ML.NET 示例:聚类之客户细分
写在前面
准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正。
如果有朋友对此感兴趣,可以加入我:https://github.com/feiyun0112/machinelearning-samples.zh-cn
客户细分-聚类示例
| ML.NET 版本 | API 类型 | 状态 | 应用程序类型 | 数据类型 | 场景 | 机器学习任务 | 算法 |
|---|---|---|---|---|---|---|---|
| v0.7 | 动态 API | 最新版 | 控制台应用程序 | .csv 文件 | 客户细分 | 聚类 | K-means++ |
问题
您想要识别具有相似概况的客户组,以便以后对他们准确定位(例如每个具有相似特征的已识别客户组进行不同的营销活动,等等)。
要解决的问题是,如何识别具有相似概况和兴趣的不同客户组,而无需任何预先存在的类别列表。你在分类列表中不分类客户,因为你的客户没有被标记所以你不能这样做。您只需要建立一组/几组客户,然后公司会将其用于其他业务目的。
数据集
在当前示例中,要处理的数据来自“The Wine Company”。这些数据基本上是该公司过去提供的报价/交易(营销活动的一部分)的历史记录,加上客户购买的历史记录。
训练数据集位于assets/inputs 文件夹中,并且拆分成两个文件。优惠文件包含有关特定优惠/优惠的过去营销活动的信息:
| Offer # | Campaign | Varietal | Minimum Qty (kg) | Discount (%) | Origin | Past Peak |
|---|---|---|---|---|---|---|
| 1 | January | Malbec | 72 | 56 | France | FALSE |
| 2 | January | Pinot Noir | 72 | 17 | France | FALSE |
| 3 | February | Espumante | 144 | 32 | Oregon | TRUE |
| 4 | February | Champagne | 72 | 48 | France | TRUE |
| 5 | February | Cabernet Sauvignon | 144 | 44 | New Zealand | TRUE |
交易文件包含有关客户购买的信息(与上述优惠相关):
| Customer Last Name | Offer # |
|---|---|
| Smith | 2 |
| Smith | 24 |
| Johnson | 17 |
| Johnson | 24 |
| Johnson | 26 |
| Williams | 18 |
该数据集来自John Foreman的书籍[Data Smart](http://www.john-foreman.com/data-smart-book.html)。
ML 任务 - 聚类
解决此类问题的ML任务称为聚类。
通过应用聚类技术,您将能够识别类似的客户并将他们分组在集群中,而无需预先存在的类别和历史标记/分类数据。聚类是识别一组“相关或类似事物”的好方法,而无需任何预先存在的类别列表。这正是聚类和分类之间的主要区别。
在当前示例中用于这个任务的算法是K-Means。简而言之,该算法将数据集的样本分配给k簇:
- K-Means 不计算最佳簇数,因此这是一个算法参数
- K-Means 最小化每个点与群集的质心(中点)之间的距离
- 属于群集的所有点都具有相似的属性(但这些属性不一定直接映射到用于训练的特征,并且通常是进一步数据分析的目标)
使用群集绘制图表可帮助您直观地确定哪些群集的数据更适合您的数据,具体取决于您可以识别每个群集的隔离程度。 确定群集数量后,可以使用首选名称命名每个群集,并将每个客户群组/群集用于任何业务目的。
下图显示了集群数据分布的示例,然后,k-Means如何能够重新构建数据集群。
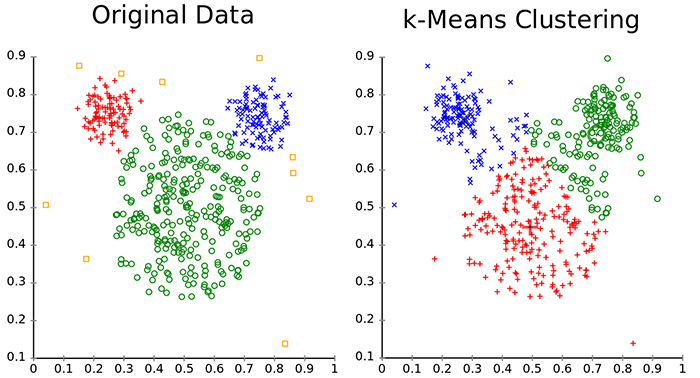
从上图中可以看出,有一个问题是:我们如何在二维空间中绘制由不同特征形成的样本? 这是一个被称为“降维”的问题:每个样本属于由他的每个特征(提供,活动等)形成的维度空间,因此我们需要一个将前一个空间的观察“翻译”到另一个空间的功能(通常 在我们的例子中,功能少得多,只有两个:X和Y)。 在这种情况下,我们将使用一种称为PCA的通用技术,但是存在类似的技术,例如可以用于相同目的的SVD。
要解决这个问题,首先我们将建立一个ML模型。 然后,我们将在现有数据上训练模型,评估其有多好,最后我们将使用该模型将客户分类为集群。

1. 建立模型
数据预处理
首先要做的是将数据加入到单个视图中。 因为我们需要比较用户进行的交易,我们将构建一个数据透视表,其中行是客户,列是活动,单元格值显示客户是否在该活动期间进行了相关事务。
数据透视表是执行PreProcess函数构建的,在本例中,PreProcess函数是通过将文件数据加载到内存中并使用Linq来join数据实现的。但您可以根据数据的大小使用任何其他方法,例如关系数据库或任何其他方法:
// inner join datasets
var clusterData = (from of in offers
join tr in transactions on of.OfferId equals tr.OfferId
select new
{
of.OfferId,
of.Campaign,
of.Discount,
tr.LastName,
of.LastPeak,
of.Minimum,
of.Origin,
of.Varietal,
Count = 1,
}).ToArray();
// pivot table (naive way)
var pivotDataArray =
(from c in clusterData
group c by c.LastName into gcs
let lookup = gcs.ToLookup(y => y.OfferId, y => y.Count)
select new PivotData()
{
C1 = (float)lookup["1"].Sum(),
C2 = (float)lookup["2"].Sum(),
C3 = (float)lookup["3"].Sum(),
// ...
};
数据被保存到pivot.csv文件中,看起来像下面的表:
| C1 | C2 | C3 | C4 | C5 | C6 | C8 | C9 | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | C18 | C19 | C20 | C21 | C22 | C23 | C24 | C25 | C26 | C27 | C28 | C29 | C30 | C31 | C32 | LastName |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
模型管道
下面是用于建立模型的代码:
//Create the MLContext to share across components for deterministic results
MLContext mlContext = new MLContext(seed: 1); //Seed set to any number so you have a deterministic environment
// STEP 1: Common data loading configuration
TextLoader textLoader = mlContext.Data.TextReader(new TextLoader.Arguments()
{
Separator = ",",
HasHeader = true,
Column = new[]
{
new TextLoader.Column("Features", DataKind.R4, new[] {new TextLoader.Range(0, 31) }),
new TextLoader.Column("LastName", DataKind.Text, 32)
}
});
var pivotDataView = textLoader.Read(pivotCsv);
//STEP 2: Configure data transformations in pipeline
var dataProcessPipeline = new PrincipalComponentAnalysisEstimator(mlContext, "Features", "PCAFeatures", rank: 2)
.Append(new OneHotEncodingEstimator(mlContext, new[] { new OneHotEncodingEstimator.ColumnInfo("LastName",
"LastNameKey",
OneHotEncodingTransformer.OutputKind.Ind) }));
//STEP 3: Create the training pipeline
var trainer = mlContext.Clustering.Trainers.KMeans("Features", clustersCount: 3);
var trainingPipeline = dataProcessPipeline.Append(trainer);
在本例中, TextLoader不显式地定义每一列,而是定义由文件的前32列构成的Features属性;并将最后一列的值定义为LastName属性。
然后,您需要对数据应用一些转换:
使用评估器
PrincipalComponentAnalysisEstimator(mlContext, "Features", "PCAFeatures", rank: 2)添加PCA列,传递参数rank: 2,这意味着我们将特征从32维减少到2维(x和y)使用
OneHotEncodingEstimator转换LastName添加KMeansPlusPlusTrainer; 与该学习器一起使用的主要参数是
clustersCount,它指定了簇的数量
2. 训练模型
在构建管道之后,我们通过使用所选算法拟合或使用训练数据来训练客户细分模型:
ITransformer trainedModel = trainingPipeline.Fit(pivotDataView);
3. 评估模型
我们评估模型的准确性。 使用ClusteringEvaluator测量此准确度,并显示Accuracy和AUC 指标。
var predictions = trainedModel.Transform(pivotDataView);
var metrics = mlContext.Clustering.Evaluate(predictions, score: "Score", features: "Features");
最后,我们使用动态API将模型保存到本地磁盘:
//STEP 6: Save/persist the trained model to a .ZIP file
using (var fs = new FileStream(modelZip, FileMode.Create, FileAccess.Write, FileShare.Write))
mlContext.Model.Save(trainedModel, fs);
运行模型训练
在Visual Studio中打开解决方案后,第一步是创建客户细分模型。 首先将项目CustomerSegmentation.Train设置为Visual Studio中的启动项目,然后单击F5。 将打开一个控制台应用程序,它将创建模型(并保存在assets/output文件夹中)。 控制台的输出类似于以下屏幕截图:
4. 使用模型
在CustomerSegmentation.Predict项目中使用在上一步中创建的模型用于项目“CustomerSegmentation.Predict”。 基本上,我们加载模型,然后加载数据文件,最后我们调用Transform来对数据执行模型。
在本例中,模型不是用来预测任何值(如回归任务)或对任何事物进行分类(如分类任务),而是基于客户的信息构建可能的集群/组。
下面的代码是如何使用模型创建这些集群:
var reader = new TextLoader(_mlContext,
new TextLoader.Arguments
{
Column = new[] {
new TextLoader.Column("Features", DataKind.R4, new[] {new TextLoader.Range(0, 31) }),
new TextLoader.Column("LastName", DataKind.Text, 32)
},
HasHeader = true,
Separator = ","
});
var data = reader.Read(new MultiFileSource(_pivotDataLocation));
//Apply data transformation to create predictions/clustering
var predictions = _trainedModel.Transform(data)
.AsEnumerable<ClusteringPrediction>(_mlContext, false)
.ToArray();
此外,方法SaveCustomerSegmentationPlotChart()使用OxyPlot库保存绘制每个分配集群中的样本的散点图。
运行模型并识别集群
要运行前面的代码,在Visual Studio中将 CustomerSegmentation.Predict项目设置为启动项目,然后点击F5。
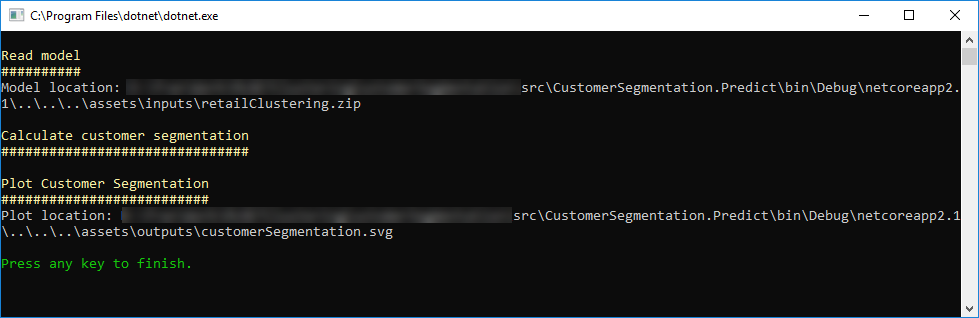
在执行预测控制台应用程序之后,将生成绘图到assets/output文件夹中,显示集群分布(类似于下图):

在该图表中,您可以识别3个群集。 在本例中,其中两个更好地分化(蓝色中的簇1和绿色中的簇2)。 但是,群集号3仅部分区分,部分客户与集群号码2重叠,这也可能发生在客户组中。
ML.NET 示例:聚类之客户细分的更多相关文章
- ML.NET教程之客户细分(聚类问题)
理解问题 客户细分需要解决的问题是按照客户之间的相似特征区分不同客户群体.这个问题的先决条件中没有可供使用的客户分类列表,只有客户的人物画像. 数据集 已有的数据是公司的历史商业活动记录以及客户的购买 ...
- ML.NET 示例:开篇
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- ML.NET 示例:目录
ML.NET 示例中文版:https://github.com/feiyun0112/machinelearning-samples.zh-cn 英文原版请访问:https://github.com/ ...
- ML.NET 示例:回归之销售预测
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- 数据挖掘应用案例:RFM模型分析与客户细分(转)
正好刚帮某电信行业完成一个数据挖掘工作,其中的RFM模型还是有一定代表性,就再把数据挖掘RFM模型的建模思路细节与大家分享一下吧!手机充值业务是一项主要电信业务形式,客户的充值行为记录正好满足RFM模 ...
- RFM模型的应用 - 电商客户细分(转)
RFM模型是网点衡量当前用户价值和客户潜在价值的重要工具和手段.RFM是Rencency(最近一次消费),Frequency(消费频率).Monetary(消费金额) 消费指的是客户在店铺消费最近一次 ...
- ML.NET 示例:聚类之鸢尾花
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- ML.NET 示例:推荐之场感知分解机
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
- ML.NET 示例:推荐之One Class 矩阵分解
写在前面 准备近期将微软的machinelearning-samples翻译成中文,水平有限,如有错漏,请大家多多指正. 如果有朋友对此感兴趣,可以加入我:https://github.com/fei ...
随机推荐
- wap2app(十)--wap2app 添加原生底部导航,添加原生标题栏,填坑
一.添加原生标题栏 添加原生标题栏可以参照 <wap2app(六)-- wap2app的原生标题头无法隐藏>,具体如下: 1.打开 sitemap.json文件 --> page配置 ...
- springboot 常见请求方式
转载请标明出处:http://blog.csdn.net/zhaoyanjun6/article/details/80404645 本文出自[赵彦军的博客] 用户模型类 package com.yib ...
- Apktool(3)——Apktool的使用
一.apktool的作用 安卓应用apk文件不仅仅是包含有resource和编译的java代码的zip文件,如果你尝试用解压工具(如好压)解压后,你将会获得classes.dex和resource.a ...
- mysql之数据备份与恢复
本文内容: 复制文件法 利用mysqldump 利用select into outfile 其它(列举但不介绍) 首发日期:2018-04-19 有些时候,在备份之前要先做flush tables , ...
- Nginx与Nginx-rtmp-module搭建RTMP视频直播和点播服务器
一.开发环境 Nginx地址: http://nginx.org/download/nginx-1.14.2.tar.gz Nginx-rtmp-module地址: https://github.c ...
- sql-server的添加数据库文件(日志数据)以及收缩数据库文件(日志数据)
环境: SSMS sql-server2016 一.为数据库添加数据文件 添加日志数据文件 以下是添加数据文件和日志文件的代码 ALTER DATABASE [joinbest] ADD FILE ( ...
- C#判断文件编码——常用字法
使用中文写文章,当篇幅超过一定程度,必然会使用到诸如:“的”.“你”.“我”这样的常用字.本类思想便是提取中文最常用的一百个字,使用中文世界常用编码(主要有GBK.GB2312.GB18030.UTF ...
- replace函数使用方法
Replace函数的含义~ 用新字符串替换旧字符串,而且替换的位置和数量都是指定的. replace函数的语法格式 =Replace(old_text,start_num,num_chars,new_ ...
- js获取select选中的内容
### 获取select选中的内容 js获取select标签选中的值 var obj = document.getElementById("selectId");//获取selec ...
- [福大软工] Z班 第4次成绩排行榜
作业要求 http://www.cnblogs.com/easteast/p/7511234.html 评分细则 (1)博客--15分,分数组成如下: 随笔开头,给出结队两个同学的学号.PS:结对成员 ...