es中级部分知识点总结
--------------------------------------------------------------- 搜索开始--------------------------------------------------------------- ---------------------------------------------------------------
1 es 5.2 以后 type:text 的字段 或默认建立 一个最长 256 个字符的不分词的 fields fields:{“type”:“keyword”,"ignore_above":256}
例子:
put /advanced PUT advanced/_doc/1
{
"name":"name2" } GET advanced/_mapping
结果:
{
"advanced": {
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
2 term query 就是不分词。直接匹配。但是只是 查询不分词, 如果 field 是text类型的 ,那么已经被建立了倒排索引,这时候只能使用 keyword 搜索了。
GET advanced/_doc/_search
{
"query":{
"constant_score": {
"filter":{
"term": {
"name.keyword": "zhang yu kun"
}
}
}
}
}
3 上面的 这个 如果在老版本中的解决办法,应该为这个字段建立一个不分词的字段。或者直接让这个字段不分词。或者直接让这个字段的字段设置为 keyword。
4 keyword 类型不分词 。
5 filter 的 数据 会缓存,不会计算相关度分数,而且是在query 之前执行。 filter 查询的 时候 会算出 一个 bitset 里面存着 匹配 用1 来表示 文档id 匹配 ,用 0 表示不匹配。并且 会根据一定规则缓存部分查询的 bitset ,总的来说 最近256 个查询中,查询次数超过一定次数,并且不是出现在太小的 segment (小于1000 或者 3%) 中的会被缓存。
6 terms 多值搜索,相当于in must 相当于 and should 相当于 or( 默认只需要一条的时候)
GET advanced/_doc/_search
{
"query":{
"constant_score": {
"filter":{
"term": {
"speciality": "js"
}
}
}
}
}
GET advanced/_doc/_search
{
"query":{
"constant_score": {
"filter":{
"terms": {
"speciality": [
"java",
"js"
]
}
}
}
}
}
备注:如果远字段里面 是 数据,那么只要 有一个值 匹配那么就匹配,如果查询条件是terms 那么就是 相当于in 也就是说 term是 后面数组里面的值是或的关系。in 本来就是或的关系。
7 range query 可以使用 gt gte lt lte 指定范围
GET advanced/_doc/_search
{
"query":{
"constant_score": {
"filter":{
"range": {
"age": {
"gte": 10,
"lte":30
}
}
}
}
}
}
8 查询的时候可以使用 es 的时间表达式, now-1d 表示当前时间减一天,18-08-27||-30d 表示指定时间减去 30天。 除了 d 以为还有 y M d H m s
9 指定分词以后的 关键字之间的 关系是and ( 默认是 或 )
GET advanced/_doc/_search
{
"query":{
"match": {
"content":{
"query": "zhang yu kun",
"operator": "and"
}
}
}
}
10 minimum_should_match 默认的 or 的时候自定 匹配 比例( 默认只用匹配到一个)
GET advanced/_doc/_search
{
"query":{
"match": {
"tcontent":{
"query": "zhang yu kun",
"operator": "or",
"minimum_should_match": "75%"
}
}
}
}
备注:如果吧 如果把词 分了以后用 should 匹配 ,然后控制 should 的 最小匹配个数。可以有相同国的效果。据说 而是内部就是分词以后用bool 里面套用 should ,然后使用term query 实现的。
11 指定搜索权重,boost 默认情况下 boost 都是一样的,都是1
GET advanced/_doc/_search
{
"query":{
"bool": {
"should": [
{
"match": {
"tcontent": {
"query": "zhang",
"boost":5
}
}
},
{
"match": {
"tcontent": "yu"
}
},
{
"match": {
"tcontent": "kun"
}
}
]
}
}
}
12: search_type 里面 query_than_fetch query_and_fetch ,dfs_query_than_fetch ,dfs_query_and_fetch
先查询,返回一个id ,后面再获取doc
查询的的时候就获取到doc
dfs 的头的,在 计算 相关对分数 tf idf 算法的时候 取得 关键字出现总次数 不再是默认的 本shard 而是 全部 shard 。
默认 search_type 是 query_than_fetch
13 遗留问题 为什么 不同 shard 会出现 bound result 的 问题 ?
不同节点 ,如果晒本地 关键字来评分,一个查询会检索 一整 shard ,那么得到的结果 排序后应该总是相等 ,问啥呢?
14 多 field 搜索评分,是 每个字段的 分别搜索的评分加起来然后除以搜索的字段数。得到的平均分。 使用 dis_max 指定分评分为 取 最高的一个。这就是 best field 策略。
GET advanced/_doc/_search
{
"query":{
"dis_max":{
"queries": [
{"match": {
"tcontent": "zhang yu"
}},
{"match": {
"name": "zhang yu"
}}
]
}
}
}
备注: 比如上面例子 在 vcentent 和 name 里面找 zhang yu ,分词后是 zhang 和 yu 如果 一个doc 的 name 和voncent 分别有一个zhang 和 yu ,name 默认分数 是zhang 和 yu 匹配到的分相加除以2.
如果一个 doc 的 name 是zhang yu,vcontent 什么都没有。那么结果是 name 字段的 分 +0 然后除二。这个分可能比 前一个低了。但是我们 dis_max 以后,是取 两个查询分数高的一个作为评分。明显如果是在两个查询字段中找一同样的值。dis_max 比价好 ,如果 是2 个字段找不同的 默认的算法比较好。
备注2: 使用 dis_max 以后 就不是用should 了 ,而是使用 queries了。里面的 查询是 or 的关系 ,并且 是选一个评分最该的最为总评分。
备注3:dis_max 的 dis 我猜是 distribute_max 的意思。分配最大的。
15 使用 tie_breoker 优化 dis_max 查询。( 默认是 各个查询的条件分数的平均值,dis_max 是 取最高值,这个 是取了最高值然后加上别的字段评分的 70% )
GET advanced/_doc/_search
{
"query":{
"dis_max":{
"queries": [
{"match": {
"tcontent": "zhang yu"
}},
{"match": {
"name": "zhang yu"
}}
],
"tie_breaker": 0.7
}
}
}
备注:tie_breoker 是大于 0 小于 1 的数。
16 multi_match 是上面 dis_max 的 另一种写法
GET advanced/_doc/_search
{
"query":{
"multi_match": {
"query": "zhang yu",
"fields": [ "name^2" ,"tcontent" ],
"tie_breaker": 0.7,
"type": "best_fields"
}
}
}
17 上面一个例子的 type best-fields 找分数最高的字段,most-fields 找查到次数最多的。 控制 接近搜索原意的本牌在前面。 老的语法是建立一个 fields 类型是 string 分词器是不分词。
18 ,对于有分词以后有同义词的可以使用 multi_query 在 元字段和 keyword 字段 一起搜,利用
19 cross_fields 的 用法 是不是和 copy_to 类似 的效果,但是呢 如果 "operator" :"and" 的 时候 会让 每个term 必须至少出现在这两个字段中的一个。如果是or 那么 2个联合起来搜索, term 出现任意哥就可以。
说白了 cross_fields 等于 copy_to
20 copy_to 吧 多个字段合并成一个隐藏的字段。(试过了 不是简单的 连接起来),这个好像只能用于搜索,但是 用这个合并出来的字段查不到。感觉没什么用。
PUT advanced2/_mapping/_doc
{
"properties":{
"f_name":{
"type":"text",
"copy_to":"name"
},
"l_name":{
"type":"text",
"copy_to":"name"
}
}
}
get advanced2/_doc/_search
{
"query":{
"match": {
"name": {
"query": "mu tou",
"operator":"and"
}
}
}
}
21 phrase query 短语匹配 只有包含指定短语的才匹配。短语匹配 默认要求 各个term 都有 ,并且 位置是 便宜量是连续的。可以通过指定slop 指定 最多移动几次。
GET advanced/_doc/_search
{
"query":{
"match_phrase": {
"tcontent": {
"query": "zhang kun",
"slop":1
}
}
}
}
22 混合使用 match 和 近似 匹配 实现 召回率 和 精确度的 平衡( 在普通的查询上如果有查询到 短语匹配的就加分)
GET advanced/_doc/_search
{
"query":{
"bool": {
"must": [
{
"match": {
"tcontent": "zhang kun"
}
}
],
"should": [
{
"match_phrase": {
"tcontent": "zhang kun"
}
}
] }
}
}
23 使用 rescore 对查询结果 重打分( 值得是在前面 match 匹配的的同时, 前面 50 个记录使用 短语匹配 ,如果符合那么久共享分数。影响排序,如果不符合 就不共享,并且只有前面50 个这样做,效率高了很多。 ) 是对 22 的优化。
GET advanced/_doc/_search
{
"query":{
"match": {
"tcontent": "zhang kun"
}
},
"rescore":{
"window_size":50,
"query":{
"rescore_query":{
"match_phrase":{
"tcontent": "zhang kun",
"slop":50
}
}
}
}
}
24 前缀搜索 ( 这个感觉分词了的 字段部分可以收到,最好搜索 不分词的字段),不计算分数,前缀搜索效率很低
GET /advanced/_doc/_search
{
"query":{
"prefix": {
"tcontent": {
"value": "zh"
}
}
}
}
25 通配符搜索 * 代表多个字符,? 代表单个字符,性能比较差 需要扫描全部倒排索引。
GET /advanced/_doc/_search
{
"query":{
"wildcard": {
"tcontent": {
"value": "z?a*"
}
}
}
}
27 正则搜索 效率同样低
GET /advanced/_doc/_search
{
"query":{
"regexp": {
"tcontent": {
"value": ".*"
}
}
}
}
28 match_phrase_prefix实现search-time搜索推荐 性能依旧差
GET /advanced/_doc/_search
{
"query":{
"match_phrase_prefix": {
"tcontent": {
"query": "hello w",
"slop":10,
"max_expansions": 50 }
}
}
}
29 通过 ngram 实现 index-time 搜索推荐,性能很强
PUT /advanced3
{
"settings": {
"analysis": {
"filter": {
"autocomplete_filter":{
"type":"edge_ngram",
"min_gram":1,
"max_gram":20
}
},
"analyzer":{
"autocomplete":{
"type":"custom",
"tokenizer":"standard",
"filter":[
"lowercase",
"autocomplete_filter"
]
}
}
}
}
}
get advanced3/_analyze
{
"analyzer":"autocomplete",
"text":"zhangyu ku"
}
然后最好使用 match_phrase 搜索。
30 bootsting (negative 匹配的 分数乘negative_boost )
GET advanced/_doc/_search
{
"query":{
"boosting": {
"positive": {
"match": {
"tcontent": "zhang"
}
},
"negative": {
"match": {
"tcontent": "yu"
}
},
"negative_boost": 0.2 }
} }
31 常量评分
GET advanced/_doc/_search
{
"query":{
"constant_score": {
"filter": {
"match": {
"tcontent": "zhang"
}
},
"boost": 1.2
}
}
}
32 自定义评分(用某个字段影响评分)
GET advanced/_doc/_search
{
"query":{
"function_score": {
"query": {
"prefix": {
"tconent": "zhang"
}
},
"field_value_factor": {
"field": "age"
} }
}
}
GET advanced/_doc/_search
{
"query":{
"function_score": {
"query": {
"prefix": {
"tconent": "zhang"
}
},
"field_value_factor": {
"field": "age",
"modifier": "log1p",
"factor": 1.2
},
"boost_mode": "multiply"
, "max_boost": 1.3
}
}
}
33 模糊查询(修正查询)
fuzziness 纠正对少个字符,删除,添加或者替换 可以使用-->"fuzziness": "auto"
GET advanced/_doc/_search
{
"query":{
"fuzzy": {
"tconent": {
"value": "cheng",
"fuzziness": 2
}
} }
}
--------------------------------------------------------------- 搜索部分结束,ik分词器开始--------------------------------------------------------------- ---------------------------------------------------------------
34 ik的 2 种 分词器 ik_max_word ik_smart .ik_max_word 分的更加细。ik_max_word 只分一次(每个词只出现一次)。 建议 ik_max_word
GET _analyze
{
"analyzer": "ik_smart",
"text": "我是一个中国人"
}
35 ik 的安装 下载ik 源码 打包,复制target\releases\elasticsearch-analysis-ik-6.3.2.zip 到 es/plugins/ik 下面 然后重启服务就可以了。如果 ik 没有对应的es 版本。可以直接修改 ik 的 <elasticsearch.version>6.3.2</elasticsearch.version> 到对应的版本级可以了。
PUT /ik_index/_mapping/_doc
{
"properties":{
"name":{
"type":"text",
"analyzer":"ik_max_word"
}
}
36 ik 的 配置 在 config 目录下面 。IKAnalyzer.cfg.xml 里面可以指定 自定义分词字典,和停用词。 <entry key="ext_dict">目录;木鹿2</entry>
字典分两 大类 ,一是正向字典。停用词。
37 拓展IK的 字典。
官方有个接口 通过http 查询 更新。
修改ik 源码。 ik 的 Dictionary 是一个单例 的类。这个 类里面 DictSegment 向这些 DictSegment 里面填写 我们的自定义字典就可以了
public class Dictionary {
/*
* 词典单子实例
*/
private static Dictionary singleton;
private DictSegment _MainDict;
private DictSegment _SurnameDict;
private DictSegment _QuantifierDict;
private DictSegment _SuffixDict;
private DictSegment _PrepDict;
private DictSegment _StopWords;
singleton._MainDict.fillSegment(word.trim().toCharArray()); 添加词
public void addWords(Collection<String> words) {
if (words != null) {
for (String word : words) {
if (word != null) {
// 批量加载词条到主内存词典中
singleton._MainDict.fillSegment(word.trim().toCharArray());
}
}
}
}
我们 可以修改这个项目源码 ,实现监听模式,在 有新词的时候主动告诉我们的 ik 。或者 定时取查询 新的词语。 原理就这样。想怎么该怎么就改了。
--------------------------------------------------------------- ik分词器结束,集合分析开始--------------------------------------------------------------- ---------------------------------------------------------------
38 聚合分析 -分组
GET /ds/_doc/_search
{
"query":{
"match_all": {}
},
"size":0,
"aggs":{
"ys":{
"terms": {
"field": "color.keyword"
}
}
}
}
39 分组 以后分别对 全部数据取平局 和 对分组的数据取平均值
GET /ds/_doc/_search
{
"query":{
"match_all": {}
},
"size":0,
"aggs":{
"ys":{
"terms": {
"field": "color.keyword"
},
"aggs": {
"pj": {
"avg": {
"field": "num"
}
}
}
},
"pj":{
"avg": {
"field": "num"
}
} }
}
常用的 聚合函数 sum min max value_count
40 直方图分组 ( histogram ),按照 每 interval 里面的 值 一组。
GET /ds/_doc/_search
{
"query":{
"match_all": {}
},
"size":0,
"aggs":{
"num":{
"histogram": {
"field": "num",
"interval": 3
}
}
}
}
41 histogram 还有一个 date_histogram 按照日期间隔分组
extended_bounds 只统计这个日期以内的 数据,
min_doc_count 最少几个会不显示 ,0 表示即便没有一个数据也要显示。
GET /ds/_doc/_search
{
"query":{
"match_all": {}
},
"size":0,
"aggs":{
"num":{
"date_histogram": {
"field": "create_date",
"interval": "day",
"format": "yyyy-MM-dd",
"min_doc_count": 0,
"extended_bounds": {
"min": "now/d",
"max": "now/d"
}
}
}
}
}
42 使用 global:{} 获取全部的 文档(可以在聚合的藤椅位置得到全部的结果)
GET /ds/_doc/_search
{
"query":{
"match": {
"color.keyword": "hongse"
}
},
"size":0,
"aggs":{
"sum":{
"sum": {
"field": "num"
}
},
"all_doc":{
"global": {},
"aggs":{
"total_sum":{
"sum": {
"field": "num"
}
}
}
} }
}
43 聚合里面 还是可以带 filter
GET /ds/_doc/_search
{
"query":{
"match": {
"color.keyword": "hongse"
}
},
"size":0,
"aggs":{
"sum":{
"filter": {
"range": {
"num": {
"gte": 5
}
} }
}
}
}
44 es 里面 一般都可以用 now-1d 表示时间 类似的 2y 年 , 5 m 分钟 , 等等 。。。。。。。。。。。。
45 聚合分组可以指定 排序字段
GET /ds/_doc/_search
{
"query":{
"match_all": {}
},
"size":0,
"aggs":{
"ys":{
"terms": {
"field": "color.keyword",
"order": {
"zs": "desc"
}
},
"aggs":{
"zs":{
"sum": {
"field": "num"
}
}
}
}
}
}
如果有多层下转,那么 排序要在你用的排序字段那层写 排序,并且 使用 层1.层2.字段名 格式。
46 . 三角选着原则
三角 : 精准 实时 大数据 ,只能做到 3 选2
1 精准 + 实时 没有大数据
2 精准 + 大数据 hadoop
3 实时+ 大数据 elasticsearch
47. 近似预估聚合算法 延时 100ms 左右 但是会有0.5% 的误差。精准的算法要慢几十倍。 一般在几秒钟 几分钟 甚至几个小时。
48 cardinality 算法 ,先去重,然后在统计数量
可以使用 precision_threshold 来指定在多大范围内几乎保证100% 的 精确。
49 取一段 数据中 ,指定比例中的最大值。(下面的例子计算的num 是 tp50 tp95 tp99 的值 )
GET ds/_doc/_search
{
"size":0,
"aggs":{
"per":{
"percentiles": {
"field": "num",
"percents": [
50,
95,
99
]
}
},
"ave":{
"avg": {
"field": "per"
}
}
}
}
备注: tp50 表示 百分之50 的数据的值都小于指定的值 。同理 tp95 百分之95 的 数据的值都小于 tp95 的值。
上面的算法,大概是 在50% 的那个数据前后取平均值,但是发现用 avg 和 min sum max 结果一样。 ?
50 percentile_ranks 计算 一定值一下的的百分比。
GET ds/_doc/_search
{
"size":0,
"aggs":{
"aaa":{
"percentile_ranks": {
"field": "num",
"values": [
3,
6
]
}
}
}
}
总结:
percentiles 是取指定百分比附近的值,
percentile_ranks 是取指定值所在的百分比
51 为什么倒排索引聚合 需要检索整个文档,正排索引不需要?
解释:个人认为 搜索的时候,对查询文本分词以后,每一个 term 取 倒排索引里面查询,如果倒排索引是有序的,那么我们只要去指定的地方查询就是了,如果时候通过hash,那么只要查询term 的hash 对应的位置是否有值就够了。所以查询 倒排索引查询是极其快的。但是 如果 使用倒排索引 聚合。比如 通过男女 分组。1W 个文档中有 100 是符合查询条件的。这个100 用来聚合。这时候我们只知道 这 100 个文档和 倒排索引的关系。 大概是这样的关系
男 doc1,doc2
倒排key doc3( fieldName, position),doc7( fieldName, position)
倒排key2 doc99( fieldName, position),doc1000( fieldName, position)
女 doc15( fieldName, position),doc33( fieldName, position)
上面 这种关系可能不是100 条,可能多余也可能少于 ,因为key 可能对应很多 这次查询不 需要的 doc_id ,doc_id 可能前面 可能出现在多个 key 后面。
时候 我们 需要找出性别,然后分组。我们找出对应的 doc_id 集合中 字段名字是 性别,的全部 倒排索引,然后分组。就得到了我们的需要的。显示 在搜索得到一个docids 的后,我们去找这个docids 的 性别字段的 key 的时候需要检索整个倒排缩影的 value 部分 ,去找key ( 通过 docid 和 字段去值里面找)。明显效率不高。这时候我们就需要 可以考虑 直接通过 docid 去找原文。然后通过原文 去分组。这个明显 查找的数据量小很多。毕竟直接通过docid 去找对应 的原文。但是.......,原文在哪里呀? 原文在磁盘里面。慢。所以 doc value 正排索引就产生了。 他是维护 内存里面 ,并且只维护指定指端的 一个 文档缩影。 可硬通过 id 去找到这里面 这个 这份数据 需要加入正排索引的部分。
重点是在 搜索的doc_ids 后去找。这些doc_ids 在 聚合字段值 的过程中 ,必须要去找 这些 doc_ids 的 全部 倒排索引。
52 elastic 内部使用os cache ,建议给jvm 少量内存,给 欧式cache 跟多内存 ,这样可以加减少 gc 和oom 开销。 比如 64 G 内存的服务器,。最大给jvm 16 G ,剩下都给 oscache
53 column 压缩 ,而是会白值相同的用一个标记代替,二不会真是的吧这个值存多份。
54 对于 分词的字段 ,聚合的时候回报错,需要设置 mapping 里面的 fielddata = true 。
不分词的 字段默认是允许聚合的。不分词的字段在 创建 index的 时候默认就为它添加了 doc value。
fielddata = true 那就建立正排索引,也就是doc value。
55 fielddata 是 lazy 加载的,只有 当聚合用到这个字段的时候才加载。而且触发 加载的时候是整个index的这个 field 都会被加载,而不是用到的 少数 doc 的 field。 field 会使用大量内存,需要对内存做一些限制。
可以通过 indeces.fielddata.cache.size:20% 设置,一般建议不要设置,设置类会如果内存不够会清楚内存,然后在使用的时候有反复加载,也会有大量的gc 消耗。
56 查看 fielddata 占用的内存
GET /_stats/fielddata?fields=*
按照node 查询fielddata 占用
GET /_nodes/stats/indices/fielddata?fields=*
按照node 下面的 index 查看
GET /_nodes/stats/indices/fielddata?fields=*&level=indices
57 circuit breaker
使用 fielddata 会占用大量内存,所以很可能oom(内存溢出),可以指定断路器,在内存溢出的时候直接进入断路器(预估内存会溢出就直接失败)。
indices.breaker.fielddata.limit 默认40% fielddata 占用的最大内存
indices.breaker.request.limit 默认 60% 聚合操作需要的最大内存
indices.breaker.total.limit 上面2 个的和 ,默认70%
----------------------------------------------------------------------------------------------------------聚合分析结束,数据建模开始---------------------------------------------------------------------------------------------------------------------------------------------------------
58 elasticsearch的 数据类型 总结
待定: long text keyword string boolean date
59 设置的fielddata的 时候可以同 frequency 来指定那些数据不加载。
"filter":{
"frequency":{
"min": 0.01,
"min_segment_size": 500
}
}
如果这个字段出现次数小于 1% 那么久不加载,在 segment 里面的 doc 数小于 500 的。这个segment 不加载。
60 设置 fielddata的时候 可以是设置 loading:"eager" ,让 查询是加载 fielddata 变成 建立索引 建立 fielddata 。
如果有大量重复字段 可以使用 loading:"eager_global_ordinals" 全局标号 ,来减少内存消耗( 存的就是编的哈,但是明显如果没有 大量重复 编个号会减低速度)。
61 剁成下钻分组统计的时候 深度优先和广度优先问题。
指定 collect_mode:"breadth_first" 表示广度优先。
depth_first 是默认值 ,深度优先。
GET /ds/_doc
{
"aggs":{
"a":{
"terms": {
"field": "",
"size": 10,
"collect_mode": "depth_first"
}
}
}
}
62 es 数据建模的2 中模式
1 传统三范式的 模式( parent child) 优点,数据没有冗余,缺点 在对大量数据搜索的时候,可能应用程序内join 代价很大
2 菲关系型数据库的 冗余模式 优点:直接存的完整的关系,join 没有额外的资源开销 。 缺点: 数据冗余,占用的存储空间大很多。
3 nested object 优点: 没冗余 ,没有外部join 的 资源占用 。 缺点:父子数据必须存在同一个shard 中。 在mapping 指定的时候,使用_parent.type 指定 父类。相当2 个 type ,一个做父 一个做子。父独立添加 添加子的时候需要指定parent 的 id,存数据的时候 通过 parent id 路由,这样父子数据就在同一个 shard 中 。
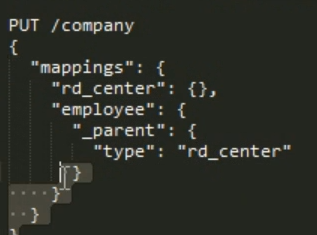
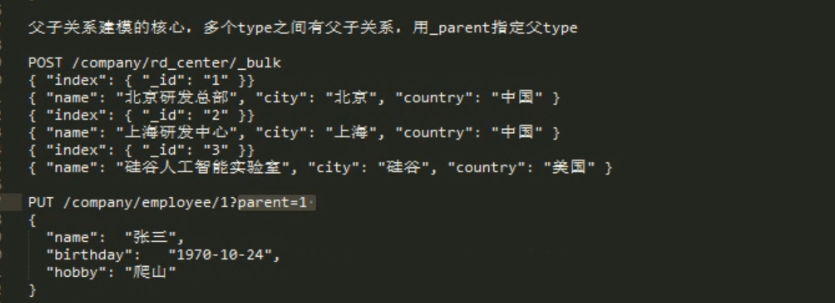
63 top_hits 对 聚合分组的数据 取 前面几个
GET /ds/_doc/_search
{
"size":0,
"aggs":{
"fz":{
"terms": {
"field": "color.keyword"
},
"aggs": {
"top5": {
"top_hits": {
"size": 10,
"_source": ["name","color"]
}
}
} }
}
}
64 : path_hierarchy 分词器这是一个 tokenizer 可以对文件目录拆分。
使用用 ,先定义一个分析器,使用 path_hierarchy 这个分词器。然后对是 文件目录的字段使用这个 自定义的分析器就可以了。
65 analyzer analyze tokenizer 的区别?
analyzer 分析器( 名词),一个 分析器包含了分词器,过滤器
analyze 分析(动词)
tokenizer 分词器(名词)
66 es 的锁
创建文档锁:创建一个指定ID的文档,如果可以创建成功那么久获取到了这个锁。es 保证只有一个线程可以创建成功。这个和redis ,zokeeper 一样。感觉 支持分布式的 工具都是利用 唯一创建 开控制分布式锁的。
修改文档锁: 需要脚本 原理 第一次来创建指定id的一条记录,后来修改的时候 带上这个 doc 指定字段的 值,做对比,如果相同 那么就是上锁的人,可以修改,如果不是 那么久不能修改。 用完锁以后删除这条doc 就释放了锁。
我觉得不是全局和 行级 的关系,而是第一种 无状态 ,不识别 创建者。 第二种 识别。如果用同一个id 那么它们都可以是全局锁,如果用不同id 它们都可以是行级锁。
共享锁: 如果第一次加锁 ,就insert ,如果已经存在,判断是否是 共享锁,如果是就 count +1 ,不是就异常。解锁,每次解锁都count--,当count = 0 的时候删除。
排它锁:向一个文档里面写入一个类型标志排它锁,如果创建成功,那么就获取成功,如果创建失败,就 获取失败。 用的是create 不是 upsert 语法。
加了排它 锁不能再加任何锁,加了共享锁还可以加共享锁。 一般用 排它锁写,共享锁读。
67 object 类型 在 存的时候做了一个合并操作 ,有些时候我们需要 指定 内层type = nested 。这样就保留json 的与哪有类型。存成nested 类型以后需要 使用nested 搜索。
不想写了 有点晚了想睡觉了,截个图,偷个懒,score_mode ,如果 查询到多个结果,评分应该怎么评。

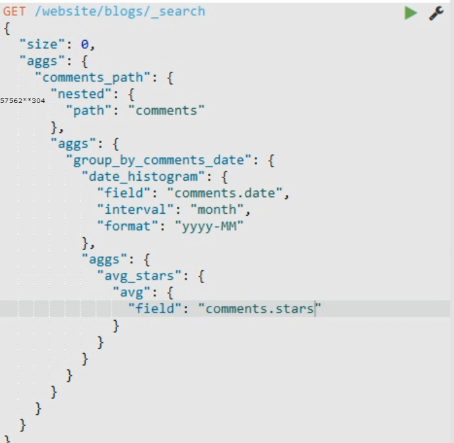
68 基于 nested 的 聚合分析( 下面的 结果是查询 博客的 nested 评论中 , 按照月份分组,然后 获取平均 评分) 为什么要在 正常的集合前面 加一层聚合并且 指定了 nested。path = comments,吧这个诞辰给一个集合的意思吗?
69 。感觉只要在前面的集合拆分成几部分,或者去其中一分部的时候就要使用aggs 。
70 reverse_nested 可以取到前面的数据。( 指的是nested 上层数据) 下面是 查询博客里面的评论中,按照年龄分组,然后在按照 tags 分组(分析这个年龄段发帖 的 tags)

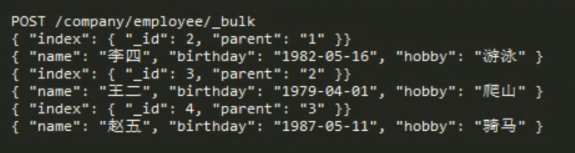
71 buck 批处理的时候,使用 定义部分 使用_开头的感觉都是 ? 前面的 id type index 之类的,? 后面的参数 直接写 。不需要加_
72 parent child 数据模型的 查询父,带上子的条件筛选
查询 子生日在一定范围的父
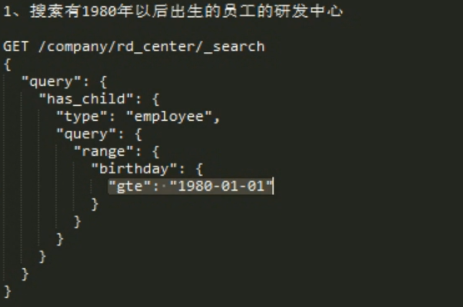
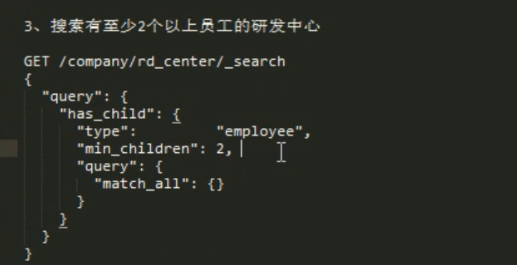
查询 有 2 个 儿子 以上的 父。
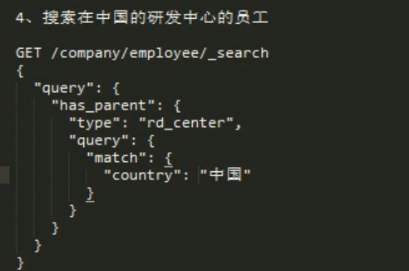
查询子,带上父类的筛选条件
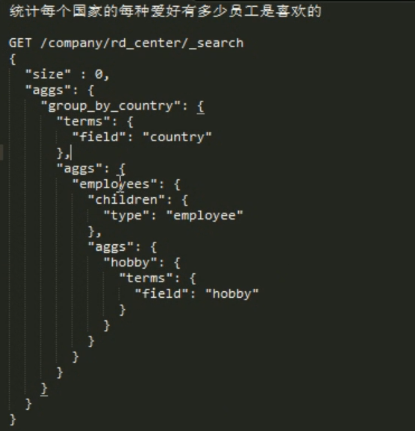
聚合统计:使用一层聚合取子, 使用 children.type 指定子。
查询的时候query type 使用 has_child has_parent ,指定内层 查询条件用的 子 或者父。
聚合的时候使用 aggs + children 取出子集合。
73 可以查询父带出子吗?
74 三种 父子关系。
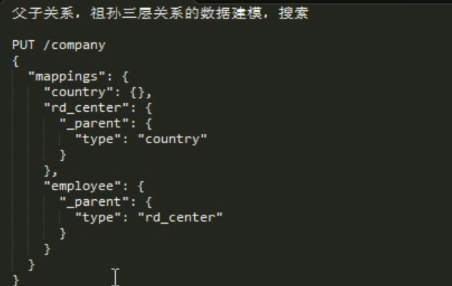
指的注意的一点:因为父子数据需要在同一个shard 里面 所以 第三次只指定 parent id 是不够的 。因为 它是不能用这个 parent id路由,它应该通过最上层的 parent id路由 。这时候 我们直接指定路由id ( routing )
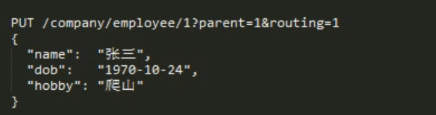
查询的时候 取2层 has_child

-----------------------------------------------------------------------------------------------------数据建模部分结束,实用部分开始-----------------------------------------------------------------------------------------------------------------
75 term vectors 一些描述 term 的 位置 偏移 负载,term 频率 字段评率 等的数据
termvactors 可以出现在 index-time 或者 query-time. 查看语法都一样
GET /ds/_doc/34D9k2UBfN_9dQLLdk-B/_termvectors ,如果没有在index-time 生成 ,那么 查看的时候是也会生成
查询语法:
GET /ds/_doc/34D9k2UBfN_9dQLLdk-B/_termvectors
{
"fields":["name"],
"offsets":true,
"payloads":true,
"positions":true,
"term_statistics":true,
"field_statistics":true
}
添加语法:
PUT /ds1/_mapping/_doc
{
"properties":{
"name":{
"type":"text",
"term_vector":"with_positions_offsets_payloads"
}
}
}
可以不指定 id 。然后用 doc 指定不存在的一份文档加入统计
GET /ds/_doc/_termvectors
{
"doc":{
"name": "电视1",
"color": "hongse",
"num": 1
},
"fields":["name"],
"offsets":true,
"payloads":true,
"positions":true,
"term_statistics":true,
"field_statistics":true
}
可以过滤部分数据: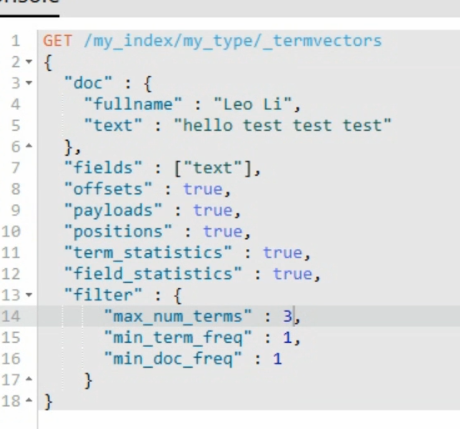
76 _mtermvectors 批量查询 termvectors

可以吧id type 指定到前面
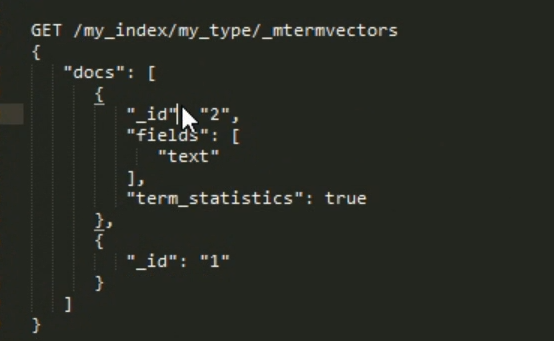
指定 doc:
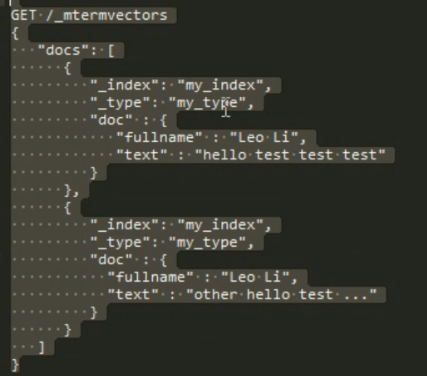
77 搜索的高亮 显示( 值得 一提 的是 highlight 部分出现的 必须是 搜索 条件里面出现过的,不然的话就无法 高亮)

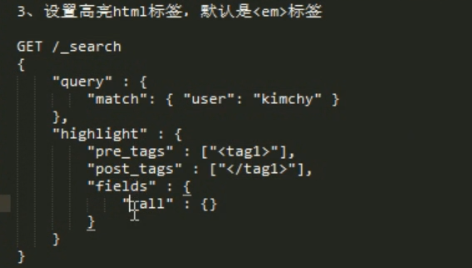
备注:高亮就是在搜索的的结果 term 部分加上 <em>term</em> html 里面会显示成红色。
78 三种高亮的
第一: plain highlight 默认
第二: posting highlight ( 在设置mapping 的时候 设置 字段的 index_optionsoffsets)
性能比 plain 高。
对磁盘消耗比较少
可以高亮句子。
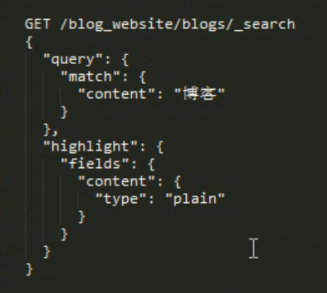
第三: fast vector highlight 如果打开了 term_vector 默认就使用的这种高亮。
在在filed 特别巨大的时候( > 1M ),这个性能最高。
强制指定 使用哪种 highlight
指定使用 高亮标签:
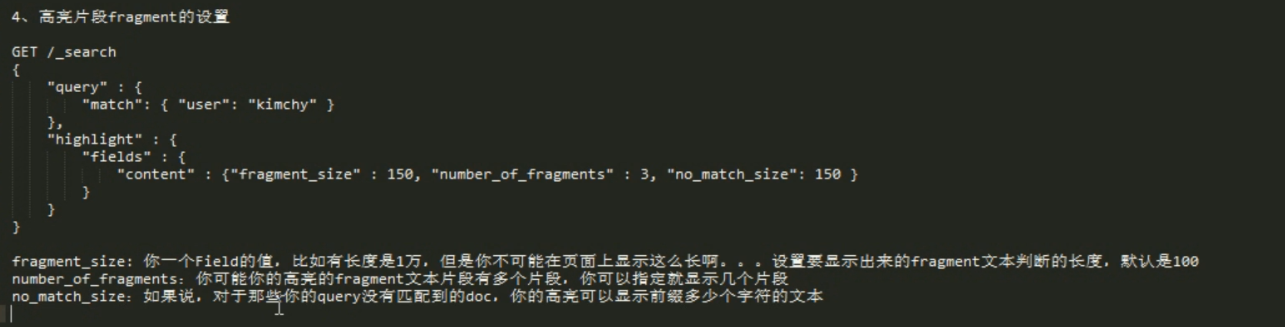
高亮设置: fragment 如果文本太长就分成多个片,number_of_fragment 显示多少片
79 搜索模板化 search template
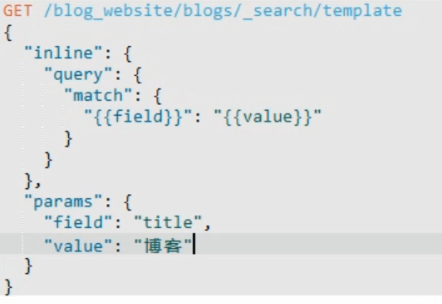
tojos语法:lnline 后面是一整行json 字符串, 把 {{#toJson}}变量{{/toJson}} 之间的部分 设置为下面的 变量后面的 json 对象。 和和上面的区别在于上面是一个简单的 参数值,下面的是一个 json 对象, 感觉最主要的还是后面inline是 json string 。
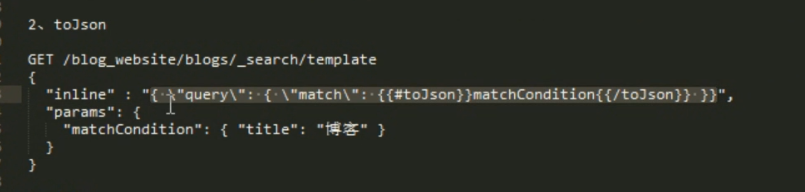
join 语法: 感觉就是取数组专用的。吧下面的 param是里面的 数组 fangdao 上面 并用 空格隔开和 title="博客 网站" 等价。
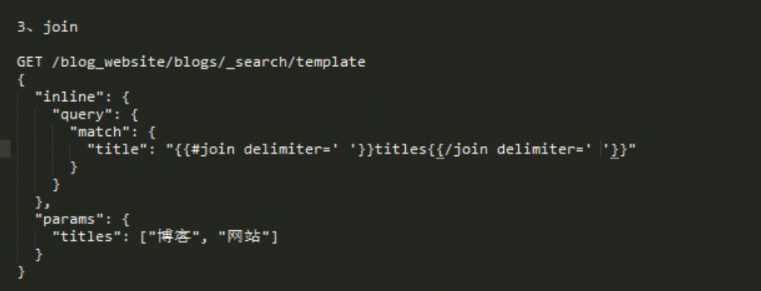
指定默认值: ^end 如果没有就定义这个 end 变量。使用中间的默认值 {{^end}}20{{/end}} 如果 后面参数有end那么久用参数,如果后面的参数没有指定 end 那么就用 20 。
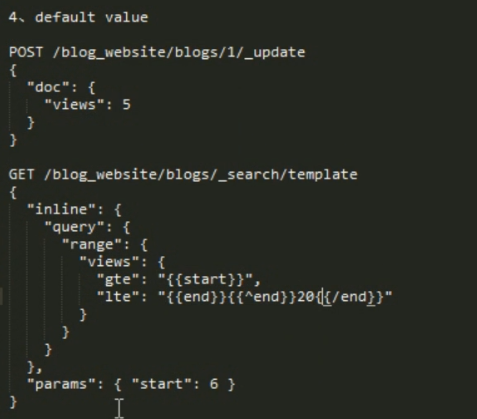
条件判断: {{#条件key}} 执行内容 {{/条件key}} 如果指定了条件key。那么中间才会被执行
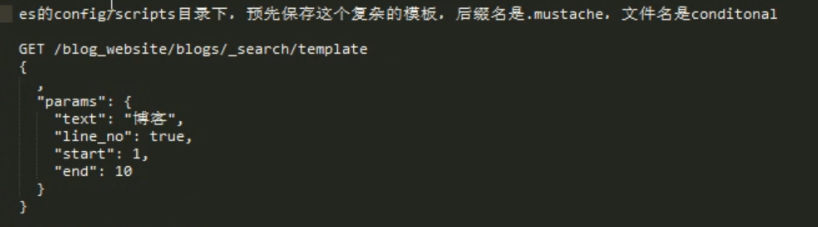
文件内容

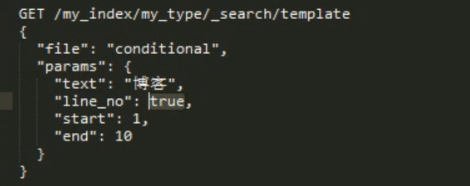
查询语句,前面讲的 几个语法 inline 部分都可以放到 脚本文件里面,然后使用 file 指定 文件,带上参数。
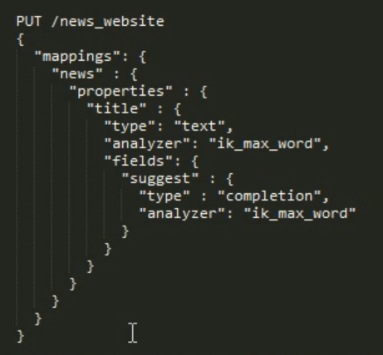
80 suggest 自动完整。 给一个字段指定 fileds.type="completion" 这个es 自动维护 类型 ,不是正排索引也不是倒排索引,不是 前缀搜索。纯内存 速度极快。
定于语法:
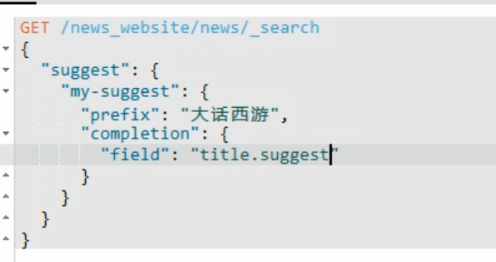
查询语法: 查询就不是query 而是 sugest ,并且指定前缀,和 completion.filed=字段.fieldsName
81 模板动态映射
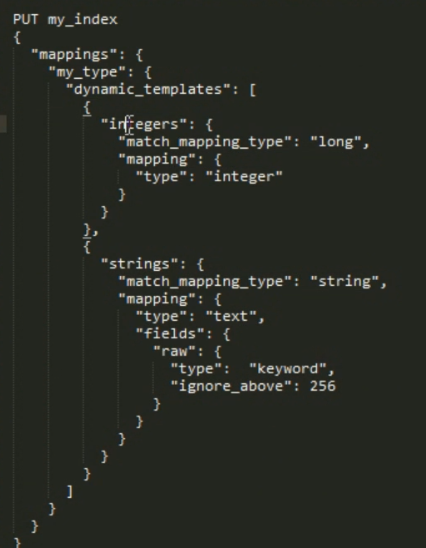
备注:匹配到 long 就是用 下面的 interge 的 mapping ,如果 匹配到 string 就使用 后 mapping的 映射 ,并且 指定 忽略的长度 和不分词的 fileds 。
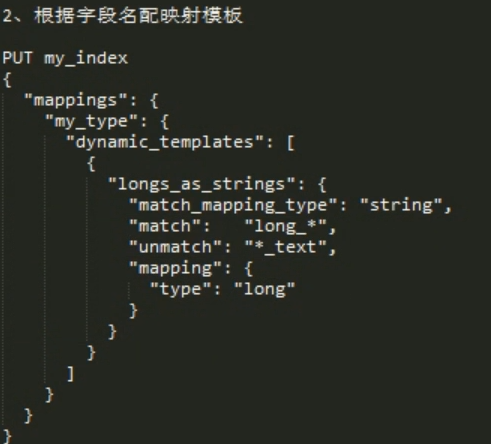
备注: 后面的 match long_* 表示 long 开头的。 *_text 匹配 _text 结尾的。 unmatch 表示不能 是这个格式。
82. 坐标搜索。 geo_point
PUT /geo
PUT /geo/_mapping/_doc
{
"properties":{
"location":{
"type":"geo_point"
}
}
}
对象格式添加:
put /geo/_doc/1
{
"location":{
"lat":40.1,
"lon":50
}
}
字符串格式添加:
put /geo/_doc/2
{
"location":"33.33,44.44"
}
数组格式:
put /geo/_doc/2
{
"location":[1.55,33.67]
}
矩形 左上 和右下 内的 点 查询 (坐标无效,随便写的) bounding_box
GET /geo/_doc/_search
{
"query":{
"geo_bounding_box":{
"location":{
"top_left":{
"lat":0,
"lon":0
},
"bottom_right":{
"lat":0,
"lon":0
}
}
}
} }
多点搜索:( 多点组成 的 不规则图形内的点 ) geo_golygon
GET /geo/_doc/_search
{
"query":{
"geo_polygon":{
"location":{
"points":[
{
"lat":0,
"lon":0
},
{
"lat":0,
"lon":0
},
{
"lat":0,
"lon":0
}
]
}
}
}
}
多少距离以内(就是一个圆形): geo_distance
GET /geo/_doc/_search
{
"query":{
"geo_distance":{
"distance":"200km",
"location":{
"lat":40,
"lon":-70
} }
}
}
多段距离统计:坐标统计(下面是统计 几个范围内 ,有几个酒店)

unit: m mi in yd km cm mm 长度单位
stance_type 有三种 : sloppy_arc(默认的),arc(最精准,但是 慢) plane( 最快,不精准 )
es中级部分知识点总结的更多相关文章
- java中级,知识点归纳(一)
一.接口和抽象类的区别 抽象类中可以含有构造方法,而接口内不能有. 抽象类中可以有普通成员变量,而接口中不能有. 抽象类中可以包含非抽象的普通方法,而接口中所有方法必须是抽象的,不能有非抽象的普通方法 ...
- 白日梦的Elasticsearch笔记(一)基础篇
目录 一.导读 1.1.认识ES 1.2.安装.启动ES.Kibana.IK分词器 二.核心概念 2.1.Near Realtime (NRT) 2.2.Cluster 2.3.Node 2.4.In ...
- 中级前端必备知识点(2.5w+月薪)进阶 (分享知乎 : 平酱的填坑札记 关注专栏 用户:安大虎)
前端已经不再是5年前刚开始火爆时候的那种html+css+js+jquery的趋势了,现在需要你完全了解前端开发的同时,还要具备将上线.持续化.闭环.自动化.语义化.封装......等概念熟练运用到工 ...
- es中的一些知识点记录
1. forcemerge接口 强制段合并,设置为1时,是期望最终只有1个索引段.但实际情况是,合并的结果是段的总数会减少,但仍大于1,可以多次执行强制合并的命令. 设置的的目标值越小.合并消耗的时间 ...
- es知识点
版权声明:本文为博主原创文章,未经博主允许不得转载.转载请务必加上原作者:铭毅天下,原文地址:blog.csdn.net/laoyang360 https://blog.csdn.net/wojius ...
- ES 知识点
一.ES基于_version 进行乐观锁并发控制 post /index/type/id/_update?retry_on_conflict=5&version=6 1.内部版本号 第一次创建 ...
- ES 基础知识点总结
为什么使用 ES? 在传统的数据库中,如果使用某列记录某件商品的标题或简介.在检索时要想使用关键词来查询某个记录,那么是很困难的,假设搜索关键词 "小米",那么 sql 语句就是 ...
- Java中级开发工程师知识点归纳
(一)Java 1.接口和抽象类的区别 ①抽象类里可以有构造方法,而接口内不能有构造方法. ②抽象类中可以有普通成员变量,而接口中不能有普通成员变量. ③抽象类中可以包含非抽象的普通方法,而接口中所有 ...
- JAVA中级开发应该掌握的小知识点
一.悲观锁.乐观锁的区别: 悲观锁:一段执行逻辑加上悲观锁,不同线程同时执行,只有一个线程可以执行,其他线程在入口处等待,直到锁被释放.乐观锁:一段执行逻辑加上乐观锁,不同线程同时执行,可以同时进入执 ...
随机推荐
- Linux文件系统命令 mkdir/rmdir
命令名:mkdir 功能:创建一个文件夹,和touch的区别是,touch是创建一个文件,后面可以跟绝对路径和相对路径 eg: mkdir ren 命令名:rmdir 功能:删除一个文件夹
- <Spark><Running on a Cluster>
Introduction 之前学习的时候都是通过使用spark-shell或者是在local模式运行spark 这边我们首先介绍Spark分布式应用的架构,然后讨论在分布式clusters中运行Spa ...
- 关于 global nonlocal 用法
# 1 关于 globals() locals() nolocl 还有内置函数的引用## 概念的解释# 命名空间# 1 局部命名空间:每一个函数都有自己的命名空间# 2 全局命名空间:写在函数外的变量 ...
- ChinaCock界面控件介绍-CCSystemBar
Android 4.4之后谷歌提供了沉浸式全屏体验, 在沉浸式全屏模式下, 状态栏. 虚拟按键动态隐藏, 应用可以使用完整的屏幕空间, 按照 Google 的说法, 给用户一种 身临其境 的体验.而A ...
- python点滴:读取和整合文件夹下的所有文件
当我们想读取一个文件夹下的多个文件,并且将所有文件的内容整合成一个文件,应该怎么做? 基本的思路是:写一个专门的函数实现以上两个功能.主要用到的命令包括os.listdir().codecs.open ...
- Python 再次改进版通过队列实现一个生产者消费者模型
import time from multiprocessing import Process,Queue #生产者 def producer(q): for i in range(10): time ...
- 利用sql语句进行增删改查
1.查询 函数:raw(sql语句) 语法:Entry.objects.raw(sql) 返回:QuerySet 2.增删改 from django.db import connection def ...
- 20155208实验二 Java面向对象程序设计
20155208实验二 Java面向对象程序设计 一.实验内容 1.初步掌握单元测试和TDD 2.理解并掌握面向对象三要素:封装.继承.多态 3.初步掌握UML建模 4.熟悉S.O.L.I.D原则 5 ...
- 20155208 《Java程序设计》实验一(Java开发环境的熟悉)实验报告
20155208 <Java程序设计>实验一(Java开发环境的熟悉)实验报告 一.实验内容及步骤 (一)使用JDK编译.运行简单的java程序 命令行下的程序开发 打开windows下的 ...
- AC自动机自我理解和模板
给出长度为m的文本 查询 n个单词出现的次数 用kmp 复杂度 n*m*(单词平均长度) 用字典树 复杂度 m*每次字典树遍历的平均深度) AC自动机 复杂度 m (思路可以理解为kmp+字典树 ) ...