Python爬虫之正则表达式的使用(三)
正则表达式的使用
re.match(pattern,string,flags=0)
re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
参数介绍:
pattern:正则表达式
string:匹配的目标字符串
flags:匹配模式
正则表达式的匹配模式:
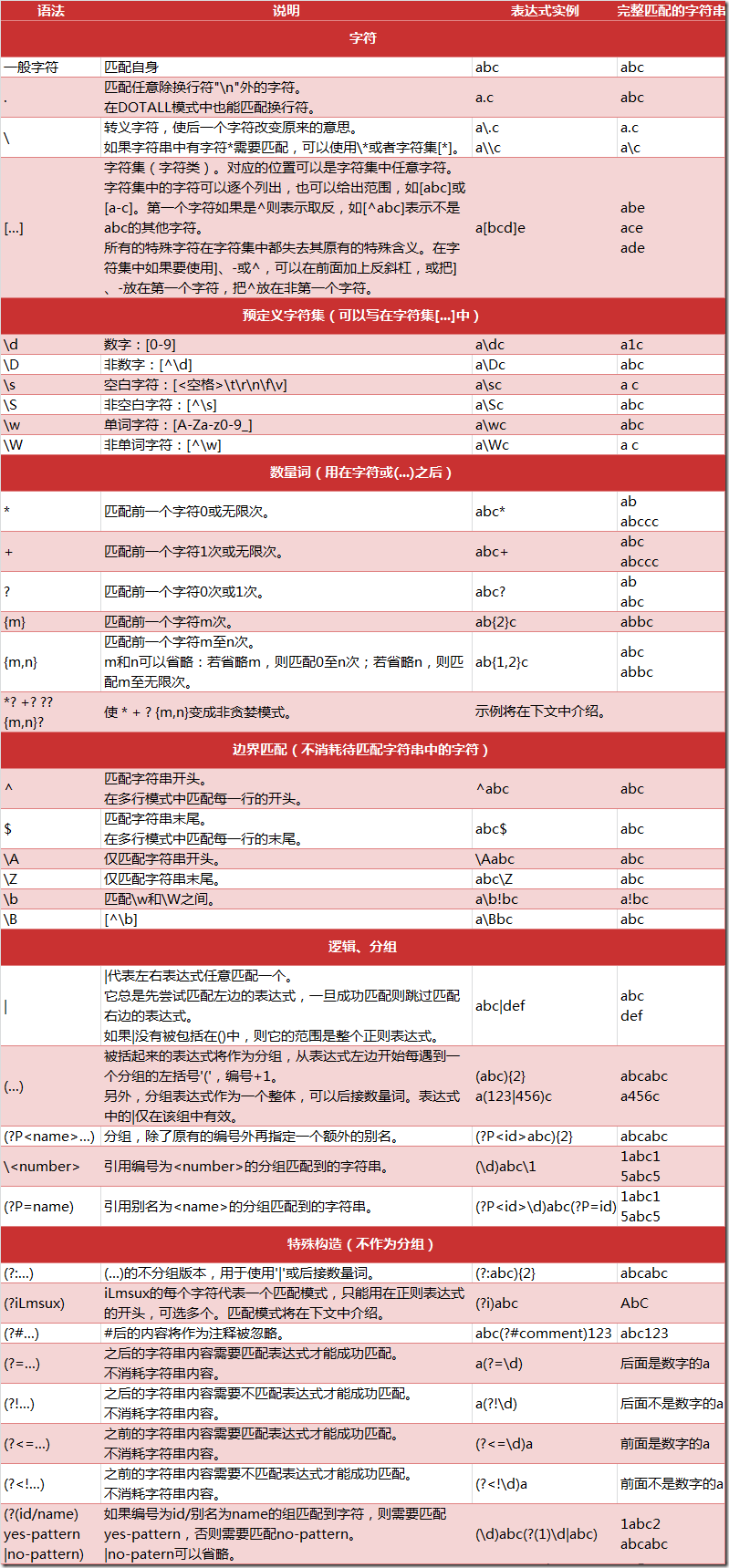
最常规的匹配
import re
content ='hello 123456 World_This is a Regex Demo'
print(len(content))
result = re.match('^hello\s\d{6}\s\w{10}.*Demo$$',content)
print(result)
print(result.group()) #返回匹配结果
print(result.span()) #返回匹配结果的范围
结果运行如下:
39
<_sre.SRE_Match object; span=(0, 39), match='hello 123456 World_This is a Regex Demo'>
hello 123456 World_This is a Regex Demo
(0, 39)
泛匹配
使用(.*)匹配更多内容
import re
content ='hello 123456 World_This is a Regex Demo'
result = re.match('^hello.*Demo$',content)
print(result) print(result.group())
结果运行如下:
<_sre.SRE_Match object; span=(0, 39), match='hello 123456 World_This is a Regex Demo'>
hello 123456 World_This is a Regex Demo
匹配目标
在正则表达式中使用()将要获取的内容括起来
使用group(1)获取第一处,group(2)获取第二处,如此可以提取我们想要获取的内容
import re
content ='hello 123456 World_This is a Regex Demo'
result = re.match('^hello\s(\d{6})\s.*Demo$',content)
print(result)
print(result.group(1))#获取匹配目标
结果运行如下:
<_sre.SRE_Match object; span=(0, 39), match='hello 123456 World_This is a Regex Demo'>
123456
贪婪匹配
import re
content ='hello 123456 World_This is a Regex Demo'
result = re.match('^he.*(\d+).*Demo$',content)
print(result)
print(result.group(1))
注意:.*会尽可能的多匹配字符
非贪婪匹配
import re
content ='hello 123456 World_This is a Regex Demo'
result = re.match('^he.*?(\d+).*Demo$',content)
print(result)
print(result.group(1))
注意:.*?会尽可能匹配少的字符
使用匹配模式
在解析HTML代码时会有换行,这时我们就要使用re.S
import re
content ='hello 123456 World_This ' \
'is a Regex Demo'
result = re.match('^he.*?(\d+).*?Demo$',content,re.S)
print(result)
print(result.group(1))
运行结果如下:
<_sre.SRE_Match object; span=(0, 39), match='hello 123456 World_This is a Regex Demo'>
123456
转义
在解析过程中遇到特殊字符,就需要做转义,比如下面的$符号。
import re
content = 'price is $5.00'
result = re.match('^price.*\$5\.00',content)
print(result.group())
总结:尽量使用泛匹配,使用括号得到匹配目标,尽量使用非贪婪模式,有换行就用re.S
re.search(pattern,string,flags=0)
re.search扫描整个字符串并返回第一个成功的匹配。
比如我想要提取字符串中的123456,使用match方法无法提取,只能使用search方法。
import re
content ='hello 123456 World_This is a Regex Demo'
result = re.match('\d{6}',content)
print(result)
import re
content ='hello 123456 World_This is a Regex Demo'
result = re.search('\d{6}',content)
print(result)
print(result.group())
运行结果如下:
<_sre.SRE_Match object; span=(6, 12), match='123456'>
123456
匹配演练
可以匹配代码里结构相同的部分,这样可以返回你需要的内容
import re
content = '<a title="2009年中信出版社出版图书" href="/doc/2703035-2853985.html" target="_blank" data-log="old:2703035-2853885,new:2703035-2853985" data-cid="sense-list">2009年中信出版社出版图书</a>'
result = re.search('<a.*?new:\d{7}-\d{7}.*?>(.*?)</a>',content)
print(result.group(1))
2009年中信出版社出版图书
re.findall(pattern,string,flags=0)
搜索字符串,以列表形式返回全部能匹配的字串
import re
html ='''
<li>
<a title="网络歌曲" href="/doc/2703035-2853927.html" target="_blank" data-log="old:2703035-2853885,new:2703035-2853927" data-cid="sense-list">网络歌曲</a>
</li>
<li>
<a title="2009年中信出版社出版图书" href="/doc/2703035-2853985.html" target="_blank" data-log="old:2703035-2853885,new:2703035-2853985" data-cid="sense-list">2009年中信出版社出版图书</a>
</li>
'''
result = re.findall('<a.*?new:\d{7}-\d{7}.*?>(.*?)</a>',html,re.S)
count = 0
for list in result:
print(result[count])
count+=1
网络歌曲
2009年中信出版社出版图书
re.sub( pattern,repl,string,count,flags)
re.sub共有五个参数
三个必选参数 pattern,repl,string
两个可选参数count,flags
替换字符串中每一个匹配的字符串后替换后的字符串
import re
content = 'hello 123456 World_This is a Regex Demo'
content = re.sub('\d+','',content)
print(content)
运行结果如下:
hello World_This is a Regex Demo
import re
content = 'hello 123456 World_This is a Regex Demo'
content = re.sub('\d+','what',content)
print(content)
运行结果如下:
hello what World_This is a Regex Demo
import re
content = 'hello 123456 World_This is a Regex Demo'
content = re.sub('(\d+)',r'\1 789',content)
print(content)
运行结果如下:
hello 123456 789 World_This is a Regex Demo
注意:这里\1代表前面匹配的123456
演练
在这里我们替换li标签
import re
html ='''
<li>
<a title="网络歌曲" href="/doc/2703035-2853927.html" target="_blank" data-log="old:2703035-2853885,new:2703035-2853927" data-cid="sense-list">网络歌曲</a>
</li>
<li>
<a title="2009年中信出版社出版图书" href="/doc/2703035-2853985.html" target="_blank" data-log="old:2703035-2853885,new:2703035-2853985" data-cid="sense-list">2009年中信出版社出版图书</a>
</li>
'''
html = re.sub('<li>|</li>','',html)
print(html)
运行结果如下,里面就没有li标签
<a title="网络歌曲" href="/doc/2703035-2853927.html" target="_blank" data-log="old:2703035-2853885,new:2703035-2853927" data-cid="sense-list">网络歌曲</a> <a title="2009年中信出版社出版图书" href="/doc/2703035-2853985.html" target="_blank" data-log="old:2703035-2853885,new:2703035-2853985" data-cid="sense-list">2009年中信出版社出版图书</a>
compile(pattern [, flags])
该函数根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的匹配
将正则表达式编译成正则表达式对象,以便于复用该匹配模式
import re
content = 'hello 123456 ' \
'World_This is a Regex Demo'
pattern = re.compile('hello.*?Demo',re.S)
result = re.match(pattern,content)
print(result.group())
运行结果如下:
hello 123456 World_This is a Regex Demo
综合使用
import re html = '''
<div class="slide-page" style="width: 700px;" data-index="1"> <a class="item" target="_blank" href="https://movie.douban.com/subject/26725678/?tag=热门&from=gaia"> <div class="cover-wp" data-isnew="false" data-id="26725678">
<img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2525020357.jpg" alt="解除好友2:暗网" data-x="694" data-y="1000">
</div>
<p> 解除好友2:暗网 <strong>7.9</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/26916229/?tag=热门&from=gaia_video"> <div class="cover-wp" data-isnew="false" data-id="26916229">
<img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2532008868.jpg" alt="镰仓物语" data-x="2143" data-y="2993">
</div>
<p> 镰仓物语 <strong>6.9</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/26683421/?tag=热门&from=gaia"> <div class="cover-wp" data-isnew="false" data-id="26683421">
<img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2528281606.jpg" alt="特工" data-x="690" data-y="986">
</div>
<p> 特工 <strong>8.3</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/27072795/?tag=热门&from=gaia"> <div class="cover-wp" data-isnew="false" data-id="27072795">
<img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2521583093.jpg" alt="幸福的拉扎罗" data-x="640" data-y="914">
</div>
<p> 幸福的拉扎罗 <strong>8.6</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/27201353/?tag=热门&from=gaia_video"> <div class="cover-wp" data-isnew="false" data-id="27201353">
<img src="https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2528842218.jpg" alt="大师兄" data-x="679" data-y="950">
</div>
<p> 大师兄 <strong>5.2</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/30146756/?tag=热门&from=gaia_video"> <div class="cover-wp" data-isnew="false" data-id="30146756">
<img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2530872223.jpg" alt="风语咒" data-x="1079" data-y="1685">
</div>
<p> 风语咒 <strong>6.9</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/26630714/?tag=热门&from=gaia"> <div class="cover-wp" data-isnew="false" data-id="26630714">
<img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2530591543.jpg" alt="精灵旅社3:疯狂假期" data-x="1063" data-y="1488">
</div>
<p> 精灵旅社3:疯狂假期 <strong>6.8</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/25882296/?tag=热门&from=gaia_video"> <div class="cover-wp" data-isnew="false" data-id="25882296">
<img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2526405034.jpg" alt="狄仁杰之四大天王" data-x="2500" data-y="3500">
</div>
<p> 狄仁杰之四大天王 <strong>6.2</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/26804147/?tag=热门&from=gaia_video"> <div class="cover-wp" data-isnew="false" data-id="26804147">
<img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2527484082.jpg" alt="摩天营救" data-x="1371" data-y="1920">
</div>
<p> 摩天营救 <strong>6.4</strong> </p>
</a> <a class="item" target="_blank" href="https://movie.douban.com/subject/24773958/?tag=热门&from=gaia_video"> <div class="cover-wp" data-isnew="false" data-id="24773958">
<img src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p2517753454.jpg" alt="复仇者联盟3:无限战争" data-x="1968" data-y="2756">
</div>
<p> 复仇者联盟3:无限战争 <strong>8.1</strong> </p>
</a>
</div>
'''
count = 0
for list in result:
print(result[count])
count+=1
运行结果如下:
('解除好友2:暗网', '7.9')
('镰仓物语', '6.9')
('特工', '8.3')
('幸福的拉扎罗', '8.6')
('大师兄', '5.2')
('风语咒', '6.9')
('精灵旅社3:疯狂假期', '6.8')
('狄仁杰之四大天王', '6.2')
('摩天营救', '6.4')
('复仇者联盟3:无限战争', '8.1')
正则表达式匹配IP
#IPv4的IP正则匹配表达式
import re
#简单的匹配给定的字符串是否是ip地址,下面的例子它不是IPv4的地址,但是它满足正则表达式
if re.match(r"^(?:[0-9]{1,3}\.){3}[0-9]{1,3}$", "272.168,1,1"):
print "IP vaild"
else:
print "IP invaild"
#精确的匹配给定的字符串是否是IP地址
if re.match(r"^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$", "223.168.1.1"):
print "IP vaild"
else:
print "IP invaild"
#简单的从长文本中提取中提取ip地址
string_ip = "is this 289.22.22.22 ip ?
result = re.findall(r"\b(?:[0-9]{1,3}\.){3}[0-9]{1,3}\b", string_ip)
if result:
print result
else:
print "re cannot find ip"
#精确提取IP
result = re.findall(r"\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b", string_ip):
if result:
print result
else:
print "re cannot find ip #IPv6的正则匹配表达式
string_IPv6="1050:0:0:0:5:600:300c:326b"
#匹配是否满足IPv6格式要求,请注意例子里大小写不敏感
if re.match(r"^(?:[A-F0-9]{1,4}:){7}[A-F0-9]{1,4}$", string_IPv6, re.I):
print "IPv6 vaild"
else:
print "IPv6 invaild"
#提取IPv6,例子里大小写不敏感
result = re.findall(r"(?<![:.\w])(?:[A-F0-9]{1,4}:){7}[A-F0-9]{1,4}(?![:.\w])", string_IPv6, re.I)
#打印提取结果
print result
判断字符串中是否含有汉字或非汉字
model中compile值可以根据需要更改,满足不同的检测需求
#判断一段文本中是否包含简体中文
import re
zhmodel = re.compile(u'[\u4e00-\u9fa5]') #检查中文
#zhmodel = re.compile(u'[^\u4e00-\u9fa5]') #检查非中文
contents = u'(2014)深南法民二初字第280号'
match = zhmodel.search(contents)
if match:
print(contents)
else:
print(u'没有包含中文')
Python爬虫之正则表达式的使用(三)的更多相关文章
- 玩转python爬虫之正则表达式
玩转python爬虫之正则表达式 这篇文章主要介绍了python爬虫的正则表达式,正则表达式在Python爬虫是必不可少的神兵利器,本文整理了Python中的正则表达式的相关内容,感兴趣的小伙伴们可以 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- 【Python爬虫】正则表达式与re模块
正则表达式与re模块 阅读目录 在线正则表达式测试 常见匹配模式 re.match re.search re.findall re.compile 实战练习 在线正则表达式测试 http://tool ...
- python爬虫-提取网页数据的三种武器
常用的提取网页数据的工具有三种xpath.css选择器.正则表达式 1.xpath 1.1在python中使用xpath必须要下载lxml模块: lxml官方文档 :https://lxml.de/i ...
- python 爬虫之-- 正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 正则表达式非python独有,python 提供了正则表达式的接口,re模块 一.正则匹配字符简介 模式 描述 \d ...
- python爬虫训练——正则表达式+BeautifulSoup爬图片
这次练习爬 传送门 这贴吧里的美食图片. 如果通过img标签和class属性的话,用BeautifulSoup能很简单的解决,但是这次用一下正则表达式,我这也是参考了该博主的博文:传送门 所有图片的s ...
- 【python爬虫和正则表达式】爬取表格中的的二级链接
开始进公司实习的一个任务是整理一个网页页面上二级链接的内容整理到EXCEL中,这项工作把我头都搞大了,整理了好几天,实习生就是端茶送水的.前段时间学了爬虫,于是我想能不能用python写一个爬虫一个个 ...
- Python爬虫运用正则表达式
我看到最近几部电影很火,查了一下猫眼电影上的数据,发现还有个榜单,里面有各种经典和热映电影的排行榜,然后我觉得电影封面图还挺好看的,想着一张一张下载真是费时费力,于是突发奇想,好像可以用一下最近学的东 ...
随机推荐
- Managers经理/代理形式的数据共享
代理方式实现进程间共享字典和列表形式的数据, 代码块: import os from multiprocessing import Process,Manager def f(d,l,normalLi ...
- Android开发技巧——ViewPager加View情况封装PagerAdapter的实现类
ViewPager是Android的support库中的一个控件. ViewPager + Fragment的使用,已经有FragmentAdapter的实现可以帮助我们快速进行开发了: ViewPa ...
- Win10安装TensorFlow1.9-GPU版本
前言 前段时间更新自己电脑上的tf1.4到1.9,没想到踩了这么多坑...特意记录下来希望可以帮到大家 删除旧版本 如果你电脑上没有安装旧版本的tf,就可以忽略这一步.我是因为想要升级到最新版本,所以 ...
- Redis实现聊天功能
在学习了Redis做为消息队列之后研究 了redis聊天的功能. 其实用关系型数据库也可以实现消息功能,自己就曾经用mysql写过一个简单的消息的功能.RDB中思路如下: ** 在实际中可以完全借助m ...
- Java用System读取系统相关信息、环境变量——(六)
package Java_Test; public class System1 { public static void main(String[] args) { // TODO Auto-gene ...
- Freemarker导出带图片的word
1.新建一doc文档
- SpringBoot定制错误页面
(1)有模板引擎的情况下,例如404错误,将会在thymeleaf的templates的error下寻找404.html,如果找不到再寻找4xx.html *所有4开头的错误状态码如果找不到特定的ht ...
- manjaro 的配置
一.更新源的配置: 1).自动方法: 在 终端 执行下面的命令从官方的源列表中对中国源进行测速和设置 sudo pacman-mirrors -c China 2).手动方法 自动方法(上面的方法1, ...
- Zookeeper简介与集群搭建【转】
Zookeeper简介 Zookeeper是一个高效的分布式协调服务,可以提供配置信息管理.命名.分布式同步.集群管理.数据库切换等服务.它不适合用来存储大量信息,可以用来存储一些配置.发布与订阅等少 ...
- IIS8.5 运行WCF
背景 这是一个项目给其它项目提供接口,其实现在哪有用WCF的了,都是restful.不过.net在这方面还是不错,比java强些,java竟然很多采用自己解析xml方式来做Web服务.难以理解. 但是 ...