ROC与AUC原理
来自:https://blog.csdn.net/shenxiaoming77/article/details/72627882
来自:https://blog.csdn.net/u010705209/article/details/53037481
在分类模型中,roc曲线和auc曲线作为衡量一个模型拟合程度的指标。
分类模型评估:
| 指标 | 描述 | Scikit-learn函数 |
| Precision | AUC | from sklearn.metrics import precision_score |
| Recall | 召回率 | from sklearn.metrics import recall_score |
| F1 | F1值 | from sklearn.metrics import f1_score |
| Confusion Matrix | 混淆矩阵 | from sklearn.metrics import confusion_matrix |
| ROC | ROC曲线 | from sklearn.metrics import confusion_matrix |
| AUC | ROC曲线下的面积 | from sklearn.metrics import auc |
回归模型评估:
| 指标 | 描述 | Scikit-learn函数 |
| Mean Square Error (MSE, RMSE) | 平均方差 | from sklearn.metrics import mean_squared_error |
| Absolute Error (MAE, RAE) | 绝对误差 | from sklearn.metrics import mean_absolute_error, median_absolute_error |
| R-Squared | R平方值 | from sklearn.metrics import r2_score |
roc和auc定义
roc全称是“受试者工作特征”(recevier operating characteristic)。roc曲线的面积就是auc(area under the curve)。auc用于衡量“二分类问题”机器学习算法性能(泛化能力)。
1. 了解roc首先了解混淆矩阵:
例如用一个分类模型来判别一个水果是苹果还是梨,混淆矩阵将会模型的预测结果总结成如下表所示的表格。
| 模型预测结果 | 模型预测结果 | ||
| 苹果 | 梨 | ||
| 真是结果 | 苹果 | 10 | 2 |
| 真是结果 | 梨 | 3 | 15 |
通过上述表格可以看出,样本的数量一共是10+2+3+15=3010+2+3+15=30个样本。其中苹果有10+2=1210+2=12个,梨有3+15=183+15=18个。该模型预测的苹果的数量是10+3=1310+3=13个,有1010个是预测正确的,33个是预测错误的。该模型预测的梨的数量是2+15=172+15=17个,其中有1515个是预测正确的,22个是预测错误的。
混淆矩阵
对于一个二分类的模型,其模型的混淆矩阵是一个2×22×2的矩阵。如下图所示:
| Predicted condition | Predicted condition | ||
| positive | negative | ||
| True condition | positive | True Positive | True Negative |
| True condition | negative | False Positive | False Negative |
混淆矩阵比模型的精度的评价指标更能够详细地反映出模型的”好坏”。模型的精度指标,在正负样本数量不均衡的情况下,会出现容易误导的结果
- True Positive:真正类(TP),样本的真实类别是正类,并且模型预测的结果也是正类。
- False Negative:假负类(FN),样本的真实类别是正类,但模型将其预测成为负类。
- False Positive:假正类(FP),样本的真实类别是负类,但模型将其预测成正类。
- True Negative:真负类(TN),样本的真实类别是负类,并且模型将其预测成为负类。
混淆矩阵中,衍生出各种评价的指标。

精度:
模型预测正确的个数 / 样本的总个数,
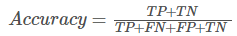
一般情况下,模型的精度越高,说明模型的效果越好。
召回率:
模型预测为正类的样本的数量,占总的正类样本数量的比值。
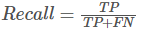
Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。
TPR:
样本中的真实正例类别总数即TP+FN。TPR即True Positive Rate,TPR = TP/(TP+FN)。
FPR:
同理,样本中的真实反例类别总数为FP+TN。FPR即False Positive Rate,FPR=FP/(TN+FP)。
截断点:
还有一个概念叫”截断点”。机器学习算法对test样本进行预测后,可以输出各test样本对某个类别的相似度概率。比如t1是P类别的概率为0.3,一般我们认为概率低于0.5,t1就属于类别N。这里的0.5,就是”截断点”。
总结一下,对于计算ROC,最重要的三个概念就是TPR, FPR, 截断点。
截断点取不同的值,TPR和FPR的计算结果也不同。将截断点不同取值下对应的TPR和FPR结果画于二维坐标系中得到的曲线,就是ROC曲线。横轴用FPR表示。
2. sklearn计算roc
sklearn给出了一个计算roc的例子:
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
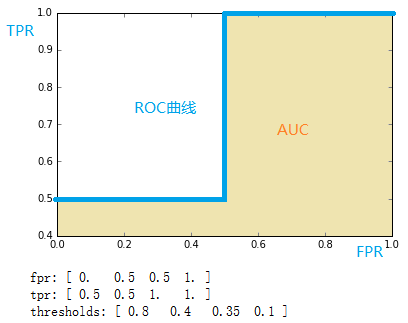
通过计算,得到的结果(TPR, FPR, 截断点)为
fpr = array([ 0. , 0.5, 0.5, 1. ])
tpr = array([ 0.5, 0.5, 1. , 1. ])
thresholds = array([ 0.8 , 0.4 , 0.35, 0.1 ]) #截断点
将结果中的FPR与TPR画到二维坐标中,得到的ROC曲线如下(蓝色线条表示),ROC曲线的面积用AUC表示(淡黄色阴影部分)。
详细计算过程:
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
(1). 分析数据
y是一个一维数组(样本的真实分类)。数组值表示类别(一共有两类,1和2)。我们假设y中的1表示反例,2表示正例。即将y重写为:
y_true = [0, 0, 1, 1]
score即各个样本属于正例的概率。
(2). 针对score,将数据排序
| 样本 | 预测属于P的概率(score) | 真实类别 |
| y[0] | 0.1 | N |
| y[2] | 0.35 | P |
| y[1] | 0.4 | N |
| y[3] | 0.8 | P |
(3). 将截断点依次取值为score值
将截断点依次取值为0.1, 0.35, 0.4, 0.8时,计算TPR和FPR的结果。
3.1. 截断点为.01
说明只要score>=0.1,它的预测类别就是正例。
此时,因为4个样本的score都大于等于0.1,所以,所有样本的预测类别都为P。
scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [1, 1, 1, 1]

TPR = TP/(TP+FN) = 1
FPR = FP/(TN+FP) = 1
3.2. 截断点为0.35
说明只要score>=0.35,它的预测类别就是P。
此时,因为4个样本的score有3个大于等于0.35。所以,所有样本的预测类有3个为P(2个预测正确,1一个预测错误);1个样本被预测为N(预测正确)。
scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [0, 1, 1, 1]
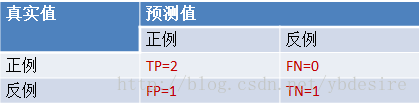
TPR = TP/(TP+FN) = 1
FPR = FP/(TN+FP) = 0.5
3.3. 截断点为0.4
说明只要score>=0.4,它的预测类别就是P。
此时,因为4个样本的score有2个大于等于0.4。所以,所有样本的预测类有2个为P(1个预测正确,1一个预测错误);2个样本被预测为N(1个预测正确,1一个预测错误)。
scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [0, 1, 0, 1]

TPR = TP/(TP+FN) = 0.5
FPR = FP/(TN+FP) = 0.5
3.4. 截断点为0.8
说明只要score>=0.8,它的预测类别就是P。所以,所有样本的预测类有1个为P(1个预测正确);3个样本被预测为N(2个预测正确,1一个预测错误)。
scores = [0.1, 0.4, 0.35, 0.8]
y_true = [0, 0, 1, 1]
y_pred = [0, 0, 0, 1]

TPR = TP/(TP+FN) = 0.5
FPR = FP/(TN+FP) = 0
(4). 心得
用下面描述表示TPR和FPR的计算过程,更容易记住
- TPR:真实的正例中,被预测正确的比例
- FPR:真实的反例中,被预测正确的比例
ROC与AUC原理的更多相关文章
- 机器学习-Confusion Matrix混淆矩阵、ROC、AUC
本文整理了关于机器学习分类问题的评价指标——Confusion Matrix.ROC.AUC的概念以及理解. 混淆矩阵 在机器学习领域中,混淆矩阵(confusion matrix)是一种评价分类模型 ...
- ROC和AUC介绍以及如何计算AUC ---好!!!!
from:https://www.douban.com/note/284051363/?type=like 原帖发表在我的博客:http://alexkong.net/2013/06/introduc ...
- Area Under roc Curve(AUC)
AUC是一种用来度量分类模型好坏的一个标准. ROC分析是从医疗分析领域引入了一种新的分类模型performance评判方法. ROC的全名叫做Receiver Operating Character ...
- 【转】ROC和AUC介绍以及如何计算AUC
转自:https://www.douban.com/note/284051363/ ROC(Receiver Operating Characteristic)曲线和AUC常被用来评价一个二值分类器( ...
- ROC和AUC介绍以及如何计算AUC
原文:http://alexkong.net/2013/06/introduction-to-auc-and-roc/ 为什么使用ROC曲线 既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因 ...
- ROC和AUC理解
一. ROC曲线概念 二分类问题在机器学习中是一个很常见的问题,经常会用到.ROC (Receiver Operating Characteristic) 曲线和 AUC (Area Under th ...
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
原文地址:http://blog.csdn.net/pkueecser/article/details/8229166 在信息检索.分类体系中,有一系列的指标,搞清楚这些指标对于评价检索和分类性能非常 ...
- 评估分类器性能的度量,像混淆矩阵、ROC、AUC等
评估分类器性能的度量,像混淆矩阵.ROC.AUC等 内容概要¶ 模型评估的目的及一般评估流程 分类准确率的用处及其限制 混淆矩阵(confusion matrix)是如何表示一个分类器的性能 混淆矩阵 ...
- ROC,AUC,Precision,Recall,F1的介绍与计算(转)
1. 基本概念 1.1 ROC与AUC ROC曲线和AUC常被用来评价一个二值分类器(binary classifier)的优劣,ROC曲线称为受试者工作特征曲线 (receiver operatin ...
随机推荐
- webVR框架A-frame
A-frame:https://blog.csdn.net/sun124608666/article/details/77869570 three.js学习文档:http://www.hewebgl. ...
- python的os模块中的os.walk()函数
os.walk('path')函数对于每个目录返回一个三元组,(dirpath, dirnames, filenames), 第一个是路径,第二个是路径下面的目录,第三个是路径下面的文件 如果加参数t ...
- centos7.3安装MongoDB
安装步骤: 1.配置包管理系统 vim /etc/yum.repos.d/mongodb.repo [mongodb] name=MongoDB Repository baseurl=http://d ...
- axure rp 8.0注册码(亲测)
今天在看一需求原型时,发现其他部门发过来是8.0版的,老的7不能用,找了个亲测可用的验证码. License:米 业成 (STUDENT)Key:nFmqBBvEqdvbiUjy8NZiyWiRSg3 ...
- 面试必问:Spring循环依赖的三种方式
引言:循环依赖就是N个类中循环嵌套引用,如果在日常开发中我们用new 对象的方式发生这种循环依赖的话程序会在运行时一直循环调用,直至内存溢出报错.下面说一下Spring是如果解决循环依赖的. 第一种: ...
- k8s device plugin
基本概念入门: Device Manager Proposal Device plugin offical Doc(中文) device-plugins offical Doc(En) Go thro ...
- 20145308 《网络对抗》 MAL_免杀原理及实践 学习总结
20145308 <网络对抗> MAL_免杀原理及实践 学习总结 实践内容 (1)理解免杀技术原理 (2)正确使用msf编码器,veil-evasion,自己利用shellcode编程等免 ...
- 定制FileField中的上传文件名称
FileField中的upload_to属性可以设定上传文件的存储目录和名称,它可以是个字符串,也可以是个callable,比如一个方法. 当upload_to的值设为一个方法时,就可以对上传文件的名 ...
- 一、数据库表中字段的增删改查,二、路由基础.三、有名无名分组.四、多app共存的路由分配.五、多app共存时模板冲突问题.六、创建app流程.七、路由分发.八、路由别名,九、名称空间.十、反向解析.十一、2.x新特性.十二、自定义转换器
一.数据库表中字段的增删改查 ''' 直接在modules中对字段进行增删改查 然后在tools下点击Run manage.py Task执行makemigrations和migrate 注意在执行字 ...
- python --- 19 判断对象所属,区分函数和对象, 反射
一.判断对象所属 isinstance, type , issubclass 1.issubclass(x,y) 判断x是否是y 的子类 2.type(x) 精准返回x 的数据类型 3.isi ...