python字典和列表的高级应用
1.将序列分解为单独的变量
1.1问题
包含n个元素的元组或列表、字符串、文件、迭代器、生成器,将它分解为n个变量
1.2方案
直接通过赋值操作
要求:变量个数要等于元素个数

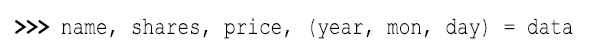

当执行分解操作时,有时需要丢弃某些特定的值,通常选一个用不到的变量来赋值就可以了
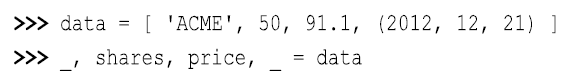
其中_代表不用的变量
2.从任意长度的可迭代对象中分解元素
问题:需要从可迭代的对象中分解n个值,但可迭代对象可能超过n,这就会导致‘too many values to unpack’的异常
解决:*表达式

注意:*变量 输出的是列表
如果*变量 放在第一个位置,那么会将前len(n)-1个值赋给*变量,最后一个值赋给其他变量




2.保存最后n个元素
|
1
2
3
4
5
6
7
8
9
|
from collections import deque#保存有限的历史记录,保存最新的n个元素,#deque(maxlen=N)创建了一个固定长度的队列,当有新记录加入队列而队列已满,会自动移除最老的记录或元素q=deque(maxlen=3)q.append(1)q.append(2)q.append(3)<br>#队列已满q.append(4)q.append(5) |
print(q)
3.找到最大和最小的n个元素
3.1 n=1
max,min
3.2 n<<N #要找的元素个数n 远远小于 元素总数N
|
1
2
3
4
5
6
|
import heapqnums=[1,8,2,23,7,-4,18,23,42,37,2]heapq.heapify(nums) #进行堆排序,并更新原列表print(nums)#堆最重要的特性是nums[0]永远是最小的那个元素print(heapq.heappop(nums)) #弹出最小的nums[0],并以第二小的元素取而代之 |
3.3 n<N #要找的元素个数n 相对小于 元素总数N
|
1
2
3
4
|
import heapqnums=[1,8,2,23,7,-4,18,23,42,37,2]print(heapq.nlargest(3,nums))print(heapq.nsmallest(3,nums)) |
3.4 n<N #要找的元素个数n 几乎接近 元素总数N
|
1
2
3
4
5
|
import heapqnums=[1,8,2,23,7,-4,18,23,42,37,2]nums1= sorted(nums)[:7] #切出最小的7个元素nums2= sorted(nums)[-7:] #切出最大的7个元素print(nums1,nums2) |
4.根据列表中字典的key对列表进行筛选
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import heapqp=[{'name':'ibm','shares':100,'prices':91.11}, {'name':'apple','shares':50,'prices':543.31}, {'name':'t','shares':150,'prices':21.51}, {'name':'mi','shares':30,'prices':441.16}, {'name':'360','shares':10,'prices':61.81}, {'name':'car','shares':80,'prices':221.51}]#s:要排序的元素#s['prices']以元素的key=['prices']进行排序cheap=heapq.nsmallest(3,p,key=lambda s:s['prices'])expensive=heapq.nlargest(3,p,key=lambda s:s['prices'])print(cheap,'\n',expensive) |
5.在两个字典中寻找相同点(集合的应用)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
a={ 'x':1, 'y':2, 'z':3}b={ 'w':10, 'x':11, 'y':2}#find keys in commonc=a.keys()& b.keys()print(c)#find keys in a that are not in bd=a.keys() - b.keys()print(d)#find keys,values in commone=a.items()& b.items()print(e) |
6.不排序且不改变原列表,实现列表有序5种方法

方法一:
思路:使用集合,对原集合和新产生的最小值集合取差集,每次取差集的最小值,插入新集合的首位。
代码实现:
|
1
2
3
4
5
6
7
|
l1=[99,999,-5,-66,-25,663,3]l2=[] #存每次找到的最小值for i in range(len(l1)): a=set(l1)-(set(l1)&set(l2)) l2.insert(0,min(a))l2=list(l2)print(l2) |
方法二:
思路:1.最小值寻找思路:首先找出最大值,并赋值给最小值变量,循环列表的每个元素,当有元素小于当前最小变量,则把该元素重新赋值给最小变量,这样就得到了一个列表的最小值。
2.整体思路:将最小值插入到新列表,重复1,在循环中加判断,如果元素不是已经找过的最小值(已添加到新列表中),则执行找最小值的循环
代码实现:
|
1
2
3
4
5
6
7
8
9
10
|
li1=[1,3,66,5,4,-1,-100,54]li2=[]for j in range(len(li1)): m=max(li1) for i in li1: if i not in li2: if i <m: m=i li2.insert(0,m)print(li2) |
方法三:
思路:1.寻找最小值,让最小值变量等于列表的第一个元素(且不是已经找到的最小值,即不属于列表l2,如果属于列表l2,则跳过该元素),循环整个列表,
如果有元素(该元素也不能是已找到的最小值,如果是,则跳过)小于当前最小值,则把该元素赋值给最小值。
2.本程序是根据列表元素的索引判断是否是已经找到的最小值
代码实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def tiaoguo(s): #跳过已找过的索引 if s in l3: return 'y'l1=[99,999,-5,-66,-25,663,3]l2=[] #存每次找到的最小值l3=[] #存已使用的索引c=l1[0] #for j in range(len(l1)): for i in range(len(l1)-j): if len(l2)==len(l1): break if tiaoguo(i)=='y': #遇到已经找过的最小值,进行跳过处理 continue if c>l1[i]: c=l1[i] l2.insert(0,c) l3.append(l1.index(c)) #把最小值的索引存在l3中 for k in range(len(l1)): #更新最小值 if tiaoguo(k)=='y': continue else: c=l1[k]print(l2) |
方法四:
思路:方法四和方法三整体思路一致,是方法三的改进版。
代码实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def list_sort(l1): l2=[] the_num = [] while (len(l1)>len(the_num)): temp = max(l1) #避免了方法三中首次给最小值变量赋值可能出现该值是已经找到的最小值的情况,因为max(l1)只有最后一次才会出现在l2中 for i in range(len(l1)): if i in the_num: # 如果是已经找到的最小值的索引,则continue continue if l1[i] <= temp: temp = l1[i] num = i the_num.append(num) l2.insert(0,temp) return l2if __name__ == '__main__': l1 = [1, 3, 66, 5, 4, -1, -100, 54] result = list_sort(l1) print(result) |
方法五:
思路:本程序是根据下一次寻找的最小值是大于上一次寻找的最小值(列表lis2[0]),且是所有大于lis2[0]的元素中的最小值。
代码实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def sour(lis1, lis2): xia = lis2[0] for i in range(len(lis1)): if lis2[0] < lis1[i]: xia = lis1[i] # 所有大于list[0]的数 for j in range(len(lis1)): if lis1[j] > lis2[0] and lis1[j] < xia: # 找到大于lis2[0]最小的数 xia = lis1[j] return xia<br>lis1 = [3, 44, 55, 2, 45, 98, 99, -1, -4, 0, -98, -65]lis2 = []lis2.append(min(lis1))for i in range(len(lis1)-1): lis2.insert(0, sour(lis1, lis2))print(lis2) |
python字典和列表的高级应用的更多相关文章
- python 字典和列表嵌套用法
python中字典和列表的使用,在数据处理中应该是最常用的,这两个熟练后基本可以应付大部分场景了.不过网上的基础教程只告诉你列表.字典是什么,如何使用,很少做组合说明. 刚好工作中采集promethe ...
- python 字典,列表,集合,字符串,基础进阶
python列表基础 首先当然是要说基础啦 列表list 1.L.append(object) -> None 在列表末尾添加单个元素,任何类型都可以,包括列表或元组等 2.L.extend(i ...
- Python 字典和列表的对比应用
Q:将下列格式的txt文件,打印出该选手的3个最快跑步时间 james2.txt =>“James Lee,2002-3-14,2-34,3:21,2.34,2.45,3.01,2:01,2:0 ...
- python 字典、列表、字符串 之间的转换
1.列表与字符串转换 1)列表转字符串: 将列表中的内容拼接成一个字符串 将列表中的值转成字符串 2)字符串转列表: 用eval转换 将字符串每个字符转成列表中的值 将字符串按分割成列表 2.列表与字 ...
- python字典和列表使用
一.字典中健值为列表或字典 1 a.setdefault(key,[]).append(b)--键值是列表 2 a.setdefault(key,{}).append(b)--键值是字典 二.键值为列 ...
- python字典推导&&列表推导&&输出随机数
字典推导: x = ['A', 'B', 'C', 'D'] y = ['Alice', 'Bob', 'Cecil', 'David'] print({i:j for i,j in zip(x,y) ...
- python字典和列表使用的要点
dicts = {} lists = [] dicts['name'] = 'zhangsan' lists.append(dicts) 这时候lists的内容应该是[{'name': 'zhangs ...
- python字典中列表追加数据
dict = {} for i in range(1, 6): if i not in dict: dict[i] = [] for j in range(101, 106): dict[i].app ...
- python字典里面列表排序
#coding=utf8 #获取到的数据库ip,和负载数据,需要按照负载情况排序 a={u'1.8.1.14': [379, 368, 361, 358, 1363], u'9.2.4.3': [42 ...
随机推荐
- 用tsMuxeR GUI给ts视频添加音轨
收藏比赛的都应该知道,高清的直播流录制了后一般是ts或者mkv封装,前者用tsMuxeR GUI可以对视频音频轨进行操作,后者用mkvtoolnix,两者都是无损操作. 至于其他格式就不考虑了,随便用 ...
- Educational Codeforces Round 23 E. Choosing The Commander trie数
E. Choosing The Commander time limit per test 2 seconds memory limit per test 256 megabytes input st ...
- Git 基础 - 打标签
列出现有标签(或者使用git tag -l) $ git tag v0. v1. 如果只对 1.4.2 系列的版本感兴趣 $ git tag -l 'v1.4.2.*' v1. v1. v1. v1. ...
- SQL Server DATEADD() 函数及实际项目应用注意事项
1. DATEADD() 函数的解释和语法分析 DATEADD() 函数在日期中添加或减去指定的时间间隔. 语法: DATEADD(datepart,number,date) date 参数是合法的日 ...
- STL——vector
学到STL的vector,发现手中的材料不是很详细,这里做个汇总. 1 操作 (1)头文件#include<vector>. (2)创建vector对象,vector<int> ...
- 学习笔记28—Python 不同数据类型取值方法
1.array数据类型 1)-------> y[i,] 或者 y[i] 2.遍历目录下所有文件夹: def eachFile(filepath): pathDir = os.list ...
- Java中的包扫描(工具)
在现在好多应用场景中,我们需要得到某个包名下面所有的类, 包括我们自己在src里写的java类和一些第三方提供的jar包里的类,那么怎么来实现呢? 今天带大家来完成这件事. 先分享代码: 1.这个类是 ...
- ASP.NET 4.x Web Api Odata v4 backend modify query 修改查询
有时候我们会想给予权限添加 filter 到查询上. 比如 会员和管理员都使用了 /api/products 作为 product 查询 但是会员不应该可以看见还没有上架的货品 /api/produc ...
- 最长连续子序列 Longest Consecutive Sequence
2018-11-25 16:28:09 问题描述: 问题求解: 方法一.如果不要求是线性时间的话,其实可以很直观的先排序在遍历一遍就可以得到答案,但是这里明确要求是O(n)的时间复杂度,那么就给了一个 ...
- webpack添加热更新
之前的wbepack一直没有加上热更新,这是一种遗憾,今天终于加上去了,看不懂我博客的可以看这篇文章:http://blog.csdn.net/hyy1115/article/details/5302 ...