MapReduce- 数据的排序处理
MapReduce- 数据的排序处理
package com.huhu.day02;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
/**
* 6 9
* 3 8
* 4 8
* 1 0
* 3 0
* 8 8
* 6 7
* 第一列升序,第二列降序
* @author huhu_k
*
*/
public class Number implements WritableComparable<Number> {
private int first;
private int second;
// private int third;
public Number() {
super();
}
public Number(int first, int second) {
super();
this.first = first;
this.second = second;
}
public int getFirst() {
return first;
}
public void setFirst(int first) {
this.first = first;
}
public int getSecond() {
return second;
}
public void setSecond(int second) {
this.second = second;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + first;
result = prime * result + second;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Number other = (Number) obj;
if (first != other.first)
return false;
if (second != other.second)
return false;
return true;
}
@Override
public String toString() {
return "Number [first=" + first + ", second=" + second + "]";
}
@Override
public void readFields(DataInput in) throws IOException {
this.first = in.readInt();
this.second = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(this.first);
out.writeInt(this.second);
}
@Override
public int compareTo(Number o) {
if (this.first== o.first) {
//第二行数据降序
return o.second - this.second;
}
//第一行升序
return this.first - o.first;
}
}
package com.huhu.day02;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class NumericSorting extends ToolRunner implements Tool {
public static class MyMapper extends Mapper<LongWritable, Text, Number, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(" ");
Number number = null;
if (line.length == 2) {
number = new Number(Integer.parseInt(line[0]), Integer.parseInt(line[1]));
}
context.write(number, NullWritable.get());
}
}
public static class MyReduce extends Reducer<Number, NullWritable, Number, Text> {
@Override
protected void reduce(Number key, Iterable<NullWritable> values, Context context)
throws IOException, InterruptedException {
for (NullWritable n : values) {
context.write(key, new Text("---"));
}
}
}
@Override
public Configuration getConf() {
return new Configuration();
}
@Override
public void setConf(Configuration arg0) {
}
@Override
public int run(String[] other) throws Exception {
Job job = Job.getInstance(getConf(), "NumbericSorting");
job.setJarByClass(NumericSorting.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Number.class);
job.setMapOutputValueClass(NullWritable.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Number.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(other[0]));
FileOutputFormat.setOutputPath(job, new Path(other[1]));
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] other = new GenericOptionsParser(conf, args).getRemainingArgs();
if (other.length != 2) {
System.out.println("your input args number is fail,you need input <in> and <out>");
System.exit(0);
}
ToolRunner.run(conf, new NumericSorting(), other);
}
}
运行结果:
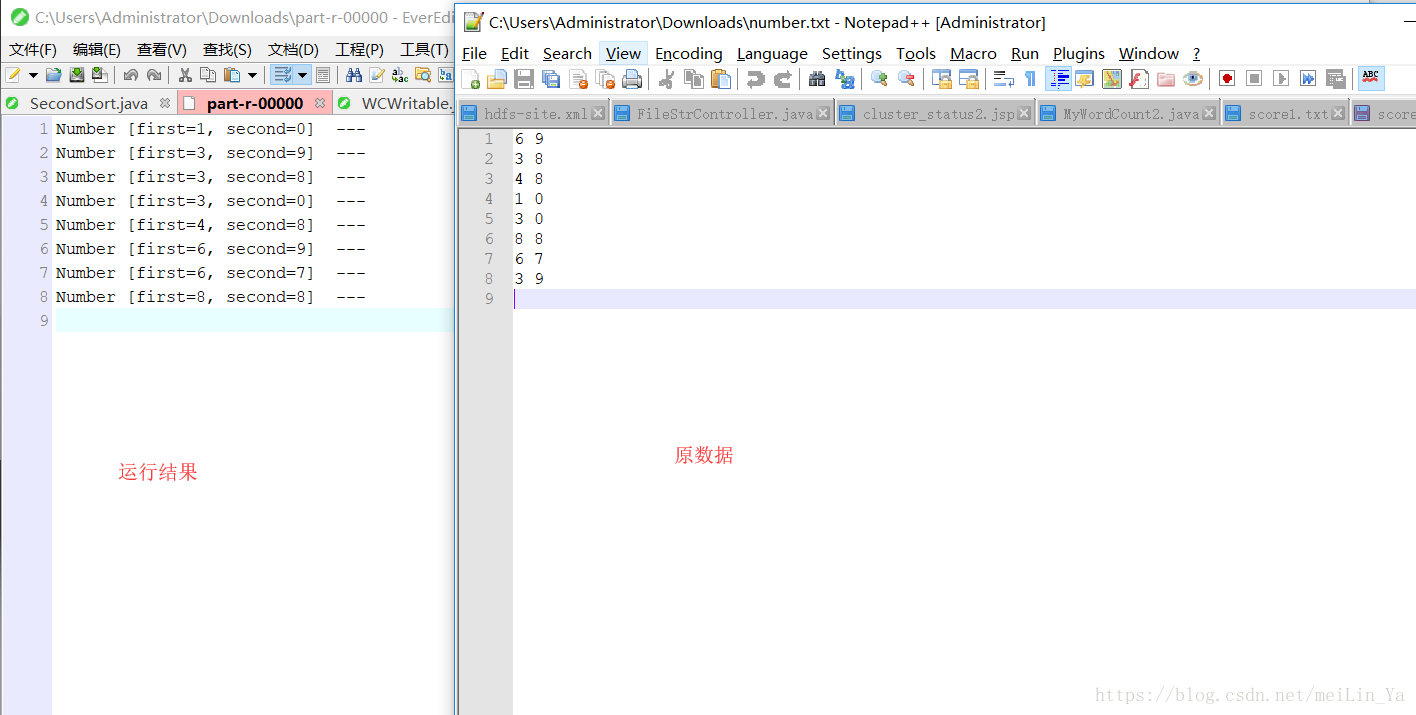
MapReduce- 数据的排序处理的更多相关文章
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- MapReduce二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- (转)MapReduce二次排序
一.概述 MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的.在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- 关于MapReduce二次排序的一点解答
上一篇博客说明了怎么自定义Key,而且用了二次排序的例子来做测试,但没有详细的说明二次排序,这一篇说详细的说明二次排序,为了说明曾经一个思想的误区,特地做了一个3个字段的二次排序来说明.后面称其为“三 ...
- mapreduce 实现数子排序
设计思路: 使用mapreduce的默认排序,按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String ...
- 详细讲解MapReduce二次排序过程
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hi ...
- MapReduce 二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- Spark 颠覆 MapReduce 保持的排序记录
在过去几年,Apache Spark的採用以惊人的速度添加着,通常被作为MapReduce后继,能够支撑数千节点规模的集群部署. 在内存中数 据处理上,Apache Spark比MapReduce更加 ...
- mapreduce数据处理——统计排序
接上篇https://www.cnblogs.com/sengzhao666/p/11850849.html 2.数据处理: ·统计最受欢迎的视频/文章的Top10访问次数 (id) ·按照地市统计最 ...
随机推荐
- python学习 day013打卡 内置函数
本节主要内容: 内置函数: 内置函数就是python给你提供的.拿来直接用的函数,比如print,input等等.截止到python版本3.6.2 python一共提供了68个内置函数.他们就是pyt ...
- springboot集成logback日志
简介 spring boot内部使用Commons Logging来记录日志,但也保留外部接口可以让一些日志框架来进行实现,例如Java Util Logging,Log4J2还有Logback. 如 ...
- P3146 [USACO16OPEN]248 & P3147 [USACO16OPEN]262144
注:两道题目题意是一样的,但是数据范围不同,一个为弱化版,另一个为强化版. P3146传送门(弱化版) 思路: 区间动规,设 f [ i ][ j ] 表示在区间 i ~ j 中获得的最大值,与普通区 ...
- jmeter学习四配置元件详解
JMeter提供的配置元件中的HTTP属性管理器用于尽可能模拟浏览器行为,在HTTP协议层上发送给被测应用的http请求 1.Http信息头管理器 用于定制Sampler发出的HTTP请求的请求头的内 ...
- git 修改默认编辑器
vim,notepad(windows自带),notepad++ 当然要选notepad++ 1.首先下载notepad++ 2.将notepad++安装目录放到path中 3.git config ...
- Ajax_请求get,post案例
1. 最原始的ajax请求方式 (1). get请求 <%@ Page Language="C#" AutoEventWireup="true" Code ...
- 力扣(LeetCode)965. 单值二叉树
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树. 只有给定的树是单值二叉树时,才返回 true:否则返回 false. 思路 递归 java版 /** * Definition for ...
- Java se基础(类的属性及关键字)
public:说明该类的访问类型是公有的,它生成的对象能被其他的对象调用! abstract:用来声明抽象类! final;如果一个类被声明成final类型,那么就不能再由它派生出子类. 可以简单的看 ...
- 04-python-闭包
1.闭包的概念: 官方概念:在一些语言中,在函数中可以(嵌套)定义另一个函数时,如果内部的函数引用了外部的函数的变量,则可能产生闭包.闭包可以用来在一个函数与一组"私有"变量之间创 ...
- css的table布局
1.table中对tr设置margin-top是没有作用的.