ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包:
- K-均值聚类(K-means) stats::kmeans()、fpc::kmeansruns()
- K-中心点聚类(K-Medoids) cluster::pam() 、fpc::pamk()
- 层次聚类 stats::hclust()、BIRCH、CURE
- 密度聚类 fpc::DBSCAN(),OPTICS
- 网格聚类 optpart::clique
- 模型聚类 EM算法(期望最大化算法) mclust::Mclust() 、RWeka::Cobweb()
- 模糊聚类 FCM(Fuzzy C-Means)算法 cluster::fanny() 、e1071::cmeans()
K均值聚类
- stats::kmeans()
- fpc::kmeansruns()
stats::kmeans()
Usage:kmeans(x, centers, iter.max = 10, nstart = 1, algorithm = c("Hartigan-Wong", "Lloyd", "Forgy", "MacQueen"), trace=FALSE)
- x:聚类对象
- centers: 是聚类个数或者是聚类中心
- iter.max:是允许的最大迭代次数,默认为10
- nstart:是初始被随机选择的聚类中心
示例代码
##数据集进行备份
newiris <- iris
newiris$Species <- NULL
library(stats)
kc <- kmeans(x=newiris, centers = 3)
##查看具体分类情况
fitted(kc)
##在三个聚类中分别统计各种花出现的次数
table(iris$Species, kc$cluster)
查看运行结果,产生了3个聚类,如下解释:
> kc
K-means clustering with 3 clusters of sizes 62, 50, 38 #K-means算法产生了3个聚类,大小分别为38,50,62. Cluster means: #每个聚类中各个列值生成的最终平均值
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.901613 2.748387 4.393548 1.433871
2 5.006000 3.428000 1.462000 0.246000
3 6.850000 3.073684 5.742105 2.071053 Clustering vector: #每行记录所属的聚类(2代表属于第二个聚类,1代表属于第一个聚类,3代表属于第三个聚类) [1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
[71] 1 1 1 1 1 1 1 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 1 3 3 3 3 1 3 3 3 3 3 3 1 1 3 3 3 3 1 3 1 3 1 3 3 1 1 3 3 3 3 3 1 3 3 3 3 1 3
[141] 3 3 1 3 3 3 1 3 3 1 Within cluster sum of squares by cluster: #每个聚类内部的距离平方和,说明第一类样本点差异最大,第二类差异最小
[1] 39.82097 15.15100 23.87947
(between_SS / total_SS = 88.4 %)
#组间的距离平方和占了整体距离平方和的的88.4%,这个值越大表明组内差距越小,组间差距越大,即聚类效果越好该值可用于与类别数取不同值时的聚类结果进行比较。 Available components: [1] "cluster" "centers" "totss" "withinss" "tot.withinss" "betweenss" "size" "iter" "ifault"
#"cluster"是一个整数向量,用于表示记录所属的聚类
#"centers"是一个矩阵,表示每聚类中各个变量的中心点
#"totss"表示所生成聚类的总体距离平方和
#"withinss"表示各个聚类组内的距离平方和
#"tot.withinss"表示聚类组内的距离平方和总量
#"betweenss"表示聚类组间的聚类平方和总量
#"size"表示每个聚类组中成员的数量
创建一个连续表,在三个聚类中分别统计各种花出现的次数
> ##在三个聚类中分别统计各种花出现的次数
> table(iris$Species, kc$cluster) 1 2 3
setosa 0 50 0
versicolor 48 0 2
virginica 14 0 36
根据最后的聚类结果画出散点图,数据为结果集中的列"Sepal.Length"和"Sepal.Width",颜色为用1,2,3表示的缺省颜色
> plot(newiris[c("Sepal.Length", "Sepal.Width")], col = kc$cluster)
在图上标出每个聚类的中心点
> points(kc$centers[,c("Sepal.Length", "Sepal.Width")], col = 1:3, pch = 8, cex=2)
生成图例 如下:
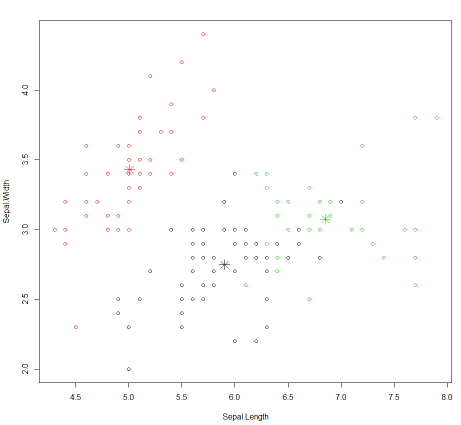
小结:
在这个示例中, 首先将数据集中变量品种全部置为空, 然后重新指定3个聚类,比较一下kmeans算法生成的结果和原有的结果。
在kmean算法中针对变量 Sepal.Length Sepal.Width Petal.Length Petal.Width生成三组随机值作为中心点,然后计算每个样本中的4个变量到随机值的距离,根据最新的随机数值总合算出平均值重新计算中心点。然后不断的重复此步骤, 直到中心点的值不再变化。最后再将样本值和最终生成的中心值作比较,距离最近的归属于这个中心值所代表的聚类。最后使用plot函数画图的时候, 可以发现kmeans算法最后生成的分类并不是特别理想,各个聚类之间的距离并不是很大。需要多运行几次。
fpc::kmeansruns()
fpc包kmeansruns函数,相比于kmeans函数更加稳定,而且还可以估计聚为几类
Usage: kmeansruns(data,krange=2:10,criterion="ch",iter.max=100,runs=100,scaledata=FALSE,alpha=0.001, critout=FALSE,plot=FALSE,...);
- krange: 聚类个数范围
- critout: logical. If TRUE, the criterion value is printed out for every number of clusters
- iter.max:是允许的最大迭代次数,默认为100
需要安装包
install.packages("lme4")
install.packages("fpc")
示例代码
> newiris <- iris
> newiris$Species <- NULL
> library(fpc)
>
> kc1 <- kmeansruns(data = newiris,krange = 1:5,critout = TRUE)
2 clusters 513.9245
3 clusters 561.6278
4 clusters 530.7658
5 clusters 495.5415
> ##kc1
> ##fitted(kc1)
> table(iris$Species, kc1$cluster) 1 2 3
setosa 0 0 50
versicolor 2 48 0
virginica 36 14 0
>
待验证:
fpc::cluster.stats()
小结:
指定聚类个数范围为:1:5, 但估计聚类结果为3,与kmeans方法相比,不需初始确定聚类个数
参考资料:
- http://www.tuicool.com/articles/eMRvE3
- https://rdrr.io/cran/fpc/man/kmeansruns.html
- http://www.statmethods.net/advstats/cluster.html
ML: 聚类算法-K均值聚类的更多相关文章
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 聚类和EM算法——K均值聚类
python大战机器学习——聚类和EM算法 注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著. 1.基本概念 (1)聚类的思想: 将数据集划分为若干个不想交的子 ...
- 【机器学习】聚类算法——K均值算法(k-means)
一.聚类 1.基于划分的聚类:k-means.k-medoids(每个类别找一个样本来代表).Clarans 2.基于层次的聚类:(1)自底向上的凝聚方法,比如Agnes (2)自上而下的分裂方法,比 ...
- 100天搞定机器学习|day44 k均值聚类数学推导与python实现
[如何正确使用「K均值聚类」? 1.k均值聚类模型 给定样本,每个样本都是m为特征向量,模型目标是将n个样本分到k个不停的类或簇中,每个样本到其所属类的中心的距离最小,每个样本只能属于一个类.用C表示 ...
- 【转】算法杂货铺——k均值聚类(K-means)
k均值聚类(K-means) 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先明确知道各个类别的信息,并且断言所有待分类项都有一个类别与之对应.但是很多时 ...
- (ZT)算法杂货铺——k均值聚类(K-means)
https://www.cnblogs.com/leoo2sk/category/273456.html 4.1.摘要 在前面的文章中,介绍了三种常见的分类算法.分类作为一种监督学习方法,要求必须事先 ...
- 机器学习理论与实战(十)K均值聚类和二分K均值聚类
接下来就要说下无监督机器学习方法,所谓无监督机器学习前面也说过,就是没有标签的情况,对样本数据进行聚类分析.关联性分析等.主要包括K均值聚类(K-means clustering)和关联分析,这两大类 ...
随机推荐
- python day09作业
- web-view中下载微信头像跨域解决方案
let img = new Image() // 头像地址后边添加时间戳可解决跨域问题 555. img.src = 'http://wx.qlogo.cn/mmopen/vi_32/RnLIHfXi ...
- linux系统nginx的https的跳转
环境:系统ubuntu16 申请证书是腾讯云免费证书 首先我在安装nginx SSL证书的时候犯了个错误,nginx是需要安装SSl的模块不然没法配置完成.需要安装一个 http_ssl_module ...
- Python学习笔记第二十五周(Django补充)
1.render_to_reponse() 不同于render,render_to_response()不用包含request,直接写template中文件 2.locals() 如果views文件中 ...
- Angular 手动解析表达式
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- OpenCV 自定义任意区域形状及计算平均值 方差
opencv中有矩形的Rect函数.圆形的circl函数等,那么任意形状怎么取呢?方法1:点乘,将其形状与图像进行点乘,求其形状对应的图像形状:方法2:用findContours函数得对应的形状区域, ...
- git 应用
git - 简易指南 助你开始使用 git 的简易指南,木有高深内容,;). 安装 下载 git OSX 版 下载 git Windows 版 下载 git Linux 版 创建新仓库 创建新文件夹, ...
- java-继承的注意事项
1.子类只能继承父类所有非私有的成员(成员方法和成员变量). 2.子类不能继承父类的构造方法,但是可以通过super关键字去访问父类构造方法. 3.不要为了部分功能而去继承.
- spring IOC简单分析
Spring IOC 体系结构 BeanFactory(BeanFactory 里只对 IOC 容器的基本行为作了定义,根本不关心你的 bean 是如何定义怎样加载的.正如我们只关心工厂里得到什么的产 ...
- 【JVM】jvm虚拟机参数解析
转载:https://blog.csdn.net/see__you__again/article/details/51998038不管是YGC还是Full GC,GC过程中都会对导致程序运行中中断,正 ...