pandas的聚合操作: groupyby与agg
pandas提供基于行和列的聚合操作,groupby可理解为是基于行的,agg则是基于列的
从实现上看,groupby返回的是一个DataFrameGroupBy结构,这个结构必须调用聚合函数(如sum)之后,才会得到结构为Series的数据结果。
而agg是DataFrame的直接方法,返回的也是一个DataFrame。当然,很多功能用sum、mean等等也可以实现。但是agg更加简洁, 而且传给它的函数可以是字符串,也可以自定义,参数是column对应的子DataFrame
一、pandas.group_by
首先来看一下案例的数据格式,使用head函数调用DataFrame的前8条记录,这里一共4个属性
column_map.head(8)
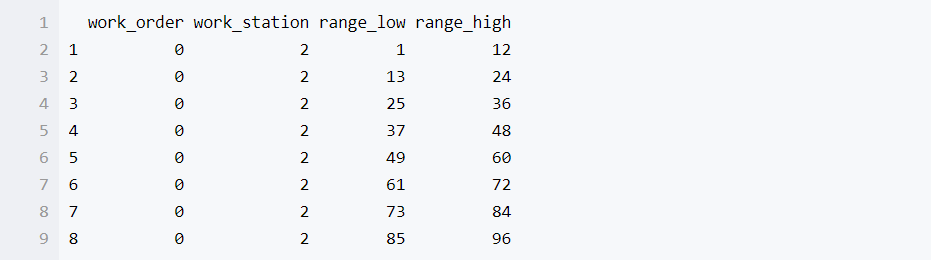
work_order 表示工序, work_station表示工位,rang_low, range_high 表示对应记录的上下限,现在使用groupby统计每个工序工位下面各有多少条记录
column_map.groupby(['work_order','work_station'])
我们会发现输出的是一个GroupBy类,并非我们想要的结果
<pandas.core.groupby.DataFrameGroupBy object at 0x111242630>
还需要加上一个聚合函数,比如
wo_ws_group = column_map.groupby(['work_order','work_station'])wo_ws_group.size()
我们就可以得到

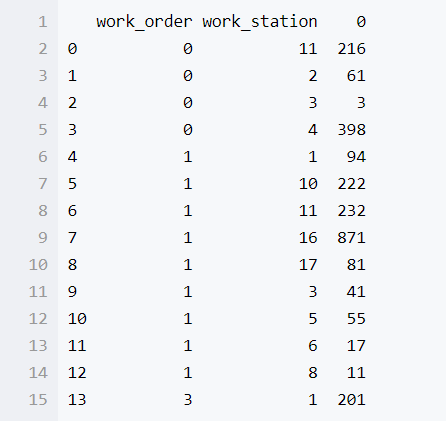
新出现的列对应着每个工序工位下面有多少条记录
但是我们可以发现它的格式已经和我们平时使用的DataFrame不太一样了,我们可以使用下面的命令解决
wo_ws_group.size().reset_index()
想要查询具体每一个记录,可以使用loc命令


使用get_group可以查询具体每一个分组下面的所有记录
wo_ws_group.get_group(('0','11'))
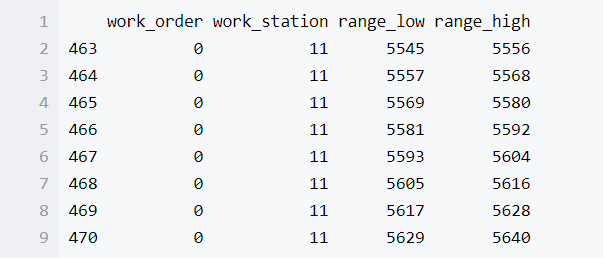
因为比较多就显示全部了,使用head,显示前几条记录
wo_ws_group.get_group(('0','11')).head(8)
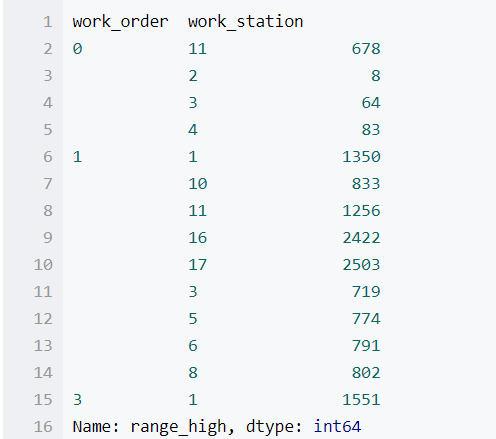
我们还可以使用idxmin(),idxmax()函数,获得每一个分组下面所有记录中数值最大最小的index
wo_ws_group['range_low'].idxmin()


对于分组结果的每一列还可以使用apply,进行一些函数的二次处理,如
wo_ws_group['work_order'].apply(lambda x:2*x).head(8)
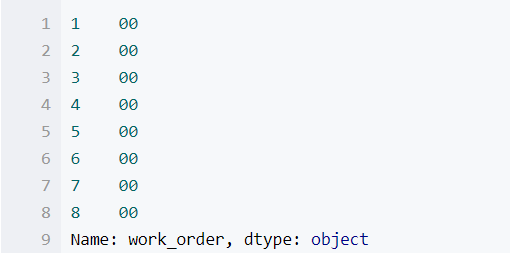
由于这里的0是字符串类型,所以2*以后都变成了2个0
二、pandas.agg
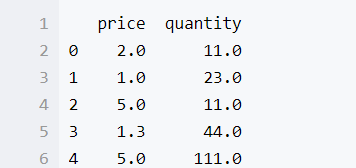
agg的使用比groupby还要简介一些,我们现自己创建一个DataFrame作为例子
data = pd.DataFrame([[2,11],[1,23],[5,11],[1.3,44],[5,111]],columns = ['price','quantity'],dtype = float)
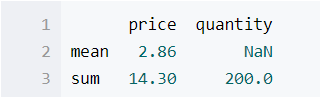
使用agg统计每一列的求和与平均值
data.agg({'price':['sum','mean'],'quantity':['sum']})
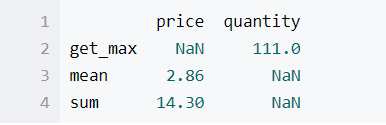
如果需要自定义一些函数的 话可以使用lambda函数

pandas的聚合操作: groupyby与agg的更多相关文章
- 数据分析入门——pandas之DataFrame多层/多级索引与聚合操作
一.行多层索引 1.隐式创建 在构造函数中给index.colunms等多个数组实现(datafarme与series都可以) df的多级索引创建方法类似: 2.显式创建pd.MultiIndex 其 ...
- Python Pandas分组聚合
Pycharm 鼠标移动到函数上,CTRL+Q可以快速查看文档,CTR+P可以看基本的参数. apply(),applymap()和map() apply()和applymap()是DataFrame ...
- Pandas 分组聚合
# 导入相关库 import numpy as np import pandas as pd 创建数据 index = pd.Index(data=["Tom", "Bo ...
- MongoTemplate聚合操作
Aggregation简单来说,就是提供数据统计.分析.分类的方法,这与mapreduce有异曲同工之处,只不过mongodb做了更多的封装与优化,让数据操作更加便捷和易用.Aggregation操作 ...
- Pandas的高级操作
pandas数据处理 1. 删除重复元素 使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True keep参数: ...
- Update(Stage4):sparksql:第3节 Dataset (DataFrame) 的基础操作 & 第4节 SparkSQL_聚合操作_连接操作
8. Dataset (DataFrame) 的基础操作 8.1. 有类型操作 8.2. 无类型转换 8.5. Column 对象 9. 缺失值处理 10. 聚合 11. 连接 8. Dataset ...
- 数据分析05 /pandas的高级操作
数据分析05 /pandas的高级操作 目录 数据分析05 /pandas的高级操作 1. 替换操作 2. 映射操作 3. 运算工具 4. 映射索引 / 更改之前索引 5. 排序实现的随机抽样/打乱表 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (27) ------ 第五章 加载实体和导航属性之关联实体过滤、排序、执行聚合操作
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 5-9 关联实体过滤和排序 问题 你有一实体的实例,你想加载应用了过滤和排序的相关 ...
- MongoDB 聚合操作
在MongoDB中,有两种方式计算聚合:Pipeline 和 MapReduce.Pipeline查询速度快于MapReduce,但是MapReduce的强大之处在于能够在多台Server上并行执行复 ...
随机推荐
- Spring FactoryBean应用
Spring 中有两种类型的Bean,一种是普通Bean,另一种是工厂Bean 即 FactoryBean.FactoryBean跟普通Bean不同,其返回的对象不是指定类的一个实例,而是该Facto ...
- shell 基本概述
SHELL的概念 SHELL是一个命令行解释器,它为用户提供了一个向Linux内核发送请求以便运行程序的界面系统级程序, 用户可以用shell来启动,挂起,停止甚至是编写一些程序. Shell还是 ...
- json模块&xml
json模块将数据修改成字符串,方便其他语言进行识别. 只认双引号,不认单引号.使用json.dumps的操作步骤 先将单引号修改成单引号 将变量使用单引号引起来 将数据类型编程json字符串 jso ...
- 基于iscroll的better-scroll在vue中的使用
什么是 better-scroll better-scroll 是一个移动端滚动的解决方案,它是基于 iscroll 的重写,它和 iscroll 的主要区别在这里.better-scroll 也很强 ...
- C#通过shell32获取文件详细备注信息
1.从系统Window/System32文件夹中Copy出 Shell32.dll Com组件 将Shell32.dll文件引用到项目中,并设置“嵌入互操作类型”为false http://blog. ...
- .net core Asp.net Mvc Ef 网站搭建 vs2017 1)
1)开发环境搭建 首先下载安装vs2017 地址 :https://www.visualstudio.com/zh-hans/downloads/ 安装勾选几项如下图 ,注意点在单个组件时.net ...
- TModalResult 和 MessageBox 返回值
//其实是对应的{ TModalResult values } const mrNone = ; mrOk = idOk; mrCancel = idCancel; mrAbort = idAbort ...
- day27 网络通信协议 tcp/udp区别
今日主要内容: 一.网络通信协议 二.tcp udp协议下的socket 一.网络通信协议 1.1互联网的本质就是一系列的网络协议 本机IP地址('127.0.0.1',xxxx) 互联网连接的电脑互 ...
- MySQL5.6数据库8小时内无请求自动断开连接
问题: 最近的项目中,发现Mysql数据库在8个小时内,没有请求时,会自动断开连接,这是MySQL服务器的问题.The last packet successfully received from t ...
- gitblit系列七:使用Jenkins配置自动化持续集成构建
1.安装 方法一: 下载jenkin.exe安装文件 下载地址:https://jenkins.io/content/thank-you-downloading-windows-installer/ ...