深度学习课程笔记(一)CNN 卷积神经网络
深度学习课程笔记(一)CNN 解析篇
相关资料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
首先提到 Why CNN for Image ?
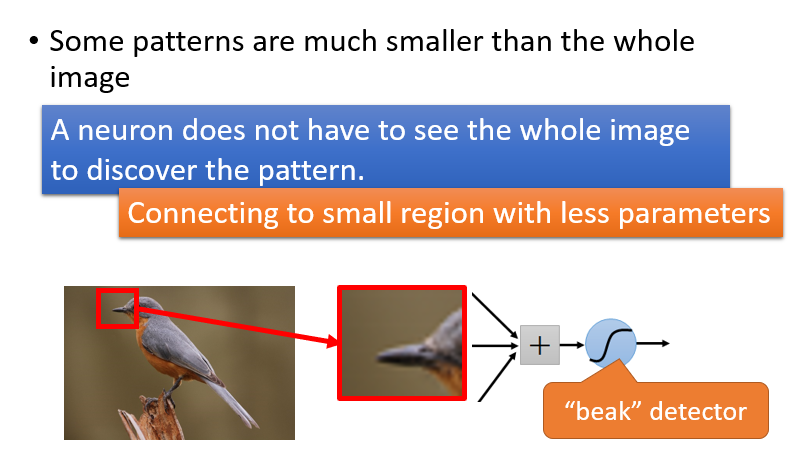
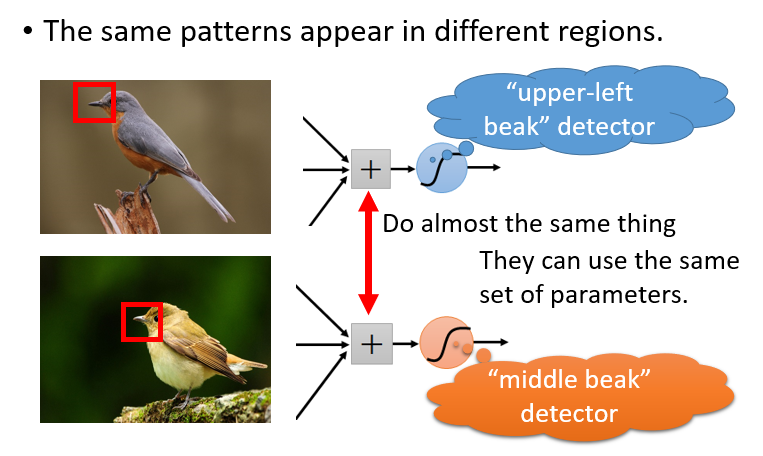

综合上述三个特点,我们可以看到图像识别有如下的特色:
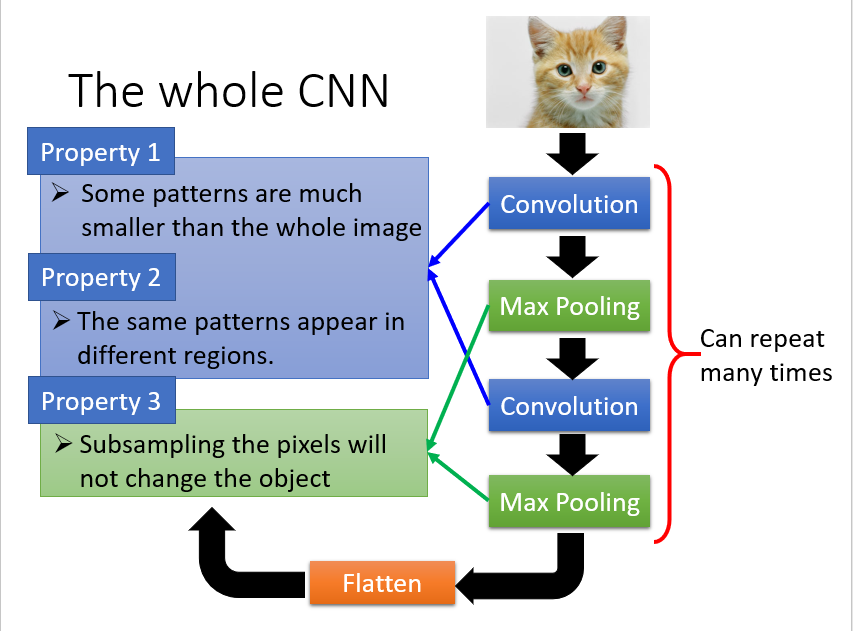
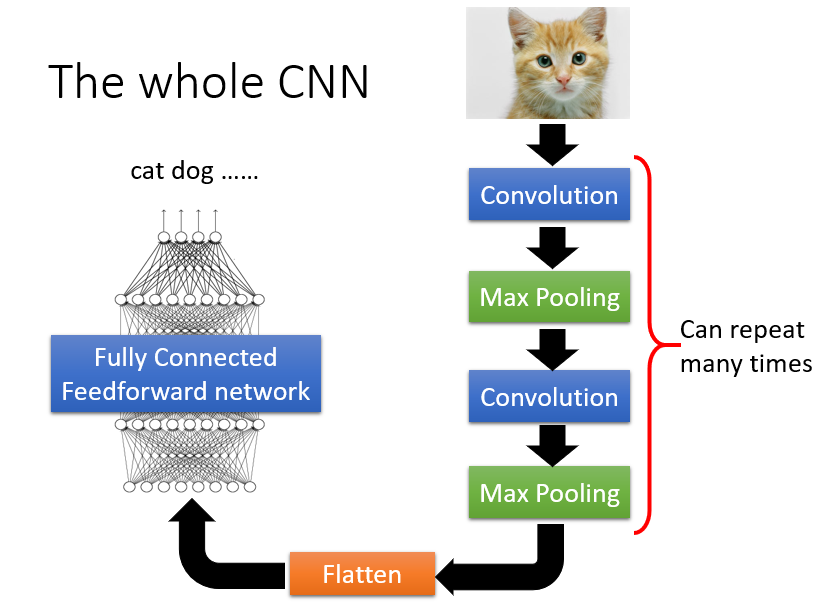
=================================== 分割线 =======================================================
以上就是整体上来感受下深度神经网络,接下来我们仔细分析下每一个部件:
1. Convolution Layer
所谓卷积层,就是将两个矩阵进行卷积操作,这里的两个矩阵分别是指 卷积核(filter)和每一个与filter相同大小的图像区域。这里的卷积操作就是 点成(矩阵对应元素相乘)。
然后没执行一次这样的操作,就滑动一次filter,然后进行下一个区域的卷积操作,直至整幅图像被处理完毕。滑动的幅度,称为stride (步长)。如下图所示:
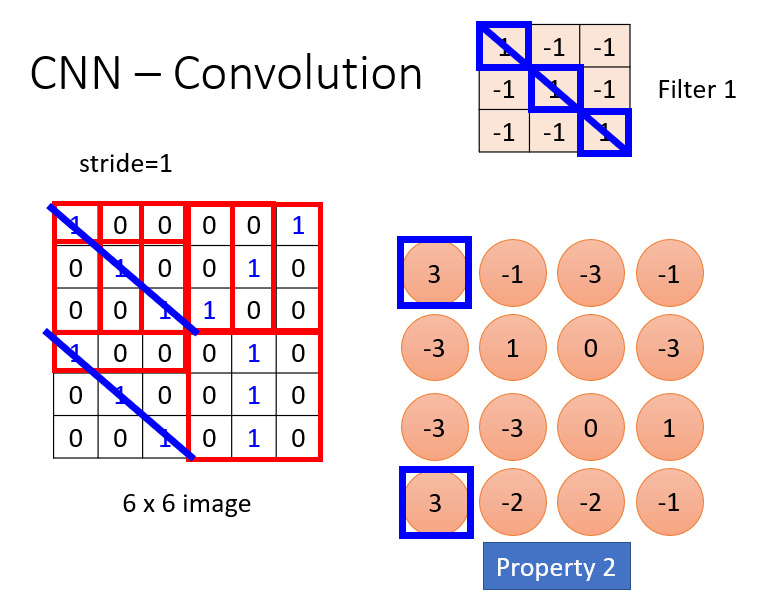
然后再用另一组 filter 对该图像进行类似的处理。一张图像可以用多个卷积核来进行处理。上面提到的图像是 gray image,而对于彩色图像来说,是三个通道的。这个没有关系,我们将三个 filter 作为一组,分别对三个 channel 进行卷积,就可以了。如下图所示:
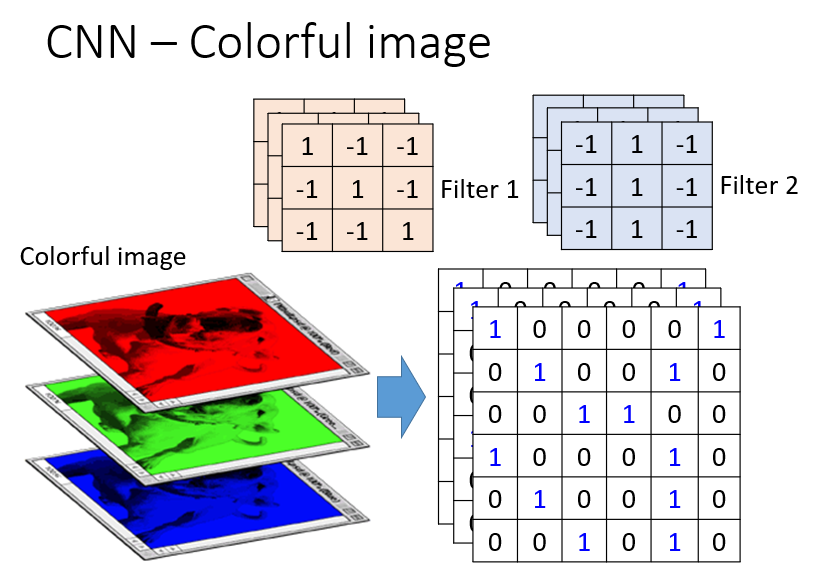
2. Pooling Layer:
所谓的池化层,就是对得到的 feature map 进行降采样处理,常见的有,mean, max pooling operation 等。即:在一个区域内,如:2*2 的区域,max pooling 就是选择一个 max value 来代表这个区域,其余的直接扔掉。mean 就是取这些 value 的平均值来代替这些。当然也可以同时进行 max 和 mean pooling 操作,来完成降采样的过程。
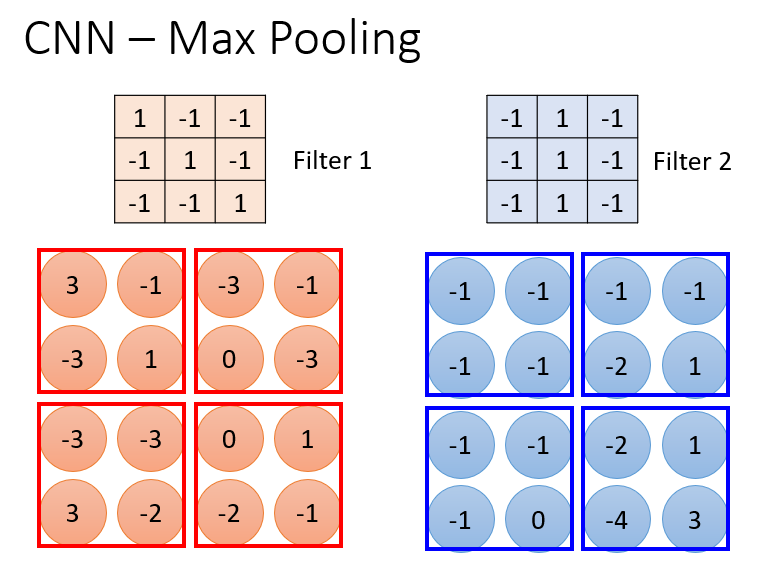
需要说明的是,max pooling 其实并不是必须的,如:在AlphaGo 中,使用的网络结构并没有使用 max pooling layer,因为使用了这个层,就会丢失一定的信息,而实际上 棋盘丢失了某些信息,结果是无法想象的。因为这可能会导致不同的局面。。。这是李宏毅老师的解释。。。但是,我觉得,这只是整个分辨率降低了而已,没有那么大的影响吧???如果有小伙伴知道更详细的答案,请不吝赐教。
3. Fully Connected Layer:
全连接层 也是常见的 CNN 组件,一般用来输出一组向量。而 fc layer 和 convolutional layer 可以看做是类似的操作,为何这么说呢?且看下图:
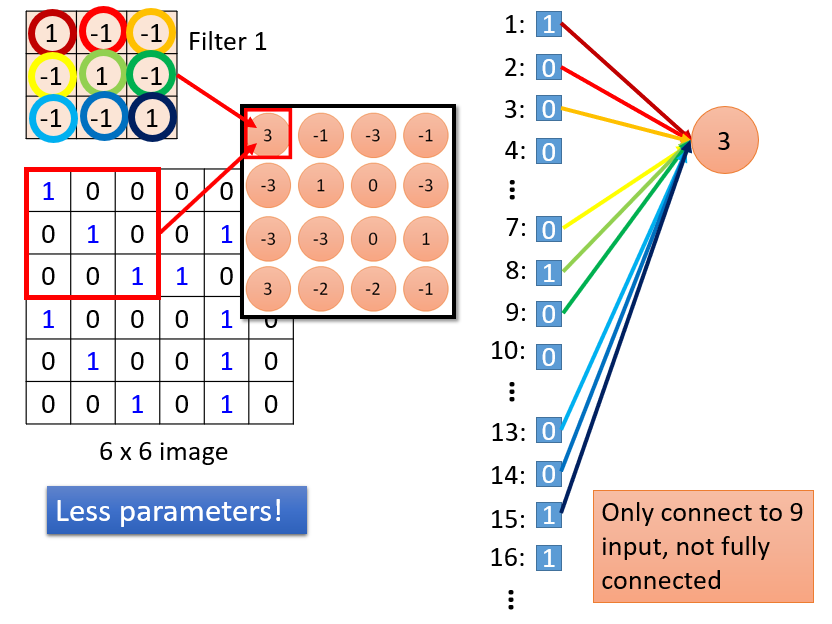
上图中,我们将 filter 中不同的 weight 设置为不同的颜色,在进行卷积操作的时候,我们进行对应元素点乘操作,从而得到 3 。我们将对应图像区域中的元素标上标号可以看出,我们这里仅仅和 9 个输入元素进行了连接,而不是所有的元素。所以,这里 convolutional layer 是 sparse connected。同时,在移动之后的卷积操作也是类似,而且这两个过程是共享权重的,都分享了同一个 filter 1. 这样就可以降低参数的数量,使得训练和测试都可以尽量快速的执行。
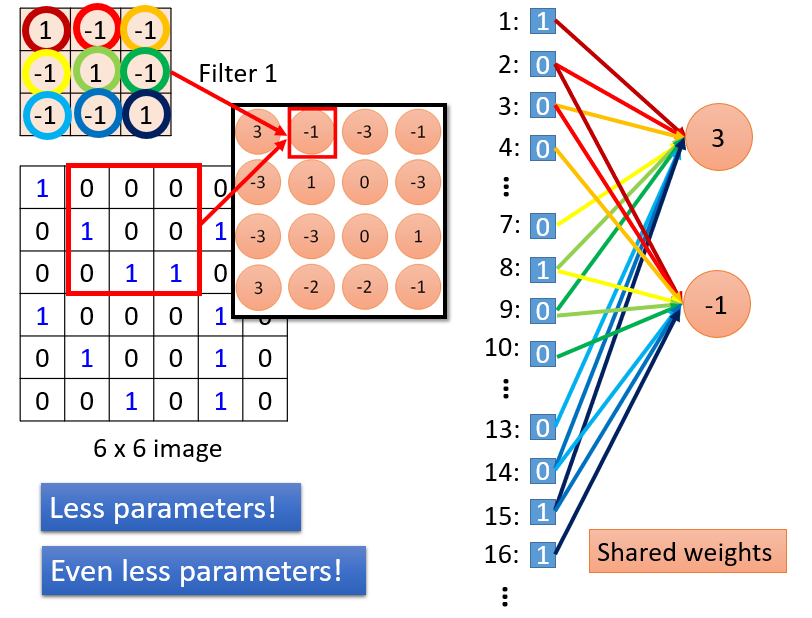
这里还有一个比较迷糊人的问题是,卷积层 出来的 feature map 是一个立方体矩阵,而 fc layer 处理的是 vector,这两者之间是怎么接起来的呢?看下图:
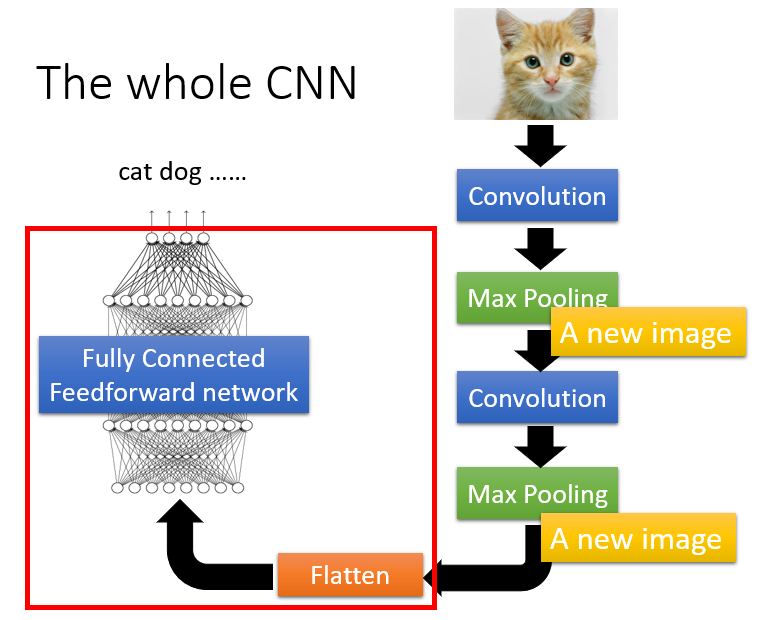
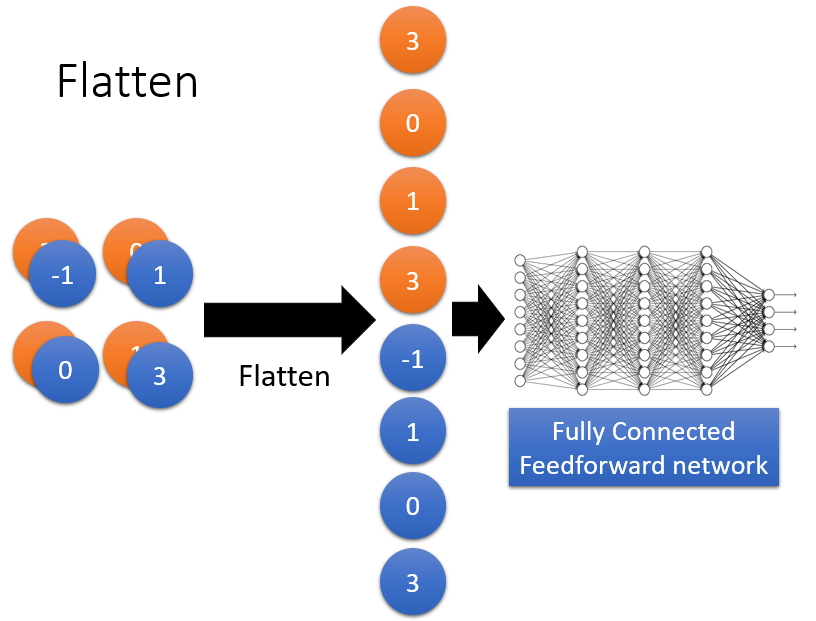
是的,你没有看错,两者之间有一个 flatten 的操作,即:将 feature map 按照每一个 map 展开,然后拼接在一起,构成一个大的 vector,再进行处理。整个过程如下所示:
4. 激活层:
常见的激活函数,有 sigmoid, ReLU, PReLU 等等。这些非线性函数被引入到 CNN 当中来,使得该模型具有非线性拟合能力。从而,可以执行更加复杂多样的任务。
========================================== 分割线 =================================================
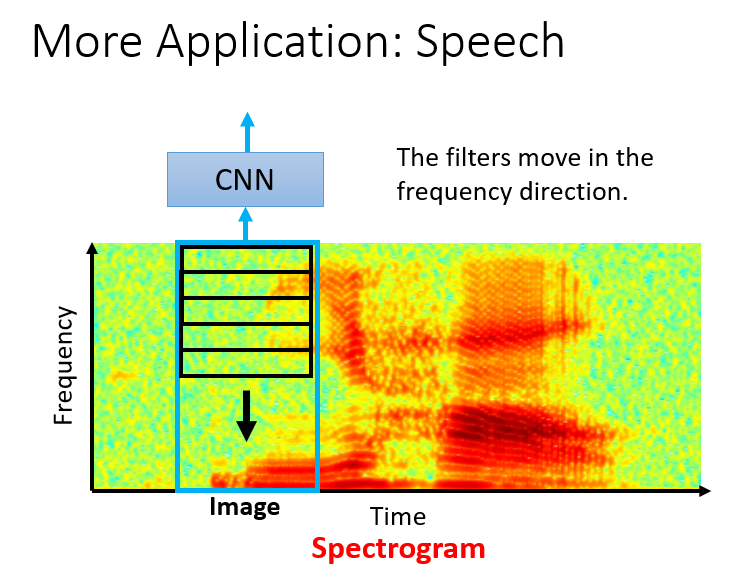
CNN 常见的应用除了在图像领域之外,还有语音和自然语言领域。你可能比较纳闷,CNN 不是专门用来处理图像的吗?
宏观的来看,这只是一个执行 weighting operation 的网络,是可以处理任何 matrix 形式的东西的。例如:将语音和文本转化为 matrix 的形式,就可以利用 CNN 来进行特征的学习,从而完成后续的研究任务,像语音识别,等等。
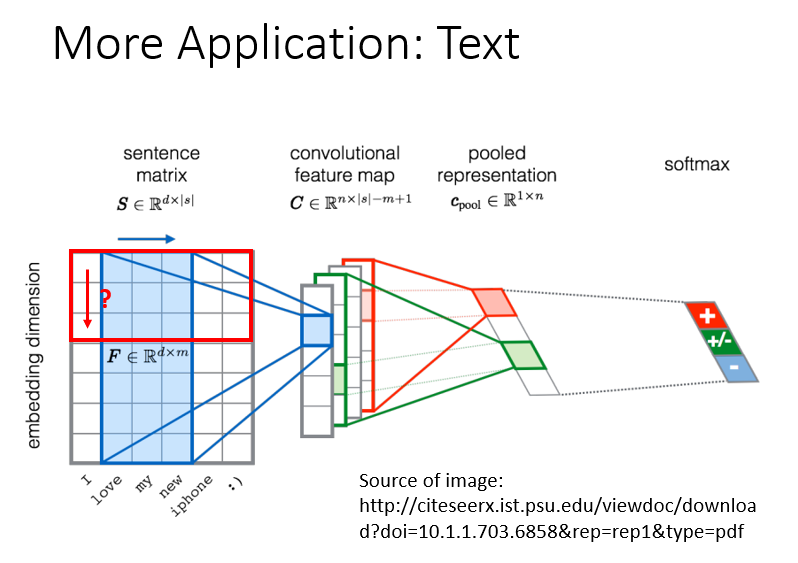
======================== 完毕 ==============================
基础的图像识别的例子 ------ pytorch 版本:
- from __future__ import print_function
- import argparse
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- from torchvision import datasets, transforms
- from torch.autograd import Variable
- # Training settings
- parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
- parser.add_argument('--batch-size', type=int, default=64, metavar='N',
- help='input batch size for training (default: 64)')
- parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
- help='input batch size for testing (default: 1000)')
- parser.add_argument('--epochs', type=int, default=10, metavar='N',
- help='number of epochs to train (default: 10)')
- parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
- help='learning rate (default: 0.01)')
- parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
- help='SGD momentum (default: 0.5)')
- parser.add_argument('--no-cuda', action='store_true', default=False,
- help='disables CUDA training')
- parser.add_argument('--seed', type=int, default=1, metavar='S',
- help='random seed (default: 1)')
- parser.add_argument('--log-interval', type=int, default=10, metavar='N',
- help='how many batches to wait before logging training status')
- args = parser.parse_args()
- args.cuda = not args.no_cuda and torch.cuda.is_available()
- torch.manual_seed(args.seed)
- if args.cuda:
- torch.cuda.manual_seed(args.seed)
- kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
- train_loader = torch.utils.data.DataLoader(
- datasets.MNIST('../data', train=True, download=True,
- transform=transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize((0.1307,), (0.3081,))
- ])),
- batch_size=args.batch_size, shuffle=True, **kwargs)
- test_loader = torch.utils.data.DataLoader(
- datasets.MNIST('../data', train=False, transform=transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize((0.1307,), (0.3081,))
- ])),
- batch_size=args.test_batch_size, shuffle=True, **kwargs)
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
- self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
- self.conv2_drop = nn.Dropout2d()
- self.fc1 = nn.Linear(320, 50)
- self.fc2 = nn.Linear(50, 10)
- def forward(self, x):
- x = F.relu(F.max_pool2d(self.conv1(x), 2))
- x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
- x = x.view(-1, 320)
- x = F.relu(self.fc1(x))
- x = F.dropout(x, training=self.training)
- x = self.fc2(x)
- return F.log_softmax(x)
- model = Net()
- if args.cuda:
- model.cuda()
- optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
- def train(epoch):
- model.train()
- for batch_idx, (data, target) in enumerate(train_loader):
- if args.cuda:
- data, target = data.cuda(), target.cuda()
- data, target = Variable(data), Variable(target)
- optimizer.zero_grad()
- output = model(data)
- loss = F.nll_loss(output, target)
- loss.backward()
- optimizer.step()
- if batch_idx % args.log_interval == 0:
- print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
- epoch, batch_idx * len(data), len(train_loader.dataset),
- 100. * batch_idx / len(train_loader), loss.data[0]))
- def test():
- model.eval()
- test_loss = 0
- correct = 0
- for data, target in test_loader:
- if args.cuda:
- data, target = data.cuda(), target.cuda()
- data, target = Variable(data, volatile=True), Variable(target)
- output = model(data)
- test_loss += F.nll_loss(output, target, size_average=False).data[0] # sum up batch loss
- pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
- correct += pred.eq(target.data.view_as(pred)).cpu().sum()
- test_loss /= len(test_loader.dataset)
- print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
- test_loss, correct, len(test_loader.dataset),
- 100. * correct / len(test_loader.dataset)))
- for epoch in range(1, args.epochs + 1):
- train(epoch)
- test()
深度学习课程笔记(一)CNN 卷积神经网络的更多相关文章
- 深度学习课程笔记(十二) Matrix Capsule
深度学习课程笔记(十二) Matrix Capsule with EM Routing 2018-02-02 21:21:09 Paper: https://openreview.net/pdf ...
- 深度学习课程笔记(十一)初探 Capsule Network
深度学习课程笔记(十一)初探 Capsule Network 2018-02-01 15:58:52 一.先列出几个不错的 reference: 1. https://medium.com/ai% ...
- 深度学习课程笔记(五)Ensemble
深度学习课程笔记(五)Ensemble 2017.10.06 材料来自: 首先提到的是 Bagging 的方法: 我们可以利用这里的 Bagging 的方法,结合多个强分类器,来提升总的结果.例如: ...
- 深度学习课程笔记(四)Gradient Descent 梯度下降算法
深度学习课程笔记(四)Gradient Descent 梯度下降算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 深度学习课程笔记(三)Backpropagation 反向传播算法
深度学习课程笔记(三)Backpropagation 反向传播算法 2017.10.06 材料来自:http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS1 ...
- 深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE
深度学习课程笔记(十八)Deep Reinforcement Learning - Part 1 (17/11/27) Lectured by Yun-Nung Chen @ NTU CSIE 201 ...
- 深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning)
深度学习课程笔记(十七)Meta-learning (Model Agnostic Meta Learning) 2018-08-09 12:21:33 The video tutorial can ...
- 深度学习课程笔记(十六)Recursive Neural Network
深度学习课程笔记(十六)Recursive Neural Network 2018-08-07 22:47:14 This video tutorial is adopted from: Youtu ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
随机推荐
- python 读csv数据 通过改变分隔符去掉引号
import csv with open(r'C:\Temp\ff.csv') as f: f_csv=csv.reader(f,delimiter='\t') headers=next(f_csv) ...
- flask 在模板中渲染表单
在模板中渲染表单 为了能够在模板中渲染表单,我们需要把表单类实例传入模板.首先在视图函数里实例化表单类LoginForm,然后再render_template()函数中使用关键脑子参数form将表单实 ...
- vc709时钟信号报单端信号错误的记录
话说,为什么我又要跑去搞fpga玩了,不是应该招个有经验的开发人员么?大概是练度不够吧…… Xilinx这个板子阿,真鸡儿贵,我这还没啥基础,慢慢试吧: 看了乱七八糟各种文档先不提,我还是决定先控制L ...
- Fiddler4入门--手机抓包工具安装和使用说明
Fiddler4入门--手机抓包工具安装和使用说明.电脑最好是笔记本连同一个wifi,这样能和手机保持统一局域网内. 很多区块链dapp项目方风控做的很差,利用fiddler抓包分析找一些漏洞,然后利 ...
- linux下mysql 8.0忘记密码后重置密码
1://免密码登陆 找到mysql配置文件:my.cnf, 在[mysqld]模块添加:skip-grant-tables 保存退出: 2://使配置生效 重启mysql服务: service ...
- centos 文件新建、删除、移动、复制等命令
创建目录 mkdir 文件名 mkdir /var/www/test cp复制命令 cp命令复制文件从一个位置到另一位置.如果目的地文件存在,将覆复写该文件: 如果目的地目录存在,文件将复制到该目录下 ...
- 怎样从外网访问内网php-fpm?
本地安装了一个php-fpm,只能在局域网内访问,怎样从外网也能访问到本地的php-fpm呢?本文将介绍具体的实现步骤. 准备工作 安装并启动php-fpm 默认安装的php-fpm端口是9000. ...
- GC Root 对象有哪些
(1)虚拟机(JVM)栈中引用对象 (2)方法区中的类静态属性引用对象 (3)方法区中常量引用的对象(final 的常量值) (4)本地方法栈JNI的引用对象
- mycat分片操作
mycat位于应用与数据库的中间层,可以灵活解耦应用与数据库,后端数据库可以位于不同的主机上.在mycat中将表分为两大类:对于数据量小且不需要做数据切片的表,称之为分片表:对于数据量大到单库性能,容 ...
- Introduction To Machine Learning Self-Evaluation Test
Preface Section 1 - Mathematical background Multivariate calculus take derivatives and integrals; de ...