机器学习&深度学习基础(目录)
从业这么久了,做了很多项目,一直对机器学习的基础课程鄙视已久,现在回头看来,系统的基础知识整理对我现在思路的整理很有利,写完这个基础篇,开始把AI+cv的也总结完,然后把这么多年做的项目再写好总结。
学习路线
第一步:数学
主要为微积分、概率统计、矩阵、凸优化
第二步:数据结构/算法
常见经典数据结构(比如字符串、数组、链表、树、图等)、算法(比如查找、排序)
同时,辅助刷leetcode,提高编码coding能力
第三步:Python数据分析
掌握Python这门语言、和基本的数据分析、数据处理知识
第四步:机器学习
掌握常见经典的模型/算法(比如回归、决策树、SVM、EM、K近邻、贝叶斯、主题模型、概率图模型,及特征处理、模型选择、模型选择等等)
同时,辅助刷kaggle,培养对数据、特征的敏锐
第五步:深度学习
掌握神经网络、CNN、RNN、LSTM等常见经典模型、以及三大DL框架
同时,配套课程利用TensorFlow等开源框架做做DL等相关实验:http://blog.csdn.net/v_JULY_v/ ... 61301
第六步:CV应用扩展
几个基础的概念:
一个机器学习通常应该包括的基本要素有:训练数据,带参数的模型,损失函数,训练算法。训练数据作用自不必说;带参数的模型是用来逼近f();损失函数是衡量模型优劣的一个指标,比如模型识别分类的准确度;训练算法也可以叫做优化函数,用于不断更新模型的参数来最小化损失函数,得到一个较好的模型,或者叫做学习机。接下来将介绍一些机器学习中的基本概念,可能没有很强的连贯性。
样本数据
样本数据就是我们上文提到的(x,y),其中x叫做输入数据(input data),y叫做输出数据(output data)或者叫做一个更加专业的名字——标签(label)。通常x和y都是高维矩阵,以x为例:
其中xi表示第i个输入样本,比如第i个文字,第i张图片,xi可以是一维文字向量,二维图片矩阵,三维视频矩阵,或者更加高维的数据类型,以一维向量为例:
其中xni表示xi数据的第n个元素的值,比如把图像展平之后第n个像素的灰度值等等。
标签y根据需求不同有各种形式,以最简单的n分类问题为例,yi就是一个n维的one-hot,其中一个值为1,其余的元素都为0,第几个元素为1就表明属于第几个类别。
数据集
完整的数据集表示为T={(x1,y1),(x2,y2),(x2,y2),...,(xi,yi)},对于一个学习机而言,不是所有的数据都用于训练学习模型,而是会被分为三个部分:训练数据、交叉验证数据、测试数据。
- 训练数据(training data):顾名思义,训练数据用于训练学习模型,通常比例不低于总数据量的一半。
- 交叉验证数据(cross validation data):交叉验证数据用于衡量训练过程中模型的好坏,因为机器学习算法大部分都不是通过解析法得到的,而是通过不断迭代来慢慢优化模型,所以交叉验证数据就可以用来监视模型训练时候的性能变化。
- 测试数据(testing data):在模型训练好了之后,测试数据用于衡量最终模型的性能好坏,这也是模型性能好坏的衡量指标,交叉验证的指标只能用于监视和辅助模型训练,不能用来代表模型好坏,所以哪怕交叉验证的准确度是100%而测试数据的准确度是10%,那么模型也是不能被认可的。通常交叉验证和测试数据的比例各占一小半。
特征
特征是机器学习和模式识别领域一个比较特有的名词,在传统机器学习算法中,由于计算性能和参数的限制,所以输入的数据维数不能太高。我们手机随随便便一张照片就有几个MB的数据量,可能会有几百万个像素,这么高维的数据量我们是不能直接输入给学习机的,因此我们需要针对特别的应用提取相对应的特征向量,特征向量的作用主要有两个:
- 降低数据维度:通过提取特征向量,把原始数据的维度大大较低,简化模型的参数数量。
- 提升模型性能:一个好的特征,可以提前把原始数据最关键的部分提取出来,因此可以提高学习机的性能。
在传统的机器学习领域,如何提取一个好的特征是大家最关心的,所以机器学习的研究很大程度变成了寻找好的特征,因此也诞生了一个学科叫做特征工程。以下是一个用hog特征进行行人检测的例子,hog特征主要是检测物体的轮廓信息,所以可以用于行人检测。

模型
这里的模型可能用词不准确,但我想表达的是指:带有一些待训练参数,用于逼近前文提到的f()的参数集合。在参数空间,f()只是一个点,而我提到的模型也是一个点,并且由于参数可以变,所以我要做的只是让我模型的这个点尽可能的接近真实f()的那个点。机器学习的模型算法有很多,但是比较常用的模型可以概括为三种:
- 基于网络的模型:最典型的就是神经网络,模型有若干层,每一层都有若干个节点,每两个节点之间都有一个可以改变的参数,通过大量非线性的神经元,神经网络就可以逼近任何函数。
- 基于核方法的模型:典型的是SVM和gaussian process,SVM把输入向量通过一个核映射到高维空间,然后找到几个超平面把数据分成若干个类别,SVM的核是可以调整。
- 基于统计学习的模型:最简单的例子就是贝叶斯学习机,统计学习方法是利用数理统计的数学工具来实现学习机的训练,通常模型中的参数是一些均值方差等统计特征,最终使得预测正确概率的期望达到最大。
一个好的学习机模型应该拥有出色的表达逼近能力、易编程实现、参数易训练等特性。
监督与非监督学习
按照任务的不同,学习机可以分为监督学习(supervised learning)和非监督学习(unsupervised)两种,从数学角度来看两者的区别在于前者知道数据的标签y而后者不知道样本的标签y,所以非监督学习的难度要大一点。
举个通俗的例子,一个母亲交孩子认识数字,当母亲拿到一个数字卡片,告诉孩子这个是数字4是数字6,然后经过大量的教导之后,当目前拿到一个卡片问孩子这个是数字几,这个就是监督学习。如果母亲那一堆数字卡片,让孩子把卡片按照不同数字进行分堆,母亲告诉孩子他分的好不好,可能经过大量的训练,孩子就知道如何把卡片进行正确分堆了,这个就是无监督学习的例子。用一个不那么贴切的名词解释就是,监督学习可以看做分类问题,而无监督可以看做是聚类的问题。
当然还有两种特殊的类型,叫做半监督学习和强化学习,半监督学习是指部分样本是知道标签的,但是其他的样本是不知道标签。强化学习是另外一个特例,为了不混淆大家理解,这里不做解释,感兴趣的可以自行查阅,之后我会单独通过一篇博客来介绍。
监督学习是简单高效的,但是非监督学习是更加有用的,因为人工标注样本标签的代价是非常昂贵耗时的。
损失函数
损失函数(loss function)更严谨地讲应该叫做目标函数,因为在统计学习中有一种目标函数是最大化预测正确的期望概率,我们这里只考虑常见的损失函数。
损失函数是用来近似衡量模型好坏的一个很重要的指标,损失函数的值越大说明模型预测误差越大,所以我们要做的就是不断更新模型的参数,使得损失函数的值最小。常用的损失函数有很多,最简单的如0-1损失函数:
这个损失函数很好理解,预测对了损失为0,预测错了就为1,所以最完美的学习机的损失函数值就应该是0。当然最小二乘误差、交叉熵误差等损失函数也是很常用的,训练时用的损失函数是所有训练样本数据的损失值的和。有了损失函数,模型的训练就变成了一个很典型的优化问题。
优化函数
我们又了目标函数,也就是损失函数,现在我需要一个东西根据损失值来不断更新模型参数,这个东西就叫做优化函数。优化函数的作用就是在参数空间找到损失函数的最优解。梯度下降法是最熟知的优化函数,大家都用下山来形象描述这个算法。假如我们在山上,我们的目标是找到这座山的最低处(最小化损失函数),一个很简单的思路就是我找到当前位置下山角度最大的方向,然后朝着这个方向走,如下图所示 
当然这种方法有个问题就是会陷入局部最优点(局部凹坑)出不来,所以各种更加好的优化函数逐渐被大家发现。一个好的优化函数应该有两个性能指标:拥有跳出局部最优解找到全局最优解的能力;拥有更快的收敛速度。
泛化能力、欠拟合和过拟合
泛化能力(generalization ability)是指机器学习模型对未知数据的预测能力,是学习方法本质上重要的性质,现实中采用最多的办法是通过误差来评价学习方法的泛化能力。但是这种评价是依赖测试数据集的,因为测试数据集是有限的,所以这种思路也不能说是完全靠谱,因此有人专门研究泛化误差来更好的表达泛化能力。
欠拟合(underfitting)和过拟合(overfitting)是两种要尽可能避免的模型训练现象,出现这两种现象就说明模型没有达到一个比较理想的泛化能力。欠拟合是指模型复杂度太低,使得模型能表达的泛化能力不够,对测试样本和训练样本都没有很好的预测性能。过拟合则相反,是模型复杂度太高,使得模型对训练样本有很好的预测性能,但是对测试样本的预测性能很差,最终泛化能力也不行。如下图所示,1和4展示的欠拟合,3和6展示的过拟合现象。而一个好的模型应该是如2和5一样,复杂度正合适,泛化能力较强。

欠拟合与过拟合
1.欠拟合:生成的拟合函数过于简单(例如 h(θ)=θ0+θ1x1)
2.过拟合:生产的拟合函数过于精确(例如h(θ)=θ0+θ1x1+...+θ6x6)
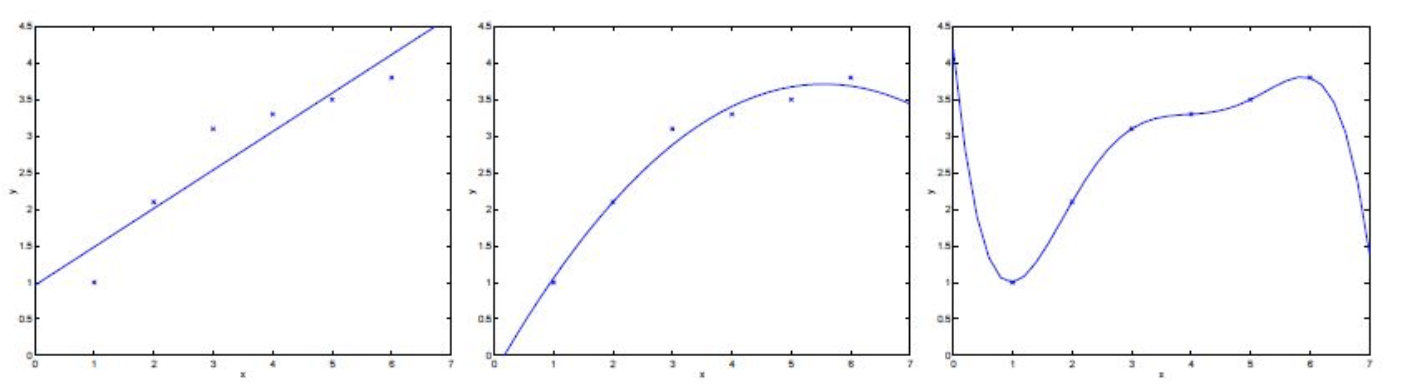
上图中,左图就是欠拟合的情况,曲线不能够很好的反映出数据的变化趋势;而右图是过拟合的情况,因为曲线经过了每一个样本点,虽然在训练集上误差小了,但是曲线的波动很大,往往在测试集上会有很大的误差。而中间图则是比较好的曲线。
当训练数据量很少时,容易发生过拟合,因为曲线会拟合这些少量数据点,而这些数据点往往不能代表数据的总体趋势,导致曲线波动大以及发生严重偏离。
欠拟合时,模型在训练集和测试集上都有很大误差(高偏差);过拟合时,模型在训练集上可能误差很小,但是在测试集上误差很大(高方差)。如果模型在训练集上误差很大,且在测试集上的误差要更大的多,那么该模型同时有着高偏差和高方差。
防止欠拟合方法:不要选用过于简单的模型
防止过拟合方法:不要选用过于复杂的模型;数据集扩增(可以是寻找更多的训练集,也可以是对原训练集做处理,比如对原图片翻转缩放裁剪等);正则化;Early stopping(在测试集上的误差率降到最低就停止训练,而不是不断降低在训练集上的误差)
L1正则化和L2正则化
L1正则化:在误差函数的基础上增加L1正则项:
L2正则化:在误差函数的基础上增加L2正则项:
L1正则化和L2正则化都能够防止过拟合。简单的来说,权值w越小,模型的复杂度越低(当w全为0时模型最简单),对数据的拟合刚刚好(也就是奥卡姆剃刀法则)。如果从更加数学的解释来看,我们看下图:
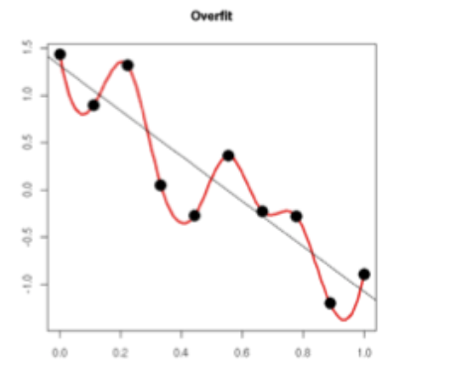
可以看出,过拟合的时候,曲线要顾及每一个点,最终形成的拟合函数波动很大。这就意味着函数在某些小区间里的导数值(绝对值)非常大。而由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。
L1正则化对应着Lasso回归模型,L2正则化对应着岭回归模型。Lasso(L1正则化)得到的w往往比较稀疏,会出现很多0,因此能够剔除无用特征(降维)。
分类和回归
分类:输入新样本特征,输出类别(离散)。常见模型有:Logistic回归,softmax回归,因子分解机,支持向量机,决策树,随机森林,BP神经网络,等等
回归:输入新样本特征,输出预测值(连续)。常见模型有:线性回归,岭回归,Lasso回归,CART树回归,等等
参数学习算法和非参数学习算法
参数学习算法:模型有固定的参数列表θ0,θ1...(比如线性回归)
非参数学习算法:模型中参数的数目会随着训练集的增加而线性增长,或者参数的值会随着测试集的变化而变化(比如局部加权回归LWR就属于非参数学习算法)
偏差和方差
偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据。 高偏差对应的是欠拟合。高偏差时,模型在训练集和测试机上都有很大误差。
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散。 高方差对应的是过拟合。高方差时,模型在训练集上的误差很小,但是在测试集上的误差很大。
如果模型在训练集上误差很大,且在测试集上的误差要更大的多,那么该模型同时有着高偏差和高方差。
监督学习和无监督学习
监督学习:训练集中的每个样本既有特征向量x,也有标签y。根据样本的y来对模型进行“监督”,调整模型的参数。监督学习对应的是分类和回归算法。
无监督学习:训练集中的每个样本只有特征向量x,没有标签y。根据样本之间的相似程度和聚集分布来对样本进行聚类。无监督学习对应的是聚类算法。
分类和聚类
分类:事先定义好了类别,类别数不变。当训练好分类器后,输入一个样本,输出所属的分类。分类模型是有监督。
聚类:事先没有定义类别标签,需要我们根据某种规则(比如距离近的属于一类)将数据样本分为多个类,也就是找出所谓的隐含类别标签。聚类模型是无监督的。
判别模型和生成模型
判别模型:由数据直接学习决策函数Y=f(X)或者条件概率分布P(Y|X)作为预测的模型,即判别模型。
生成模型:由数据学习联合概率密度分布P(X,Y),然后求出条件概率分布P(Y|X)作为预测的模型,即生成模型:P(Y|X)= P(X,Y)/ P(X)。
归一化与标准化
归一化方法:
- 把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。
- 把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
标准化方法:
数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。由于信用指标体系的各个指标度量单位是不同的,为了能够将指标参与评价计算,需要对指标进行规范化处理,通过函数变换将其数值映射到某个数值区间。
归一化,一般的方法是 (x-min(x))/(max(x)-min(x)) 。 标准化,一般方法是(x-mean(x))/std(x) 。 其中mean(x)代表样本均值,std(x)代表样本标准差。这两种方法都是属于线性转换,都是按比例缩放的。
归一化和标准化的好处:
- 归一化的依据非常简单,不同变量往往量纲不同,归一化可以消除量纲对最终结果的影响,使不同变量具有可比性。比如两个人体重差10KG,身高差0.02M,在衡量两个人的差别时体重的差距会把身高的差距完全掩盖,归一化之后就不会有这样的问题。
- 标准化的原理比较复杂,它表示的是原始值与均值之间差多少个标准差,是一个相对值,所以也有去除量纲的功效。同时,它还带来两个附加的好处:均值为0,标准差为1。
协方差和相关系数
协方差:表示两个变量在变化过程中的变化趋势相似程度,或者说是相关程度。
当X增大Y也增大时,说明两变量是同向变化的,这时协方差就是正的;当X增大Y却减小时,说明两个变量是反向变化的,这时x协方差就是负的。协方差越大,说明同向程度越高;协方差越小,说明反向程度越高。
相关系数:也表示两个变量在变化过程中的变化相似程度。但是进行了归一化,剔除了变化幅度数值大小的的影响,仅单纯反映了每单位变化时的相似程度。
翻译一下:相关系数就是协方差分别除以X的标准差和Y的标准差。
当相关系数为1时,两个变量正向相似度最大,即X变大一倍,Y也变大一倍;当相关系数为0时,两个变量的变化过程完全没有相似度;当相关系数为-1时,两个变量的负向相似度最大,即X变大一倍,Y缩小一倍。
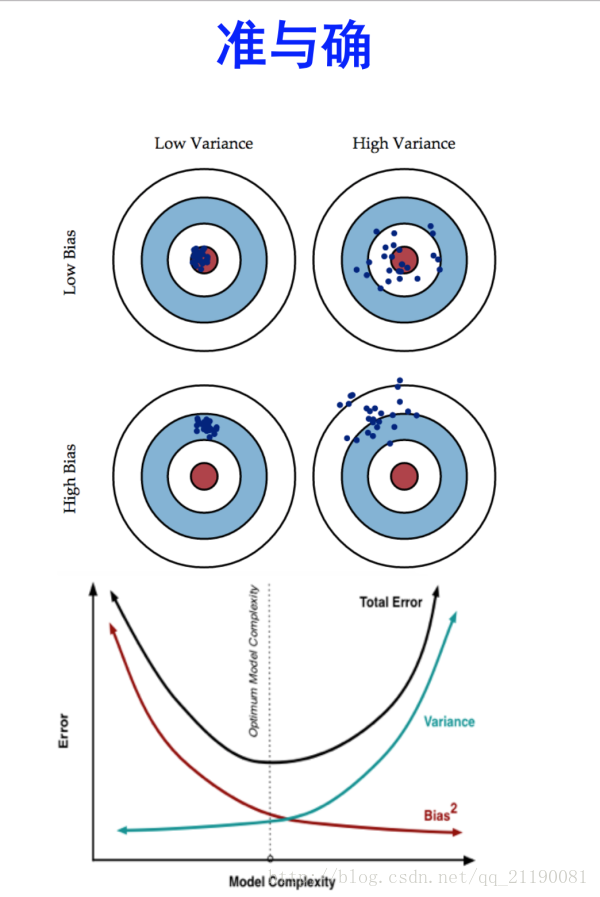
偏差,误差和方差
Bias(偏差),Error(误差),和Variance(方差)三者是容易混淆的概念,首先
Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。如下图所示,随着模型的复杂度增加,模型预测的偏差会越来越小,但是方差越来越大,预测结果的分布会散开来。
机器学习和深度学习
目前所说的深度学习通常是指基于神经网络改进的深度学习网络,相比于传统的神经网络,深度学习网络拥有更加高的模型复杂度,所以可以直接把原始数据输入到学习机,不需要人工提取特征。所以如果不从数理角度考虑,传统机器学习和深度学习的最本质区别在于,深度学习拥有训练高复杂度模型能力,所以可以不用人工提取特征,即
深度学习=人工提取特征+传统机器学习方法
机器学习&深度学习基础(目录)的更多相关文章
- 机器学习&深度学习基础(机器学习基础的算法概述及代码)
参考:机器学习&深度学习算法及代码实现 Python3机器学习 传统机器学习算法 决策树.K邻近算法.支持向量机.朴素贝叶斯.神经网络.Logistic回归算法,聚类等. 一.机器学习算法及代 ...
- 机器学习&深度学习基础(tensorflow版本实现的算法概述0)
tensorflow集成和实现了各种机器学习基础的算法,可以直接调用. 代码集:https://github.com/ageron/handson-ml 监督学习 1)决策树(Decision Tre ...
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- TensorFlow深度学习基础与应用实战高清视频教程
TensorFlow深度学习基础与应用实战高清视频教程,适合Python C++ C#视觉应用开发者,基于TensorFlow深度学习框架,讲解TensorFlow基础.图像分类.目标检测训练与测试以 ...
- [转载]机器学习&深度学习经典资料汇总,全到让人震惊
自学成才秘籍!机器学习&深度学习经典资料汇总 转自:中国大数据: http://www.thebigdata.cn/JiShuBoKe/13299.html [日期:2015-01-27] 来 ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- 机器学习&深度学习资料
机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 1) 机器学习(Machine Learning)&深度学习(Deep Lea ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
随机推荐
- scikit-learn全局图
https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
- 大数据量时 Mysql LIMIT如何正确对其进行优化(转载)
以下的文章主要是对Mysql LIMIT简单介绍,我们大家都知道LIMIT子句一般是用来限制SELECT语句返回的实际行数.LIMIT取1个或是2个数字参数,如果给定的是2个参数,第一个指定要返回的第 ...
- Web前端性能优化进阶——完结篇
前言 在之前的文章 如何优化网站性能,提高页面加载速度 中,我们简单介绍了网站性能优化的重要性以及几种网站性能优化的方法(没有看过的可以狂戳 链接 移步过去看一下),那么今天我们深入讨论如何进一步优化 ...
- grpc 使用总结
1.grpc支持多种语言,需要根据pb文件创建出相应java文件. 2.构建服务端. 3.构建客户端. 4.grpc对象基于创建者模式.
- Python3基础之基本问题
问题1: 加法运算符重载 如果我们有两个列表对象,我要将两个列表中的元素依下标进行加和,我们该如何实现? 1列表对象的加法 list1 = [1,2,3,4] list2 = [10,20,30,40 ...
- python生成指定文件夹目录树
# -*- coding: utf-8 -*- import sys from pathlib import Path class DirectionTree(object): "" ...
- vs2010中关于HTML控件与服务器控件分别和js函数混合使用的问题
此文档解决以下问题: 1.在.cs文件中如何访问html控件? 在html控件中添加属性runat="server"即可 2.在html控件中,如何调用js函数? 在html控件中 ...
- C# 调用windows api 操作鼠标、键盘、窗体合集...更新中
鼠标操作window窗体合集...更新中 1.根据句柄查找窗体 引自http://www.2cto.com/kf/201410/343342.html 使用SPY++工具获取窗体 首先打开spy+ ...
- GitHub超全机器学习工程师成长路线图,开源两日收获3700+Star!【转】
作者 | 琥珀 出品 | AI科技大本营(ID:rgznai100) 近日,一个在 GitHub 上开源即收获了 3700+ Star 的项目,引起了营长的注意.据介绍,该项目以 TensorFlow ...
- iOS开发-NSUndoManager撤销(undo)和重做(redo)
程序开发中我们经常会用到的两个快捷键Ctrl+Z和Ctrl+C,撤销和复制,Cocoa开发也可以实现这两个操作,为我们提供非常简单的操作类NSUndoManger,也可以称之为撤销管理器,NSUndo ...