python 全栈开发,Day124(MongoDB初识,增删改查操作,数据类型,$关键字以及$修改器,"$"的奇妙用法,Array Object 的特殊操作,选取跳过排序,客户端操作)
一、MongoDB初识
什么是MongoDB
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
官方给出了以上的解释,那么综上所述,马德 F U C K ! 有效信息太少了(完全没用)
那么让我来用人类的语言讲述一下MongoDB吧
它和我们使用的关系型数据库最大的区别就是约束性,可以说文件型数据库几乎不存在约束性,理论上没有主外键约束,没有存储的数据类型约束等等
关系型数据库中有一个 "表" 的概念,有 "字段" 的概念,有 "数据条目" 的概念
MongoDB中也同样有以上的概念,但是名称发生了一些变化,严格意义上来说,两者的概念即为相似,但又有些出入,不过无所谓,我们就当是以上概念就好啦
光说的话,还是有点儿模糊,就让我们来做一个小例子,进行一个对比吧
下面我们做一张表:
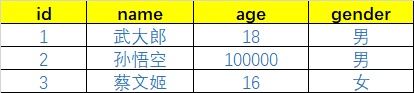
这是我们用关系型数据库做的一张很简单的User表对吧
接下来我们再看一下MongoDB的数据结构:
User = [{
"name": "武大郎",
"age": 18,
"gender": "男"
}, {
"name": "孙悟空",
"age": 100000,
"gender": "男"
}, {
"name": "蔡文姬",
"age": 16,
"gender": "女"
}]
这......这特么不就是个列表,里面放着三个字典吗?你说的对,如果你理解成了列表和字典,那么证明了你只会Python,在其他语言中它又是别的类型了,我们把这种类型的玩意儿,叫做:Json
那么你就该恍然大悟了吧,MongoDB的每个表(Collection)中存储的每条数据(Documents)都是一个一个的Json,Json中的每一个字段(Key)我们称之为:Field
就此我们引出了三个关键字,Collection也就是关系型数据库中"表"的概念,Documents就是"数据条目",Field就是"字段"
这么说,可能还不太明白。看下面的表
| MySQL | MongoDB |
| DB | DB |
| Table | Colletions |
| 字段 | Field |
| row | Documents |
MongoDB安装
mongodb(主程序)
链接:https://pan.baidu.com/s/139_BqPbh0IPcDMPmkWnS8w 密码:fybs
你必须得先安装上数据库才能继续装X
关于MongoDB的安装,真的没有难度,真的真的没有难度,来跟着DragonFire一步一步操作,带你Legendary
首先分享给你一个MongoDB 3.4的msi安装包 点击这里可以下载哦(如果不能下载证明我还没搞定分享msi,自己下载一个吧)
选择默认安装/选择安装
选择 安装
安装完成之后,开始进入配置环节,首先我们要进入目录:
"C:\Program Files\MongoDB\Server\3.4\bin"
带着你配置环境变量,让X装的更加自然更加美:
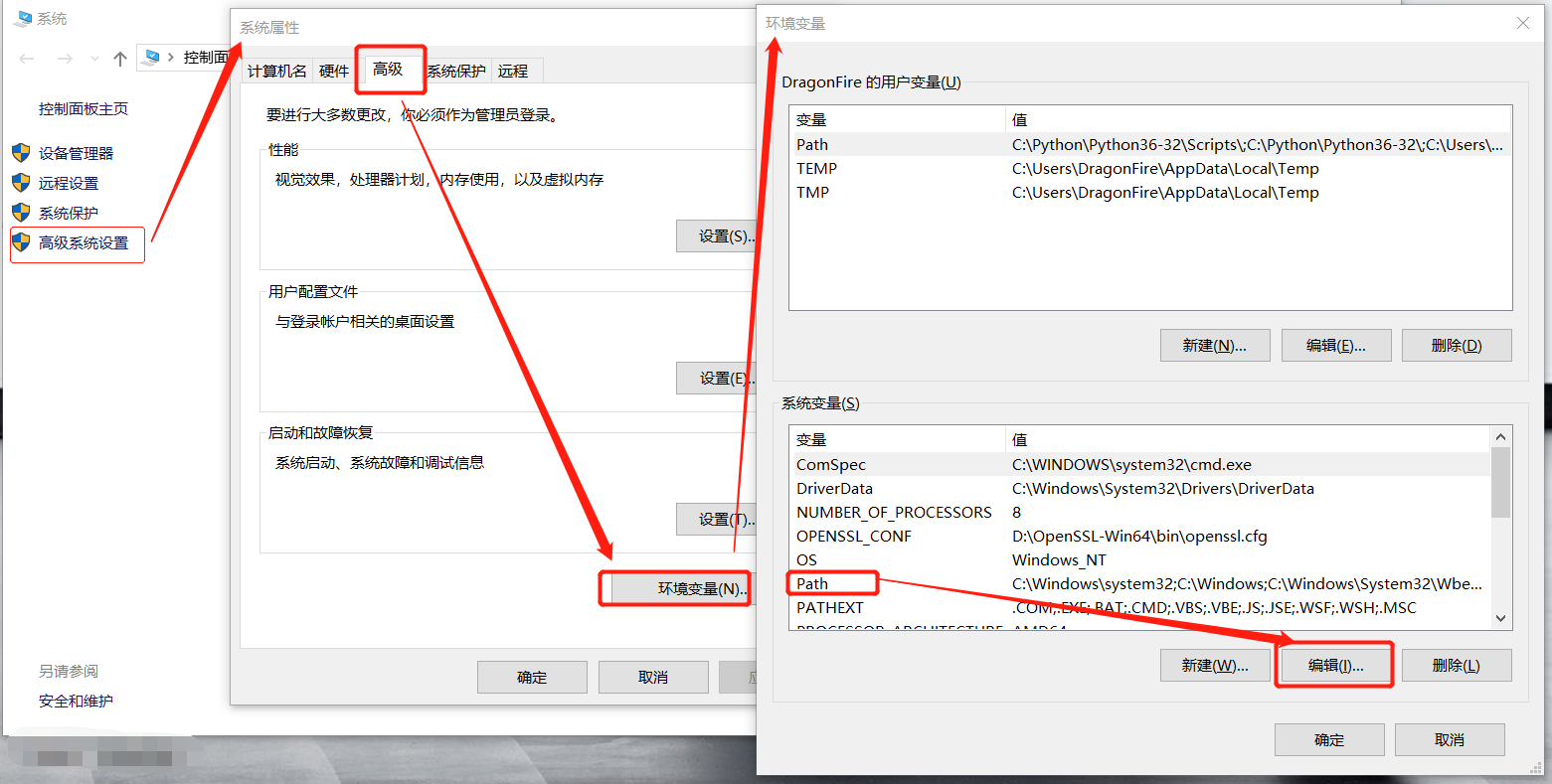
之后的操作,windows 7 与 windows 10 不太一样,大同小异啦
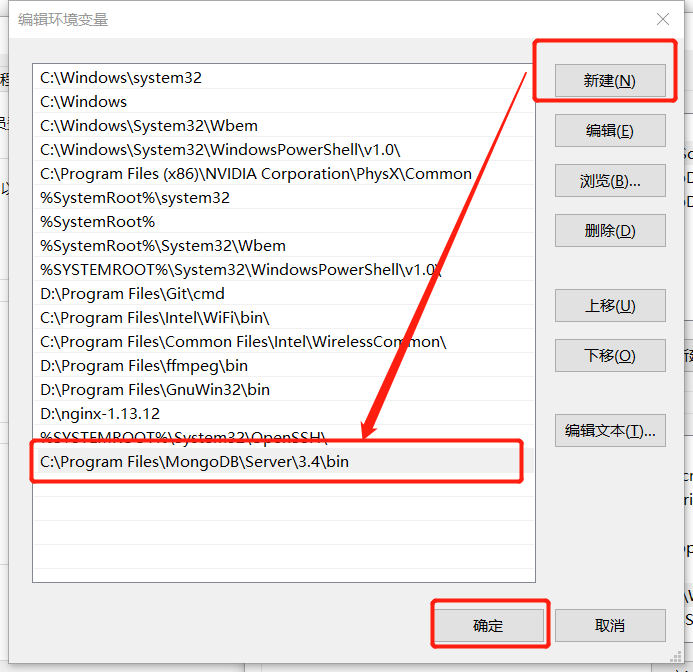
windows 10 一路到底的"确定"
windows 7 在这里需要注意的是,Path路径移动到最后,输入:" ;C:\Program Files\MongoDB\Server\3.4\bin " 一定要带上 " ; " 哦
因为没有找到windows 7 操作系统的计算机,所以这里只能给windows 7 的同学说声抱歉了
OK!到了这里我们基本已经完成了部分操作了
我们来试一下成果吧
打开cmd窗口进行一次ZB的操作吧
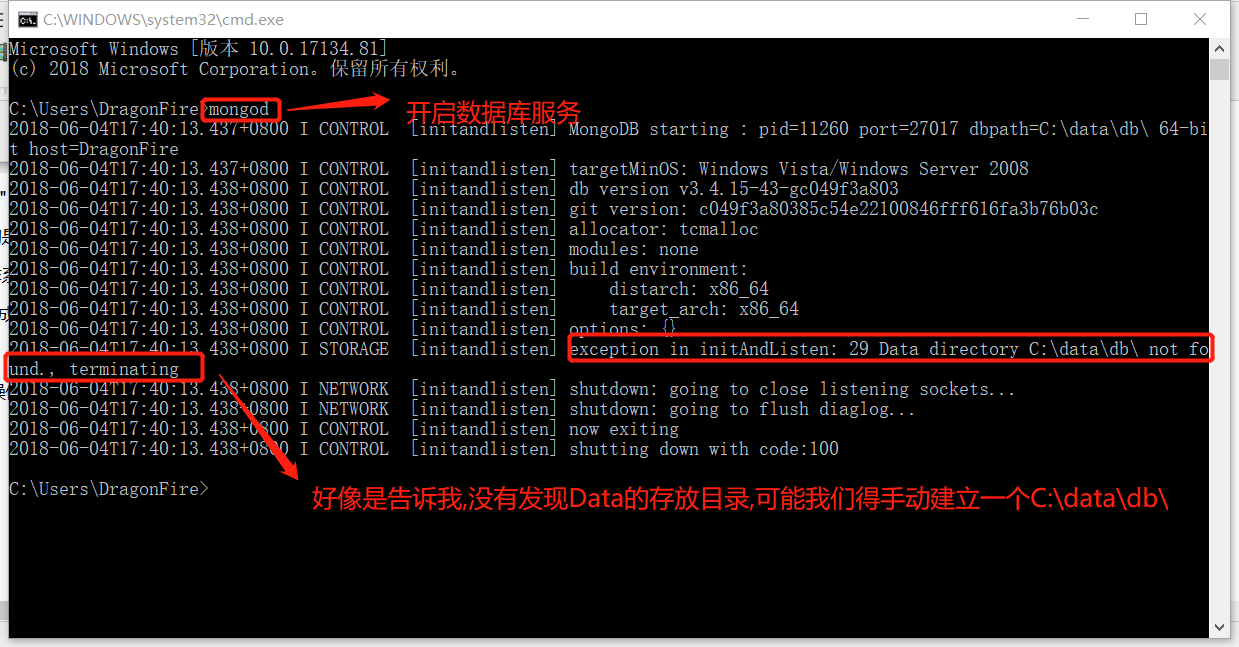
那我们来创建一个" C:\data\db\ "的目录吧
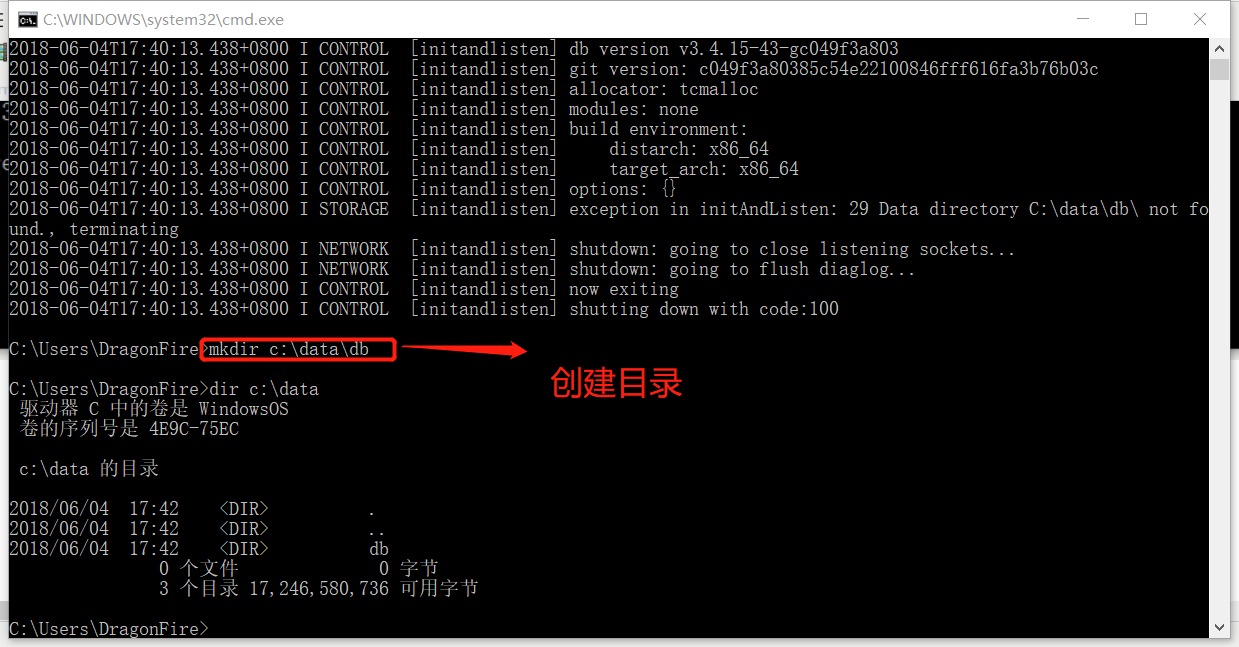
好了目录已经有了,再次ZB试一下
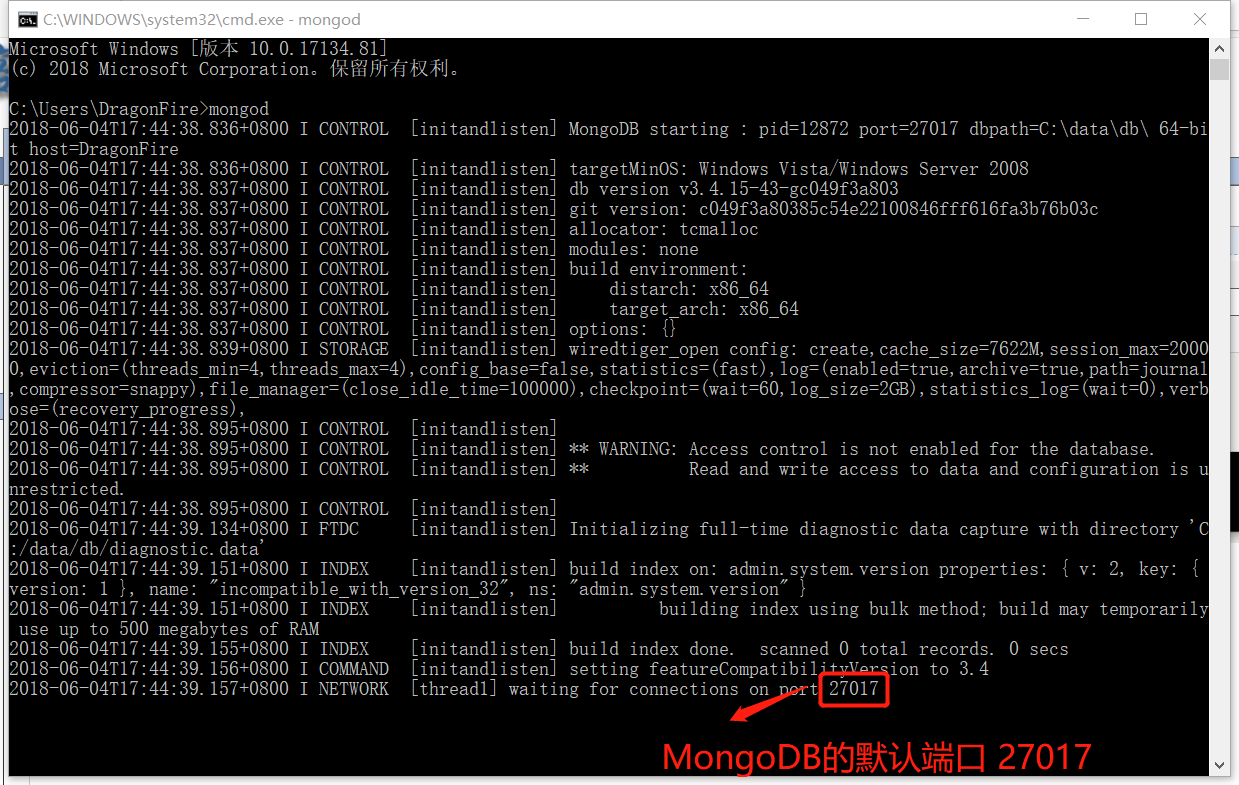
好了开启成功了
那么服务开启了,客户端怎么去连接呢,这时我们需要另一个cmd窗口开启mongo的客户端
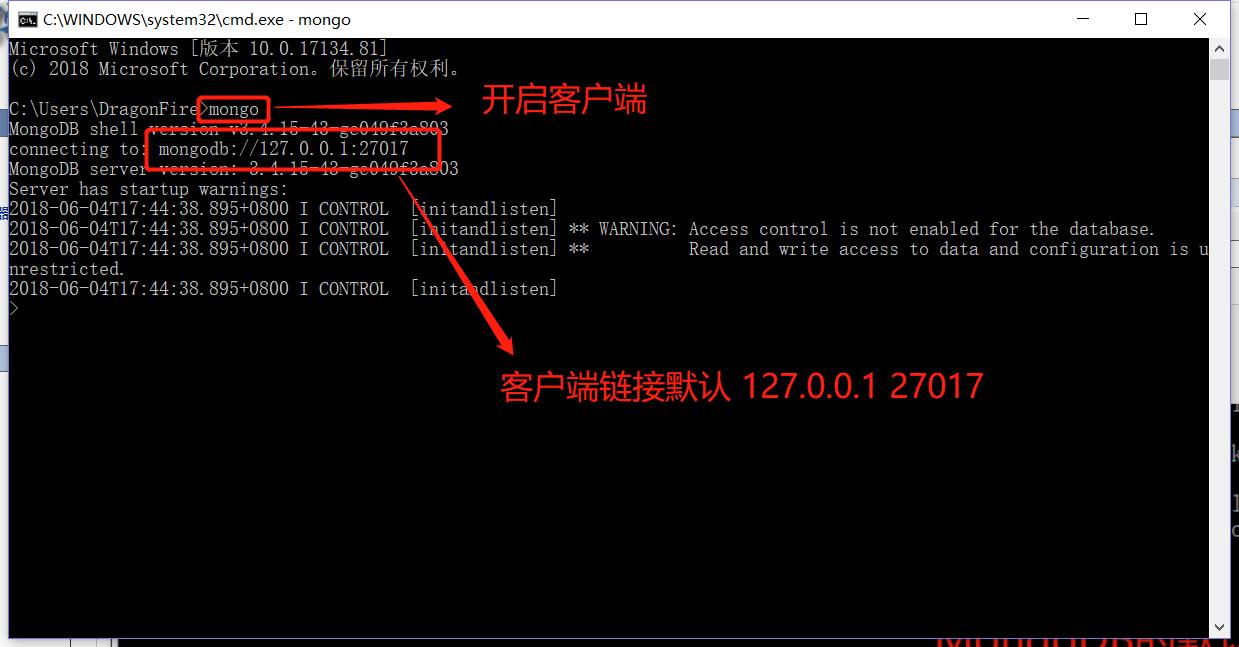
到此,我们成功的完成了,服务端的部署开启,还有客户端的链接,如果你还想继续往下学习的话,我给你一句金玉良言
千万别把这两个cmd窗口关了,不然你还得重新打开一次,哈哈哈哈哈哈哈哈!!!!
本文参考链接:
https://www.cnblogs.com/DragonFire/p/9135630.html
二、增删改查操作
本章我们来学习一下关于 MongoDB的增删改查
MongoDB根本不存在SQL语句,操作它,需要使用ORM语法
创建数据库
这里和一般的关系型数据库一样,都要先建立一个自己的数据库空间
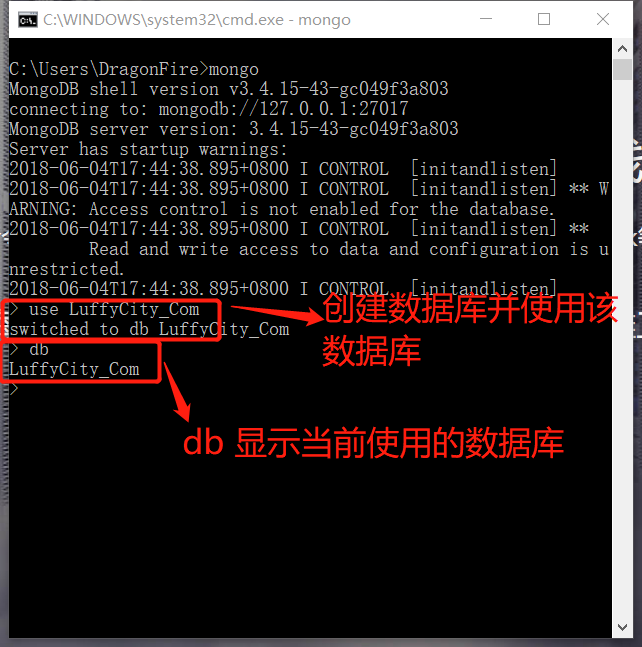
嗯嗯嗯嗯,我感受到了你内心的惊呼,瞅瞅你们这些没见过世面的样子
是的,MongoDB设计的比较随意,没有就认为你是在创建,use LuffyCity_Com是不存在的,所以MongoDB就认为你是要创建并使用
这个概念一定要记清楚哦,MongoDB中如果你使用了不存在的对象,那么就等于你在创建这个对象哦
使用了不存在的对象,就代表创建对象,我们使用这一谬论创建一张表(Collection)试试
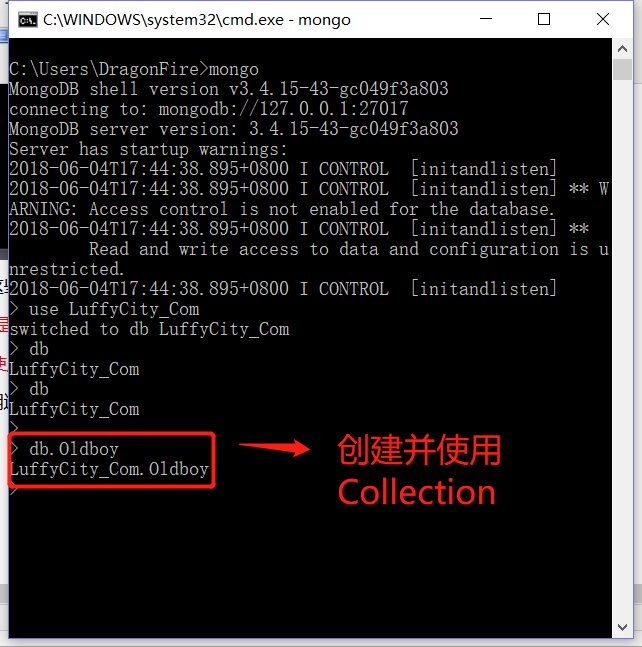
看来真的不是谬论,真的成功的创建了一个Oldboy的Collection
那么接下来就是在表(Collection)中添加一条数据了,怎么添加呢?
插入数据
insert(不推荐)
插入一条或者多条数据,需要带有允许插入多条的参数,这个方法目前官方已经不推荐喽
db.Oldboy.insert({"name":"DragonFire","age":20})
效果如下:
> db.Oldboy.insert({"name":"DragonFire","age":20})
WriteResult({ "nInserted" : 1 })
insertOne
插入一条数据,官方推荐
db.Oldboy.insertOne({"name":"WuSir","age":20})
效果如下:
> db.Oldboy.insertOne({"name":"WuSir","age":20})
{
"acknowledged" : true,
"insertedId" : ObjectId("5b98d462430c27444ccdd644")
}
我们可以看出来两种方法的返回值截然不同对吧
insertMany
插入多条数据,无需参数控制,官方推荐
db.Oldboy.insertMany([{"name":"WuSir2","age":20},{"name":"WuSir3","age":20}])
效果如下:
> db.Oldboy.insertMany([{"name":"WuSir2","age":20},{"name":"WuSir3","age":20}])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5b98d51b430c27444ccdd645"),
ObjectId("5b98d51b430c27444ccdd646")
]
}
这就是我们向LuffyCity_Com.Oldboy中插入了2条数据
这里留下一个数据类型的悬念
插入完成就要查询
查询数据
主要是 (find findOne) , 这里没有findMany
find
这里不是select,如果你的第一反应是select 证明你关系型数据库没白学
find() 无条件查找:将该表(Collection)中所有的数据一次性返回
> db.Oldboy.find()
{ "_id" : ObjectId("5b98d45a430c27444ccdd643"), "name" : "DragonFire", "age" : 20 }
{ "_id" : ObjectId("5b98d462430c27444ccdd644"), "name" : "WuSir", "age" : 20 }
{ "_id" : ObjectId("5b98d51b430c27444ccdd645"), "name" : "WuSir2", "age" : 20 }
{ "_id" : ObjectId("5b98d51b430c27444ccdd646"), "name" : "WuSir3", "age" : 20 }
>
条件查找:age等于20的数据,这里会返回多条结果
> db.Oldboy.find({"age":20})
{ "_id" : ObjectId("5b98d45a430c27444ccdd643"), "name" : "DragonFire", "age" : 20 }
{ "_id" : ObjectId("5b98d462430c27444ccdd644"), "name" : "WuSir", "age" : 20 }
{ "_id" : ObjectId("5b98d51b430c27444ccdd645"), "name" : "WuSir2", "age" : 20 }
{ "_id" : ObjectId("5b98d51b430c27444ccdd646"), "name" : "WuSir3", "age" : 20 }
说到这里,有的同学不禁要问一下:"_id":ObjectId("乱七八糟一道对看着毫无关系的一对字符串") 是什么,我们插入的时候并没有一个字段(Field)并没有_id这个,
对了这就是MongoDB自动给我们添加到系统唯一标识"_id" 是一个ObjectId 类型,我们会在数据类型中第一个说到他(MongoDB 之 数据类型 最无聊! But 最有用! MongoDB - 3)
findOne
findOne()无条件查找一条数据,默认当前Collection中的第一条数据
> db.Oldboy.findOne()
{
"_id" : ObjectId("5b98d45a430c27444ccdd643"),
"name" : "DragonFire",
"age" : 20
}
条件查找一条age等于19的数据,如有多条数据则返回更靠前的数据
> db.Oldboy.findOne({"age":20})
{
"_id" : ObjectId("5b98d45a430c27444ccdd643"),
"name" : "DragonFire",
"age" : 20
}
查询数据的时候,发现了有些数据出现错误了,要修改怎么办呢?
修改数据
主要用到,(update updateOne updateMany) 之 跟insert一样,不推荐update的写法
update(不推荐)
根据条件修改该条数据的内容
> db.Oldboy.update({"name":"DragonFire"},{$set:{"age":21}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
把name等于DragonFire中的age改为21,这里要注意的是({"条件"},{"关键字":{"修改内容"}}),其中如果条件为空,那么将会修改Collection中所有的数据
关于$set关键字的解释就是,本节最后再说,留个悬念
updateOne(推荐)
根据条件修改一条数据的内容,如出现多条,只修改最高前的数据
举例:把age等于20的所有数据中第一条数据的name改为hello kitty
> db.Oldboy.updateOne({"age":20},{$set:{"name":"hello kitty"}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
updateMany(推荐)
根据条件修改所有数据的内容,多条修改
举例:把age等于20的所有数据中的name改为Elizabeth
> db.Oldboy.updateMany({"age":20},{$set:{"name":"Elizabeth"}})
{ "acknowledged" : true, "matchedCount" : 3, "modifiedCount" : 3 }
上述中有一个$set的悬念,这个悬念呀,可能要留到再往后一些了
但是$set:{"name":"Elizabeth"}我还是要解释一下: $set 是update时的关键字,表示我要设置name属性的值为"Elizabeth"
那么我们之前说过MongoDB的灵活性,没有就代表我要创建,所以说如果该条Documents没有name属性,他就会自动创建一个name属性并且赋值为"Elizabeth"
更改了半天,我觉得,这些数据我都不想要了,该怎么办呢?
删除数据
MongoDB提供了三个用于删除操作的API,分别是:
- db.collection.remove()
- db.collection.deleteOne()
- db.collection.deleteMany()
这三个API都支持一个过滤条件参数,用于匹配到满足条件的Document,然后进行删除操作。
remove(不推荐)
remove() 方法已经过时了,现在官方推荐使用 deleteOne() 和 deleteMany() 方法。
remove({}):无条件删除数据,这里要注意了,这是删除所有数据,清空Collection
当然了,我现在还不会操作!
remove还支持条件删除
举例:删除name等于"DragonFire"的所有Document
> db.Oldboy.remove({"name":"DragonFire"})
WriteResult({ "nRemoved" : 1 })
> db.Oldboy.find()
{ "_id" : ObjectId("5b9b556e57f4ea3828d6c60b"), "name" : "WuSir", "age" : 20 }
{ "_id" : ObjectId("5b9b558257f4ea3828d6c60c"), "name" : "WuSir2", "age" : 20 }
{ "_id" : ObjectId("5b9b558257f4ea3828d6c60d"), "name" : "WuSir3", "age" : 20 }
deleteOne(推荐)
删除匹配到的所有的Document中的第一个
> db.Oldboy.deleteOne({"age":20})
{ "acknowledged" : true, "deletedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b9b558257f4ea3828d6c60c"), "name" : "WuSir2", "age" : 20 }
{ "_id" : ObjectId("5b9b558257f4ea3828d6c60d"), "name" : "WuSir3", "age" : 20 }
deleteMany(推荐)
删除所有匹配到的Document
> db.Oldboy.deleteMany({"age":20})
{ "acknowledged" : true, "deletedCount" : 2 }
> db.Oldboy.find()
>
发现数据已经被清空了!
那么到这里呢,增删改查就已经完事儿了
之后我们来说一下MongoDB的数据类型,跟你们透漏一下,MongoDB的数据类型,老(te)有(bie)意(wu)思(liao)了
本文参考链接:
https://www.cnblogs.com/DragonFire/p/9135638.html
三、数据类型
丰富多彩的数据类型世界
首先我们要先了解一下MongoDB中有什么样的数据类型:
Object ID :Documents 自生成的 _id
String: 字符串,必须是utf-8
Boolean:布尔值,true 或者false (这里有坑哦~在我们大Python中 True False 首字母大写)
Integer:整数 (Int32 Int64 你们就知道有个Int就行了,一般我们用Int32)
Double:浮点数 (没有float类型,所有小数都是Double)
Arrays:数组或者列表,多个值存储到一个键 (list哦,大Python中的List哦)
Object:如果你学过Python的话,那么这个概念特别好理解,就是Python中的字典,这个数据类型就是字典
Null:空数据类型 , 一个特殊的概念,None Null
Timestamp:时间戳
Date:存储当前日期或时间unix时间格式 (我们一般不用这个Date类型,时间戳可以秒杀一切时间类型)
看着挺多的,但是真要是用的话,没那么复杂,很简单的哦
剖析MongoDB的数据类型
那么我们根据以上所说的数据类型(捡重点说,别整没用的)展开说明:
1. Object ID
> db.Oldboy.find()
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "Elizabeth", "age" : 20 }
解释:
"_id" : ObjectId("5b151f8536409809ab2e6b26")
"5b151f85" 代指的是时间戳,这条数据的产生时间
"" 代指某台机器的机器码,存储这条数据时的机器编号
"09ab" 代指进程ID,多进程存储数据的时候,非常有用的
"2e6b26" 代指计数器,这里要注意的是,计数器的数字可能会出现重复,不是唯一的
以上四种标识符拼凑成世界上唯一的ObjectID
只要是支持MongoDB的语言,都会有一个或多个方法,对ObjectID进行转换
可以得到以上四种信息
注意:这个类型是不可以被JSON序列化的
这是MongoDB生成的类似关系型DB表主键的唯一key,具体由24个字节组成:
0-8字节是时间戳,
9-14字节的机器标识符,表示MongoDB实例所在机器的不同;
15-18字节的进程id,表示相同机器的不同MongoDB进程。
19-24字节是计数器
2. String
> db.Oldboy.find()
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "Elizabeth", "age" : 20 }
UTF-8字符串,记住是UTF-8字符串
3. Boolean
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "Elizabeth", "display" : true }
true or false 这里首字母是小写的
4. Integer
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "Elizabeth", "age" : 20 }
整数 (Int32 Int64 你们就知道有个Int就行了,一般我们用Int32)
5. Double
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "Apple", "Price" : 5.8 }
浮点数 (MongoDB中没有float类型,所有小数都是Double)
6. Arrays
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "Apple", "place" : ["China","America","New Zealand"] }
数组或者列表,多个值存储到一个键 (list哦,大Python中的List哦
7. Object
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "LuffyCity", "course" : {"name" : "Python","price" : 19800 } }
如果你学过Python的话,那么这个概念特别好理解,就是Python中的字典,这个数据类型就是字典
8. Null
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "atmosphere", "price" : null }
空数据类型 , 一个特殊的概念,None Null
9. Timestamp :时间戳
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "Shanghai", "date" : 1528183743111 }
10. Date
{ "_id" : ObjectId("5b151f8536409809ab2e6b26"), "name" : "Beijing", "date" : ISODate("2018-06-05T15:28:33.705+08:00") }
存储当前日期或时间格式 (我们一般很少使用这个Date类型,因为时间戳可以秒杀一切时间类型)
数据类型就介绍到这里了,接下来我们就要学习一下在数据进行增删改查时,数据类型的特殊用法
本文参考链接:
https://www.cnblogs.com/DragonFire/p/9135854.html
四、$关键字以及$修改器
上一篇文章中提到过 $set 这个系统关键字,用来修改值的,对吧!
但是MongoDB中类似这样的关键字有很多, $lt $gt $lte $gte 等等,这么多我们也不方便记,这里我们说说几个比较常见的
准备基础数据
# 清空所有数据
> db.Oldboy.remove({})
WriteResult({ "nRemoved" : 3 }) # 插入3条数据
> db.Oldboy.insertMany([{"name":"Linux","score":59},{"name":"Python","score":100},{"name":"Go","score":80}])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5b98f5b3430c27444ccdd64a"),
ObjectId("5b98f5b3430c27444ccdd64b"),
ObjectId("5b98f5b3430c27444ccdd64c")
]
} # 查询所有数据
> db.Oldboy.find()
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64a"), "name" : "Linux", "score" : 59 }
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64b"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64c"), "name" : "Go", "score" : 80 }
常见的$关键字
:(等于)
在MongoDB中什么字段等于什么值其实就是 " : " 来搞定 比如 "name" : "Linux"
> db.Oldboy.find({"name":"Linux"})
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64a"), "name" : "Linux", "score" : 59 }
$in
查询一个键的多个值
> db.Oldboy.find({"name":{$in:["Linux","Go"]}})
{ "_id" : ObjectId("5b9b9a4cc09c7f67e7a5e499"), "name" : "Linux", "score" : 59 }
{ "_id" : ObjectId("5b9b9a4cc09c7f67e7a5e49b"), "name" : "Go", "score" : 80 }
$or
满足任意 $or 条件的数据,至少要满足一个
> db.Oldboy.find({$or:[{"score":80},{"score":100}]})
{ "_id" : ObjectId("5b9b9a4cc09c7f67e7a5e49a"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b9b9a4cc09c7f67e7a5e49b"), "name" : "Go", "score" : 80 }
$gt(大于)
在MongoDB中的 大于 > 号 我们用 : $gt 比如 : "score" : { $gt : 80 } 就是 得到 "score" 大于 80 的数据
> db.Oldboy.find({"score":{$gt:80}})
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64b"), "name" : "Python", "score" : 100 }
$lt(小于)
小于 : 在MongoDB中的 小于 < 号 我们用 : $lt 比如 : "score" : { $lt : 80 } 就是 得到 "score" 小于 80 的数据
> db.Oldboy.find({"score":{$lt:80}})
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64a"), "name" : "Linux", "score" : 59 }
$gte(大于等于)
大于等于 : 在MongoDB中的 大于等于 >= 号 我们用 : $gte 比如 : "score" : { $gte : 80 } 就是 得到 "score" 大于等于 80 的数据
> db.Oldboy.find({"score":{$gte:80}})
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64b"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64c"), "name" : "Go", "score" : 80 }
$lte(小于等于)
小于等于 : 在MongoDB中的 小于等于 <= 号 我们用 : $lte 比如 : "score" : { $lte : 80 } 就是 得到 "score" 小于等于 80 的数据
> db.Oldboy.find({"score":{$lte:80}})
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64a"), "name" : "Linux", "score" : 59 }
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64c"), "name" : "Go", "score" : 80 }
这就是MongoDB中的运算符,是不是很类似我们使用的ORM中的运算符啊,没错,最开始的时候我们就已经说了,MongoDB的操作就是很类似ORM的
update修改器
常用的update修改器: $inc $set $unset $push $pull
在此前的update中,我们用过$set,对数据进行过更新,其实在update中还存在很多的$关键字,我们把update中的这些关键字叫做 修改器
修改器很多,这里挑一些重要的来说一说:
1. $inc
Python中的 变量 += 1 , 将查询到的结果 加上某一个值 然后保存
还是上面的Collection数据,我们来试一下$inc , 让不及格的 "Linux" 变成 60 分
> db.Oldboy.updateOne({"score":59},{$inc:{"score":1}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
成功了 , {$inc:{"score":1}}的意思是,"score"的原有数值上面 +1
查看所有数据
> db.Oldboy.find()
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64a"), "name" : "Linux", "score" : 60 }
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64b"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64c"), "name" : "Go", "score" : 80 }
我们再来实验一次,把60改为20,这怎么操作呢,其实可以理解为在 60 上加一个 -40
> db.Oldboy.updateOne({"score":60},{$inc:{"score":-40}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
又成功了 , {$inc:{"score":-20}}也来越喜欢英俊潇洒又不会翻车的自己了
$inc 的用法是不是很简单啊,就是原有基础上在增加多少对吧
查看所有数据
> db.Oldboy.find()
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64a"), "name" : "Linux", "score" : 20 }
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64b"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98f5b3430c27444ccdd64c"), "name" : "Go", "score" : 80 }
2. $set
此前我们已经提到过 $set 的用法和特性(没有就自动添加一条)了
再做一个例子:把 "score" 为 100 分 的 "price" 赋值为 99.8
> db.Oldboy.updateOne({"score":100},{$set:{"price":99.8}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : "" }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100, "price" : 99.8 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
发现Python多了一个属性price
再把 "score" 为 20 分的 "score" 赋值为 59 分
> db.Oldboy.updateOne({"score":20},{$set:{"score":59}})
{ "acknowledged" : true, "matchedCount" : 0, "modifiedCount" : 0 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100, "price" : 99.8 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
完美~
3. $unset
用来删除Key(field)的
做一个小例子 : 刚才我们有一个新的"price" 这个field ,现在我们来删除它
> db.Oldboy.updateOne({"score":100},{$unset:{"price":1}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : 59 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
成功了! {$unset:{"price" : 1}} 就是删除 "english_name" 这个 field 相当于 关系型数据库中删除了 字段
4. $push
它是用来对Array (list)数据类型进行 增加 新元素的,相当于我们大Python中 list.append() 方法
做一个小例子 :首先我们要先对原有数据增加一个Array类型的field:
> db.Oldboy.update({},{$set:{"test_list":[1,2,3,4,5]}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : 59, "test_list" : [ 1, 2, 3, 4, 5 ] }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
使用update $set 的方法只能为Document中的第一条添加
使用updateMany $set 的方法 可以为所有满足条件的 Document 添加 "test_list" , 注意我这里的条件为空 " {} " 就算是为空,也要写上"{}" 记住记住记住
接下来我们就要队列表进行添加了: 将 "score" 为 59 的Document 中"test_list" 添加一个 6
> db.Oldboy.updateMany({"score":59},{$push:{"test_list":6}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : 59, "test_list" : [ 1, 2, 3, 4, 5, 6 ] }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
$push 是在 Array(list) 的尾端加入一个新的元素 {$push : {"test_list" : 6}}
5. $pull
有了$push 对Array类型进行增加,就一定有办法对其内部进行删减,$pull 就是指定删除Array中的某一个元素
做一个例子: 把我们刚才$push进去的 6 删除掉
> db.Oldboy.updateMany({"score":59},{$pull:{"test_list":6}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : 59, "test_list" : [ 1, 2, 3, 4, 5 ] }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
问题来了,如果 Array 数据类型中 如果有 多个 6 怎么办呢?
重复执行3条命令,查看所有数据
> db.Oldboy.updateMany({"score":59},{$push:{"test_list":6}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.updateMany({"score":59},{$push:{"test_list":6}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.updateMany({"score":59},{$push:{"test_list":6}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : 59, "test_list" : [ 1, 2, 3, 4, 5, 6, 6, 6 ] }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
再次执行命令,删除6
> db.Oldboy.updateMany({"score":59},{$pull:{"test_list":6}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : 59, "test_list" : [ 1, 2, 3, 4, 5 ] }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
全部删掉了.....
得出了一个结论,只要满足条件,就会将Array中所有满足条件的数据全部清除掉
6. $pop
指定删除Array中的第一个 或 最后一个 元素
做个小例子: 删除"score" 等于 59 分 test_list 的最后一个元素
> db.Oldboy.updateMany({"score":59},{$pop:{"test_list":1}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : 59, "test_list" : [ 1, 2, 3, 4 ] }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
怎么删除第一个呢?
> db.Oldboy.updateMany({"score":59},{$pop:{"test_list":-1}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b98faa9430c27444ccdd64d"), "name" : "Linux", "score" : 59, "test_list" : [ 2, 3, 4 ] }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64e"), "name" : "Python", "score" : 100 }
{ "_id" : ObjectId("5b98faa9430c27444ccdd64f"), "name" : "Go", "score" : 80 }
{$pop:{"test_list" : -1}} -1 代表最前面, 1 代表最后边 (这和我们大Python正好相反) 记住哦
本文参考链接:
https://www.cnblogs.com/DragonFire/p/9141976.html
五、"$"的奇妙用法
在MongoDB中有一个非常神奇的符号 "$"
"$" 在 update 中 加上关键字 就 变成了 修改器
其实 "$" 字符 独立出现也是有意义的 , 我起名叫做代指符
准备基础数据
# 清空数据
> db.Oldboy.remove({})
WriteResult({ "nRemoved" : 3 }) # 插入3条数据
> db.Oldboy.insertMany([{"name":"Linux","score":100,"test_list":[2,3,4]},{"name":"Python","score":80,"test_list":[1,2,3,4,5]},{"name":"Go","score":59,"test_list":[1,2,3,4,5]}])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5b990189430c27444ccdd650"),
ObjectId("5b990189430c27444ccdd651"),
ObjectId("5b990189430c27444ccdd652")
]
} # 查看所有数据
> db.Oldboy.find()
{ "_id" : ObjectId("5b990189430c27444ccdd650"), "name" : "Linux", "score" : 100, "test_list" : [ 2, 3, 4 ] }
{ "_id" : ObjectId("5b990189430c27444ccdd651"), "name" : "Python", "score" : 80, "test_list" : [ 1, 2, 3, 4, 5 ] }
{ "_id" : ObjectId("5b990189430c27444ccdd652"), "name" : "Go", "score" : 59, "test_list" : [ 1, 2, 3, 4, 5 ] }
首先看个例子: 现在把 "score": 100 的 test_list 里面的 2 改为 9
> db.Oldboy.updateOne({"score":100},{$set:{"test_list.0":9}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b990189430c27444ccdd650"), "name" : "Linux", "score" : 100, "test_list" : [ 9, 3, 4 ] }
{ "_id" : ObjectId("5b990189430c27444ccdd651"), "name" : "Python", "score" : 80, "test_list" : [ 1, 2, 3, 4, 5 ] }
{ "_id" : ObjectId("5b990189430c27444ccdd652"), "name" : "Go", "score" : 59, "test_list" : [ 1, 2, 3, 4, 5 ] }
{$set :{"test_list." : 9}} 这样就是对应 Array 中的下标进行修改了 "test_list.下标"
问题来了 如果 是 一个很长很长很长的 Array 你要查找其中一个值,把这个值修改一下怎么整呢?
把9还原成2
> db.Oldboy.updateMany({"score":100,"test_list":9},{$set:{"test_list.$":2}})
{ "acknowledged" : true, "matchedCount" : 1, "modifiedCount" : 1 }
> db.Oldboy.find()
{ "_id" : ObjectId("5b990189430c27444ccdd650"), "name" : "Linux", "score" : 100, "test_list" : [ 2, 3, 4 ] }
{ "_id" : ObjectId("5b990189430c27444ccdd651"), "name" : "Python", "score" : 80, "test_list" : [ 1, 2, 3, 4, 5 ] }
{ "_id" : ObjectId("5b990189430c27444ccdd652"), "name" : "Go", "score" : 59, "test_list" : [ 1, 2, 3, 4, 5 ] }
神奇不神奇?
$ 字符 在语句中代表了什么呢? 下标,位置
解释一下: 首先我们查询一下db.Oldboy.findOne({"score":100,"test_list":3}) 返回 给我们满足条件的数据对吧
> db.Oldboy.findOne({"score":100,"test_list":3})
{
"_id" : ObjectId("5b990189430c27444ccdd650"),
"name" : "Linux",
"score" : 100,
"test_list" : [
2,
3,
4
]
}
那么 如果 我们 使用 update的话, 满足条件的数据下标位置就会传递到 $ 字符中,在我们更新操作的时候就相当于 对这个位置 的元素进行操作
本文参考链接:
https://www.cnblogs.com/DragonFire/p/9146896.html
六、Array Object 的特殊操作
相比关系型数据库, Array [1,2,3,4,5] 和 Object { 'name':'DragonFire' } 是MongoDB 比较特殊的类型了
特殊在哪里呢?在他们的操作上又有什么需要注意的呢?
那我们先建立一条数据,包含 Array 和 Object 类型
# 清空所有数据
> db.Oldboy.remove({})
WriteResult({ "nRemoved" : 3 }) # 插入一条数据
> db.Oldboy.insert({"name":"路飞学城-骑士计划","price":[19800,19500,19000,18800],"other":{"start":"2018年8月1日","start_time":"08:30","count":150}})
WriteResult({ "nInserted" : 1 }) # 查看所有数据
> db.Oldboy.find()
{ "_id" : ObjectId("5b990568430c27444ccdd653"), "name" : "路飞学城-骑士计划", "price" : [ 19800, 19500, 19000, 18800 ], "other" : { "start" : "2018年8月1日", "start_time" : "08:30", "count" : 150 } }
数据看着可能不太直观,大概是这个样子
{
"_id" : ObjectId("5b17d01a49bf137b585df891"),
"name" : "路飞学城-骑士计划",
"price" : [
19800,
19500,
19000,
],
"other" : {
"start" : "2018年8月1日",
"start_time" : "08:30",
"count" : 150
}
}
好的,这条数据已经完成了
针对这条数据我们进行一系列的操作,并讲解使用方式
Array 小秀一波
把price 中 19000 改为 19300
> db.Oldboy.update({"name":"路飞学城-骑士计划"},{$set:{"price.2":19300}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.Oldboy.find()
{ "_id" : ObjectId("5b990568430c27444ccdd653"), "name" : "路飞学城-骑士计划", "price" : [ 19800, 19500, 19300, 18800 ], "other" : { "start" : "2018年8月1日", "start_time" : "08:30", "count" : 150 } }
db.Oldboy.update({"name":"路飞学城-骑士计划"},{$set:{"price.2":19300}})
我们用了引用下标的方法更改了数值 , "price.2"代指的是 Array 中第3个元素
混合用法
如果 price.1 中小于19800 则加 200
> db.Oldboy.update({"name":"路飞学城-骑士计划","price.1":{$lt:19800}},{$inc:{"price.1":200}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.Oldboy.find() ":200}})
{ "_id" : ObjectId("5b990568430c27444ccdd653"), "name" : "路飞学城-骑士计划", "price" : [ 19800, , 19300, 18800 ], "other" : { "start" : "2018年8月1日", "start_time" : "08:30", "count" : 150 } }
发现第二个价格,加了200块!
复习一下:"price.1":{$lt:19800} 是查找 price.1 小于 19800
复习两下:{$inc:{"price.1":200}} 是什么啊? price.1 拿出来 加上 200 之后 再存进去
那么顺理成章的混合到一起了
上节课我们也学习了 $ 的用法,现在我们混搭 $ 再做一个练习
我们把 price 小于 19500 的 自动补上 200
> db.Oldboy.update({"name":"路飞学城-骑士计划","price":{$lt:19500}},{$inc:{"price.$":200}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.Oldboy.find()
{ "_id" : ObjectId("5b990568430c27444ccdd653"), "name" : "路飞学城-骑士计划", "price" : [ 19800, 19700, , 18800 ], "other" : { "start" : "2018年8月1日", "start_time" : "08:30", "count" : 150 } }
发现第3个更改了!18800并没有更改
细心的同学已经发现了,只改了第一个匹配的!是的 $ 这个只储存一个下标。
批量更改的话,嘻嘻嘻嘻截至2017年1月1日,MongoDB没有这个功能
你只要把这个Array 拿出来,在程序里面改完,原方不动的放回去不就搞定了吗
Object 字典
Object 字典总玩儿过吧,但是这里更像是 JavaScript 中的 Object 对象
1. 把other中 count 改为 199
> db.Oldboy.update({"name":"路飞学城-骑士计划"},{$set:{"other.count":199}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.Oldboy.find()
{ "_id" : ObjectId("5b990568430c27444ccdd653"), "name" : "路飞学城-骑士计划", "price" : [ 19800, 19700, 19500, 18800 ], "other" : { "start" : "2018年8月1日", "start_time" : "08:30", "count" : } }
对了就是在这个对象 打点儿 key 就可以更改数值了 , 要注意的是, 咱们用的 $set 进行修改的,那么就意味着,如果没有"other.count"这个field的话,他会自动创建
这个用法就到这里了,下面我们玩儿个更深的
2. 混合用法
如果 count 小于 200 那么 加 10
> db.Oldboy.update({"name":"路飞学城-骑士计划","other.count":{$lt:200}},{$inc:{"other.count":10}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.Oldboy.find()
{ "_id" : ObjectId("5b990568430c27444ccdd653"), "name" : "路飞学城-骑士计划", "price" : [ 19800, 19700, 19500, 18800 ], "other" : { "start" : "2018年8月1日", "start_time" : "08:30", "count" : } }
这么玩儿完了之后,条件位置的打点儿调用,也尝试过了
Object的用法就这么多了
Array + Object 的用法
Array + Object 的用法 告诉你们,这个老High了
首先,我们要先建立一条 Document 嘻嘻嘻嘻嘻
# 清空所有数据
> db.Oldboy.remove({})
WriteResult({ "nRemoved" : 1 }) # 插入一条数据
> db.Oldboy.insert({"name":"路飞学城-骑士计划","price":[{"start" : "2018年8月1日","start_time" : "08:30","count" : 150},{"start" : "2018年8月2日","start_time" : "09:30","count" : 160},{"start" : "2018年8月3日","start_time" : "10:30","count" : 170},{"start" : "2018年8月4日","start_time" : "11:30","count" : 180},]})
WriteResult({ "nInserted" : 1 }) # 查看所有数据
> db.Oldboy.find()
{ "_id" : ObjectId("5b990b6e430c27444ccdd654"), "name" : "路飞学城-骑士计划", "price" : [ { "start" : "2018年8月1日", "start_time" : "08:30", "count" : 150 }, { "start" : "2018年8月2日", "start_time" : "09:30", "count" : 160 }, { "start" : "2018年8月3日", "start_time" : "10:30", "count" : 170 }, { "start" : "2018年8月4日", "start_time" : "11:30", "count" : 180 } ] }
数据比较复杂,大概是这个样子
{
"_id" : ObjectId("5b17de9d44280738145722b9"),
"name" : "路飞学城-骑士计划",
"price" : [
{
"start" : "2018年8月1日",
"start_time" : "08:30",
"count" : 150
},
{
"start" : "2018年8月2日",
"start_time" : "09:30",
"count" : 160
},
{
"start" : "2018年8月3日",
"start_time" : "10:30",
"count" : 170
},
{
"start" : "2018年8月4日",
"start_time" : "11:30",
"count" : 180
}
]
}
insert的代码要自己写哦,学完一直没怎么练习过,Document添加完成之后
1. 把count 大于 175 的field 加 15
> db.Oldboy.update({"price.count":{$gt:175}},{$inc:{"price.$.count":15}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.Oldboy.find()
{ "_id" : ObjectId("5b990b6e430c27444ccdd654"), "name" : "路飞学城-骑士计划", "price" : [ { "start" : "2018年8月1日", "start_time" : "08:30", "count" : 150 }, { "start" : "2018年8月2日", "start_time" : "09:30", "count" : 160 }, { "start" : "2018年8月3日", "start_time" : "10:30", "count" : 170 }, { "start" : "2018年8月4日", "start_time" : "11:30", "count" : } ] }
分析一下我们的代码:
{"price.count":{$gt:175}}, price 明明是个 Array 啊 怎么就直接 打点儿 count 了呢 这里要知道price 打点儿 就是从内部的Object 中找到 count 小于 175 的结果
{$inc:{"price.$.count":15}} , 这里就比较好理解了,price里面第 $ (大于175的第一个) 个元素中 count 增加 15
我们要学会举一反三 $set 如果忘了, 就再来一个例子吧
2. 把 count 大于 180 的 start 改为 "2018年8月10日"
> db.Oldboy.update({"price.count":{$gt:180}},{$set:{"price.$.start":"2018年8月10日"}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.Oldboy.find()
{ "_id" : ObjectId("5b990b6e430c27444ccdd654"), "name" : "路飞学城-骑士计划", "price" : [ { "start" : "2018年8月1日", "start_time" : "08:30", "count" : 150 }, { "start" : "2018年8月2日", "start_time" : "09:30", "count" : 160 }, { "start" : "2018年8月3日", "start_time" : "10:30", "count" : 170 }, { "start" : "2018年8月10日", "start_time" : "11:30", "count" : 195 } ] }
不做过多解释了,没学会的翻回去看吧
到此为止我们MongoDB的操作阶段就已经学习结束了.
本文参考链接:
https://www.cnblogs.com/DragonFire/p/9147430.html
七、选取跳过排序
我们已经学过MongoDB的 find() 查询功能了,在关系型数据库中的选取(limit),排序(sort) MongoDB中同样有,而且使用起来更是简单
首先我们看下添加几条Document进来
# 清空所有数据
> db.Oldboy.remove({})
WriteResult({ "nRemoved" : 1 }) # 插入多条数据
> db.Oldboy.insertMany([{"name" : "Python","price" : ""},{"name" : "骑士计划","price" : ""},{"name" : "Linux","price" : ""},{"name" : "Python架构","price" : ""},])
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("5b990d6b430c27444ccdd655"),
ObjectId("5b990d6b430c27444ccdd656"),
ObjectId("5b990d6b430c27444ccdd657"),
ObjectId("5b990d6b430c27444ccdd658")
]
} # 查看所有数据
> db.Oldboy.find()
{ "_id" : ObjectId("5b990d6b430c27444ccdd655"), "name" : "Python", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd657"), "name" : "Linux", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd658"), "name" : "Python架构", "price" : "" }
现在有四条Document 根据它们, 对 Limit Skip Sort 分别展开学习 最后来一个 大杂烩
Limit 选取
我要从这些 Document 中取出多少个
做个小例子 : 我只要 2 条 Document
> db.Oldboy.find().limit(2)
{ "_id" : ObjectId("5b990d6b430c27444ccdd655"), "name" : "Python", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
结果是很明显的,很赤裸裸的,很一丝不挂的
但是我还是要解释一下 : limit(2) 就是选取两条Document, 从整个Collection的第一条 Document 开始选取两条
如果我们不想从第一条Document开始选取,怎么办呢?
Skip 跳过
我要跳过多少个Document
做个小例子 : 我要跳过前两个 Document 直接从第三个Document 开始
> db.Oldboy.find().skip(2)
{ "_id" : ObjectId("5b990d6b430c27444ccdd657"), "name" : "Linux", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd658"), "name" : "Python架构", "price" : "" }
结果还是很明显,很赤裸
按照国际惯例解释一下 : skip(2) 就是跳过两条Document, 从整个Collection 的第一条 Document 开始跳,往后跳两条
另一个例子 : 跳过第一条 直接从 第二条 开始
> db.Oldboy.find().skip(1)
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd657"), "name" : "Linux", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd658"), "name" : "Python架构", "price" : "" }
问题来了,我只想要第二条和第三条怎么处理呢?
Limit + Skip
从这儿到那儿 的 选取
就是刚才的问题,一个小例子 : 我只想要第二条和第三条怎么处理呢
> db.Oldboy.find().skip(1).limit(2)
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd657"), "name" : "Linux", "price" : "" }
国际惯例 : 跳过第一条Document 从第二条开始选取两条 Document
别着急,还有另一种写法
> db.Oldboy.find().limit(2).skip(1)
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd657"), "name" : "Linux", "price" : "" }
两种写法完全得到的结果完全一样但是国际惯例的解释却不同
国际惯例 : 选取两条Document 但是要 跳过 第一条Document 从 第二条 开始 选取
绕了半天,都晕了,注意这里特别要注意了!!!!!! 这里的两种写法,一定一定一定要记住一个,因为只要记住一个就行了,完全完全没区别,一个符合中国人的理解,一个是其他国家的理解
Sort 排序
将结果按照关键字排序
做个小例子 : 将find出来的Document 按照 price 进行 升序 | 降序 排列
升序
> db.Oldboy.find().sort({"price":1})
{ "_id" : ObjectId("5b990d6b430c27444ccdd658"), "name" : "Python架构", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd655"), "name" : "Python", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd657"), "name" : "Linux", "price" : "" }
降序
> db.Oldboy.find().sort({"price":-1})
{ "_id" : ObjectId("5b990d6b430c27444ccdd657"), "name" : "Linux", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd655"), "name" : "Python", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd658"), "name" : "Python架构", "price" : "" }
国际惯例 : 按照 price 字段进行升序 , 1 为升序 , -1 为降序
Limit + Skip + Sort
一个例子 : 选取第二条第三条 并 按照 price 进行 升序排列
> db.Oldboy.find()
{ "_id" : ObjectId("5b990d6b430c27444ccdd655"), "name" : "Python", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd657"), "name" : "Linux", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd658"), "name" : "Python架构", "price" : "" } > db.Oldboy.find().skip(1).limit(2).sort({"price":1})
{ "_id" : ObjectId("5b990d6b430c27444ccdd655"), "name" : "Python", "price" : "" }
{ "_id" : ObjectId("5b990d6b430c27444ccdd656"), "name" : "骑士计划", "price" : "" }
问题出现了, 按道理不应该是 9800 然后 19800 吗?
知识点来喽
重点 : Sort + Skip + Limit 是有执行优先级的 他们的界别分别是 优先 Sort 其次 Skip 最后 Limt
Skip + Limit 的优先级 也是先 Skip 再 Limit
看一次,记不住
看两次,不会用
看三次,不如自己做一次
做一次,不如做三次
练习一下加深印象
本文参考链接:
https://www.cnblogs.com/DragonFire/p/9154832.html
八、客户端操作
windows客户端
nosqlbooster4mongo(客户端)
链接:https://pan.baidu.com/s/1zZRAtSwj8H1hliErA1kOOA 密码:tyng
使用
打卡之后,长这个样子

点击左侧的Connect,点击Create
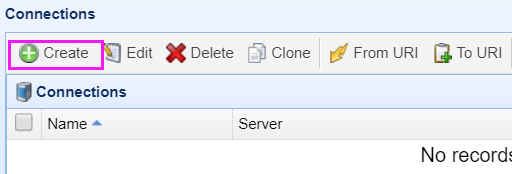
默认配置就可以了,点击测试连接
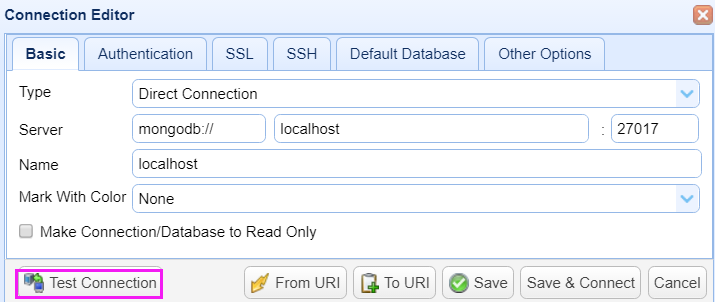
出现ok,表示成功了

点击保存并连接
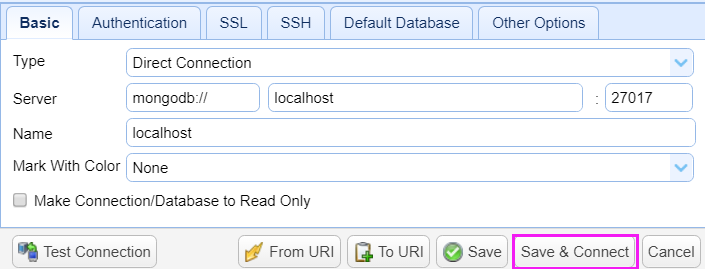
默认的2个数据库admin和local,是不能操作的!
只能操作自己创建的
查看数据
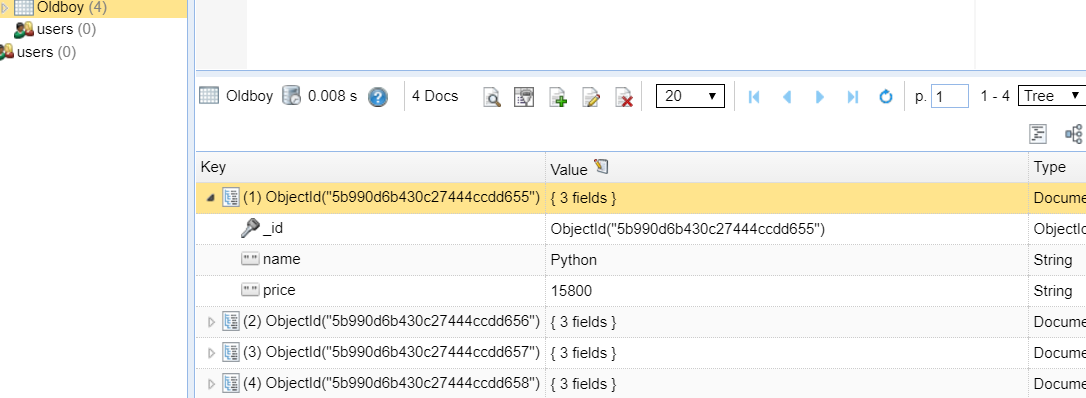
双击Oldbody,也就是表,效果如下:
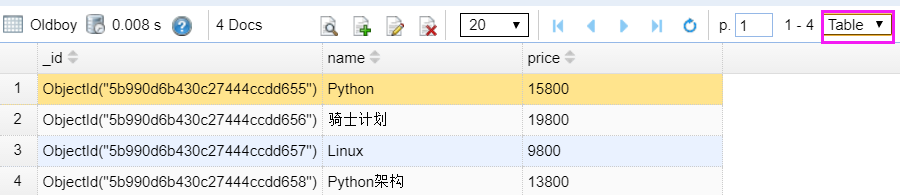
选择右侧的table,可以展示位表格数据
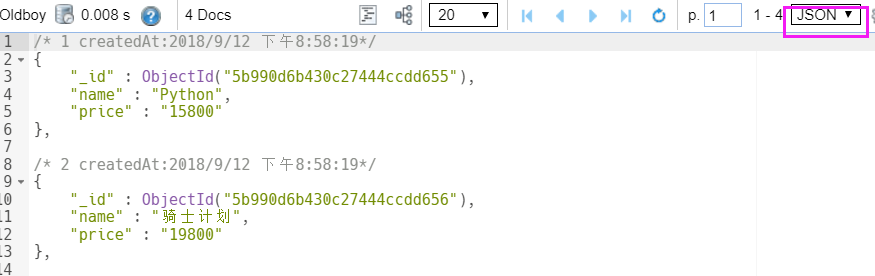
也可以选择,展示为JSON数据
光标移动到ORM语句上,按F5,就会执行SQL!
所以:今后想执行哪句,将光标移动到此,按F5,就会执行指定的ORM语句!非常方便!
插入数据
插入一条数据
查看所有数据
其他操作,遵循MongoDB的ORM语法即可!这里就不演示了!
python程序
python操作MongoDB,需要安装模块 pymongo
pip install pymongo
连接
新建一个文件 test_mongo.py
import pymongo # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 res = mongo_db.goods.find()
print(res)
执行输出:
<pymongo.cursor.Cursor object at 0x000001F68B7D09E8>
插入数据
import pymongo # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 # 插入多条数据
res = mongo_db.goods.insert_many([{"name" : "酸菜","price" : ""},{"name" : "白菜","price" : ""},{"name" : "小青菜","price" : "0.5"},])
print(res)
执行输出:
<pymongo.results.InsertManyResult object at 0x00000143817B3548>
查询数据
查询所有
可以将结果转换为列表
import pymongo # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 # 插入多条数据
res = mongo_db.goods.find()
print(list(res))
执行输出:
[{'_id': ObjectId('5b991895e125324a58178dd3'), 'name': '酸菜', 'price': ''}, {'_id': ObjectId('5b991895e125324a58178dd4'), 'name': '白菜', 'price': ''}, {'_id': ObjectId('5b991895e125324a58178dd5'), 'name': '小青菜', 'price': '0.5'}]
也可以对结果做for循环
import pymongo # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 # 插入多条数据
res = mongo_db.goods.find()
for i in res:
print(i)
执行输出:
{'_id': ObjectId('5b991895e125324a58178dd3'), 'name': '酸菜', 'price': ''}
{'_id': ObjectId('5b991895e125324a58178dd4'), 'name': '白菜', 'price': ''}
{'_id': ObjectId('5b991895e125324a58178dd5'), 'name': '小青菜', 'price': '0.5'}
查询单条
import pymongo # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 # 插入多条数据
res = mongo_db.goods.find_one()
print(res)
执行输出:
{'_id': ObjectId('5b991895e125324a58178dd3'), 'name': '酸菜', 'price': ''}
查询指定id呢?
由于_id是ObjectId对象,需要导入模块
import pymongo
from bson import ObjectId # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 # 插入多条数据
res = mongo_db.goods.find({"_id":ObjectId("5b991895e125324a58178dd5")})
for i in res:
print(i)
执行输出:
{'_id': ObjectId('5b991895e125324a58178dd5'), 'name': '小青菜', 'price': '0.5'}
更新
import pymongo
from bson import ObjectId # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 res = mongo_db.goods.update_one({"name":"小青菜"},{"$set":{"price":2}})
print(res)
执行输出:
<pymongo.results.UpdateResult object at 0x000001AF61E332C8> None
删除
import pymongo
from bson import ObjectId # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 res = mongo_db.goods.delete_one({"name":"小青菜"})
print(res,res.raw_result)
执行输出:
<pymongo.results.DeleteResult object at 0x000001825B2134C8> {'n': 0, 'ok': 1.0}
排序
import pymongo
from bson import ObjectId # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 res = mongo_db.goods.find({}).skip(1).limit(2)
print(list(res))
执行输出:
[{'_id': ObjectId('5b991895e125324a58178dd4'), 'name': '白菜', 'price': ''}]
进阶
import pymongo
from bson import ObjectId # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 res = mongo_db.goods.find({}).sort("age",pymongo.DESCENDING)
print(list(res))
执行输出:
[{'_id': ObjectId('5b991895e125324a58178dd3'), 'name': '酸菜', 'price': ''}, {'_id': ObjectId('5b991895e125324a58178dd4'), 'name': '白菜', 'price': ''}]
高级操作
import pymongo
from bson import ObjectId # 连接数据库
mclient = pymongo.MongoClient(host="127.0.0.1", port=27017)
mongo_db = mclient["testdb"] # 切换数据库,不存在则创建 res = mongo_db.goods.find({}).sort("age",pymongo.DESCENDING).skip(1).limit(2)
print(list(res))
执行输出:
[{'_id': ObjectId('5b991895e125324a58178dd4'), 'name': '白菜', 'price': ''}]
今日内容总结
MongoDB:文件型数据库 find() update() delete() insert()持久化
redis:get set 默认持久化 1.MongoDB是什么及其概念:
MongoDB是一个快速存储数据(JSON),并ORM操作的数据库
MongoDB是文件型数据库,不存在关系
MongoDB中基本上存储了大量的冗余数据
MongoDB中没有字段的概念
MongoDB是非常灵活的数据库
专有名词:
Mysql MongoDB
DB DB
Table Colletions Table概念
row Documents row概念
字段 Field 字段概念
_id 唯一概念 不存在即创建:
如果使用了不存在的对象即创建该对象 2.MongoDB的存储结构: 关系型数据库:
id name age course score score1
1 子龙 84 python 99 0
2 xiaoqinglong 73 javascript 0 99 文件型数据库:
[
{
_id:ObjectId("1298478375f8234d")
ids:1,
names:子龙,
ages:84,
courses:python,
scores:99
},
{
id:2,
name:xiaoqinglong,
age:73,
course:javascript,
score1:99
}
] 3.初识MongoDB
1.安装mongoDB bin目录环境变量
2.启动mongoDB:
mongod (手动创建文件夹) c:\data\db
mongod --dbpath "E:\Program Files\MongoDB\data\db"
3.MongoDB的默认端口号:27017 (redis:6379 MySql:3306) 4.mongodb 的指令:
show dbs 查看当前数据库服务器中的所有数据库(DB)
use dbname 创建或使用数据库
db 查看当前使用的数据库 / 代指当前使用的数据库的名字或对象
show tables 查看当前数据库的 数据表 Collations 5.MongoDB的增删改查:
增:
db.Collations.insert({"name":"zilong"})
db.Collations.insert([{"name":"zilong"},{"name":""}])
// insert 方式 被官方不推荐了
1.db.Collations.insertOne({}) 只能单行操作插入
2.db.Collations.insertMany([{},{}]) 根据array(列表)中的元素插入多行数据 改:
db.user.update({"name":"酸菜"},{$set:{"name":"老坛酸菜"}})
db.user.update({"name":"酸菜"},{$set:{"name":"老坛酸菜"}},多条修改:true)
// update 方式 被官方不推荐了
db.user.updateOne({"name":"子龙"},{$set:{"name":"赵子龙"}})
db.user.updateMany({"name":"小青龙"},{$set:{"name":"白虎"}}) 删除:
db.user.remove({})
// remove 方式 被官方不推荐了
db.user.deleteOne({"name":"白虎"})
db.user.deleteMany({"name":"翠花儿"}) 查:
1.db.find({条件:1}) 2.db.findOne({条件:1})
db.user.findOne({"name":"酸菜","age":1}) 逗号相当于 and 3.数学比较符:
$lt 小于
$gt 大于
$lte 小于等于
$gte 大于等于
find({"字段":{$比较符:值}})
db.user.find({"age":{$gt:2}}) # where age > 2
6.修改器:
$set : 将某个key的value 修改为 某值
$unset: 删除字段 {$unset: {test: "" }} $inc:{$inc:{"age":100}} 原有值基础上增加 xxx array:
$push : 向数组Array最后位置插入一条元素 {$push:{"hobby":1234}} [].append(1234)
$pull : 删除数组中的某一个元素 {$pull:{"hobby":123}}
#删除字典 db.user.updateOne({"_id":ObjectId("5b98794ec34b9812bcabdde7"),"hobby.age":18},{$unset:{"hobby.$":1}})
$pop : 删除数组的第一个或最后一个
最后一个:{$pop:{"hobby":1}}
第一个:{$pop:{"hobby":-1}} $ :代指符合条件的某数据 array.$ :
db.user.updateOne({"_id":ObjectId("5b98794ec34b9812bcabdde7"),"hobby.name":"翠花儿"},{$set:{"hobby.$.name":"农妇山泉"}}) 查询$关键字:
$in: db.user.find({age:{$in:[1,2,3]}}) 字段符合in,array中的数值
$or: db.user.find({$or:[{age:{$in:[1,2,3,4]}},{name:666}]})
$all: db.user.find({test:{$all:[1,2]}}) array元素相同即可 或 包含所有$all中的元素 7.数据类型:
基于BSON结构
string 字符串,Utf8
integer 整型
double 双精度,包含float,MongoDB中不存在Float
Null 空数据类型
Date 时间类型 ISODate(2018-9-12 10:45:58)
Timestamp 时间戳类型 ISODate("") ObjectId 对象ID Documents 自生成的 _id ObjectId("5b98794ec34b9812bcabdde7")
#"5b151f85" 代指的是时间戳,这条数据的产生时间
#"364098" 代指某台机器的机器码,存储这条数据时的机器编号
#"09ab" 代指进程ID,多进程存储数据的时候,非常有用的
#"2e6b26" 代指计数器,这里要注意的是,计数器的数字可能会出现重复,不是唯一的
#以上四种标识符拼凑成世界上唯一的ObjectID
#只要是支持MongoDB的语言,都会有一个或多个方法,对ObjectID进行转换
#可以得到以上四种信息 不能够被 JSON 化
from BSON import ObjectId ?arrays [] 数组类型 相当于python中的list $pop $push $pull
?object {name:1} 对象类型 相当于python中的dict ps:由于MongoDB存储自由度没有限制,所以我们程序员要定义好数据格式,尽可能少的修改格式(开发阶段随便修改) 8. 排序 跳过 显示条目
sort 排序 find().sort(id:-1/1) 1 升序 2 降序 desc
skip 跳过 find().skip(2) 从三条开始返回
limit 显示条目 find().limit(2)只显示前两条 混搭:
db.user.find({}).sort({age:-1 }).skip(1).limit(2)
根据age字段进行降序排列,并且跳过第一条,从第二条开始返回,两条数据 9.pymongo:
sort("age",pymongo.DESCENDING)
今日作业
1.自己练习一下$的用法
2.基于昨天的web版问答系统,问了什么问题,存在Mongodb数据库里
3.回答什么答案,存在Mongodb数据库里
4.做一个聊天记录查询的功能 附加作业:
最好:
{
user_name:123,chat_list:[
{q:"",a:"",update_at:123123123}
]
} 进阶:
{
user_name:123,chat_list:[
{q:"",a:"",update_at:123123123}
],
# 问题和回答统计,使用$inc
qcount:10,acount:10
}
python 全栈开发,Day124(MongoDB初识,增删改查操作,数据类型,$关键字以及$修改器,"$"的奇妙用法,Array Object 的特殊操作,选取跳过排序,客户端操作)的更多相关文章
- python 全栈开发,Day5(字典,增删改查,其他操作方法)
一.字典 字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据.存储大量的数据,是关系型数据,查询数据快. 列表是从头遍历到尾字典使用二分查找 二分查找也称折半查找(Bi ...
- 巨蟒python全栈开发flask8 MongoDB回顾 前后端分离之H5&pycharm&夜神
1.MongoDB回顾 .启动 mongod - 改变data/db位置: --dbpath D:\data\db mongod --install 安装windows系统服务 mongod --re ...
- python 全栈开发,Day17(初识面向对象)
一.引子 第一次参加工作,进入了一家游戏公司,公司需要开发一款游戏<人狗大战>一款游戏,首先得把角色和属性定下来. 角色有2个,分别是人和狗属性如下:人 :昵称.性别.血.攻击力狗 :名字 ...
- python全栈开发day21面向对象初识总结
- python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)
python全栈开发中级班全程笔记 第三章:员工信息增删改查作业代码 作业要求: 员工增删改查表用代码实现一个简单的员工信息增删改查表需求: 1.支持模糊查询,(1.find name ,age fo ...
- Python全栈开发【面向对象】
Python全栈开发[面向对象] 本节内容: 三大编程范式 面向对象设计与面向对象编程 类和对象 静态属性.类方法.静态方法 类组合 继承 多态 封装 三大编程范式 三大编程范式: 1.面向过程编程 ...
- Python全栈开发【模块】
Python全栈开发[模块] 本节内容: 模块介绍 time random os sys json & picle shelve XML hashlib ConfigParser loggin ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
随机推荐
- .NET MVC中的ActionResult
一 摘要 本文介绍了ASP.NET MVC中的ActionResult,本节主要介绍 EmptyResult / Content Result /JavaScriptResult /JsonResu ...
- golang数组排序算法
冒泡排序 图 https://www.cnblogs.com/onepixel/articles/7674659.html package main import ( "fmt" ...
- POJ - 1584 A Round Peg in a Ground Hole(判断凸多边形,点到线段距离,点在多边形内)
http://poj.org/problem?id=1584 题意 按照顺时针或逆时针方向输入一个n边形的顶点坐标集,先判断这个n边形是否为凸包. 再给定一个圆形(圆心坐标和半径),判断这个圆是否完全 ...
- Eclipse Groovy插件使用时出现的错误 org.eclipse.core.runtime.InvalidRegistryObjectException: Invalid registry object
在eclipse marketplace中下载了groovy插件,发现使用的groovy版本跟项目中使用的groovy版本不一致. 于是在Preferences -> Groovy -> ...
- SQL Server进阶(二)字段类型
概述 系统数据类型详情 SqlDbType namespace System.Data { // // 摘要: // 指定要用于 System.Data.SqlClient.SqlParameter ...
- Javaweb学习笔记——(八)——————常见系统体系结构,Tomcat,以及web的内部外部应用,http协议概述
·软件系统体系结构: 1.常见软件系统体系结构B/S.C/S C/S 1.C/S结构即客户端/服务器(Client/Server),列如QQ: 2.需要编写服务器端程序,以及客户端程序,列如我们安装的 ...
- pyqt5-布局控件
在布局中添加控件用addWidght(),添加布局用addLayout() 垂直布局QVBoxLayout 需要导入 from PyQt5.QtWidgets import QVBoxLayout ...
- JavaSE之概述
作此篇是鉴于个人Java学习之需要,也便于日后进一步归纳与复习. 规定: 1 Java全面概述[囊括 Java工作原理,JVM方面知识,关键字(final,static,public,pr ...
- 【centos】 error: command 'gcc' failed with exit status 1
原文连接http://blog.csdn.net/fenglifeng1987/article/details/38057193 用安装Python模块出现error: command 'gcc' f ...
- Mybatis进阶学习笔记——动态sql
1.if标签 <select id="queryByNameAndTelephone" parameterType="Customer" resultTy ...