机器学习笔记-----AP(affinity propagat)算法讲解及matlab实现
大家好,我是人见人爱,花见花开的小花。哈哈~~!
在统计和数据挖掘中,亲和传播(AP)是基于数据点之间"消息传递"概念的聚类算法。与诸如k-means或k-medoids的聚类算法不同,亲和传播不需要在运行算法之前确定或估计聚类的数量。 类似于k-medoids,亲和力传播算法发现"样本",输入集合的成员,输出聚类结果。
一 算法描述
2.1基本介绍
我们让(x1,…xn)作为一系列的数据点,然后用矩阵S代表各个数据点之间的相似度,一般相似度的判断有欧氏距离,马氏距离,汉明距离。如果S(i,k)>S(i,j)则表示i到k的距离比i到j的距离近。其中S(k,k)表示节点k作为k的聚类中心的合适程度,可以理解为,节点k成为聚类中心合适度,在最开始时,这个值是初始化的时候使用者给定的值,会影响到最后聚类的数量。
这个算法通过迭代两个消息传递步骤来进行,以更新下面两个矩阵:
代表(Responsibility)矩阵R:r(i,k)表示第k个样本适合作为第i个样本的类代表点的代表程度。说白了K为男人,i为女人,代表矩阵R表示,这个男人成为i这个女人老公的适合程度。
适选(Availabilities)矩阵A=[a(i,k)]N×N:a(i,k)表示第i个样本选择第k个样本作为类代表样本的适合程度,同理表示i选择K作为自己老公的可能性。当然,这个社会是相对于封建社会有点进步的,比如也会征求女方的意见,但是又有一定弊端,这个男人K可以三妻四妾。所以K这个聚类中心,周围可以有许多样本i。所以有的人叫R矩阵为吸引度矩阵,矩阵A为归属度矩阵也是不无道理的。
2.2 算法的迭代公式

对于代表矩阵r:
假设现在有一个聚类中心K,我们找到另外一个假想的聚类中心k',重新定义K'的代表矩阵和适合矩阵: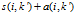 ,找出这两个值相加最大的那一个,在用我们的
,找出这两个值相加最大的那一个,在用我们的 减去这个最大的,就表示这个K的聚类中心对i这个样本的吸引程度。你想想,最大情敌的吸引力都没有我高,那我岂不是最牛叉???
减去这个最大的,就表示这个K的聚类中心对i这个样本的吸引程度。你想想,最大情敌的吸引力都没有我高,那我岂不是最牛叉???
对于适合矩阵a:
我们要明白一个道理,如果一个男人对大部分女人的吸引力都很大,那么这个男人对你这个女人的吸引力的可能性是不是比别人大一点?明白了这个道理。同理如果节点k作为其他节点i'的聚类中心的合适度很大,那么节点k作为节点i的聚类中心的合适度也可能会较大,由此就可以先计算节点k对其他节点的吸引度,r(i',k),然后做一个累加和表示节点k对其他节点的吸引度,得到: 。等等r(k,k)是什么意思呢,一般帅的人是不是都是特别容易自恋?你懂得,所以这个表示样本选择自己作为聚类中心的自恋程度。为了不让这个值过大,影响整体结果,将这个值控制在0以下。当i=k的时候我们选
。等等r(k,k)是什么意思呢,一般帅的人是不是都是特别容易自恋?你懂得,所以这个表示样本选择自己作为聚类中心的自恋程度。为了不让这个值过大,影响整体结果,将这个值控制在0以下。当i=k的时候我们选 就可以了。a(k,k)表示K这个作为聚类中心的能力。
就可以了。a(k,k)表示K这个作为聚类中心的能力。
注意有时候为了防止参数更新时的震动需要引入一个减震参数damping。Damping计算如下:

二 算法实现
function idx = AP(S)
N = size(s,1);
A=zeros(N,N);
R=zeros(N,N); % Initialize messages
lam=0.9; % Set damping factor
same_time = -1;
for iter=1:10000
% Compute responsibilities
Rold=R;
AS=A+S;
[Y,I]=max(AS,[],2);
for i=1:N
AS(i,I(i))=-1000;
end
[Y2,I2]=max(AS,[],2);
R=S-repmat(Y,[1,N]);
for i=1:N
R(i,I(i))=S(i,I(i))-Y2(i);
end
R=(1-lam)*R+lam*Rold; % Dampen responsibilities
% Compute availabilities
Aold=A;
Rp=max(R,0);
for k=1:N
Rp(k,k)=R(k,k);
end
A=repmat(sum(Rp,1),[N,1])-Rp;
dA=diag(A);
A=min(A,0);
for k=1:N
A(k,k)=dA(k);
end;
A=(1-lam)*A+lam*Aold; % Dampen availabilities
if(same_time == -1)
E=R+A;
[tt idx_old] = max(E,[],2);
same_time = 0;
else
E=R+A;
[tt idx] = max(E,[],2);
if(sum(abs(idx_old-idx)) == 0)
same_time = same_time + 1;
if(same_time == 10)
iter
break;
end
end
idx_old = idx;
end
end
E=R+A;
[tt idx] = max(E,[],2);
% figure;
% for i=unique(idx)'
% ii=find(idx==i);
% h=plot(x(ii),y(ii),'o');
% hold on;
% col=rand(1,3);
% set(h,'Color',col,'MarkerFaceColor',col);
% xi1=x(i)*ones(size(ii)); xi2=y(i)*ones(size(ii));
% line([x(ii)',xi1]',[y(ii)',xi2]','Color',col);
% end;
总结:算法讲解部分到这里结束了。谢谢大家,能否走一波关注?哈哈
机器学习笔记-----AP(affinity propagat)算法讲解及matlab实现的更多相关文章
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- 【机器学习笔记之四】Adaboost 算法
本文结构: 什么是集成学习? 为什么集成的效果就会好于单个学习器? 如何生成个体学习器? 什么是 Boosting? Adaboost 算法? 什么是集成学习 集成学习就是将多个弱的学习器结合起来组成 ...
- Stanford机器学习笔记-9. 聚类(K-means算法)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
- 吴恩达机器学习笔记58-协同过滤算法(Collaborative Filtering Algorithm)
在之前的基于内容的推荐系统中,对于每一部电影,我们都掌握了可用的特征,使用这些特征训练出了每一个用户的参数.相反地,如果我们拥有用户的参数,我们可以学习得出电影的特征. 但是如果我们既没有用户的参数, ...
- 吴恩达机器学习笔记55-异常检测算法的特征选择(Choosing What Features to Use of Anomaly Detection)
对于异常检测算法,使用特征是至关重要的,下面谈谈如何选择特征: 异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:
- 机器学习笔记(五) K-近邻算法
K-近邻算法 (一)定义:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别. (二)相似的样本,特征之间的值应该是相近的,使用k-近邻算法需要做标准化处理.否 ...
- [吴恩达机器学习笔记]14降维3-4PCA算法原理
14.降维 觉得有用的话,欢迎一起讨论相互学习~Follow Me 14.3主成分分析原理Proncipal Component Analysis Problem Formulation 主成分分析( ...
- 机器学习笔记—混合高斯和 EM 算法
本文介绍密度估计的 EM(Expectation-Maximization,期望最大). 假设有 {x(1),...,x(m)},因为是无监督学习算法,所以没有 y(i). 我们通过指定联合分布 p( ...
- [机器学习笔记]kNN进邻算法
K-近邻算法 一.算法概述 (1)采用测量不同特征值之间的距离方法进行分类 优点: 精度高.对异常值不敏感.无数据输入假定. 缺点: 计算复杂度高.空间复杂度高. (2)KNN模型的三个要素 kNN算 ...
随机推荐
- ArcGIS Engine开发之空间查询
空间查询功能是通过用户选择的空间几何体以及该几何体与当前地图中要素之间的几何关系进行空间查找,从而得到查询结果的操作. 相关类与接口 空间查询相关的类主要是SpatialFilter类,其实现的接口主 ...
- 在Android中,使用Kotlin的 API请求简易方法
原文标题:API request in Android the easy way using Kotlin 原文链接:http://antonioleiva.com/api-request-kotli ...
- 网络安全——数据的加密与签名,RSA介绍
一. 密码概述 发送者对明文进行加密然后生成密文,接受者再对密文解密得到明文的过程. 现在使用的所有加密算法都是公开的!但是密钥肯定不是公开的. 1 散列(哈希)函数 通常有MD5.SHA1.SHA2 ...
- yii2 ActiveRecord多表关联以及多表关联搜索的实现
作者:白狼 出处:http://www.manks.top/yii2_many_ar_relation_search.html 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明 ...
- EasyUI combobox
高度自适应 data-options="required:true,editable:false,panelHeight:'auto',panelMaxHeight:170" 加上 ...
- ERROR 2003 (HY000): Can't connect to MySQL server on 'ip address' (111)的处理办法
远程连接mysql数据库时可以使用以下指令 mysql -h 192.168.1.104 -u root -p 如果是初次安装mysql,需要将所有/etc/mysql/内的所有配置文件的bind-a ...
- JSP动作元素——————实践篇
本篇在理论的基础上实现不同JSP页面间的跳转 使用 Eclipse Java EE IDE 创建一个新的 Java Web 项目,具体步骤如下: (1)启动 Eclipse Java EE IDE,在 ...
- 一步一步学FRDM-KE02Z(一):IAR调试平台搭建以及OpenSDA两种工作模式设置
摘要:FRDM-KE02Z是飞思卡尔公司较为新的微控制器,学习和开发资料较少.从本篇开始会陆续介绍其相关的开发流程,并完成一个小型的工程项目.这是本系列博客的第一篇,主要介绍开发环境IAR for A ...
- C#组件系列——又一款Excel处理神器Spire.XLS,你值得拥有
前言:最近项目里面有一些对Excel操作的需求,博主想都没想,NPOI呗,简单.开源.免费,大家都喜欢!确实,对于一些简单的Excel导入.导出.合并单元格等,它都没啥太大的问题,但是这次的需求有两点 ...
- Android开发之画图的实现
Android开发之画图的实现 四天前上完安卓的第一节课,真的是一脸懵逼,尽管熊哥说和java是差不多的,然而这个包和那个包之间的那些转换都是些什么鬼呀!!!但是四天的学习和操作下来,我觉得安卓 ...