浅谈分词算法(4)基于字的分词方法(CRF)
前言
通过前面几篇系列文章,我们从分词中最基本的问题开始,并分别利用了1-gram和HMM的方法实现了分词demo。本篇博文在此基础上,重点介绍利用CRF来实现分词的方法,这也是一种基于字的分词方法,在将句子转换为序列标注问题之后,不使用HMM的生成模型方式,而是使用条件概率模型进行建模,即判别模型CRF。之后我们对CRF与HMM进行对比,同样的我们最终也会附上CRF分词的实现代码。
目录
浅谈分词算法(1)分词中的基本问题
浅谈分词算法(2)基于词典的分词方法
浅谈分词算法(3)基于字的分词方法(HMM)
浅谈分词算法(4)基于字的分词方法(CRF)
浅谈分词算法(5)基于字的分词方法(LSTM)
条件随机场(conditional random field CRF)
为了说清楚CRF在分词上的应用,我们需要简单介绍下条件随机场CRF,我们不去长篇大论的展开论述,只讨论几个核心的点,并重点阐述下线性链条件随机场,也是我们在序列标注问题中经常遇到的,如分词、词性标注、韵律标注等等。
核心点
在上一篇博文中,我们简单介绍了HMM模型,是一个五元组,它的核心围绕的是一个关于序列\(X\)和\(Y\)的联合概率分布\(P(X,Y)\),而在条件随机场的核心围绕的是条件概率分布模型\(P(Y|X)\),它是一种马尔可夫随机场,满足马尔科夫性(这里我们就不展开阐述了,具体可参考[3])。我们这里必须搬出一张经典的图片,大家可能在网上的无数博文中也都看到过,其来源与[4]:
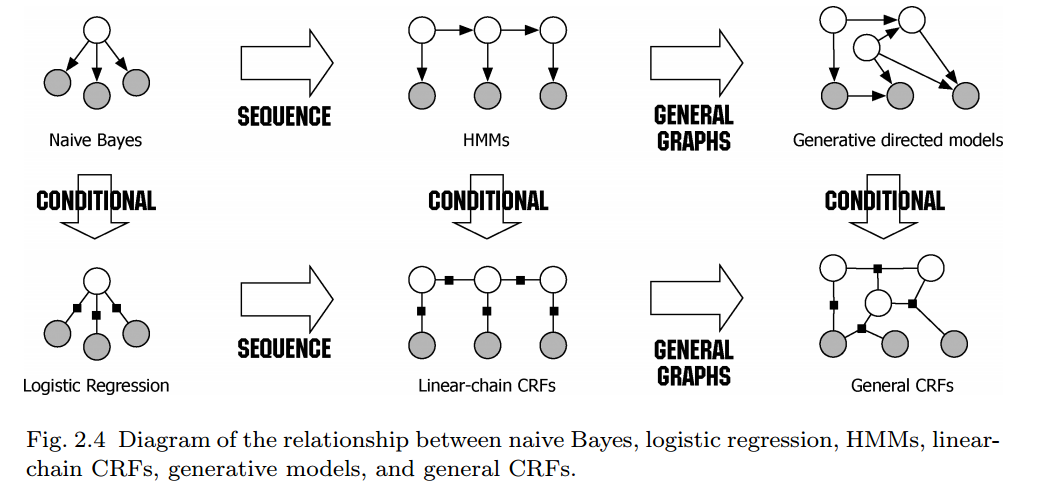
从图中我们可以看出模型之间的演化过程以及模型之间的区别,对于用在分类问题中的逻辑回归与CRF其实都同属于对数线性模型,这里直观的我们也很好理解,当用CRF模型对\(X\)和\(Y\)序列建模时,我们需要判断\(x_i\)对应的标签\(y_i\)时其实可以看做一次逻辑回归分类问题,只不过这个分类问题考虑了上下文的序列信息,也就是说单纯的回归分类会损失上下文的序列信息如:有一系列连续拍摄的照片,现在想在照片上打上表示照片里的活动内容的标记,当然可以将每张照片单独做分类,但是会损失信息,例如当有一张照片上是一张嘴,应该分类到“吃饭”还是分类到“唱K”呢?如果这张照片的上一张照片内容是吃饭或者做饭,那么这张照片表示“吃饭”的可能性就大一些,如果上一张照片的内容是跳舞,那这张照片就更有可能在讲唱K的事情。
设有联合概率分布\(P(Y)\),由无向图\(G=(V,E)\)表示,在图\(G\)中,结点表示随机变量,边表示随机变量之间的依赖关系,如果联合概率分布\(P(Y)\)满足成对、局部或全局马尔可夫性,就称此联合概率分布为马尔可夫随机场(Markov random filed)也称概率无向图模型(probablistic undirected graphical model):
- 成对马尔可夫性:设\(u,v\)是无向图\(G\)中任意两个没有边连接的结点,其他所有结点表示为\(O\),对应的随机变量分别用\(Y_u,Y_v,Y_O\)表示,成对马尔可夫性是指给定随机变量组\(Y_O\)的条件下随机变量\(Y_u,Y_v\)是条件独立的,如下:\[P(Y_u,Y_v|Y_O)=P(Y_u|Y_O)P(Y_v|Y_O)\]
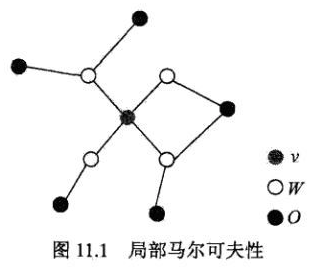
- 局部马尔可夫性:设\(v\in V\)是\(G\)中任意一个节点,\(W\)是与\(v\)有边连接的所有节点,\(O\)是\(v\),\(W\)以外的其他所有节点。\(v\)表示的随机变量是\(Y_v\),\(W\)表示的随机变量是\(Y_w\),\(O\)表示的随机变量是\(Y_o\)。局部马尔可夫性是在给定随机变量组\(Y_w\)的条件下随机变量\(Y_v\)与随机变量\(Y_o\)是独立的。\[P(Y_v,Y_O|Y_W)=P(Y_v|Y_w)P(Y_O|Y_W)\]
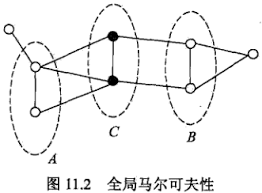
- 全局马尔可夫性:\(A,B\)是\(G\)中被C分开的任意节点集合。全局马尔科夫性是指给定\(Y_c\)条件下\(Y_A\)和\(Y_B\)是条件独立的,即\[P(Y_A,Y_B|Y_C)=P(Y_A|Y_C)P(Y_B|Y_C)\]
下面我们具体阐述下一种特殊也常用的线性链条件随机场。
线性链条件随机场
给定一个线性链条件随机场\(P(Y|X)\),当观测序列为\(x=x_1x_2...\)时,状态序列为 \(y=y_1y_2...\)的概率可写为(实际上应该写为\(P(Y=y|x;θ)\),参数被省略了)
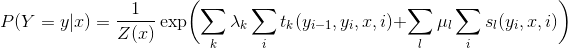
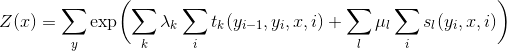
\(Z(x)\)作为规范化因子,是对\(y\)的所有可能取值求和。我们可以用下图来理解:
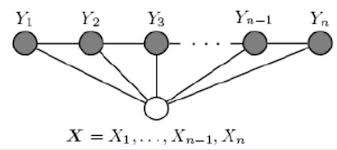
对于线性链CRF,特征函数是个非常重要的概念(很容易联想到HMM的转移概率和发射概率):
- 转移特征\(t_k(y_{i−1},y_i,x,i)\)是定义在边上的特征函数(transition),依赖于当前位置\(i\)和前一位置\(i-1\);对应的权值为\(λ_k\)。
- 状态特征\(s_l(y_i,x,i)\)是定义在节点上的特征函数(state),依赖于当前位置\(i\);对应的权值为\(μ_l\)。
一般来说,特征函数的取值为 1 或 0 ,当满足规定好的特征条件时取值为 1 ,否则为 0 。
简化形式
对于转移特征这一项:
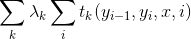
可以看出外面那个求和号是套着里面的求和号的,这种双重求和就表明了对于同一个特征\(k\),在各个位置\(i\)上都有定义。
基于此,很直觉的想法就是把同一个特征在各个位置\(i\)求和,形成一个全局的特征函数,也就是说让里面那一层求和号消失。在此之前,为了把加号的两项合并成一项,首先将各个特征函数\(t\)(设其共有\(K_1\)个)、\(s\)(设共\(K_2\)个)都换成统一的记号\(f\) :
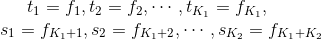
相应的权重同理:
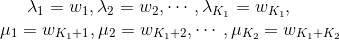
那么就可以记为:
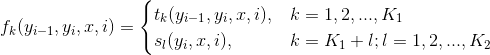
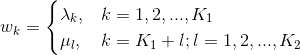
然后就可以把特征在各个位置\(i\)求和,即
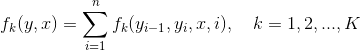
其中\(K=K_1+K_2\)。进而可以得到简化表示形式:
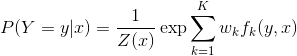
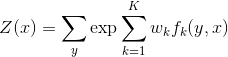
这个形式我们在下一节介绍CRF分词的时候会使用。
CRF分词
对于一个句子的分词问题我们在前面的系列博文中已经阐述,输入的句子\(S\)相当于序列\(X\),输出的标签序列L相当于序列\(Y\),我们要训练一个模型,使得在给定\(S\)的前提下,找到其最优对应的\(L\)。
训练该模型的关键点就是特征函数\(F\)的选取以及每个特征函数权重\(W\)的确定,而对于每个特征函数而言,其输入有如下四个要素:
- 句子\(S\)(就是我们要标注词性的句子)
- \(i\),用来表示句子\(S\)中第\(i\)个单词
- \(l_i\),表示要评分的标注序列给第i个单词标注的词性
- \(l_{i-1}\),表示要评分的标注序列给第\(i-1\)个单词标注的词性
它的输出值是0或者1,0表示要评分的标注序列不符合这个特征,1表示要评分的标注序列符合这个特征。我们发现这里的特征函数在选取当前\(s_i\)的对应标签\(l_i\)时,只考虑了其前一个标签\(l_{i-1}\),这就是使用了我们上一节阐述的线性链条件随机场,而公式中的f就是我们这里的特征函数。
Note:在实际的应用时,除了单一的特征选取,我们通常会通过构造复合特征的方式,考虑更多的上下文信息。
CRF VS HMM
在上一篇博文中我们介绍了HMM在分词中的使用,那么读者肯定会问既然HMM已经能完成任务,为什么还需要CRF来重新搞一波,原因就是CRF比HMM更强大。
对于序列\(L\)和\(S\),根据之前的介绍我们易知如下公式:
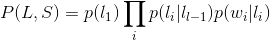
其中\(w_i\)为\(S\)中第\(i\)个词,\(l_i\)为第\(i\)个词的标签,公式中前半部分为状态转移概率,后半部分为发射概率。我们用对数形式表示该式:
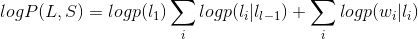
把这个式子与CRF的简化形式比较,不难发现,如果我们把第一个HMM式子中的log形式的概率看做是第二个CRF式子中的特征函数的权重的话,我们会发现,CRF和HMM具有相同的形式。所以可以说:每一个HMM模型都等价于某个CRF。
总结下两者的区别:
- HMM是生成模型以联合概率建模,CRF是判别模型以条件概率建模
- HMM为了简化计算做了有限状态假设和一对一假设(当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签),所以在特征选取上会有很多限制;而CRF可以定义数量更多,种类更丰富的特征函数(如定义一个特征函数f,考虑当前词离句首的距离,来着眼于整个句子)。
- CRF可以使用任意的权重 将对数HMM模型看做CRF时,特征函数的权重由于是log形式的概率,所以都是小于等于0的,而且概率还要满足相应的限制,但在CRF中,每个特征函数的权重可以是任意值,没有这些限制。
Note:其实在HMM和CRF之间还有一个MEMM,即最大熵马尔科夫模型,MEMM模型是对转移概率和表现概率建立联合概率,统计时统计的是条件概率,但MEMM容易陷入局部最优,是因为MEMM只在局部做归一化(标记偏置问题),不过一般用的不多我们就不过多介绍,可参考[5]
代码实现
下面我们利用wapiti来实现一个简单的CRF分词器。相关说明:
- wapiti是一个开源的CRF工具,doc在这里:https://wapiti.limsi.fr/
- 数据源来源于msr整理所得:http://sighan.cs.uchicago.edu/bakeoff2005/
- python
- ubuntu/macos
训练代码
https://github.com/xlturing/machine-learning-journey/tree/master/seg_crf
大家可以直接看下源代码
实验结果
- Load model
- Label sequences
1000 sequences labeled 3.96%/43.30%
2000 sequences labeled 3.89%/44.00%
3000 sequences labeled 3.87%/44.50%
Nb sequences : 3985
Token error : 3.85%
Sequence error: 44.74% - Per label statistics
B Pr=0.96 Rc=0.98 F1=0.97
E Pr=0.96 Rc=0.98 F1=0.97
S Pr=0.97 Rc=0.95 F1=0.96
M Pr=0.92 Rc=0.87 F1=0.90 - Done
这个训练集和测试集都相对较小,效果还不错,读者在真正上线使用时还需要依赖词典等诸多与场景对应的分词特性,本文更加关注原理和理解。
参考文献
- HMM MEMM CRF 区别 联系
- 如何轻松愉快地理解条件随机场(CRF)?
- NLP —— 图模型(二)条件随机场(Conditional random field,CRF)
- An Introduction to Conditional Random Fields
- HMM MEMM CRF 区别 联系
- 《统计学习方法》 李航
浅谈分词算法(4)基于字的分词方法(CRF)的更多相关文章
- 浅谈分词算法(5)基于字的分词方法(bi-LSTM)
目录 前言 目录 循环神经网络 基于LSTM的分词 Embedding 数据预处理 模型 如何添加用户词典 前言 很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做 ...
- 浅谈分词算法(3)基于字的分词方法(HMM)
目录 前言 目录 隐马尔可夫模型(Hidden Markov Model,HMM) HMM分词 两个假设 Viterbi算法 代码实现 实现效果 完整代码 参考文献 前言 在浅谈分词算法(1)分词中的 ...
- 浅谈分词算法基于字的分词方法(HMM)
前言 在浅谈分词算法(1)分词中的基本问题我们讨论过基于词典的分词和基于字的分词两大类,在浅谈分词算法(2)基于词典的分词方法文中我们利用n-gram实现了基于词典的分词方法.在(1)中,我们也讨论了 ...
- 浅谈局域网ARP攻击的危害及防范方法(图)
浅谈局域网ARP攻击的危害及防范方法(图) 作者:冰盾防火墙 网站:www.bingdun.com 日期:2015-03-03 自 去年5月份开始出现的校内局域网频繁掉线等问题,对正常的教育教 ...
- 浅谈Tarjan算法及思想
在有向图G中,如果两个顶点间至少存在一条路径,称两个顶点强连通(strongly connected).如果有向图G的每两个顶点都强连通,称G是一个强连通图.非强连通图有向图的极大强连通子图,称为强连 ...
- 浅谈 Tarjan 算法
目录 简述 作用 Tarjan 算法 原理 出场人物 图示 代码实现 例题 例题一 例题二 例题三 例题四 例题五 总结 简述 对于初学 Tarjan 的你来说,肯定和我一开始学 Tarjan 一样无 ...
- 浅谈Manacher算法与扩展KMP之间的联系
首先,在谈到Manacher算法之前,我们先来看一个小问题:给定一个字符串S,求该字符串的最长回文子串的长度.对于该问题的求解.网上解法颇多.时间复杂度也不尽同样,这里列述几种常见的解法. 解法一 ...
- [Machine Learning] 浅谈LR算法的Cost Function
了解LR的同学们都知道,LR采用了最小化交叉熵或者最大化似然估计函数来作为Cost Function,那有个很有意思的问题来了,为什么我们不用更加简单熟悉的最小化平方误差函数(MSE)呢? 我个人理解 ...
- 浅谈Tarjan算法
从这里开始 预备知识 两个数组 Tarjan 算法的应用 求割点和割边 求点-双连通分量 求边-双连通分量 求强连通分量 预备知识 设无向图$G_{0} = (V_{0}, E_{0})$,其中$V_ ...
随机推荐
- 关于Tomcat性能监控的第三方工具Probe的简介
Tomcat Probe => Lambda Probe =>PSI Probe,这个小工具已经三易其名了.(现在挪窝到GitHub了,很方便). 这个Probe可以说是一个增强版本的 T ...
- css3 @media 实现响应式布局
使用css3的@media,可以实现针对不同媒体.不同分辨率的响应式布局. 方法1:根据不同分辨率使用不同css文件 <link rel="stylesheet" media ...
- ASP.NET MVC用户登录(Memcache存储用户登录信息)
一.多站点共享用户信息解决方案: 采用分布式缓存Memcache模拟Session进行用户信息信息共享 1.视图部分
- 普通PC安装ESXi5.5以及以上的方法
原贴内容 With ESXi 5, ESX no longer uses MBR for boot, it has gone to GPT-based partitions instead. W ...
- 二叉搜索树(BST)
(第一段日常扯蛋,大家不要看)这几天就要回家了,osgearth暂时也不想弄了,毕竟不是几天就能弄出来的,所以打算过完年回来再弄.这几天闲着也是闲着,就掏出了之前买的算法导论看了看,把二叉搜索树实现了 ...
- NAT模式下VMware中CentOS7无法连接外网的解决方法
故障现象 ----------------------------------------------------------------------------------------------- ...
- QueryParser 是对一段话进行分词的 用于收集客户端发来的
- 设计模式【PHP案例】
内容来源: 波客 菜鸟教程 策略模式 在策略模式(Strategy Pattern)中,一个类的行为或其算法可以在运行时更改.这种类型的设计模式属于行为型模式. 在策略模式中,我们创建表示各种策略的对 ...
- 学习Spring Boot:(二十一)使用 EhCache 实现数据缓存
前言 当多次查询数据库影响到系统性能的时候,可以考虑使用缓存,来解决数据访问新能的问题. SpringBoot 已经为我们提供了自动配置多个 CacheManager 的实现,只要去实现使用它就可以了 ...
- 洛谷 P2764 最小路径覆盖问题 解题报告
P2764 最小路径覆盖问题 问题描述: 给定有向图\(G=(V,E)\).设\(P\) 是\(G\) 的一个简单路(顶点不相交)的集合.如果\(V\) 中每个顶点恰好在\(P\) 的一条路上,则称\ ...