python常用模块: random模块, time模块, sys模块, os模块, 序列化模块
一. random模块
import random
# 任意小数
print(random.random()) # 0到1的任意小数
print(random.uniform(-10, 10)) # 通过传参,可以取任意范围内的小数 # 任意整数
print(random.randint(-10, 10)) # 通过传参,可以取任意范围内的整数
print(random.randrange(-10, 10, 2)) # '2'是步长,这样从-10到10只能任意取偶数
# randint的范围都是闭区间, randrange的区间是左闭右开. # 随机抽取任意值
lst = ['hello', 'good', 112, ('better', 'best')]
print(random.choice(lst)) # 只能抽取一个
print(random.sample(lst, 2)) # 通过改变第二个参数值,可以改变抽取的个数 # 打乱顺序
lst = ['hello', 'good', 112, ('better', 'best')]
random.shuffle(lst) # 列表里元素的顺序会被打乱
print(lst) # 列表里元素的顺序发生改变
通过random模块实现随机验证码的功能,要求验证码全是数字或者由数字,字母(大小写)组成.
def verification_code(n = 6, flag = True): # 默认n为6,flag为 True
s = ''
for i in range(n):
ver_code = str(random.randint(0, 9)) # 随机整数(0-9)
if flag == True:
alp = chr(random.randint(97, 122)) # 随机小写字母(a-z)
alp_upper = chr(random.randint(65, 90)) # 随机大写字母(A-Z)
ver_code = random.choice([ver_code, alp, alp_upper]) # 随机抽取数字,小写字母,大写字母,三种可能的情况
s+= ver_code # 把每次抽取的结果进行拼接
return s
print(verification_code())
二. time模块
1. 时间戳时间(格林威治时间)
float数据类型, 秒为计量单位, 给机器看的.是从伦敦时间1970-1-1 0:0:0(北京时间: 1970-1-1 8:0:0)开始计时的.
2. 结构化时间
是一个时间对象, 有很多时间相关的属性.是时间戳和格式化时间转换的桥梁.
3. 格式化时间(字符串时间)
str数据类型, 可以根据你想要的格式来显示时间, 给人看的.
import time # 时间戳时间
ret = time.time()
print(ret) # 1533713732.5889328 # 结构化时间
obj = time.localtime()
print(obj)
# time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=15, tm_min=36, tm_sec=12, tm_wday=2, tm_yday=220, tm_isdst=0)
print(obj.tm_year) #
print(obj.tm_mon) #
print(obj.tm_mday) # # 格式化时间
# %Y和%y:表示年, %m表示月份, %d表示天数, %A表示星期几, %H表示小时, %M表示分钟, %S表示秒
print(time.strftime('%Y-%m-%d')) # 2018-08-08
print(time.strftime('%y-%m-%d')) # 18-08-08
print(time.strftime('%Y/%m/%d %A %H:%M:%S')) # 2018/08/08 Wednesday 15:40:39
print(time.strftime('%c')) # Wed Aug 8 15:44:02 2018
4. 三种时间格式的转换
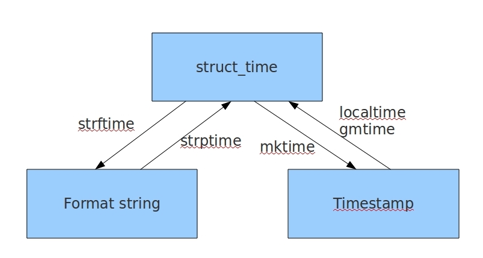
# 结构化时间=>>时间戳
# time.mktime(结构化时间)
ret3 = time.localtime()
print(ret3)
# time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=16, tm_min=0, tm_sec=5, tm_wday=2, tm_yday=220, tm_isdst=0)
ret4 = time.mktime(ret3)
print(ret4) # 1533715205.0 # 格式化时间=>>结构化时间
# time.strptime(时间字符串,字符串对应格式)
ret5 = time.strftime('%Y-%m-%d %H:%M:%S') # 获取格式化时间
print(ret5) # 2018-08-08 15:55:27
ret6 = time.strptime(ret5, '%Y-%m-%d %H:%M:%S') # 把格式化时间转成结构化时间
print(ret6)
# time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=15, tm_min=55, tm_sec=27, tm_wday=2, tm_yday=220, tm_isdst=-1) # 结构化时间=>>格式化时间
#time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则现实当前时间
ret7 = time.localtime()
print(ret7)
# time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=16, tm_min=5, tm_sec=35, tm_wday=2, tm_yday=220, tm_isdst=0)
ret8 = time.strftime('%Y-%m-%d %H:%M:%S', ret7)
print(ret8) # 2018-08-08 16:05:35
# 时间戳=>>格式化时间 : 时间戳=>>结构化时间=>>格式化时间
ret1 = time.time() # 获取时间戳
print(ret1) # 1533715856.4748423
ret2 = time.localtime(ret1) # 把时间戳转换成结构化时间
print(ret2)
# time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=16, tm_min=10, tm_sec=56, tm_wday=2, tm_yday=220, tm_isdst=0)
ret3 = time.strftime('%Y-%m-%d %H:%M:%S', ret2) # 把结构化时间转换成格式化时间
print(ret3) # 2018-08-08 16:10:56 # 格式化时间=>>时间戳 : 格式化时间=>>结构化时间=>>时间戳
ret4 = time.strftime('%Y-%m-%d %H:%M:%S') # 获取格式化时间
print(ret4) # 2018-08-08 16:17:38
ret5 = time.strptime(ret4, '%Y-%m-%d %H:%M:%S') # 格式化时间=>>结构化时间
print(ret5)
# time.struct_time(tm_year=2018, tm_mon=8, tm_mday=8, tm_hour=16, tm_min=17, tm_sec=38, tm_wday=2, tm_yday=220, tm_isdst=-1)
ret6 = time.mktime(ret5) # 结构化时间=>>时间戳
print(ret6) # 1533716258.0
计算每个月1号(0:0:0)的时间戳.
# 计算每个月的1号的时间戳
ret = time.localtime() # 获取当前的结构化时间
year = ret.tm_year # 获取当前年份
mon = ret.tm_mon # 获取当前月份 ret1 = time.strptime('%s-%s-1' % (year, mon), '%Y-%m-%d') # 把时间设置成1号
print(ret1)
print(time.mktime(ret1)) # 结构化时间=>>时间戳
三. sys模块
sys模块是与python解释器交互的一个接口
import sys # sys.path
# sys.path 获取指定模块搜索路径的字符串集合,可以将写好的模块放在得到的某个路径下,就可以在程序中import时正确找到。
print(sys.path) # 返回的数据类型是列表
# ['D:\\pycharm\\练习\\week06', 'D:\\pycharm', 'C:\\Python37\\python37.zip', 'C:\\Python37\\DLLs', 'C:\\Python37\\lib',
# 'C:\\Python37', 'C:\\Python37\\lib\\site-packages', 'D:\\JetBrains\\PyCharm 2018.1.4\\helpers\\pycharm_matplotlib_backend']
sys.path.append('路径') # 添加路径 sys.modules
# sys.modules是一个全局字典,该字典是python启动后就加载在内存中。每当程序员导入新的模块,sys.modules将自动记录该模块。
# 当第二次再导入该模块时,python会直接到字典中查找,从而加快了程序运行的速度。它拥有字典所拥有的一切方法。
# print(sys.modules) print(sys.platform) # 获取当前系统平台 结果不准确
# sys.exit() # 结束程序 # sys.argv 在外部向程序内部传递参数
name = sys.argv[1]
pwd = sys.argv[2]
if name == 'alex' and pwd == 'alex3714':
print('执行以下代码')
else:
exit()
# 此程序在pycharm无反应,在cmd里可以正常执行
四. os模块
os模块就是对操作系统进行操作
#OS模块 #os模块就是对操作系统进行操作,使用该模块必须先导入模块:
import os #getcwd() 获取当前工作目录(当前工作目录默认都是当前文件所在的文件夹)
result = os.getcwd()
print(result) #chdir()改变当前工作目录
os.chdir('/home/sy')
result = os.getcwd()
print(result) open('02.txt','w') #操作时如果书写完整的路径则不需要考虑默认工作目录的问题,按照实际书写路径操作
open('/home/sy/下载/02.txt','w') #listdir() 获取指定文件夹中所有内容的名称列表
result = os.listdir('/home/sy')
print(result) #mkdir() 创建文件夹
#os.mkdir('girls')
#os.mkdir('boys',0o777) #makedirs() 递归创建文件夹
#os.makedirs('/home/sy/a/b/c/d') #rmdir() 删除空目录
#os.rmdir('girls') #removedirs 递归删除文件夹 必须都是空目录
#os.removedirs('/home/sy/a/b/c/d') #rename() 文件或文件夹重命名
#os.rename('/home/sy/a','/home/sy/alibaba'
#os.rename('02.txt','002.txt') #stat() 获取文件或者文件夹的信息
#result = os.stat('/home/sy/PycharmProject/Python3/10.27/01.py)
#print(result) #system() 执行系统命令(危险函数)
#result = os.system('ls -al') #获取隐藏文件
#print(result) #环境变量
'''
环境变量就是一些命令的集合
操作系统的环境变量就是操作系统在执行系统命令时搜索命令的目录的集合
'''
#getenv() 获取系统的环境变量
result = os.getenv('PATH')
print(result.split(':')) #putenv() 将一个目录添加到环境变量中(临时增加仅对当前脚本有效)
#os.putenv('PATH','/home/sy/下载')
#os.system('syls') #exit() 退出终端的命令 #os模块中的常用值
#curdir 表示当前文件夹 .表示当前文件夹 一般情况下可以省略
print(os.curdir) #pardir 表示上一层文件夹 ..表示上一层文件夹 不可省略!
print(os.pardir) #os.mkdir('../../../man')#相对路径 从当前目录开始查找
#os.mkdir('/home/sy/man1')#绝对路径 从根目录开始查找 #name 获取代表操作系统的名称字符串
print(os.name) #posix -> linux或者unix系统 nt -> window系统 #sep 获取系统路径间隔符号 window ->\ linux ->/
print(os.sep) #extsep 获取文件名称和后缀之间的间隔符号 window & linux -> .
print(os.extsep) #linesep 获取操作系统的换行符号 window -> \r\n linux/unix -> \n
print(repr(os.linesep)) #导入os模块
import os #以下内容都是os.path子模块中的内容 #abspath() 将相对路径转化为绝对路径
path = './boys'#相对
result = os.path.abspath(path)
print(result) #dirname() 获取完整路径当中的目录部分 & basename()获取完整路径当中的主体部分
path = '/home/sy/boys'
result = os.path.dirname(path)
print(result) result = os.path.basename(path)
print(result) #split() 将一个完整的路径切割成目录部分和主体部分
path = '/home/sy/boys'
result = os.path.split(path)
print(result) #join() 将2个路径合并成一个
var1 = '/home/sy'
var2 = '000.py'
result = os.path.join(var1,var2)
print(result) #splitext() 将一个路径切割成文件后缀和其他两个部分,主要用于获取文件的后缀
path = '/home/sy/000.py'
result = os.path.splitext(path)
print(result) #getsize() 获取文件的大小
#path = '/home/sy/000.py'
#result = os.path.getsize(path)
#print(result) #isfile() 检测是否是文件
path = '/home/sy/000.py'
result = os.path.isfile(path)
print(result) #isdir() 检测是否是文件夹
result = os.path.isdir(path)
print(result) #islink() 检测是否是链接
path = '/initrd.img.old'
result = os.path.islink(path)
print(result) #getctime() 获取文件的创建时间 get create time
#getmtime() 获取文件的修改时间 get modify time
#getatime() 获取文件的访问时间 get active time import time filepath = '/home/sy/下载/chls' result = os.path.getctime(filepath)
print(time.ctime(result)) result = os.path.getmtime(filepath)
print(time.ctime(result)) result = os.path.getatime(filepath)
print(time.ctime(result)) #exists() 检测某个路径是否真实存在
filepath = '/home/sy/下载/chls'
result = os.path.exists(filepath)
print(result) #isabs() 检测一个路径是否是绝对路径
path = '/boys'
result = os.path.isabs(path)
print(result) #samefile() 检测2个路径是否是同一个文件
path1 = '/home/sy/下载/001'
path2 = '../../../下载/001'
result = os.path.samefile(path1,path2)
print(result) #os.environ 用于获取和设置系统环境变量的内置值
import os
#获取系统环境变量 getenv() 效果
print(os.environ['PATH']) #设置系统环境变量 putenv()
os.environ['PATH'] += ':/home/sy/下载'
os.system('chls')
五. 序列化模块
序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
序列化的目的
1. json模块
json模块用于字符串和python数据类型间进行转换, 有四种方法: dumps,loads,dump,load
import json
# dunps,losds dic1 = {'k1': 'v1', 'k2': 'v2'}
json_dic1 = json.dumps(dic1) # 序列化=>>把字典转成字符串
print(json_dic1, type(json_dic1)) # {"k1": "v1", "k2": "v2"} <class 'str'>
new_dic1 = json.loads(json_dic1) # 反序列化=>>把字符串转成字典
# 要用json的loads功能处理的字符串类型的字典中的字符串必须由""表示
print(new_dic1, type(new_dic1)) # {'k1': 'v1', 'k2': 'v2'} <class 'dict'> # json格式的key必须是字符串数据类型
dic2 = {1: 2, 3: 4, 5: 6} # 如果是数字为key,那么dump之后会强行转成字符串数据类型
json_dic2 = json.dumps(dic2)
print(json_dic2, type(json_dic2)) # {"1": 2, "3": 4, "5": 6} <class 'str'>
new_dic2 = json.loads(json_dic2)
print(new_dic2, type(new_dic2)) # {'1': 2, '3': 4, '5': 6} <class 'dict'> # json格式的key不可以是元组数据类型,value为元组时,序列化时会被转成列表,反序列化后还是列表.
dic3 = {(1, 2): 3, (4, 5): 6} # 把元组作为key时
json_dic3 = json.dumps(dic3) # 报错: keys must be str, int, float, bool or None, not tuple
dic4 = {'ab': (1, 2), 'cd': (4, 5)}
json_dic4 = json.dumps(dic4)
print(json_dic4, type(json_dic4)) # {"ab": [1, 2], "cd": [4, 5]} <class 'str'>
new_dic4 = json.loads(json_dic4)
print(new_dic4, type(new_dic4)) # {'ab': [1, 2], 'cd': [4, 5]} <class 'dict'> lst = [1, 2, 3, 4, 5, 6]
json_lst = json.dumps(lst)
print(json_lst, type(json_lst)) # [1, 2, 3, 4, 5, 6] <class 'str'>
new_lst = json.loads(json_lst)
print(new_lst, type(new_lst)) # [1, 2, 3, 4, 5, 6] <class 'list'>
# dump,load
# dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
# load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
dic1 = {'k1': 'v1', 'k2': 'v2'}
with open('', 'w')as f1: # 只写模式
json.dump(dic1, f1) # 把字典转成字符串并写入文件'123'里.
#
with open('')as f2: # 只读模式
new_dic1 = json.load(f2)
print(new_dic1, type(new_dic1)) # {'k1': 'v1', 'k2': 'v2'} <class 'dict'>
json格式下,多个文件写入文件时,使用dumps方法
: 可以多次dump,但是不能load出来了
dic = {'k1': 'v1', 'k2': 'v2'}
lst = [1, 2, 3, 4, 5, 6]
with open('', 'w')as f1:
json.dump(dic, f1) # dic被序列化写入文件
json.dump(lst, f1) # lst被序列化写入文件
with open('', 'r')as f2:
new_dic = json.load(f2) # 报错,无法反序列化
new_lst = json.load(f2) # # dumps
dic = {'k1': 'v1', 'k2': 'v2'}
lst = [1, 2, 3, 4, 5, 6]
with open('', 'w')as f1:
json_dic = json.dumps(dic)
json_lst = json.dumps(lst)
f1.write(json_dic+'\n')
f1.write(json_lst+'\n')
with open('') as f2:
for line in f2:
new = json.loads(line)
print(new, type(new))
# {'k1': 'v1', 'k2': 'v2'} <class 'dict'>
# [1, 2, 3, 4, 5, 6] <class 'list'>
序列化时遇到中文,需要添加 ensure_ascii = False 参数
# 中文格式 ensure_ascii = False
dic = {'k1': '牛奶', 'k2': '可乐'}
json_dic1 = json.dumps(dic) # 序列化过程有中文时,会把汉字转成bytes类型,对loads没有影响,loads后还是汉字
print(json_dic1) # {"k1": "\u725b\u5976", "k2": "\u53ef\u4e50"}
new_dic1 = json.loads(json_dic1)
print(new_dic1) # {'k1': '牛奶', 'k2': '可乐'}
json_dic2 = json.dumps(dic, ensure_ascii=False) # 加上ensure_ascii = False就会让汉字序列化后显示的还是汉字
print(json_dic2) # {"k1": "牛奶", "k2": "可乐"}
json其它参数
# json的其他参数,是为了用户看的更方便,但是会相对浪费存储空间
# sort_keys:按key的首字母从a-z排序. indent:缩进.
# separators:分隔符,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
data = {'username': ['李华', '二愣子'], 'sex': 'male', 'age': 16}
json_dic2 = json.dumps(data, sort_keys=True, indent=4, separators=(',', ':'), ensure_ascii=False)
print(json_dic2)
# {
# "age":16,
# "sex":"male",
# "username":[
# "李华",
# "二愣子"
# ]
# }
2. pickle模块
用于python特有的类型和python的数据类型间进行转换.不仅可以序列化字典,列表...可以把python中任意的数据类型序列化.
# pickle
# dump的结果是bytes,dump用的f文件句柄需要以wb的形式打开,load所用的f是'rb'模式
# 支持几乎所有对象的序列化
import pickle
# dumps,loads dic = {1: 'v1', ('a', 'b'): ('c', 'd')} # pickle格式的key值可以为数字,也可以为元组.value为元组时不会被转为列表
pickle_dic = pickle.dumps(dic)
print(pickle_dic, type(pickle_dic)) # bytes类型
# b'\x80\x03}q\x00(K\x01X\x02\x00\x00\x00v1q\x01X\x01\x00\x00\x00aq\x02X\x01\x00\x00\x00bq
# \x03\x86q\x04X\x01\x00\x00\x00cq\x05X\x01\x00\x00\x00dq\x06\x86q\x07u.' <class 'bytes'>
new_dic = pickle.loads(pickle_dic)
print(new_dic, type(new_dic)) # {1: 'v1', ('a', 'b'): ('c', 'd')} <class 'dict'> # pickle 格式下可以对元组和集合序列化和反序列化
tu = ('a', 'b', 'c', 'd') # 元组
pickle_tu = pickle.dumps(tu)
print(pickle_tu)
# b'\x80\x03(X\x01\x00\x00\x00aq\x00X\x01\x00\x00\x00bq\x01X\x01\x00\x00\x00cq\x02X\x01\x00\x00\x00dq\x03tq\x04.'
new_tu = pickle.loads(pickle_tu)
print(new_tu) # ('a', 'b', 'c', 'd') se = {'a', 'b', 'c', 'd'} # 集合
pickle_se = pickle.dumps(se)
print(pickle_se)
# b'\x80\x03cbuiltins\nset\nq\x00]q\x01(X\x01\x00\x00\x00bq\x02X\x01\x00\x00\x00aq\x03X
# \x01\x00\x00\x00cq\x04X\x01\x00\x00\x00dq\x05e\x85q\x06Rq\x07.'
new_se = pickle.loads(pickle_se)
print(new_se) # {'c', 'b', 'd', 'a'}
# pickle对对象序列化时,类必须存在于内存中
class A:
def __init__(self, name):
self.name = name def func(self):
return '%s正在吃饭' % self.name a = A('jack')
pickle_a = pickle.dumps(a)
print(pickle_a)
# b'\x80\x03c__main__\nA\nq\x00)\x81q\x01}q\x02X\x04\x00\x00\x00nameq\x03X\x04\x00\x00\x00jackq\x04sb.'
new_a = pickle.loads(pickle_a) # new_a就相当于a
print(new_a) # <__main__.A object at 0x000002B3BB8554A8>
print(new_a.name) # jack
print(new_a.func()) # jack正在吃饭
# dump,load 因为pickle序列化获得的是bytes类型,在读/写文件时mode设置为wb/rb
dic = {1: 'v1', ('a', 'b'): ('c', 'd')}
with open('', 'wb')as f1: # wb模式
pickle_dic = pickle.dump(dic, f1) # 写入的bytes在文件显示的是乱码格式
with open('', 'rb')as f2: # rb模式
new_dic = pickle.load(f2)
print(new_dic) # {1: 'v1', ('a', 'b'): ('c', 'd')}
在pickle格式下,写入多个数据时,dumps和dump都可以
# pickle多个数据写入文件,dumps和dump都可以
# dump
dic = {1: 'v1', ('a', 'b'): ('c', 'd')}
lst = [1, 2, 3, 4, 5]
with open('', 'wb')as f1:
pickle.dump(dic, f1)
pickle.dump(lst, f1)
with open('', 'rb')as f2:
new_dic = pickle.load(f2)
new_lst = pickle.load(f2)
print(new_dic) # {1: 'v1', ('a', 'b'): ('c', 'd')}
print(new_lst) # [1, 2, 3, 4, 5]
# dumps
dic = {1: 'v1', ('a', 'b'): ('c', 'd')}
lst = [1, 2, 3, 4, 5]
with open('', 'wb')as f1:
pickle_dic = pickle.dumps(dic)
pickle_lst = pickle.dumps(lst)
f1.write(pickle_dic + b'\n') # bytes和str类型的\n无法拼接,需要在\n前加上b
f1.write(pickle_lst + b'\n')
with open('', 'rb')as f2:
for line in f2:
new = pickle.loads(line)
print(new, type(new))
# {1: 'v1', ('a', 'b'): ('c', 'd')} <class 'dict'>
# [1, 2, 3, 4, 5] <class 'list'>
dic = {1: 'v1', ('a', 'b'): ('c', 'd')}
lst = [1, 2, 3, 4, 5]
with open('', 'wb')as f1:
pickle.dump(dic, f1)
pickle.dump(lst, f1)
with open('', 'rb')as f2:
# for line in f2: # 循环取出每行
# print(pickle.load(f2)) # 报错: EOFError
while True: # 用try和except
try:
print(pickle.load(f2))
except EOFError:
break
#
# # {1: 'v1', ('a', 'b'): ('c', 'd')}
# # [1, 2, 3, 4, 5]
总结 : json和pickle的区别 :
json :
可以跨语言,跨平台使用.限制比较多,只能序列化字典,列表,数字等数据类型.无法序列化元组,集合,对象等数据类型.
字典的key不可以是元组和数字,字典的value为元组时,序列化会变成列表.
dump的结果是字符串
pickle :
只适用于python(python所有数据类型)
dunp的结果是bytes, dump用的f文件句柄需要以wb的形式打开,load所用的f是'rb'模式.
3. shelve
shelve只提供给一个open方法,是用key来访问的,使用起来和字典类似。
import shelve
f = shelve.open('shelve_demo') # 会生成三个文件 : shelve_demo.dir,shelve_demo.bak, shelve_demo.dat
f['key'] = {'k1': (1, 2, 3), 'k2': 'v2'} # 写入
f.close() f = shelve.open('shelve_demo')
content = f['key'] # 读取
f.close()
print(content) # {'k1': (1, 2, 3), 'k2': 'v2'} # shelve 如果你写定了一个文件
# 改动的比较少
# 读文件的操作比较多
# 且你大部分的读取都需要基于某个key获得某个value
python常用模块: random模块, time模块, sys模块, os模块, 序列化模块的更多相关文章
- python note 17 random、time、sys、os模块
1.random模块(取随机数模块) # 取随机小数 : 数学计算 import random print(random.random())# 取0-1之间的小数 print(random.unifo ...
- 18 常用模块 random shutil shevle logging sys.stdin/out/err
random:随机数 (0, 1) 小数:random.random() ***[1, 10] 整数:random.randint(1, 10) *****[1, 10) 整数:random.rand ...
- python常用内置模块-random模块
random模块:用于生成随机数 '''关于数据类型序列相关,参照https://www.cnblogs.com/yyds/p/6123692.html''' random() 随机获取0 到1 之间 ...
- 常用模块random/os/sys/time/datatime/hashlib/pymysql等
一.标准模块 1.python自带的,import random,json,os,sys,datetime,hashlib等 ①.正常按照命令:打开cmd,执行:pip install rangdom ...
- python常用模块1
一. 什么是模块: 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编写的代码 ...
- random os 序列化 模块模块 随机选择
# 1 random 模块 随机选择# import random#随机取小数# ret = random.random() #空是0到1之间的小数字# print(ret)# # 0.0799728 ...
- python常用模块(模块和包的解释,time模块,sys模块,random模块,os模块,json和pickle序列化模块)
1.1模块 什么是模块: 在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护. 为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文 ...
- python 常用模块之random,os,sys 模块
python 常用模块random,os,sys 模块 python全栈开发OS模块,Random模块,sys模块 OS模块 os模块是与操作系统交互的一个接口,常见的函数以及用法见一下代码: #OS ...
- python 常用模块(一): random , time , sys , os模块部分知识.
1.常用模块:(1)collectiaons模块 (2)与时间相关 time模块 (3)random模块 (4)os模块 (5)sys模块 (6) 序列化模块: json , pickle 2 ...
随机推荐
- js实现一条抛物线
抛物线运动解释: 以右开口为例,根据公式 y^2 = 2px .确定p的值,已知x求y. <!DOCTYPE html> <html> <head> <me ...
- LeetCode - Find K Closest Elements
Given a sorted array, two integers k and x, find the k closest elements to x in the array. The resul ...
- window.location.herf=url参数有中文,到后台乱码问题解决
js中的代码: /*将中文的参数进行两次编码 */ function queryByName(){ //获取查询条件的用户名 ...
- day43 数据库学习egon的博客 索引
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
- keycloak docker-compose 运行
内容很简单,主要是搭建一个可运行的keycloak 环境,方便开发测试,同时支持数据库的持久化 docker-compose 文件 version: "3" services: a ...
- sqler sql 转rest api 的docker image
最新sqler 又发布了一个版本,同时官方文档也更新,对于数据库的连接有了详细的说明 Dockerfile 为了方便以及减少大小,使用多阶段构建,同时都通过环境变量运行 FROM alpine:lat ...
- debezium sql server 集成
debezium 是一个方便的cdc connector 可以帮助我们解决好多数据实时变更处理.数据分析.微服务的数据通信 从上次跑简单demo到现在,这个工具是有好多的变更,添加了好多方便的功能,支 ...
- Android之根布局动态载入子布局时边距设置无效问题
Android大部分的控件都会有padding和layout_margin两个属性,一般来说它们的差别是: padding:控件中的内容离控件边缘的距离. margin: 控件离它的父控件边缘的距离 ...
- 你不知道的JavaScript(上卷) (Kyle Simpson 著)
第一部分 作用域和闭包 第1章 作用域是什么 (已看) 1.1 编译原理 1.2 理解作用域 1.2.1 演员表 1.2.2 对话 1.2.3 编译器有话说 1.2.4 引擎和作用域的对话 1.2.5 ...
- openstack--5--控制节点和计算节点安装配置nova
Nova相关介绍 目前的Nova主要由API,Compute,Conductor,Scheduler组成 Compute:用来交互并管理虚拟机的生命周期: Scheduler:从可用池中根据各种策略选 ...