩阵太神奇了Orz,网上的题解大多是spfa,不过我发想dijkstra也能做 把n*n的矩阵看成是单向边距离矩阵就行 */ #include<iostream> #include& ...
- Friends number
问题 : Friends number 时间限制: 1 Sec 内存限制: 128 MB 题目描述 Paula and Tai are couple. There are many stories ...
- vue-cli3.0 使用postcss-plugin-px2rem(推荐)和 postcss-pxtorem(postcss-px2rem)自动转换px为rem 的配置方法;
如何在vue-cli3.0中使用postcss-plugin-px2rem 插件 插件的作用是 自动将vue项目中的px转换为rem . 为什么这三个中要推荐 postcss-plugin-px2r ...