学习大数据基础框架hadoop需要什么基础
什么是大数据?进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB(1MB大约等于一百万字节)、GB(1024MB)、TB(1024GB),一直向上攀升,目前,PB(等于1024TB)级的数据系统已经很常见,随着移动个人数据、社交网站、科学计算、证券交易、网站日志、传感器网络数据量的不断加大,国内拥有的总数据量早已超出 ZB(1ZB=1024EB,1EB=1024PB)级别。
传统的数据处理方法是:随着数据量的加大,不断更新硬件指标,采用更加强大的CPU、更大容量的磁盘这样的措施,但现实是:数据量增大的速度远远超出了单机计算和存储能力提升的速度。
而“大数据”的处理方法是:采用多机器、多节点的处理大量数据方法,而采用这种新的处理方法,就需要有新的大数据系统来保证,系统需要处理多节点间的通讯协调、数据分隔等一系列问题。
总之,采用多机器、多节点的方式,解决各节点的通讯协调、数据协调、计算协调问题,处理海量数据的方式,就是“大数据”的思维。其特点是,随着数据量的不断加大,可以增加机器数量,水平扩展,一个大数据系统,可以多达几万台机器甚至更多。
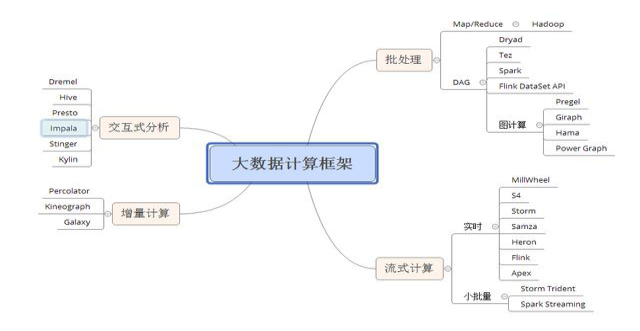
Hadoop最初主要包含分布式文件系统HDFS和计算框架MapReduce两部分,是从Nutch中独立出来的项目。在2.0版本中,又把资源管理和任务调度功能从MapReduce中剥离形成YARN,使其他框架也可以像MapReduce那样运行在Hadoop之上。与之前的分布式计算框架相比,Hadoop隐藏了很多繁琐的细节,如容错、负载均衡等,更便于使用。
Hadoop也具有很强的横向扩展能力,可以很容易地把新计算机接入到集群中参与计算。在开源社区的支持下,Hadoop不断发展完善,并集成了众多优秀的产品如非关系数据库HBase、数据仓库Hive、数据处理工具Sqoop、机器学习算法库Mahout、一致性服务软件ZooKeeper、管理工具Ambari等,形成了相对完整的生态圈和分布式计算事实上的标准。
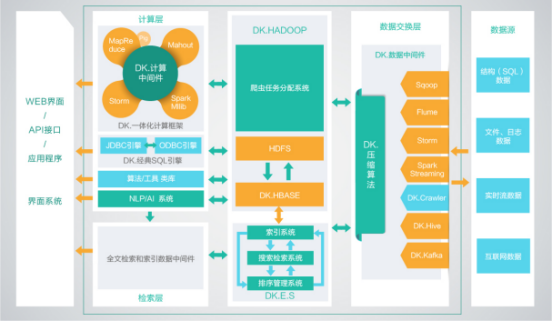
大快的大数据通用计算平台(DKH),已经集成相同版本号的开发框架的全部组件。如果在开源大数据框架上部署大快的开发框架,需要平台的组件支持如下:
数据源与SQL引擎:DK.Hadoop、spark、hive、sqoop、flume、kafka
数据采集:DK.hadoop
数据处理模块:DK.Hadoop、spark、storm、hive
机器学习和AI:DK.Hadoop、spark
NLP模块:上传服务器端JAR包,直接支持
搜索引擎模块:不独立发布
大快大数据平台(DKH),是大快公司为了打通大数据生态系统与传统非大数据公司之间的通道而设计的一站式搜索引擎级,大数据通用计算平台。传统公司通过使用DKH,可以轻松的跨越大数据的技术鸿沟,实现搜索引擎级的大数据平台性能。
DKH,有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。
DKH,更是通过大快独有的中间件技术,将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
DKH,虽然进行了高度的整合,但是仍然保持了开源系统的全部优点,并与开源系统100%兼容,基于开源平台开发的大数据应用,无需经过任何改动,即可在DKH上高效运行,并且性能会有最高5倍的提升。
DKH,更是集成了大快的大数据一体化开发框架(FreeRCH), FreeRCH开发框架提供了大数据、搜索、自然语言处理和人工智能开发中常用的二十多个类,通过总计一百余种方法,实现了10倍以上的开发效率的提升。
DKH的SQL版本,还提供了分布式MySQL的集成,传统的信息系统,可无缝的实现面向大数据和分布式的跨越。
DKH标准平台技术构架图
学习大数据基础框架hadoop需要什么基础的更多相关文章
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- Java软件开发者,如何学习大数据?
正常来讲学习大数据之前都要做到以下几点 1.学习基础的编程语言(java,python) 2.掌握入门编程基础(linux操作,数据库操作.git操作) 3.学习大数据里面的各种框架(hadoop.h ...
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- 一篇了解大数据架构及Hadoop生态圈
一篇了解大数据架构及Hadoop生态圈 阅读建议,有一定基础的阅读顺序为1,2,3,4节,没有基础的阅读顺序为2,3,4,1节. 第一节 集群规划 大数据集群规划(以CDH集群为例),参考链接: ht ...
- 大数据测试之初识Hadoop
大数据测试之初识Hadoop POPTEST老李认为测试开发工程师是面向测试的开发,也就是说,写代码就是为完成测试任务服务的,写自动化测试(性能自动化,功能自动化,安全自动化,接口自动化等等)的cas ...
- 一起来学大数据——走进Linux之门,学习大数据的重中之重
昨天我们看了有关大数据Hadoop的一些知识点,但是要在学习大数据之前,我们还是要为大数据的环境做一些的部署. 那么,今天我们就来讲讲开启我们大数据之路的Linux,跟上我们的脚步yo~ Linux介 ...
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
- 12.Linux软件安装 (一步一步学习大数据系列之 Linux)
1.如何上传安装包到服务器 有三种方式: 1.1使用图形化工具,如: filezilla 如何使用FileZilla上传和下载文件 1.2使用 sftp 工具: 在 windows下使用CRT 软件 ...
随机推荐
- Python数据分析库pandas基本操作
Python数据分析库pandas基本操作2017年02月20日 17:09:06 birdlove1987 阅读数:22631 标签: python 数据分析 pandas 更多 个人分类: Pyt ...
- wx小程序功能总结
注:1. 微信默认的宽度为750rpx , 不会变化. 2.bindtap 绑定触摸事件,可冒泡 catchtap 绑定触摸事件,不可冒泡 1.唤出系统菜单 2.上传图片 showSelection( ...
- DocumentFragment --更快捷操作DOM的途径
使用DocumentFragment将一批子元素添加到任何类似node的父节点上,对这批子元素的操作不需要一个真正的根节点.可以不依赖可见的DOM来构造一个DOM结构,而效率高是它真正的优势,试验表明 ...
- Codeforce 9C - Hexadecimal's Numbers
One beautiful July morning a terrible thing happened in Mainframe: a mean virus Megabyte somehow got ...
- JavaScript中的内置对象-8--3.Math-Math对象的方法-min()- max()- ceil() - floor()- round()- abs(); Math对象的random()方法;
JavaScript内置对象-3.Math(数值) 学习目标 1.掌握Math对象的方法: min() max() ceil() floor() round() abs() Math.min() 语法 ...
- ORA-00600: internal error code, arguments: [kole_t2u], [34]
数据库版本10.2.0.5,Alert 日志存在ORA-600报错 ORA-00600: internal error code, arguments: [kole_t2u], [34], [] -- ...
- 【leetcode】66-PlusOne
problem Plus One code class Solution { public: vector<int> plusOne(vector<int>& digi ...
- MAC使用pycharm上传代码到Github上
本人的电脑已经在GitHub中添加成功了SSH keys! 以下为在pycharm中上传代码到Github的步骤. Step1:打开pycharm,preferences---plugins(插件)选 ...
- Light OJ 1296:Again Stone Game(SG函数打表找规律)
Alice and Bob are playing a stone game. Initially there are n piles of stones and each pile contains ...
- Beta周第14次Scrum会议(11/23)【王者荣耀交流协会】
一.小组信息 队名:王者荣耀交流协会 小组成员 队长:高远博 成员:王超,袁玥,任思佳,王磊,王玉玲,冉华 小组照片 二.开会信息 时间:2017/11/23 17:02~17:14,总计12min. ...