Sqoop与HDFS、Hive、Hbase等系统的数据同步操作
Sqoop与HDFS结合
下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出。
Sqoop import
它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示。
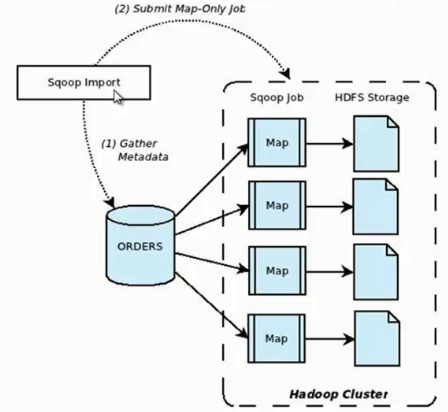
我们来分析一下 Sqoop 数据导入流程,首先用户输入一个 Sqoop import 命令,Sqoop 会从关系型数据库中获取元数据信息,比如要操作数据库表的 schema是什么样子,这个表有哪些字段,这些字段都是什么数据类型等。它获取这些信息之后,会将输入命令转化为基于 Map 的 MapReduce作业。这样 MapReduce作业中有很多 Map 任务,每个 Map 任务从数据库中读取一片数据,这样多个 Map 任务实现并发的拷贝,把整个数据快速的拷贝到 HDFS 上。
下面我们看一下 Sqoop 如何使用命令行来导入数据的,其命令行语法如下所示
- sqoop import \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --target-dir /junior/sqoop/ \ //可选,不指定目录,数据默认导入到/user下
- --where "sex='female'" \ //可选
- --as-sequencefile \ //可选,不指定格式,数据格式默认为 Text 文本格式
- --num-mappers 10 \ //可选,这个数值不宜太大
- --null-string '\\N' \ //可选
- --null-non-string '\\N' \ //可选
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名。
--table:要读取的数据库表。
--target-dir:将数据导入到指定的 HDFS 目录下,文件名称如果不指定的话,会默认数据库的表名称。
--where:过滤从数据库中要导入的数据。
--as-sequencefile:指定数据导入数据格式。
--num-mappers:指定 Map 任务的并发度。
--null-string,--null-non-string:同时使用可以将数据库中的空字段转化为'\N',因为数据库中字段为 null,会占用很大的空间。
下面我们介绍几种 Sqoop 数据导入的特殊应用。
1、Sqoop 每次导入数据的时候,不需要把以往的所有数据重新导入 HDFS,只需要把新增的数据导入 HDFS 即可,下面我们来看看如何导入新增数据。
- sqoop import \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --incremental append \ //代表只导入增量数据
- --check-column id \ //以主键id作为判断条件
- --last-value 999 //导入id大于999的新增数据
上述三个组合使用,可以实现数据的增量导入。
2、Sqoop 数据导入过程中,直接输入明码存在安全隐患,我们可以通过下面两种方式规避这种风险。
1)-P:sqoop 命令行最后使用 -P,此时提示用户输入密码,而且用户输入的密码是看不见的,起到安全保护作用。密码输入正确后,才会执行 sqoop 命令。
- sqoop import \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --table user \
- -P
2)--password-file:指定一个密码保存文件,读取密码。我们可以将这个文件设置为只有自己可读的文件,防止密码泄露。
- sqoop import \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --table user \
- --password-file my-sqoop-password
Sqoop export
它的功能是将数据从 HDFS 导入关系型数据库表中,其流程图如下所示。

我们来分析一下 Sqoop 数据导出流程,首先用户输入一个 Sqoop export 命令,它会获取关系型数据库的 schema,建立 Hadoop 字段与数据库表字段的映射关系。 然后会将输入命令转化为基于 Map 的 MapReduce作业,这样 MapReduce作业中有很多 Map 任务,它们并行的从 HDFS 读取数据,并将整个数据拷贝到数据库中。
下面我们看一下 Sqoop 如何使用命令行来导出数据的,其命令行语法如下所示。
- sqoop export \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --export-dir user
--connect:指定 JDBC URL。
--username/password:mysql 数据库的用户名和密码。
--table:要导入的数据库表。
--export-dir:数据在 HDFS 上的存放目录。
下面我们介绍几种 Sqoop 数据导出的特殊应用。
1、Sqoop export 将数据导入数据库,一般情况下是一条一条导入的,这样导入的效率非常低。这时我们可以使用 Sqoop export 的批量导入提高效率,其具体语法如下。
- sqoop export \
- --Dsqoop.export.records.per.statement=10 \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --export-dir user \
- --batch
--Dsqoop.export.records.per.statement:指定每次导入10条数据,--batch:指定是批量导入。
2、在实际应用中还存在这样一个问题,比如导入数据的时候,Map Task 执行失败, 那么该 Map 任务会转移到另外一个节点执行重新运行,这时候之前导入的数据又要重新导入一份,造成数据重复导入。 因为 Map Task 没有回滚策略,一旦运行失败,已经导入数据库中的数据就无法恢复。Sqoop export 提供了一种机制能保证原子性, 使用--staging-table 选项指定临时导入的表。Sqoop export 导出数据的时候会分为两步:第一步,将数据导入数据库中的临时表,如果导入期间 Map Task 失败,会删除临时表数据重新导入;第二步,确认所有 Map Task 任务成功后,会将临时表名称为指定的表名称。
- sqoop export \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --staging-table staging_user
3、在 Sqoop 导出数据过程中,如果我们想更新已有数据,可以采取以下两种方式。
1)通过 --update-key id 更新已有数据。
- sqoop export \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --update-key id
2)使用 --update-key id和--update-mode allowinsert 两个选项的情况下,如果数据已经存在,则更新数据,如果数据不存在,则插入新数据记录。
- sqoop export \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --update-key id \
- --update-mode allowinsert
4、如果 HDFS 中的数据量比较大,很多字段并不需要,我们可以使用 --columns 来指定插入某几列数据。
- sqoop export \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --column username,sex
5、当导入的字段数据不存在或者为null的时候,我们使用--input-null-string和--input-null-non-string 来处理。
- sqoop export \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --input-null-string '\\N' \
- --input-null-non-string '\\N'
Sqoop与其它系统结合
Sqoop 也可以与Hive、HBase等系统结合,实现数据的导入和导出,用户需要在 sqoop-env.sh 中添加HBASE_HOME、HIVE_HOME等环境变量。
1、Sqoop与Hive结合比较简单,使用 --hive-import 选项就可以实现。
- sqoop import \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --hive-import
2、Sqoop与HBase结合稍微麻烦一些,需要使用 --hbase-table 指定表名称,使用 --column-family 指定列名称。
- sqoop import \
- --connect jdbc:mysql://db.dajiangtai.net:3306/djtdb_hadoop \
- --username sqoop \
- --password sqoop \
- --table user \
- --hbase-table user \
- --column-family city
参考资料:https://www.cnblogs.com/qiaoyihang/p/6229714.html
Sqoop与HDFS、Hive、Hbase等系统的数据同步操作的更多相关文章
- Sqoop_具体总结 使用Sqoop将HDFS/Hive/HBase与MySQL/Oracle中的数据相互导入、导出
一.使用Sqoop将MySQL中的数据导入到HDFS/Hive/HBase watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvYWFyb25oYWRvb3A=/ ...
- Flume + HDFS + Hive日志收集系统
最近一段时间,负责公司的产品日志埋点与收集工作,搭建了基于Flume+HDFS+Hive日志搜集系统. 一.日志搜集系统架构: 简单画了一下日志搜集系统的架构图,可以看出,flume承担了agent与 ...
- Hadoop生态组件Hive,Sqoop安装及Sqoop从HDFS/hive抽取数据到关系型数据库Mysql
一般Hive依赖关系型数据库Mysql,故先安装Mysql $: yum install mysql-server mysql-client [yum安装] $: /etc/init.d/mysqld ...
- sqoop1.4.6从mysql导入hdfs\hive\hbase实例
//验证sqoop是否连接到mysql数据库sqoop list-tables --connect 'jdbc:mysql://n1/guizhou_test?useUnicode=true& ...
- sqoop的导入|Hive|Hbase
导入数据(集群为对象) 在Sqoop中“导入”概念指:从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入,即使用import关键字. 1 RDBMS到HD ...
- 利用Sqoop将MySQL海量测试数据导入HDFS和HBase
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.安装Sqoop 1.下载sqoop,解压.文件夹重命名 wget http://mirror.bit.edu.cn/apache/sqoop/1 ...
- sqoop命令,mysql导入到hdfs、hbase、hive
1.测试MySQL连接 bin/sqoop list-databases --connect jdbc:mysql://192.168.1.187:3306/trade_dev --username ...
- Centos搭建mysql/Hadoop/Hive/Hbase/Sqoop/Pig
目录: 准备工作 Centos安装 mysql Centos安装Hadoop Centos安装hive JDBC远程连接Hive Hbase和hive整合 Centos安装Hbase 准备工作: 配置 ...
- Hive/hbase/sqoop的基本使用教程~
Hive/hbase/sqoop的基本使用教程~ ###Hbase基本命令start-hbase.sh #启动hbasehbase shell #进入hbase编辑命令 list ...
随机推荐
- CUDNN安装
在英伟达官网下载后解压,然后: cd cuda sudo cp lib64/* /usr/local/cuda/lib64/ sudo cp include/* /usr/local/cuda/inc ...
- Could not autowire. No beans of 'TbItemMapper' type found. less... (Ctrl+F1) Checks autowiring prob
Intellij Idea开发工具在@Autowired或者@Resource注入XxxMapper接口时报如下错误: Could not autowire. No beans of 'TbItemM ...
- laravel项目出现Non-static method Redis::hGet() cannot be called statically的解决方法
早上ytkah在配置laravel项目中出现Non-static method Redis::hGet() cannot be called statically错误提示,很显然这是redis出问题了 ...
- centos 安装 pcre
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/luozhonghua2014/article/details/37054235 #rpm -qa | ...
- XML 文档(1, 2)中有错误:不应有 <xml xmlns=''>
症状 用XmlSerializer进行xml反序列化的时候,程序报错: 不应有 <xml xmlns=''>. 说明: 执行当前 Web 请求期间,出现未经处理的异常.请检查堆栈跟踪信息, ...
- [js]js中回调函数
//回调函数: 把一个函数当参数传给另个函数 /* function f1() { console.log('f1'); } function f2(f) { f(); console.log(1); ...
- 一个基于JRTPLIB的轻量级RTSP客户端(myRTSPClient)——实现篇:(十)使用JRTPLIB传输RTP数据
myRtspClient通过简单修改JRTPLIB的官方例程作为其RTP传输层实现.因为JRTPLIB使用的是CMAKE编译工具,这就是为什么编译myRtspClient时需要预装CMAKE. 该部分 ...
- js计算斐波拉切
function feibo(a){ if(!a || a <= 0){ throw new Error("参数错误,必须大于0"); }else if(a == 1){ r ...
- Tensorflow实现LeNet-5、Saver保存与读取
一. LeNet-5 LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络. 卷积神经网络能够很好的利用图像的结构信息. 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定 ...
- Mac下安装m2crypto 解决找不到openssl头文件的错误
直接复制整段到终端运行 sudo env LDFLAGS="-L$(brew --prefix openssl)/lib" CFLAGS="-I$(brew --pref ...