【Hadoop学习之三】Hadoop全分布式安装
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk8
hadoop3.1.1
全分布式就是集群,注意配置主机名。
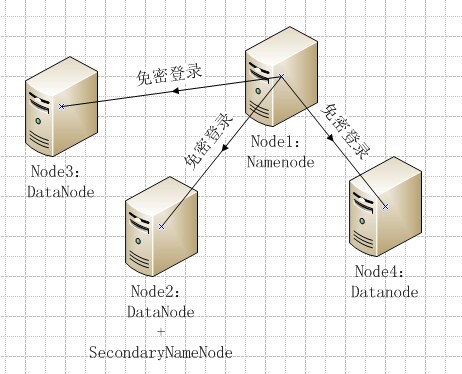
一、平台和软件
1、安装JDK和免密登录参考:【Hadoop学习之二】Hadoop伪分布式安装
2、设置环境变量
[root@node1 /]# vi /etc/profile
[root@node1 /]# source /etc/profile

#注意pwd 是打印当前路径 意思是要拷贝到远程主机统一目录下
[root@node1 etc]# scp /etc/profile node2:`pwd`
profile % .9KB/s :
[root@node1 etc]# scp /etc/profile node3:`pwd`
profile % .9KB/s :
[root@node1 etc]# scp /etc/profile node4:`pwd`
profile % .9KB/s :
3、node1-node4设置主机名 后重启
[root@node1 /]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.230.11 node1
192.168.230.12 node2
192.168.230.13 node3
192.168.230.14 node4
分发到另外三个节点
[root@node1 etc]# scp /etc/hosts node2:`pwd`
hosts % .2KB/s :
[root@node1 etc]# scp /etc/hosts node3:`pwd`
hosts % .2KB/s :
[root@node1 etc]# scp /etc/hosts node4:`pwd`
hosts % .2KB/s :
第一次配置hosts 需要重启生效
[root@node1 /]# reboot
二、配置
1、修改/usr/local/hadoop-3.1.1/etc/hadoop/hadoop-env.sh 设置JAVA环境变量、角色用户
在最后添加如下设置:
export JAVA_HOME=/usr/local/jdk1..0_65
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
2、修改/usr/local/hadoop-3.1.1/etc/hadoop/core-site.xml 配置主节点相关信息
(1)fs.defaultFS 主节点通讯信息 (hadoop3默认端口改为9820)
(2)hadoop.tmp.dir 设置namenode元数据和datanode block数据的目录
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9820</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoopfull</value>
</property>
</configuration>
3、修改/usr/local/hadoop-3.1.1/etc/hadoop/hdfs-site.xml 配置从节点相关信息
(1)dfs.replication 副本数
(2)dfs.namenode.secondary.http-address 二级namenode (hadoop默认端口改为9868)
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
4、修改workers(hadoop2.X叫slave)配置从节点(DATANODE)信息
配置:
node2
node3
node4
5、分发hadoop到node2、node3、node4 依赖免密登录 注意拷贝时的目录 (注意:jdk也可以采用这种方式分发)
[root@node2 local]# scp -r /usr/local/hadoop-3.1. node2:`pwd`
[root@node2 local]# scp -r /usr/local/hadoop-3.1. node3:`pwd`
[root@node2 local]# scp -r /usr/local/hadoop-3.1. node4:`pwd`
三、启动
首次启动,需要主节点进行格式化
[root@node1 /]# hdfs namenode -format
启动:node1作为namenode主节点,要在主节点上启动
[root@node1 /]# start-dfs.sh
关闭:
[root@node1 /]# stop-dfs.sh
可以使用jps命令,在node2、node3、node4上查看启动情况
【Hadoop学习之三】Hadoop全分布式安装的更多相关文章
- Centos 6.5 hadoop 2.2.0 全分布式安装
hadoop 2.2.0 cluster setup 环境: 操作系统:Centos 6.5 jdk:jdk1.7.0_51 hadoop版本:2.2.0 hostname ip master ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- hadoop 2.7.3伪分布式安装
hadoop 2.7.3伪分布式安装 hadoop集群的伪分布式部署由于只需要一台服务器,在测试,开发过程中还是很方便实用的,有必要将搭建伪分布式的过程记录下来,好记性不如烂笔头. hadoop 2. ...
- centos 7下Hadoop 2.7.2 伪分布式安装
centos 7 下Hadoop 2.7.2 伪分布式安装,安装jdk,免密匙登录,配置mapreduce,配置YARN.详细步骤如下: 1.0 安装JDK 1.1 查看是否安装了openjdk [l ...
- hadoop学习之hadoop完全分布式集群安装
注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流.转载请注明来自: http://blog.csdn.net/ab198604/article/details/8250461 要想深入的 ...
- [大数据] hadoop全分布式安装
一.准备工作 在伪分布式的搭建基础上修改配置,搭建全分布式hadoop环境,伪分布式安装参照 hadoop伪分布式安装. 首先准备4台虚拟机,信息如下: 192.168.1.11 namenode1 ...
- hadoop学习笔记——基础知识及安装
1.核心 HDFS 分布式文件系统 主从结构,一个namenoe和多个datanode, 分别对应独立的物理机器 1) NameNode是主服务器,管理文件系统的命名空间和客户端对文件的访问操 ...
- Hadoop + Hive + HBase + Kylin伪分布式安装
问题导读 1. Centos7如何安装配置? 2. linux网络配置如何进行? 3. linux环境下java 如何安装? 4. linux环境下SSH免密码登录如何配置? 5. linux环境下H ...
- Hadoop开发第4期---分布式安装
一.复制虚拟机 由于Hadoop的集群安装需要多台机器,由于条件有限,我是用虚拟机通过克隆来模拟多台机器,克隆方式如下图所示
随机推荐
- java之面向对象的基础知识
面向对象其实是种思想,凡是思想都是比较抽象的,所以我们总要找到一些方法使它便于我们理解:建模就是最常用的方式,而建模的一个特点就是减少关注度,尽量减少对具体细节的关注,这在面向对象三大特性中深有体现. ...
- tensorflow入门笔记(三) tf.GraphKeys
tf.GraphKeys类存放了图集用到的标准名称. 该标准库使用各种已知的名称收集和检索图中相关的值.例如,tf.Optimizer子类在没有明确指定待优化变量的情况下默认优化被收集到tf.Grap ...
- 两个java工程之间的相互调用方法
如果你有两个java项目的话,如何向他们之间进行信息的通信前提:必须知道要通信的java项目(接收请求方)的服务器的IP地址和访问路径.其实两个java项目之间的通信还是使用HTTP的请求.主要有两种 ...
- SpringBoot-热部署Devtools
热部署 什么是热部署 所谓的热部署:比如项目的热部署,就是在应用程序在不停止的情况下,实现新的部署 项目演示案例 @RestController @Slf4j public class IndexCo ...
- 【Mock】mock基础、简单的单元测试代码练习。
说到接口测试,必问 mock,mock 通俗一点来说就是模拟接口返回.解决接口的依赖关系,主要是为了解耦,单元测试用的多. 什么是Mock unittest.mock 是一个用于在 Python 中进 ...
- wps去广告
彻底解决WPS弹出热点广告.WPS购物图标的办法 方法一:(一定有效) https://www.cnblogs.com/ytaozhao/p/5654149.html 一直用WPS,但一直有一个问题迟 ...
- 终极大招——Scrapy框架
Scrapy框架 Scrapy 是一个开源和协作的框架,其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的,使用它可以以快速.简单.可扩展的方式从网站中提取所需的数据.但目前Scrapy的用途 ...
- python按修改时间顺序排列文件
import os def sort_file_by_time(file_path): files = os.listdir(file_path) if not files: return else: ...
- js 图片区域可点击,适配移动端,图片大小随意改变
实现图片区域可点击,实际上使用map是可以的,但是适配效果并不好,图片只能是固定大小的值,而且点都被写死了. 在这里,我使用的js基于canvas写的一个小工具.可以圈出你需要点击的部分,然后生成一串 ...
- mac 下 IntelliJ IDEA 快捷键
编辑器 Cmd + N // 代码生成,getter, setter Opt + Enter // 导入类或者注解