《机器学习实战》之k-近邻算法(示例)
看了这本书的第一个算法—k-近邻算法,这个算法总体构造思想是比较简单的,在ACM当中的话就对应了kd树这种结构。首先需要给定训练集,然后给出测试数据,求出训练集中与测试数据最相近的k个数据,根据这k个数据的属性来确定我们测试数据的属性。
书上的例子是给了四个点以及这四个点的标签,分别是A,A,B,B,现在给定一测试点,需要根据这四个训练集来判断该测试点的标签应该是A还是B。
from numpy import *
import operator def createDataSet():
group = array([[1.0,1.1], [1.0,1.0], [0,0], [0,0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet #统一矩阵,实现加减
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1) #进行累加,axis=0是按列,axis=1是按行
distances = sqDistances**0.5 #开根号
sortedDistIndicies = distances.argsort() #按升序进行排序,返回原下标
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 #get是字典中的方法,前面是要获得的值,后面是若该值不存在时的默认值
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
#在python3中没有iteritems,key在这里是按照字典的第二个元素来排序,降序排序
return sortedClassCount[0][0] #获得字典中第一对映射中的第一个值 if __name__ == "__main__":
dataSet, labels = createDataSet()
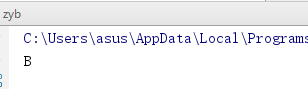
inX = [0.2, 0.2]
print(classify0(inX, dataSet, labels, 2))
代码详解:
①array
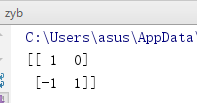
这是numpy库中,它就是用来构造矩阵的:
from numpy import array a = array([[1,1],
[2,3]])
b = array([[0,1],
[3,2]])
c = a-b
print(c)
②tile()函数
tile(A,repes)返回shape = repes的矩阵,每个元素是A
from numpy import tile a = [1,2,3]
b = tile(a,(2,3))
print(b)

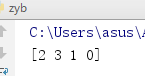
③argsort()
按序排列,返回原始下标
from numpy import argsort a = [4,3,1,2]
b = argsort(a)
print(b)
《机器学习实战》之k-近邻算法(示例)的更多相关文章
- 02机器学习实战之K近邻算法
第2章 k-近邻算法 KNN 概述 k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法. 一句话总结:近朱者赤近墨者黑! k ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 《机器学习实战》-k近邻算法
目录 K-近邻算法 k-近邻算法概述 解析和导入数据 使用 Python 导入数据 实施 kNN 分类算法 测试分类器 使用 k-近邻算法改进约会网站的配对效果 收集数据 准备数据:使用 Python ...
- 《机器学习实战》——K近邻算法
三要素:距离度量.k值选择.分类决策 原理: (1) 输入点A,输入已知分类的数据集data (2) 求A与数据集中每个点的距离,归一化,并排序,选择距离最近的前K个点 (3) K个点进行投票,票数最 ...
- 机器学习实战python3 K近邻(KNN)算法实现
台大机器技法跟基石都看完了,但是没有编程一直,现在打算结合周志华的<机器学习>,撸一遍机器学习实战, 原书是python2 的,但是本人感觉python3更好用一些,所以打算用python ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 机器学习随笔01 - k近邻算法
算法名称: k近邻算法 (kNN: k-Nearest Neighbor) 问题提出: 根据已有对象的归类数据,给新对象(事物)归类. 核心思想: 将对象分解为特征,因为对象的特征决定了事对象的分类. ...
- 机器学习 Python实践-K近邻算法
机器学习K近邻算法的实现主要是参考<机器学习实战>这本书. 一.K近邻(KNN)算法 K最近邻(k-Nearest Neighbour,KNN)分类算法,理解的思路是:如果一个样本在特征空 ...
- 机器学习:1.K近邻算法
1.简单案例:预测男女,根据身高,体重,鞋码 import numpy as np import matplotlib import sklearn from skleran.neighbors im ...
- 机器学习实战笔记-2-kNN近邻算法
# k-近邻算法(kNN) 本质是(提取样本集中特征最相似数据(最近邻)的k个分类标签). K-近邻算法的优缺点 例 优点:精度高,对异常值不敏感,无数据输入假定: 缺点:计算复杂度高,空间复杂度高: ...
随机推荐
- python字典的排序,按key排序和按value排序---sorted()
>>> d{'a': 5, 'c': 3, 'b': 4} >>> d.items()[('a', 5), ('c', 3), ('b', 4)] 字典的元素是成键 ...
- jenkins3
Jenkins是基于java开发的. GitHub Git (熟练使用) Doocker (了解) Jenkins (熟练使用) Django (熟练使用) Angularjs (了解) Sentry ...
- 文本tfidf
文本分类tf:词的频率 idf:逆文档频率 代码实例: # tf idf from sklearn.feature_extraction.text import TfidfVectorizer imp ...
- SSM的理解
SSM(Spring+SpringMVC+MyBatis)框架集由Spring.SpringMVC.MyBatis三个开源框架整合而成,常作为数据源较简单的web项目的框架.其中spring是一个轻量 ...
- storm的trident编程模型
storm的基本概念别人总结的, https://blog.csdn.net/pickinfo/article/details/50488226 编程模型最关键最难就是实现局部聚合的业务逻辑聚合类实现 ...
- Python For Android (P4a):添加权限(Permissions)
from flutter study: <uses-permission android:name="android.permission.INTERNET"/>< ...
- url去重 --布隆过滤器 bloom filter原理及python实现
https://blog.csdn.net/a1368783069/article/details/52137417 # -*- encoding: utf-8 -*- ""&qu ...
- tcpdump 抓包工具使用
1. 常用命令 监听p4p1网卡上来自 192.168.162.14 的包 tcpdump -i p4p1 src host 192.168.162.14 tcpdump -i p4p1 dst po ...
- shell脚本一键安装jdk
直接上shell #!/bin/bash #offline jdk install ipath="/usr/local" installpath=$(cd `dirname $0` ...
- 2018-2019-1 20189206 《Linux内核原理与分析》第二周作业
Linux内核分析 第二周学习 知识总结 操作系统与内核 操作系统 指在整个系统中负责完成最基本功能和系统管理的那些部分 内核 实际是操作系统的内在核心 内核独立于普通应用程序,拥有受保护的内存空间和 ...