路飞学城-Python开发集训-第4章
学习心得:
学习笔记:
在python中一个py文件就是一个模块
模块好处:
1、提高可维护性
2、可重用
3、避免函数名和变量名冲突
模块分为三种:
1、内置标准模块(标准库),查看所有自带和第三方模块总数的方法:help("modules"),带下划线的是系统调用的,我们用的主要是不带下划线的。
2、第三方开源模块,可通过pip install 模块名 联网安装
3、自定义模块
模块调用:
import module
from module import xx
from xx.xx import xx as rename
from module.xx .xx import *
-------------------------------------------------------------------------------------------------------------
import module #会解释整个module
from module import method #会解释整个module,但只引入方法
from package import module #会解释整个module
from package.module import method #会解释整个module,但只引入方法
import package #只执行package下的__init__方法,并不解释包下的所有模块。
注意:模块一旦被调用,即相当于执行了另外一个py文件里面的代码
python找模块的时候会有一些路径,这个路径可以用sys.path显示出来
import sys
>>>sys.path #输出结果:['', 'C:\\Python\\Python35\\lib\\site-packages\\pytz-2018.3-py3.5.egg', 'C:\\Python\\Python35\\lib\\
site-packages\\pip-10.0.1-py3.5.egg', 'C:\\Python\\Python35\\python35.zip', 'C:\\Python\\Python35\\D
LLs', 'C:\\Python\\Python35\\lib', 'C:\\Python\\Python35', 'C:\\Python\\Python35\\lib\\site-packages
'] #第一个空表示当前目录,最后一个site-packages是放标准和第三方模块的地方。
https://pypi.python.org/pypi
下载安装第三方模块:
>>> python setup.py build #setup.py是模块包的中文件名称
>>> python setup.py intall
包和文件夹:
在python2中只能从包导入,如果是从文件夹导入会报错。
python3对此做了优化,从文件夹也可以导入模块。
只有入口程序所在的目录会加入到sys.path中来,不管里面间接调用多少层,和他们没关系。如何理解?看下面。

假如有这样一个目录结构,现在从manage.py进入程序,在manage.py文件中通过from crm import views.py,如果在views.py中想要引入proj下面的settings.py,要怎么引入呢?通过from proj import settings.py,为什么可以这样?views.py和proj不在同一个目录,sys.path中也没这个路径啊,程序是怎么找到proj这个包的呢?其实这块就验证了上面那句话,只有入口程序所在的目录会加入到sys.path中来,而在入口程序中调用其它py文件,其它Py文件再调用另外其它py文件,都是按照这个sys.path路径来查找的。这才是上面问题的本质。因为这个原因,所以项目的入口程序都是放在程序的根目录下的,这样就能很方便的调用所有模块了。
1、从views.py开始运行,在views.py文件中导入proj中的settings.py,实现如下:
import sys,os print(dir())
print(__file__) #my_proj\crm\views.py 显示的路径是从python执行的当前位置开始往后的路径
#也就是说__file__就是这样一个相对路径。 BASE_DIR = os.path.dirname(os.path.dirname(__file__)) #这块的path是os模块的方法,不是sys的
print(BASE_DIR) #my_proj 往上走了两层,获得了当前文件的目录的目录路径,但还是相对路径 BASE_DIR =os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
#注意BASE_DIR中只用到了os.path的方法,没有用到sys,这样得到的就是整个绝对路径。
print(BASE_DIR) #C:\Users\Lowry\PycharmProjects\lufyy\my_proj sys.path.append(BASE_DIR) #将BASE_DIR加入到sys.path中 from proj import settings #至此跨模块导入模块就实现了 def sayhi():
print("hello world")
2、从manage.py开始运行程序,如何在views.py中引入module.py模块?
#第一种方法:
from crm import module
#此种方法每次只能从最外层往里面找,试想里面不是一层而是10层呢?那么from后面就是crm.xx.xx.xx.xx直到views.py所在层。 #第二种方法:
from . import module # 这个.代表当前文件目录
3、

第二句的意思是相对路径回到的目录不能是程序入口的那个目录,如果是,则报错。
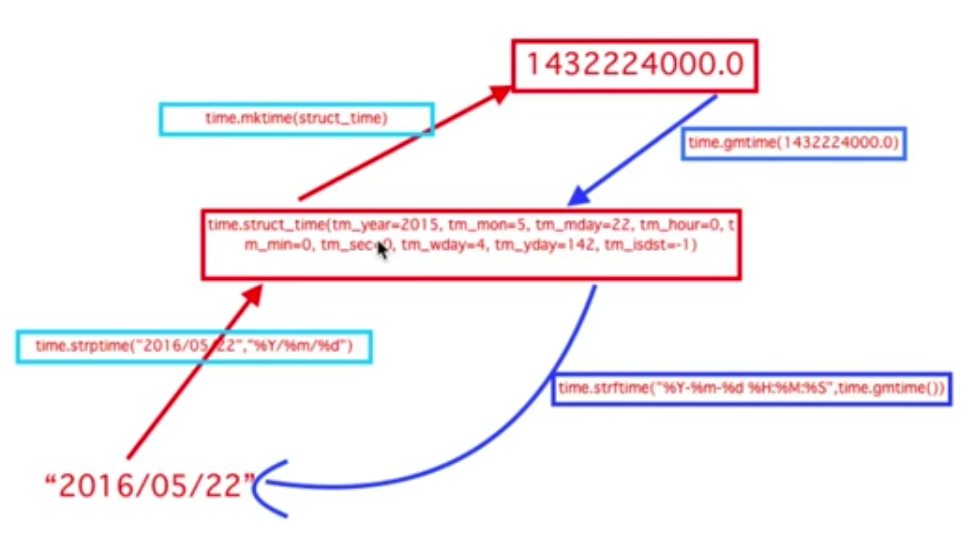
time模块:
import time print(time.localtime()) #拿到的是当前系统时间对象,随系统时间改变而改变。
print(time.mktime(time.localtime())) #将struct_time转换为时间戳
os模块:用于和系统进行交互用的
序列化模块:序列化是指把内存的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes
把字符串转成内存数据类型叫反序列化
只把数据类型转成字符串存到内存里的意义?
json.dumps json.loads
1、把内存数据通过网络共享给远程其它人
2、定义了不同语言之间的交互规则
1、纯文本,坏处,不能共享复杂的数据类型
2、xml,坏处,占空间大
3、json,简单,可读性好
json
支持str、int、tuple、dict、list
pickle
支持python里的所有数据类型
只能在Python里面使用
shelve模块:之前的json和pickle都只能dump和load一次,但这个模块可以dmup和load多次,他是通过对pickle封装得来的,所以只能在python中使用。
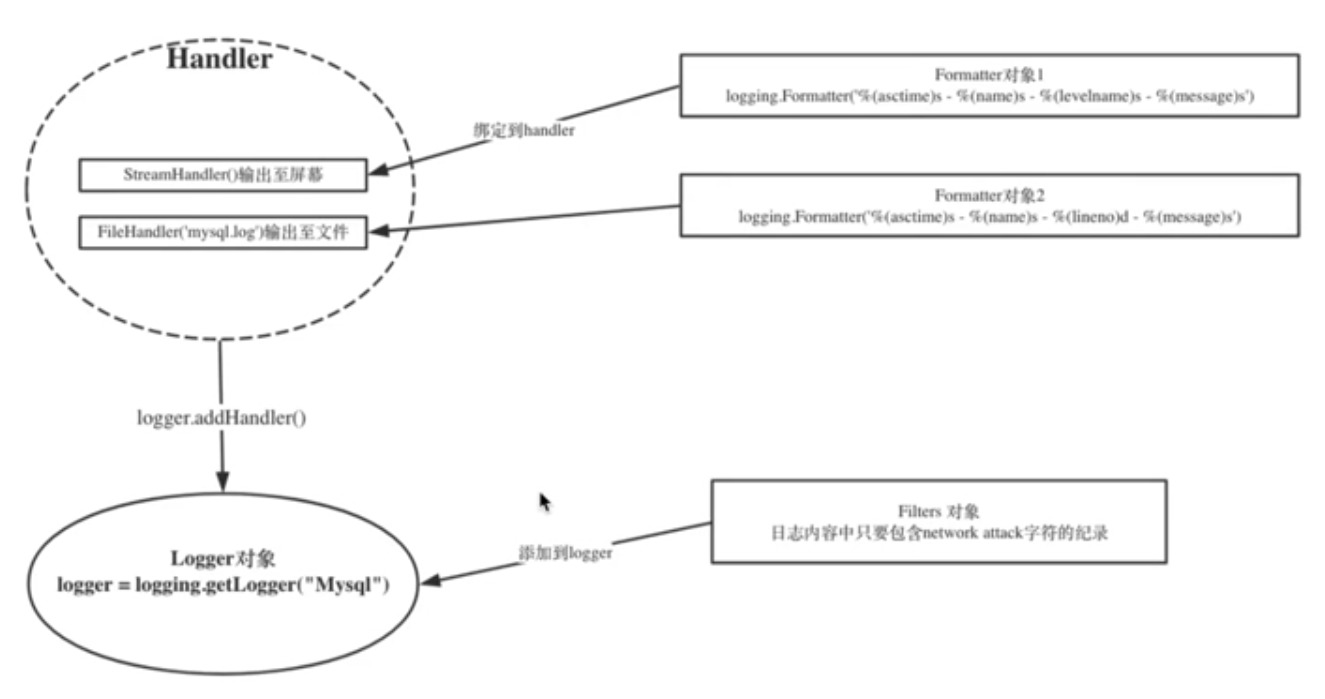
logging模块
日志同时输出到屏幕和文件:
python使用logging模块记录日志涉及四个主要类,使用官方文档中的概括最为合适:
logger提供了应用程序可以直接使用的接口;
handler将(logger创建的)日志记录发送到合适的目的输出;
filter提供了细度设备来决定输出哪条日志记录;
fromatter决定日志记录的最终输出格式
路飞学城-Python开发集训-第4章的更多相关文章
- 路飞学城-Python开发集训-第1章
学习体会: 在参加这次集训之前我自己学过一段时间的Python,看过老男孩的免费视频,自我感觉还行,老师写的代码基本上都能看懂,但是实际呢?....今天是集训第一次交作业的时间,突然发现看似简单升级需 ...
- 路飞学城-Python开发集训-第3章
学习心得: 通过这一章的作业,使我对正则表达式的使用直接提升了一个level,虽然作业完成的不怎么样,重复代码有点多,但是收获还是非常大的,有点找到写代码的感觉了,遗憾的是,这次作业交过,这次集训就结 ...
- 路飞学城-Python开发集训-第2章
学习心得: 这章对编码的讲解超级赞,现在对于编码终于有一点认知了,但还没有大彻大悟,还需要更加细心的琢磨一下Alex博客和视频,以前真的是被编码折磨死了,因为编码的问题而浪费的时间很多很多,现在终于感 ...
- 路飞学城-Python开发集训-第5章
面向过程:核心是过程二字,过程是解决问题的步骤,相当于设计一条流水线,是机械式的思维方式 优点:复杂的问题流程化,进而简单化 缺点:可扩展性差 面向对象:核心是对象二字,对象就是特征与技能的结合体. ...
- 路飞学城-Python爬虫集训-第三章
这个爬虫集训课第三章的作业讲得是Scrapy 课程主要是使用Scrapy + Redis实现分布式爬虫 惯例贴一下作业: Python爬虫可以使用Requests库来进行简单爬虫的编写,但是Reque ...
- 路飞学城-Python开发-第一章
# 基础需求: # 让用户输入用户名密码 # 认证成功后显示欢迎信息 # 输错三次后退出程序 username = 'pandaboy' password = ' def Login(username ...
- 路飞学城-Python爬虫集训-第一章
自学Python的时候看了不少老男孩的视频,一直欠老男孩一个会员,现在99元爬虫集训果断参与. 非常喜欢Alex和武Sir的课,技术能力超强,当然讲着讲着就开起车来也说明他俩开车的技术也超级强! 以上 ...
- 路飞学城-Python爬虫集训-第二章
本次爬虫集训的第二次作业是web微信. 先贴一下任务: 作业中使用到了Flask. Flask是一个使用 Python 编写的轻量级 Web 应用框架.其 WSGI 工具箱采用 Werkzeug ,模 ...
- 路飞学城-Python开发-第二章
''' 数据结构: menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{}, '网易':{}, 'google':{} }, '中关村':{ '爱奇艺':{}, '汽车之家' ...
随机推荐
- MR程序本地调试,提交到集群运行
在本地调试,提交到集群上运行. 在本地程序中的Configuration中添加如下配置: Configuration conf = new Configuration(); conf.set(&quo ...
- angular分页插件tm.pagination 解决触发二次请求的问题
angular分页插件tm.pagination(解决触发二次请求的问题) DEMO: http://jqvue.com/demo/tm.pagination/index.html#?current ...
- Linux禁止ping以及开启ping的方法
---恢复内容开始--- Linux默认是允许Ping响应的,系统是否允许Ping由2个因素决定的:A.内核参数,B.防火墙,需要2个因素同时允许才能允许Ping,2个因素有任意一个禁Ping就无法P ...
- LVS + HAProxy实现跨网负载均衡
- LockSupport的源码实现原理以及应用
一.为什么使用LockSupport类 如果只是LockSupport在使用起来比Object的wait/notify简单, 那还真没必要专门讲解下LockSupport.最主要的是灵活性. 上边的例 ...
- <自动化测试方案_6>第六章、API自动化测试
第六章.API自动化测试 (一)工具实现 目前大众接口测试的工具有:Postman.SoupUI.jmeter他们的特点介绍有人做个宏观的研究,这里进行引用:https://blog.csdn.net ...
- Android-textview图文混排(网络图片)
工作太忙,不做过多的解释了,核心是用到了 SpannableStringBuilder Glide 和 Rxjava 直接上代码了,就两个类. public class ImageSpanAsyn ...
- MySQL 基本语句(2)
1.创建数据库 :create database 名称 [charset 字符集 collate 校对规则] ; 如: drop database if exists `mydb` ; # 若存在就 ...
- 机器学习之EM算法(五)
摘要 EM算法全称为Expectation Maximization Algorithm,既最大期望算法.它是一种迭代的算法,用于含有隐变量的概率参数模型的最大似然估计和极大后验概率估计.EM算法经常 ...
- SQL server 导出平面文件时出错: The code page on Destination - 3_txt.Inputs[Flat File Destination Input].Columns[UserId] is 936 and is required to be 1252.
我在导出平面文件时:Error 0xc00470d4: Data Flow Task 1: The code page on Destination - 3_txt.Inputs[Flat File ...